目录
Resource Info Paper https://ceur-ws.org/Vol-2699/paper07.pdf Code & Data https://github.com/ranyxr/dice_story Model https://drive.google.com/drive/folders/1T68rWkOde5ZwcuodQ9iWuYJAcqAmb0Jo Public CIKM Date 2020.10.19
Summary Overiew
这篇文章是2020年的,研究了如何将知识图谱模型与 LM 相结合,并且提出了一个 DICE 模型。当时还没有 LLM 的概念,但是作者还是使用了 GPT-2 这样的模型微调进行了测试,感觉作者对于未来趋势的把握还是十分不错的。
主要思想就是,通过根据 User 的关键词,根据构建好的知识图谱 KG,去寻找完善词语之间的关系,生成 SVO 三元组,并其通过三元组提交给语言模型生成最后的故事文本,这里作者的目标是生成短故事(5句话左右)。但是知识图谱在这里仅起到一个 enrich 的作用,并没有其他的作用。
Main Content
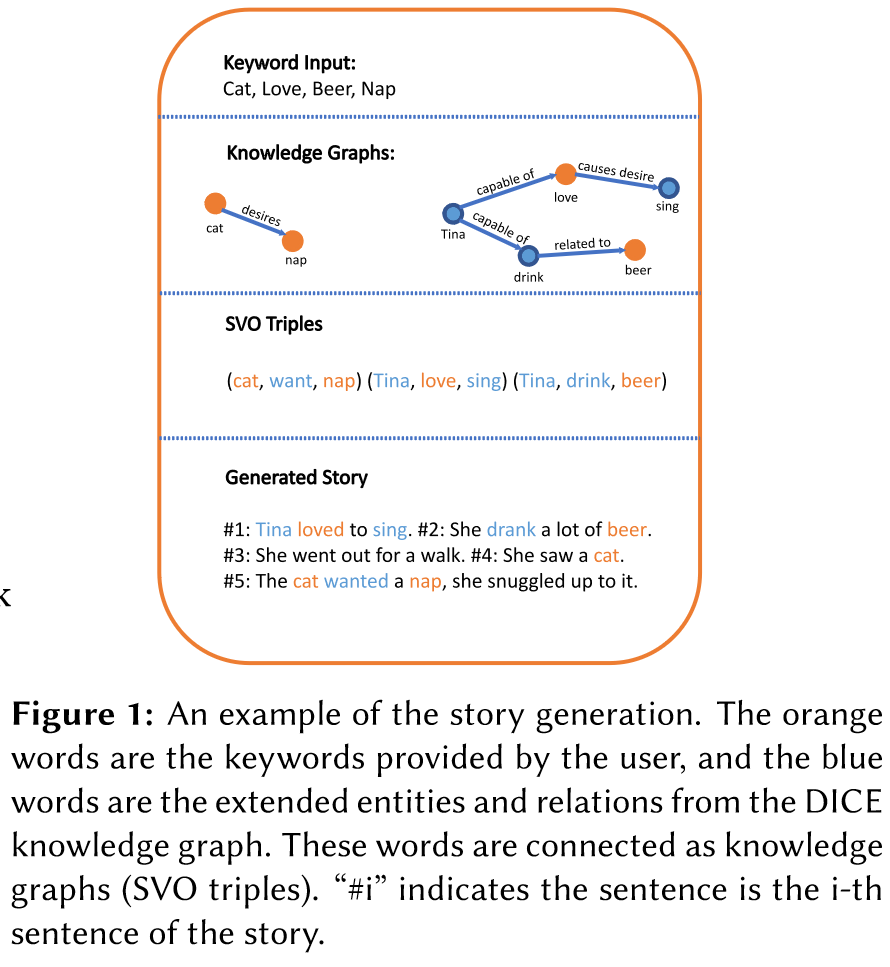
文章主要想要解决的问题:
- Q1:在没有知识图谱嵌入的情况下,如何将语言模型与知识图谱结合起来生成故事?
- Q2:使用知识图谱自动生成故事有哪些优缺点?
Contributions:
- 我们提出了一种结合知识图谱和语言模型的新方法,无需使用知识图谱嵌入即可生成文本。结果表明,我们可以有效地将知识图谱中的知识作为背景或情节注入到自动生成的故事中,从而在一定程度上控制这些故事的内容。
- 我们引入了一个经过微调的模型,该模型接受 SVO 三元组作为提示,而不是原始 GPT-2 模型使用的句子,从而利用 SVO 三元组提供的上下文生成合理而有创意的故事。
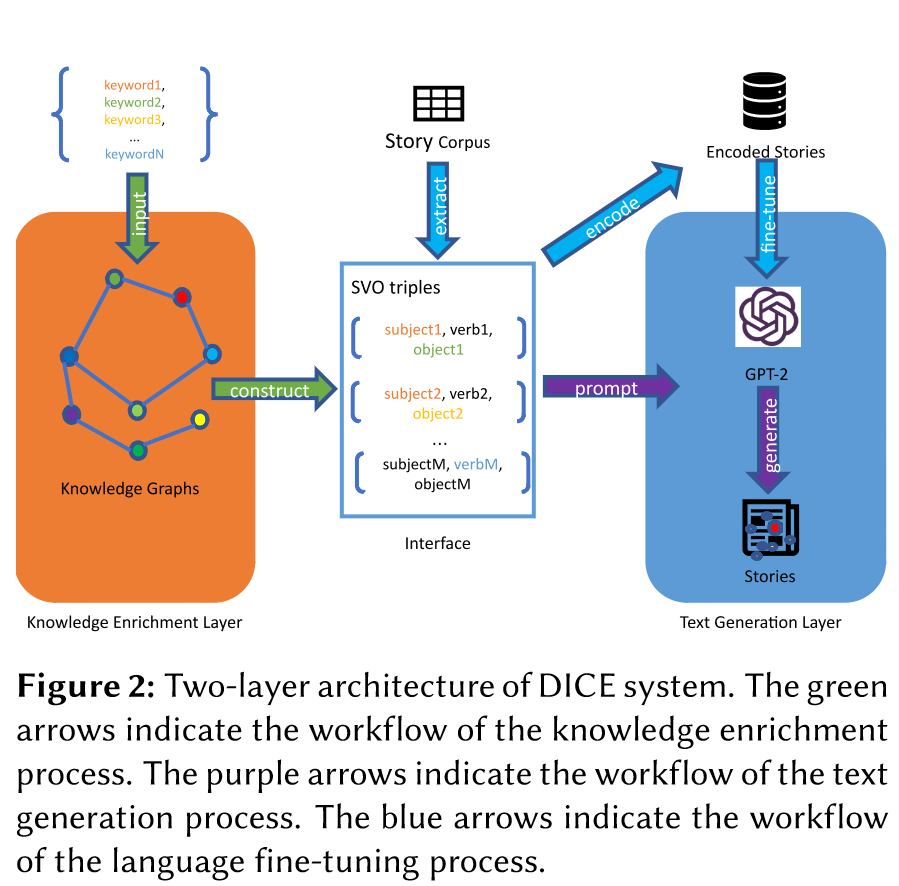
该系统的任务是从一组 SVO 三元组中生成 5 句故事,这些三元组被提取出来并重新组合到一个知识图谱中。系统的预期输入是用户提供的一组关键词。图 2 显示了 DICE 系统的双层结构。我们使用 SVO 三元组作为连接知识丰富层和文本生成层的接口。SVO 三元组可以从知识图谱中构建,也可以从故事语料库中提取;同时,它们还可以作为语言模型生成故事的提示。系统首先利用知识图谱检查这些关键词之间的关系并添加其他信息,然后生成一组 SVO 三元组,供语言模型生成故事。
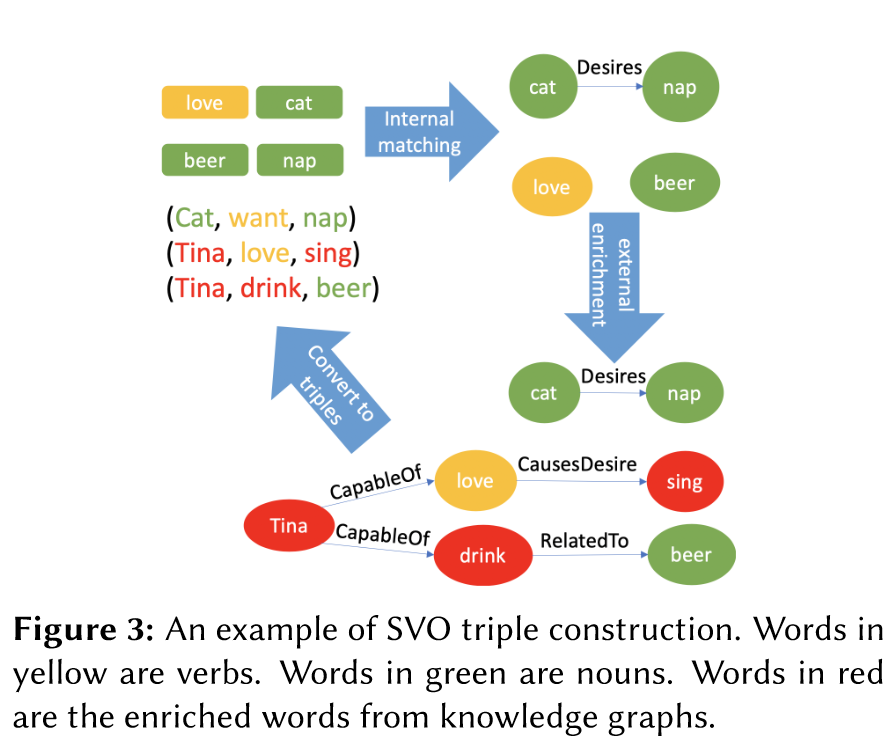
示例生成的故事文本:

Experiments
Metrics
评估重点关注生成输出的两个方面:与故事无关的指标和与故事相关的指标。
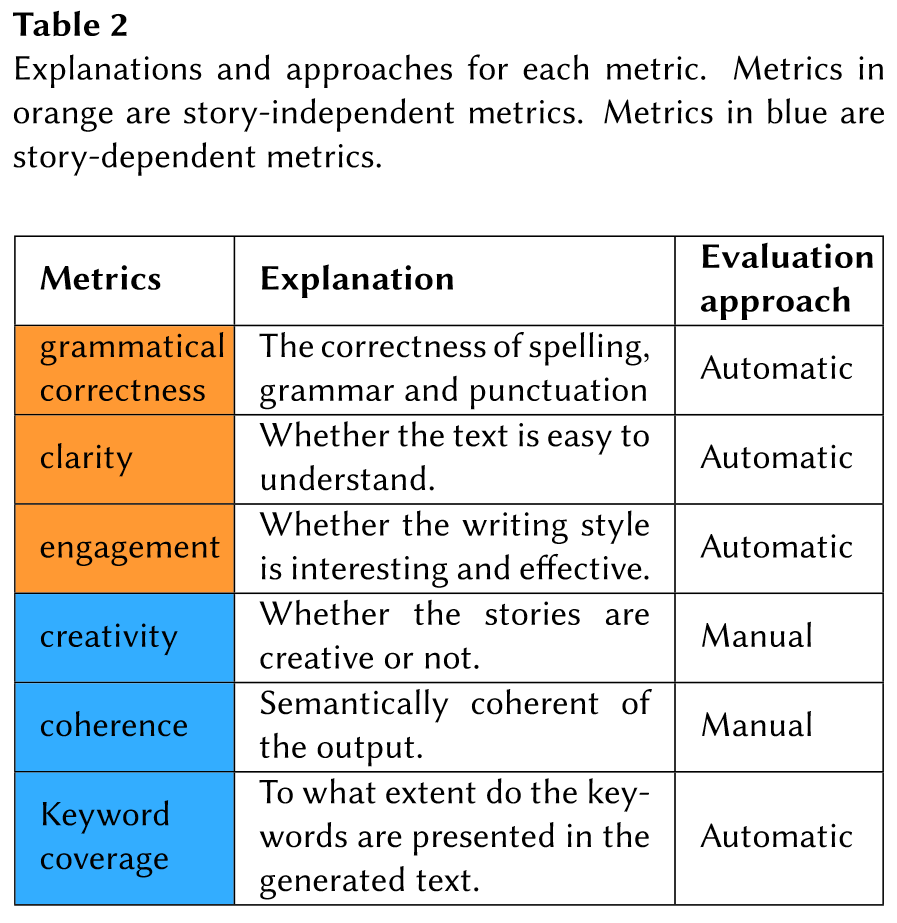
对于与故事无关的指标,我们使用自动分析工具 Grammarly 来评估生成文本的整体语法性能。
Datasets
- ROCStories
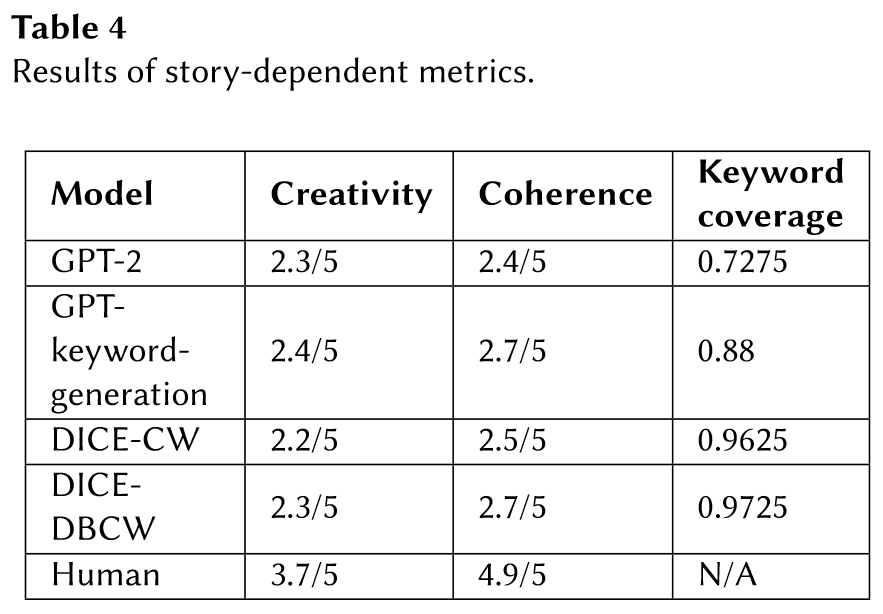
Results
为每个模型随机挑选了 100 个样本来评估它们的性能。

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: 此篇论文提出了一种新的方法,将知识图谱与语言模型结合,用于创造性故事生成。该方法不依赖于知识图谱的嵌入,而是直接使用主谓宾(SVO)三元组作为提示来引导语言模型生成故事。这种方法有效地将知识图谱中的知识注入到自动生成的故事中,同时也能在一定程度上控制故事的内容。这一方法的关键在于使用SVO三元组作为连接知识丰富层和文本生成层的接口。
-
论文中存在的问题及改进建议:
- 问题:虽然该方法能够有效地利用SVO三元组影响故事情节,但它无法保证故事的连贯性,因为这些三元组是从故事的每个句子中单独提取的,且相互之间联系较弱。
- 改进建议:可以考虑采用更复杂的结构化输入(如图形网络),以更好地捕获故事中的因果关系和逻辑流,从而提高故事的连贯性。
-
基于论文的内容和研究结果,提出的创新点或研究路径: a. 探索使用图形神经网络来增强故事生成的连贯性和逻辑性,通过将SVO三元组以图形的形式组织,使得模型可以更好地理解和利用故事元素之间的关系。 b. 开发一种新的语言模型训练方法,专门针对故事生成任务,例如通过模仿人类叙述故事的方式来训练模型。 c. 利用更丰富的外部知识源,如历史数据库、文学作品集,来提供更多样化和深入的背景知识,从而生成更具创造性和多样性的故事。
-
为新的研究路径制定的研究方案: a. 使用图形神经网络增强故事生成:
- 研究方法:构建一个能够处理图形结构输入的语言模型,并使用图形神经网络来分析和理解SVO三元组之间的关系。
- 步骤:首先构建一个包含人物、事件和地点等元素的图形网络,然后利用图形神经网络来学习这些元素之间的关系。最后,使用这些关系来引导故事生成。
- 期望成果:生成的故事将具有更高的逻辑性和连贯性,同时保持创造性。
b. 开发针对故事生成的语言模型训练方法:
- 研究方法:分析人类故事叙述的特点,设计模拟这些特点的训练任务。
- 步骤:通过对大量文学作品和口头叙述故事的分析,提取故事叙述的关键元素和模式,然后设计相应的训练任务来指导模型学习这些元素和模式。
- 期望成果:培养出能够更自然、更具人类风格的故事叙述能力的语言模型。
c. 利用丰富的外部知识源提升故事生成:
- 研究方法:整合历史数据库、文学作品集等多元化知识源,为故事生成提供更广泛的背景知识。
- 步骤:开发算法来整合和处理这些知识源,确保知识的准确性和适用性。然后将这些知识用于指导故事生成。
- 期望成果:生成具有丰富背景、文化深度和创造性的故事。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!