目录
Resource Info Paper https://arxiv.org/abs/2311.09677 Code & Data https://github.com/shizhediao/R-Tuning Public ArXiv Date 2024.03.14
Summary Overview
本文提出了一种指令调优的新方法 Refusal-Aware Instruction Tuning (R-Tuning)
该方法首先通过识别参数知识和指令调整数据之间的知识差距来形式化。然后,基于知识交叉构建拒绝感知数据,从而调整LLMs,避免回答超出其参数知识的问题。
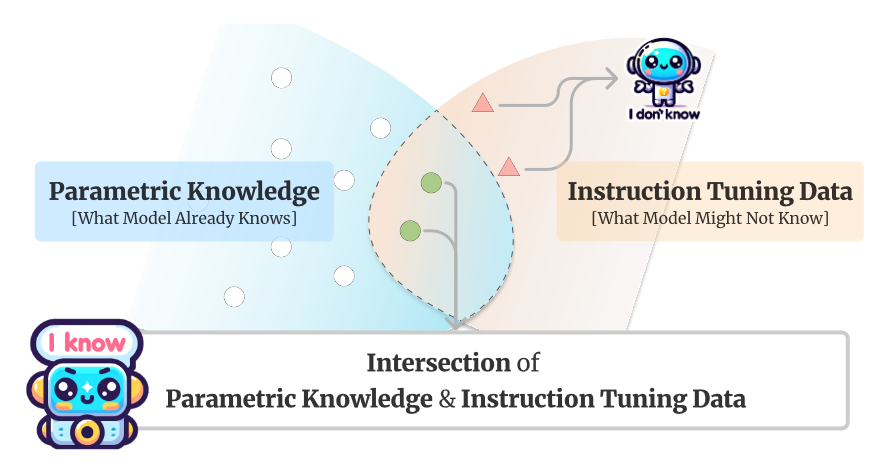
Main Content
之前的研究(Min et al., 2022; Wang et al., 2023; Zhou et al., 2023)表明,几乎所有知识都是在预训练阶段获得的,而指令调优则教授格式化和思维链提示指导知识启发。
即使面对超出其知识范围的问题,LLMs也会冒险提供答案。仅根据正确答案训练模型会无意中教会它猜测而不是承认自己的无知。
R-Tuning引入了两个步骤:
- 测量参数知识和指令调优数据之间的知识差距,识别不确定的问题。通过在训练数据上推断一次模型并比较预测和标签,指令调整数据被分为不确定数据和确定数据。
- 通过在标签词后面填充不确定性表达式来构造拒绝感知数据,然后在拒绝感知数据上微调模型。
进一步的分析令人惊讶地表明,在训练期间学习不确定性,然后用它来过滤和回答问题,比直接对测试数据应用不确定性过滤会产生更好的结果。
Contributions:
- 我们研究了指令调优数据和参数知识之间存在的知识差距,并将幻觉问题归因于迫使模型使用传统指令调优来完成答案。
- 为了解决这个问题,我们提出了一种新颖的指令调优方法——R-Tuning,它根据模型自身的知识来区分指令调优数据。 R-Tuning 构建一个拒绝感知数据集,然后调整模型以避免响应超出其参数知识的问题。
- 实验结果证明了R-Tuning的有效性和泛化能力。我们发现该模型的学习拒绝能力作为一种元技能发挥作用,与任务无关并通过多任务训练得到增强。
拒绝感知数据识别
首先应用预训练的模型来回答中的所有问题,并根据预测和标签之间的比较将问题分成两组。如果模型的预测能和标签匹配,该问题会被放进,否则,被放入。
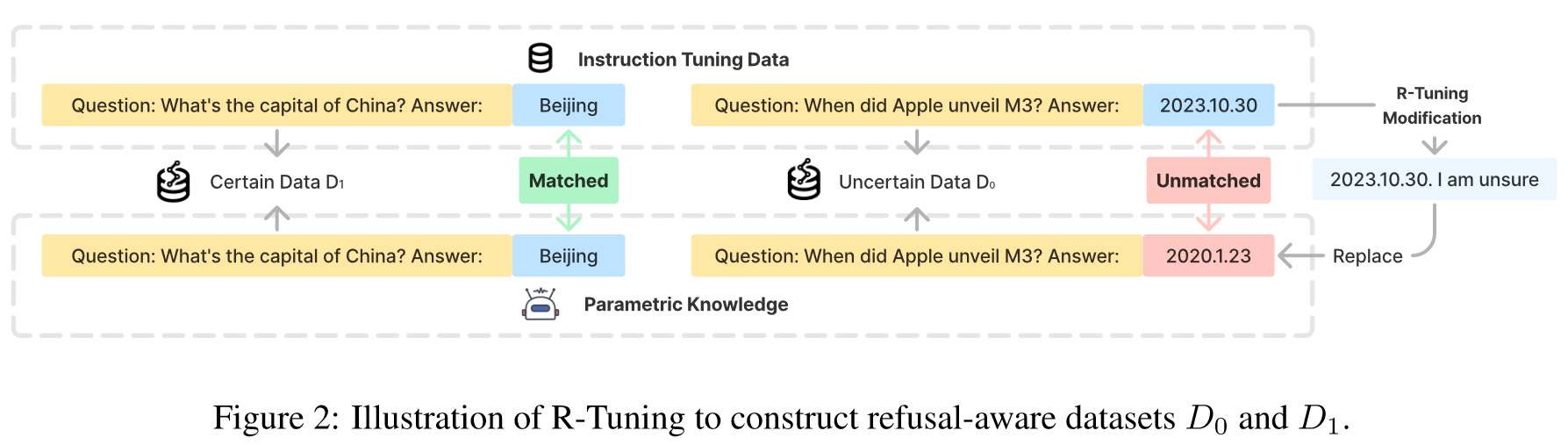
确定数据集是通过在模板后附加"I am sure"来构造的,而不确定数据集是通过在模板后附加"I am not sure"来构造的。我们使用的prompt是Are you sure you accurately answered the question based on your internal knowledge?
因为构造了新式的数据集,微调阶段的如下:
Related Work
Uncertainty Quantification of LLMs 不确定性量化是机器学习中长期存在的问题。在深度学习时代,Guo 等人。 (2017) 首先根据 ECE 指标(预期校准误差)确定深度神经网络缺乏校准的预测置信度(又名预测概率)(Naeini 等人,2015)。陈等人。 (2022)进一步研究预训练大型语言模型的校准问题,并在大型语言模型上观察到相同的错误校准问题。 ActivePrompt (Diao et al., 2023b) 引入了不确定性来选择思想链注释的问题,并证明了其在积极、明智地选择和注释LLMs情境学习最有帮助的范例方面的有效性。
Experiments
Metrics
accuracy:
Average Precision (AP) score:
Datasets
- Question-Answering
- ParaRel
- HotpotQA
- SelfAware
- HaluEval
- FalseQA
- NEC
- Multi-Choice
- MMLU
- WiCE
- FEVER
Baselines
- Pretrain-T:
- 评估原始预训练检查点在整个测试集上的性能。
- Pretrain-W:
- 为了验证自愿回答问题的有效性,我们评估了经过微调的模型愿意回答的测试集上原始预训练检查点的性能。直观上,如果愿意回答的问题在基本模型的知识范围内,那么该基线应该表现良好。
- Vanilla:
- 使用所有问题和真实标签对上的模型进行微调,传统的指令调优方法。
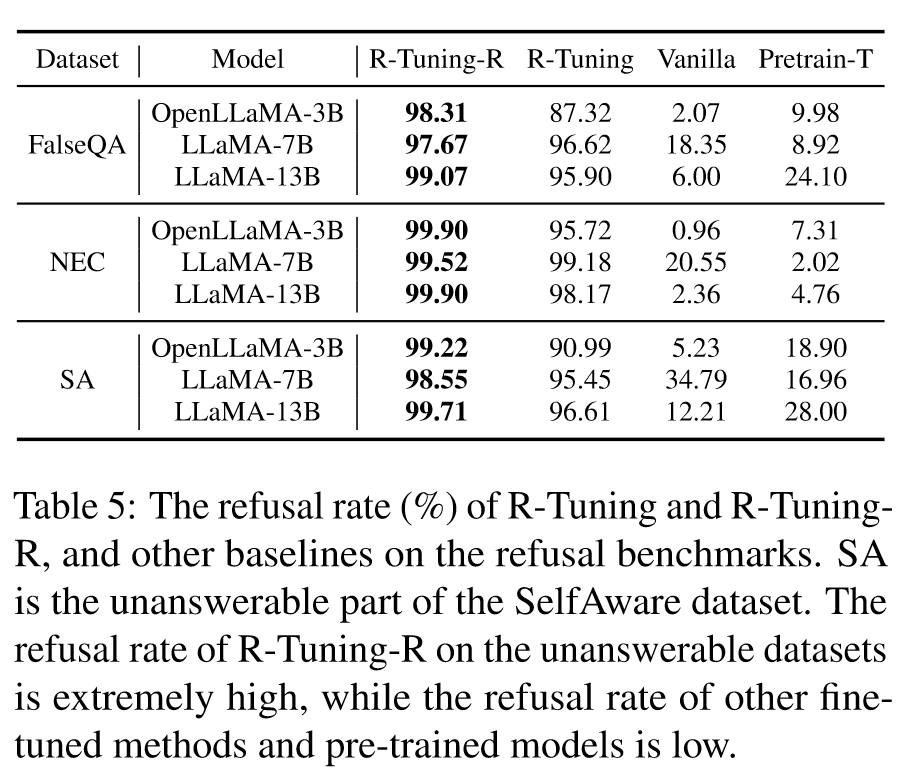
Results
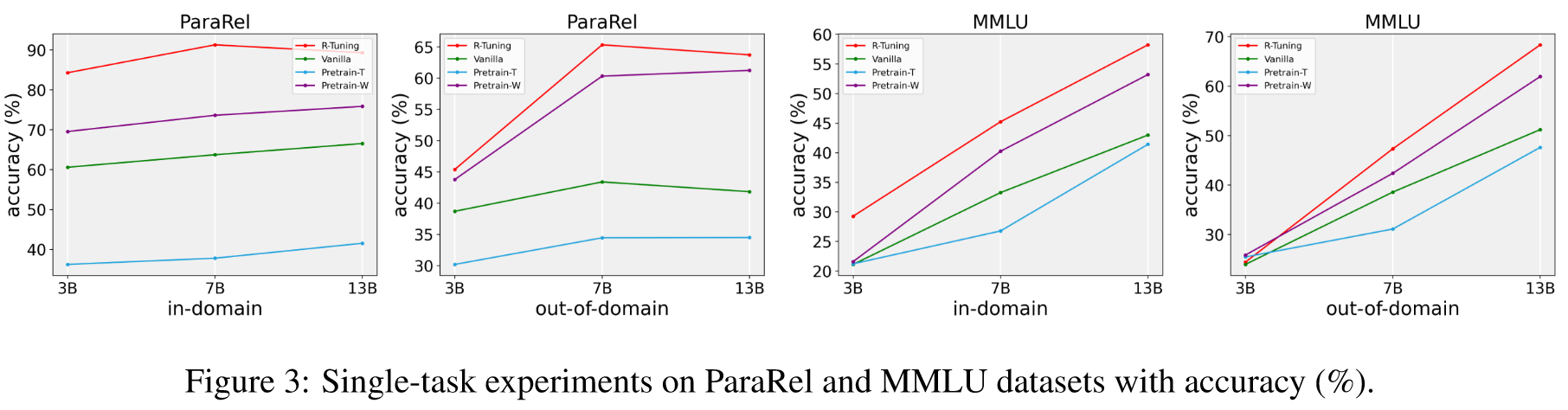
采用无监督识别策略的 R-Tuning (R-Tuning-U) 和采用标签替换的 R-Tuning (R-Tuning-R)。

R-Tuning-R:(1)替换方法丢弃了可用于训练的有价值的标签。 (2) R-Tuning要么只能输出答案,要么只输出确定性,但不能同时响应两者,导致难以同时考虑精度和召回率。
🤖ChatGPT
ChapGPT
论文的创新之处与独特性:
本文提出的“拒绝意识指导调优”(Refusal-Aware Instruction Tuning, 简称R-Tuning)方法在自然语言处理领域中具有显著的创新性和独特性。该方法的核心创新在于解决了大型语言模型(LLMs)在面对超出其参数化知识范畴的问题时倾向于生成虚假事实的问题。R-Tuning通过识别参数化知识与指导调优数据之间的知识差距,然后构建拒绝意识数据,使模型能在超出其参数化知识的问题上选择不回答。这种方法有效提高了模型对已知问题的回答能力,同时减少了对未知问题的误答。此外,实验结果表明,这种拒绝能力是一种元技能,可以推广到其他任务上。
论文中存在的问题及改进建议:
尽管R-Tuning在减少模型的“幻觉”(即错误信息的生成)方面取得了进展,但该方法也存在一些局限性。首先,R-Tuning依赖于对训练数据进行的监督式和非监督式的确定性与不确定性的识别,这可能限制了其在没有清晰标签的真实世界数据集上的应用。其次,R-Tuning在训练过程中可能会因为过度强调拒绝回答而忽略了对模型预测能力的进一步提升。针对这些问题,可以考虑开发更加精细化的不确定性评估机制,以及平衡拒绝答案与提高预测准确性之间的关系。
基于论文的内容和研究结果,提出的创新点或研究路径:
a. 发展更高级的不确定性评估算法:设计算法来更精确地评估模型对于特定问题的不确定性,可以提高R-Tuning方法的效能。
b. 自适应学习机制:开发一种机制,使模型能够根据其在特定任务上的表现自适应地调整拒绝回答的阈值。
c. 多模态拒绝意识模型:扩展R-Tuning方法到多模态领域,例如结合文本、图像和音频数据的处理,来增强模型在更广泛应用场景下的拒绝能力。
为新的研究路径制定的研究方案:
a. 对于更高级的不确定性评估算法,研究可以从现有不确定性评估技术出发,如贝叶斯方法和深度学习的集成方法,以提高评估的准确性和效率。预期成果是一个能更准确识别和处理未知问题的语言模型。
b. 对于自适应学习机制,可以采用强化学习或元学习方法,使模型在不断的互动过程中学会优化其拒绝答案的策略。这样的研究可能会导致更智能和适应性更强的语言模型。
c. 在多模态拒绝意识模型的研究中,可以探索将R-Tuning方法与图像识别、语音处理等技术结合,以实现对多种数据类型的综合理解和处理。这项研究的目标是创建一个能够在更复杂、多元化的数据输入情况下做出准确反应的模型。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!