目录
Resource Info Paper http://arxiv.org/abs/2312.15685 Code & Data https://github.com/hkust-nlp/deita Public ICLR Date 2024.04.21
Summary Overview
最近的研究表明数据工程在指令调整中的关键作用——如果选择得当,只需有限的数据即可实现卓越的性能。然而,对于什么是好的指令调整数据以进行对齐,以及我们应该如何自动有效地选择数据,我们仍然缺乏原则性的理解。在这项工作中,我们深入研究了用于对齐的自动数据选择策略。我们从对照研究开始,跨三个维度测量数据:复杂性、质量和多样性,同时我们检查现有方法并引入增强数据测量的新技术。随后,我们提出了一个简单的策略来根据测量选择数据样本。我们提出了 DEITA(Data-Efficient Instruction Tuning for Alignment)。
Main Content
指令调优或监督微调 (SFT) 使用带注释的指令数据细化预训练模型,通常作为 RLHF 之前的基础步骤,以促进模型的初始对齐。
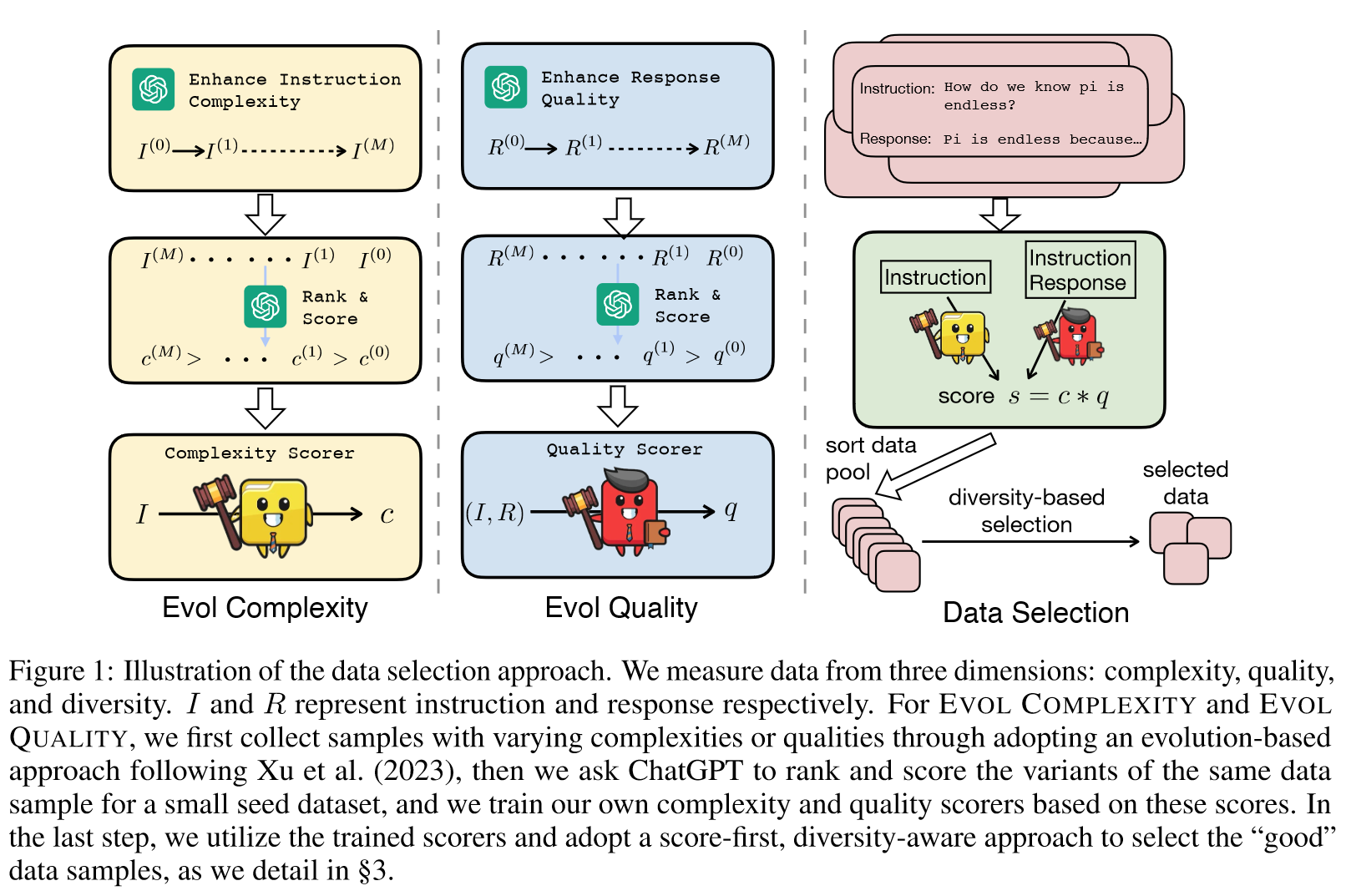
我们的数据选择策略简单而有效,为数据高效的指令调整范例铺平了道路——可以自动选择更少的训练样本,从而获得与在更大的数据集上训练的模型相当甚至超越的性能。
THE DATA SELECTION PROBLEM
形式上,给定一个大型指令调整数据池,,其中表示指令-响应对形式的单个数据样本。我们的目标是使用表示的选择策略从中选择大小为的子集。是子集大小,与指令调整中消耗的计算量成比例相关,因此我们也将称为数据预算。通常,我们定义一个指标来评估数据并根据该指标选择数据样本。将指令调优后的对齐性能表示为,数据预算为的最优数据选择策略满足
和
FROM THE COMPLEXITY PERSPECTIVE - EVOL COMPLEXITY
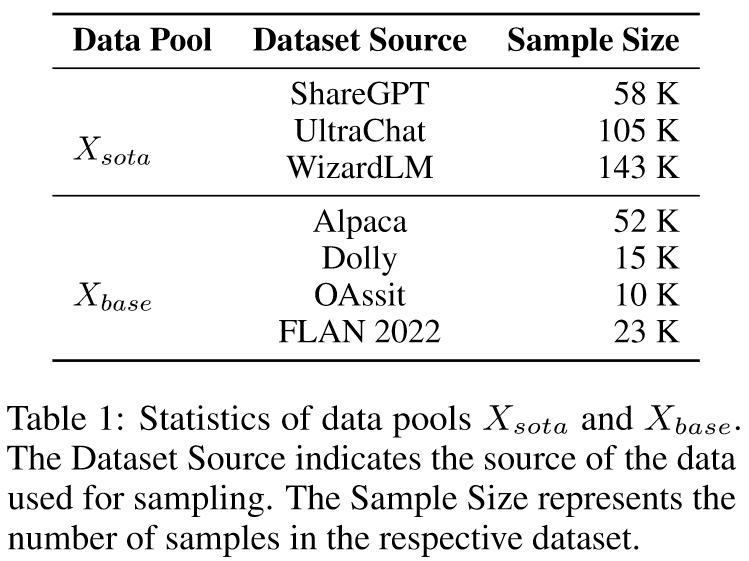
Baselines: Random Selection, Instruction Length, Perplexity, Direct Scoring, Instruction Node, Instag Complexity, IFD
Evol Complexity: 受到Evol-Instruct的启发,提出EVOL COMPLEXTITY,一种基于进化的复杂性度量。首先收集一个小规模种子数据集,,表示指令-响应对。对于每个指令样本,我们使用Xu等人提出的In-Depth Evolving Prompt。通过增加约束、深化、具体化和增加推理步骤等技术来增强复杂性。经过次迭代后,我们获得了的一组不同复杂度的指令,。这里将设置为5,总共获得6中变化。
如图 1 左侧所示,然后我们要求 ChatGPT 对这 6 个样本进行排序和评分(附录 E.2 中提示),得到指令对应的复杂度分数 c。我们强调,与直接评分不同,我们在一个提示中给 ChatGPT 所有 6 个样本 - 这些样本代表同一原始样本的不同进化阶段,这样的评分方案有助于 ChatGPT 捕获它们之间微小的复杂性差异,从而产生复杂性分数以实现样本之间更细粒度的复杂性区分。我们发现这一点至关重要,否则,ChatGPT 倾向于为大多数示例分配相似的分数,如附录 B 中所示。在小种子数据集上获得 ChatGPT 分数后,我们使用这些分数来训练 LLaMA-1 7B 模型进行预测给定输入指令的复杂性分数。在多回合对话的情况下,我们对每一回合单独评分,并将它们的总和作为最终分数。在本文的实验中,我们使用从 Alpaca 数据集(Taori et al., 2023)中随机采样的 2K 个示例作为种子数据集。
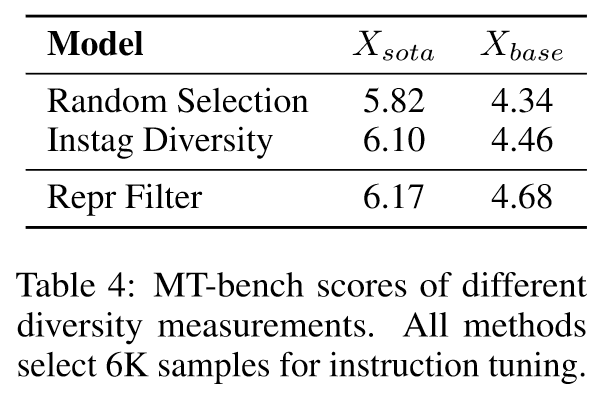
表 2 展示了使用各种复杂性指标从 Xsota 和 Xbase 选择 6K 数据样本的结果。我们的 Evol-Complexity 指标可在 MT-bench 上实现最佳对齐性能。我们观察到,虽然 Instag Complexity 在 Xsota 上表现良好,但它在 Xbase 上的性能仅比 Random Selection 稍好一些。相比之下,EVOL COMPLEXITY 在两个数据集上都实现了卓越的性能,表明在不同数据集池上具有很强的鲁棒性。此外,与严重依赖 ChatGPT 注释的方法(例如直接评分和指令节点)相比,我们的方法具有显着的优势。实验结果还表明,指令长度并不是对齐首选数据的良好指标。有趣的是,困惑度(一种直观的复杂性衡量标准)产生的结果比随机选择基线差得多。通过进一步的调查,我们发现具有大困惑度的样本通常表现出非常短的响应。
FROM THE QUALITY PERSPECTIVE - EVOL QUALITY
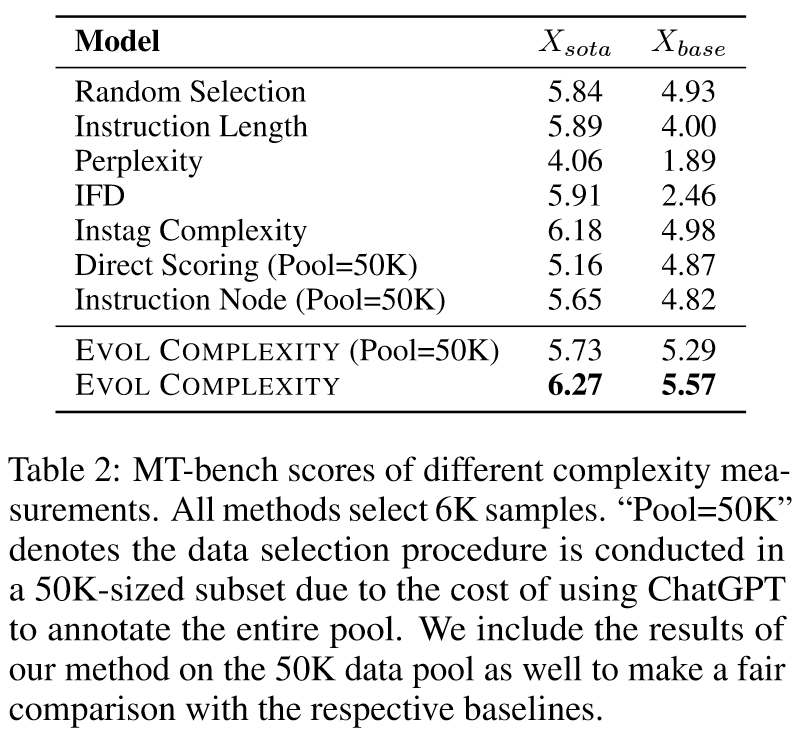
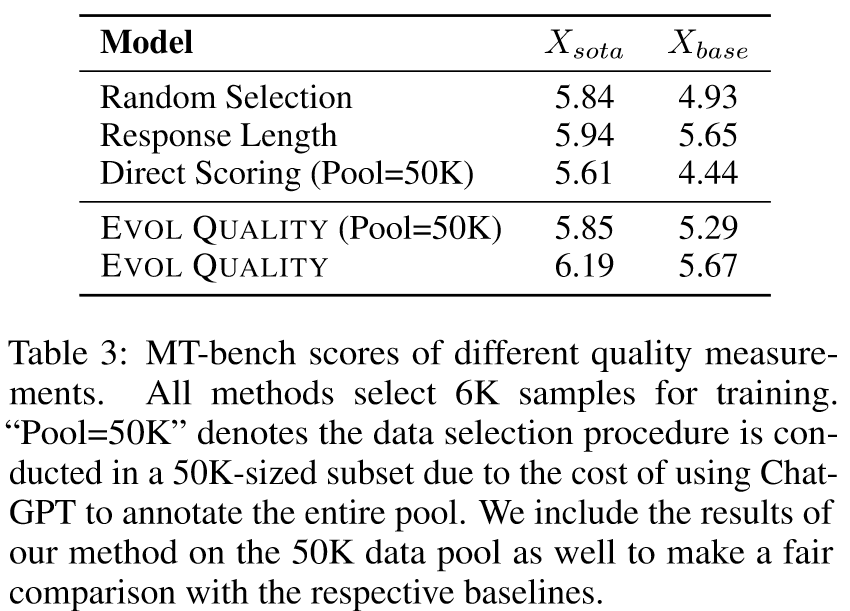
Baselines: Random Selection,Response Length,Direct Scoring
Evol Quality: 以类似于EVOL COMPLEXITY的方式,我们引入EVOL QUALITY来增强质量测量的辨别力。对于给定的数据样本,我们提示ChatGPT以进化的方式提升响应的质量。这主要涉及增强帮助性、增强相关性、丰富深度、培养创造力和提供额外细节。经过次迭代后,对于相同的指令,我们获得了一组的各种质量响应,表示为。与EVOL COMPLEXITY类似,我们将设置为5。
表3给出了分别从Xsota和Xbase中选择前6K数据的实验结果。所提出的 EVOL QUALITY 方法始终表现出卓越的对准性能。我们注意到,具有较高质量方差的池 Xbase 更容易受到质量指标的影响,这是直观的,因为此类池中存在许多低质量的示例,并且会严重损害性能。这一结果意味着质量是一个需要考虑的必要维度,尤其是在处理包含大量低质量示例的数据池时。我们还观察到响应长度与最终比对性能正相关,但对于已经高质量的数据集(例如 Xsota),其影响并不显着
FROM THE DIVERSITY PERSPECTIVE - AN EMBEDDING-BASED APPROACH

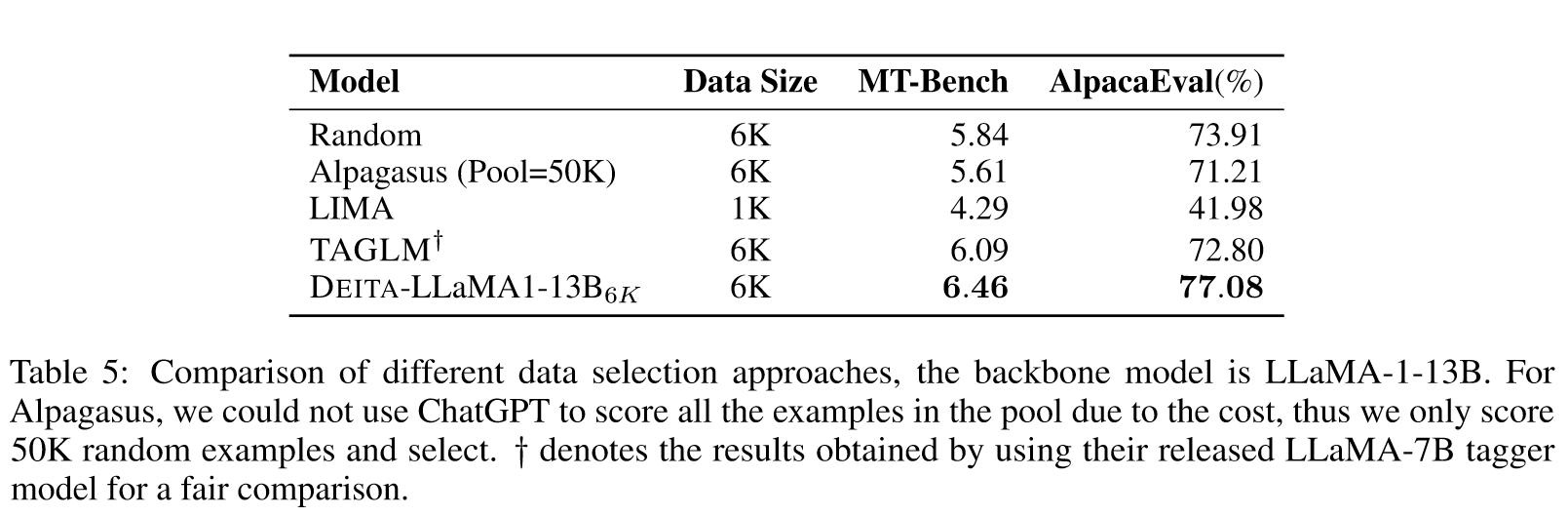
 在本文中,我们彻底研究了什么是适合对齐的良好数据的问题。我们的研究包括三项对照研究,涵盖三个维度:复杂性、质量和多样性。在这些研究中,我们提出了自动数据选择的新方法,并在选定的数据样本上训练我们的模型 DEITA。实验结果表明,DEITA 能够在 10 倍训练样本的情况下实现优于或媲美最先进开源模型的性能。我们向其他人发布我们选择的数据,以便更有效地调整模型。
在本文中,我们彻底研究了什么是适合对齐的良好数据的问题。我们的研究包括三项对照研究,涵盖三个维度:复杂性、质量和多样性。在这些研究中,我们提出了自动数据选择的新方法,并在选定的数据样本上训练我们的模型 DEITA。实验结果表明,DEITA 能够在 10 倍训练样本的情况下实现优于或媲美最先进开源模型的性能。我们向其他人发布我们选择的数据,以便更有效地调整模型。
Experiments
Results
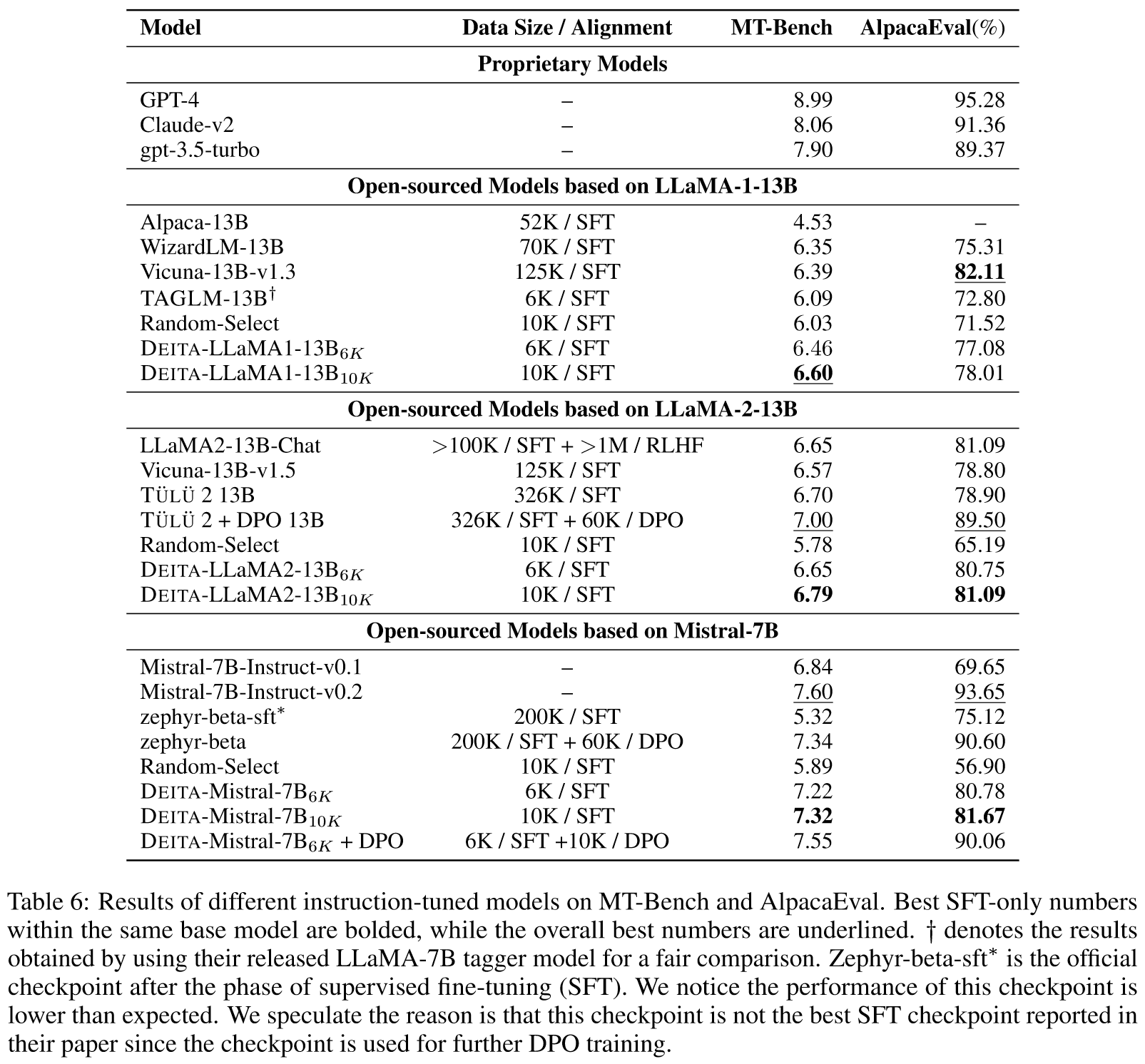
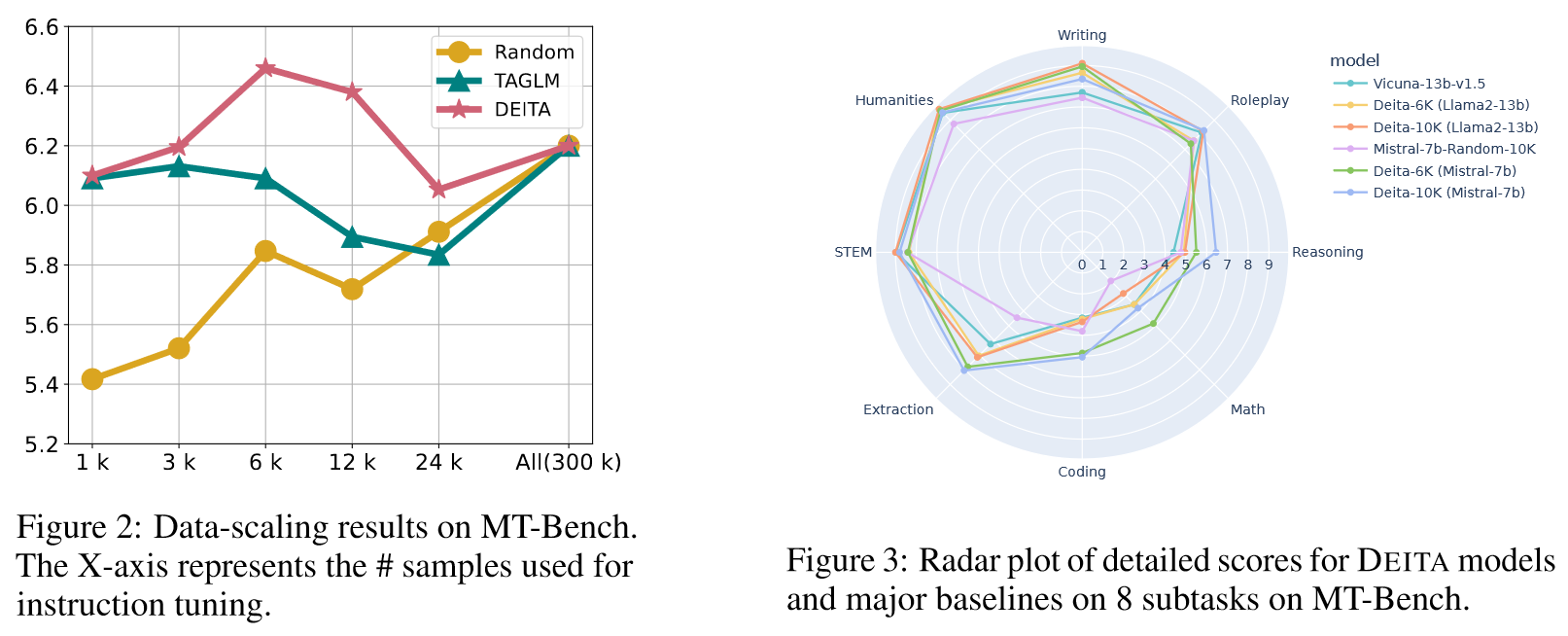
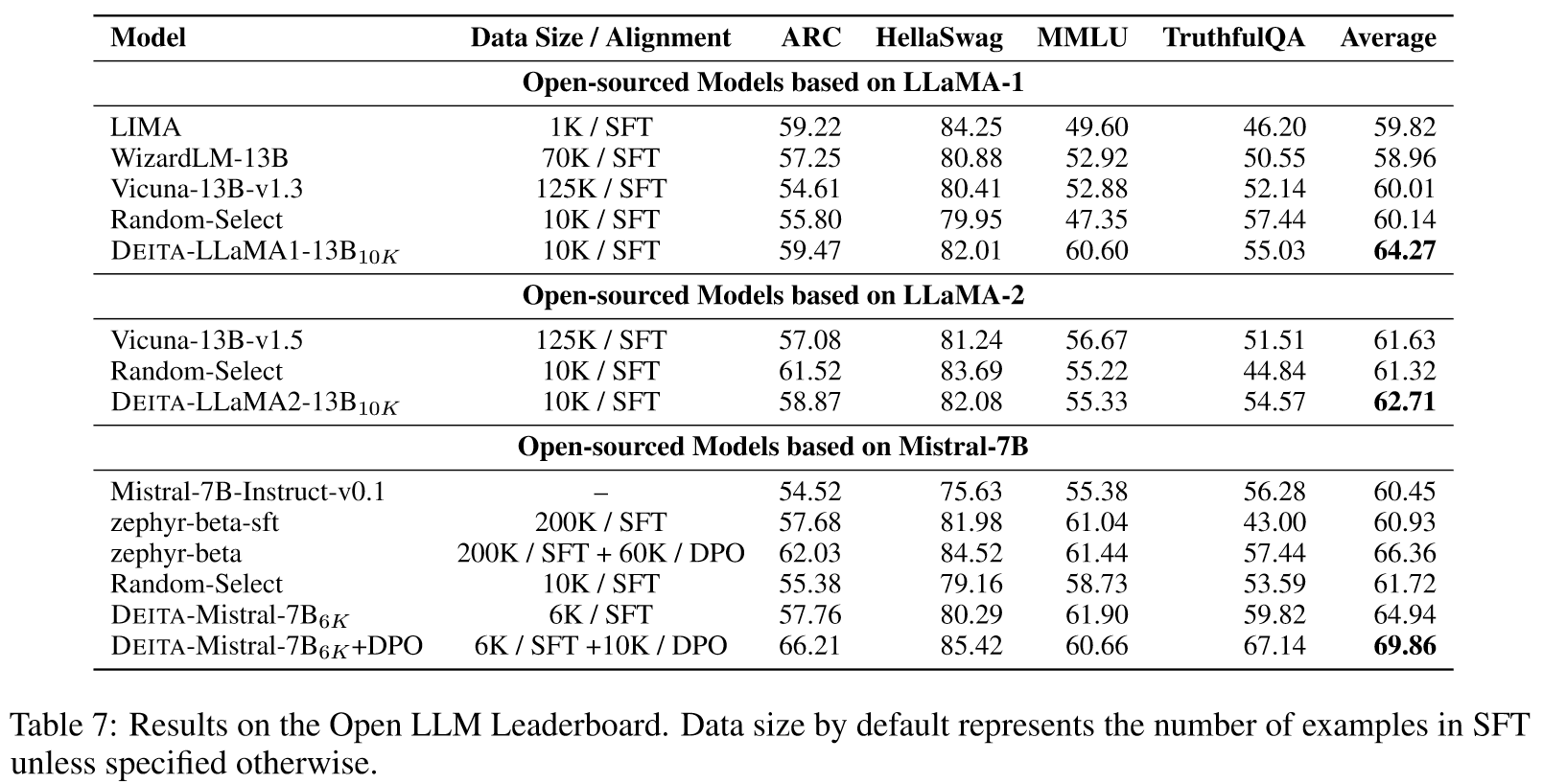 Data Scaling:
Data Scaling:
Case Study
🤖ChatGPT
ChapGPT
论文的创新之处与独特性:
论文探索了如何在指令调整(instruction tuning)过程中自动选择数据,以提高大型语言模型(LLMs)与人类偏好的对齐质量。主要创新包括:
- 三维数据评估框架:首次提出通过复杂性(complexity)、质量(quality)、和多样性(diversity)三个维度来评估数据集,这为数据选择提供了新的理论依据。
- 自动数据选择策略DEITA:开发了一种新的数据效率指令调整方法(Data-Efficient Instruction Tuning for Alignment, DEITA),该方法使用远少于基线模型的数据样本数目(6K vs. 60K),但能达到相当甚至更优的性能。
- 实证验证:通过与现有最先进模型的比较,实证显示DEITA模型在多个评价指标上具有竞争力,特别是在数据效率上的优势明显。
论文中存在的问题及改进建议:
- 数据维度的独立性:论文中虽然提出了三维评估数据的方法,但并未充分探讨这些维度之间的相互影响及其独立性。建议进一步研究这些维度的关联性,以更精确地指导数据选择。
- 样本多样性的实证研究不足:虽然论文提到了多样性在数据选择中的重要性,但在实验设计中缺少对多样性本身如何影响模型性能的直接测试。可以设计实验来验证不同多样性级别对性能的具体影响。
- 更广泛的实验验证:DEITA方法主要与开源对齐模型进行了比较,可能缺乏与商业模型或不同类型的数据集进行比较的视角。建议在未来的研究中包括更多种类的数据集和对比模型,以全面验证方法的通用性和鲁棒性。
基于论文的内容和研究结果,提出的创新点或研究路径:
- 交叉维度数据优化:开发一种新的数据选择框架,该框架能够同时考虑复杂性、质量和多样性的交叉影响,使用机器学习算法来预测不同数据维度组合的最优配置。
- 动态数据选择机制:构建一个动态数据选择机制,能够根据模型在训练过程中的表现逐步调整数据选择的策略,实现更精细化的训练过程控制。
- 多模态数据对齐优化:研究如何将DEITA框架扩展到多模态数据(例如文本与图像),探索多模态场景下的数据选择和模型对齐问题。
为新的研究路径制定的研究方案:
-
交叉维度数据优化研究方案:
- 研究方法:使用统计和机器学习方法来分析不同数据维度的相互作用,并建立预测模型。
- 步骤:首先通过实验确定各维度的独立影响,然后构建多元回归模型来预测组合影响,最后通过交叉验证优化模型参数。
- 期望成果:发展出一种新的理论模型,能够指导实际的数据选择工作,优化模型的数据效率和性能。
-
动态数据选择机制研究方案:
- 研究方法:实现一个基于反馈循环的动态调整框架,利用实时性能反馈调整数据选择策略。
- 步骤:设计实验以收集中间训练结果,使用这些数据反馈调整数据选择算法,逐步优化数据集的结构。
- 期望成果:开发出一个能够自适应调整的数据选择系统,显著提高模型训练的效率和效果。
-
多模态数据对齐优化研究方案:
- 研究方法:探索和实现多模态数据集的同步处理和优化策略。
- 步骤:首先标定不同模态的数据特征和性能影响,然后开发同步处理算法,最后通过模拟实验测试算法效果。
- 期望成果:形成一套多模态数据处理的新方法,能够有效提升不同数据类型的整合和模型训练的对齐质量。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!