目录
Resource Info Paper https://arxiv.org/abs/2310.11248 Code & Data https://crosscodeeval.github.io/ Public Neurips Date 2024.05.05
Summary Overview
近年来,代码完成模型取得了重大进展,但当前流行的评估数据集(例如 HumanEval 和 MBPP)主要关注单个文件中的代码完成任务。这种过于简化的设置无法代表现实世界的软件开发场景,其中存储库跨越具有大量跨文件依赖项的多个文件,并且通常需要访问和理解跨文件上下文才能正确完成代码。
为了填补这一空白,我们提出了 CROSSCODEEVAL,这是一种多样化、多语言的代码完成基准,需要深入的跨文件上下文理解才能准确地完成代码。 CROSSCODEEVAL 建立在一组多样化的现实世界、开源、许可许可的存储库上,采用四种流行的编程语言:Python、Java、TypeScript 和 C#。为了创建严格需要跨文件上下文才能准确完成的示例,我们提出了一种简单而有效的基于静态分析的方法来精确定位当前文件中跨文件上下文的使用。
对 CodeGen 和 StarCoder 等最先进的代码语言模型的大量实验表明,当相关的跨文件上下文不存在时,CROSSCODEEVAL 极具挑战性,并且在将这些上下文添加到提示中时,我们看到了明显的改进。然而,尽管有这些改进,即使是性能最高的模型,性能的巅峰仍然没有达到,这表明 CROSSCODEEVAL 也能够评估模型利用广泛上下文来更好地完成代码的能力。最后,我们对检索跨文件上下文的各种方法进行了基准测试,并表明 CROSSCODEEVAL 也可用于衡量代码检索器的能力。
Main Content

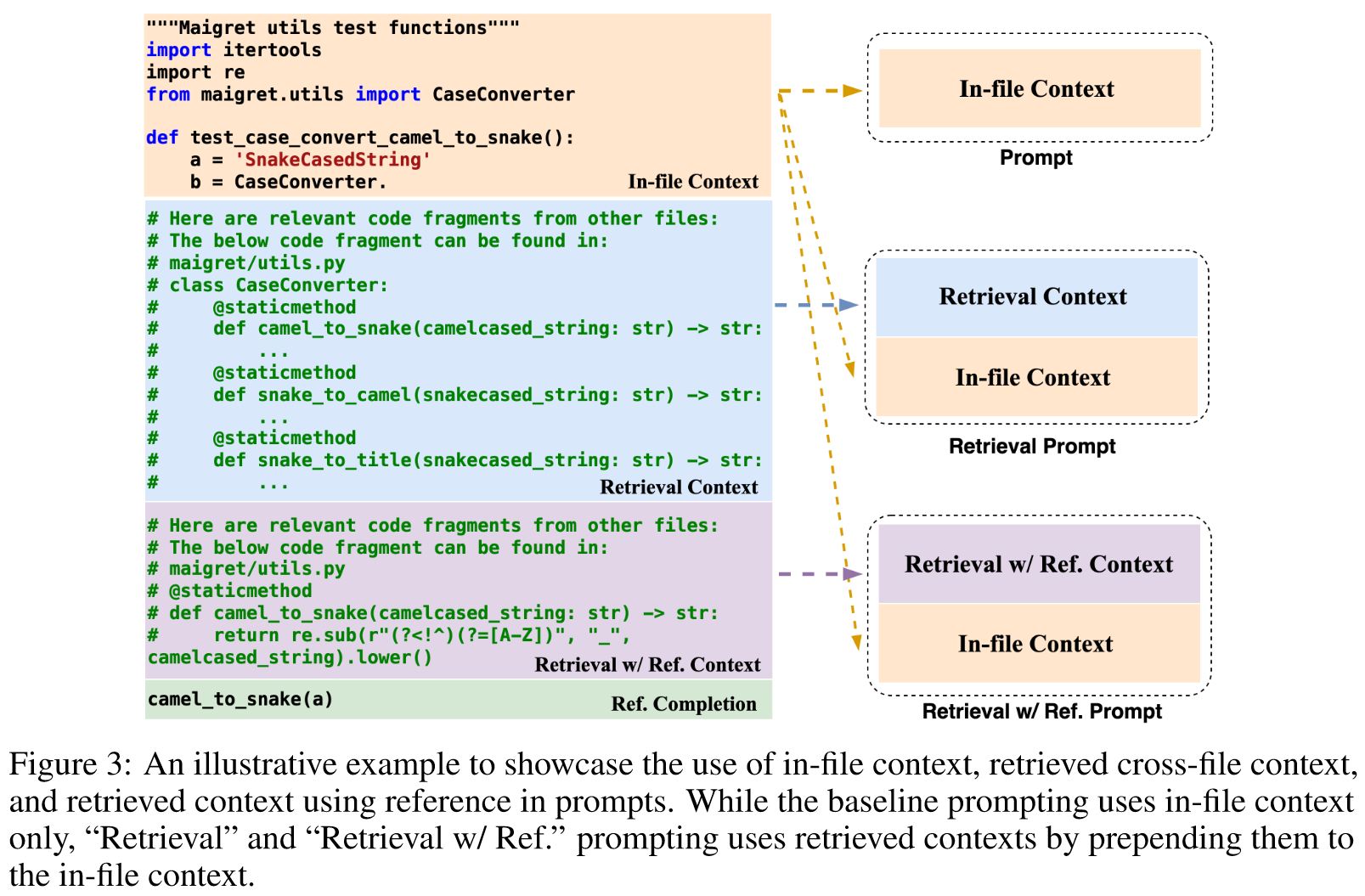
与仅使用当前文件中的上下文即可预测正确答案的现有数据集不同,CROSSCODEEVAL 严格要求跨文件上下文才能正确完成缺失的代码。

上图展示了如何构造数据,首先将传入的一个class在此文件中写为空类,找出其中的undefined name即是其他依赖文件所定义的函数,此时可以在此建立数据。
Data Collection
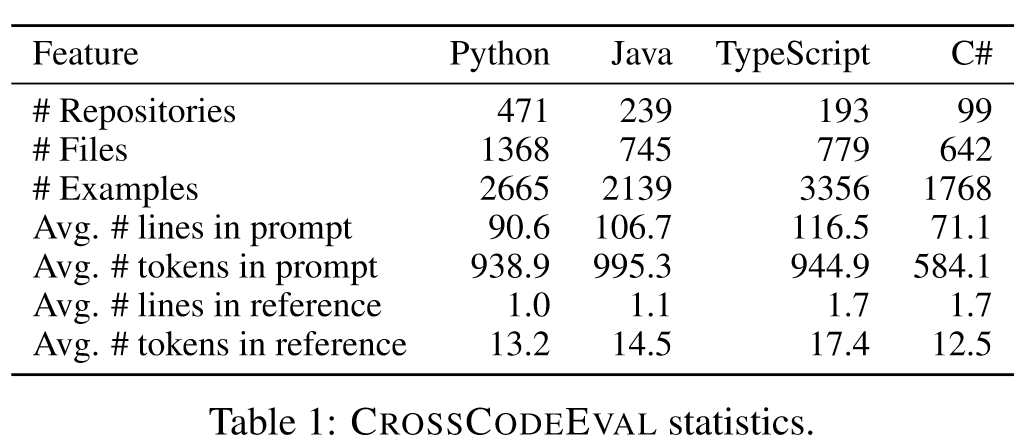
我们从 GitHub 收集许可的存储库。为了减轻潜在的数据泄漏问题,我们专注于最近创建的存储库,而不是分叉。具体来说,我们收集了 2023 年 3 月 5 日至 2023 年 9 月 1 日期间创建的存储库。该时间跨度确保收集到足够的数据,并且与 2023 年中期之前发布的许多现有代码 LM 的训练数据不重叠,无论数据是否公开。我们将存储库限制为包含我们研究的四种语言,并且仅保留压缩文件大小 < 1MB 且星数 >= 3 的存储库。然后,我们过滤掉源代码文件少于 10 个或超过 50 个的存储库。最后,我们删除至少一个源代码文件与常用 Stack (Kocetkov et al., 2022) 数据集中的代码文件之一完全匹配的存储库。结果,我们分别获得了 471、239、193 和 99 个存储库。
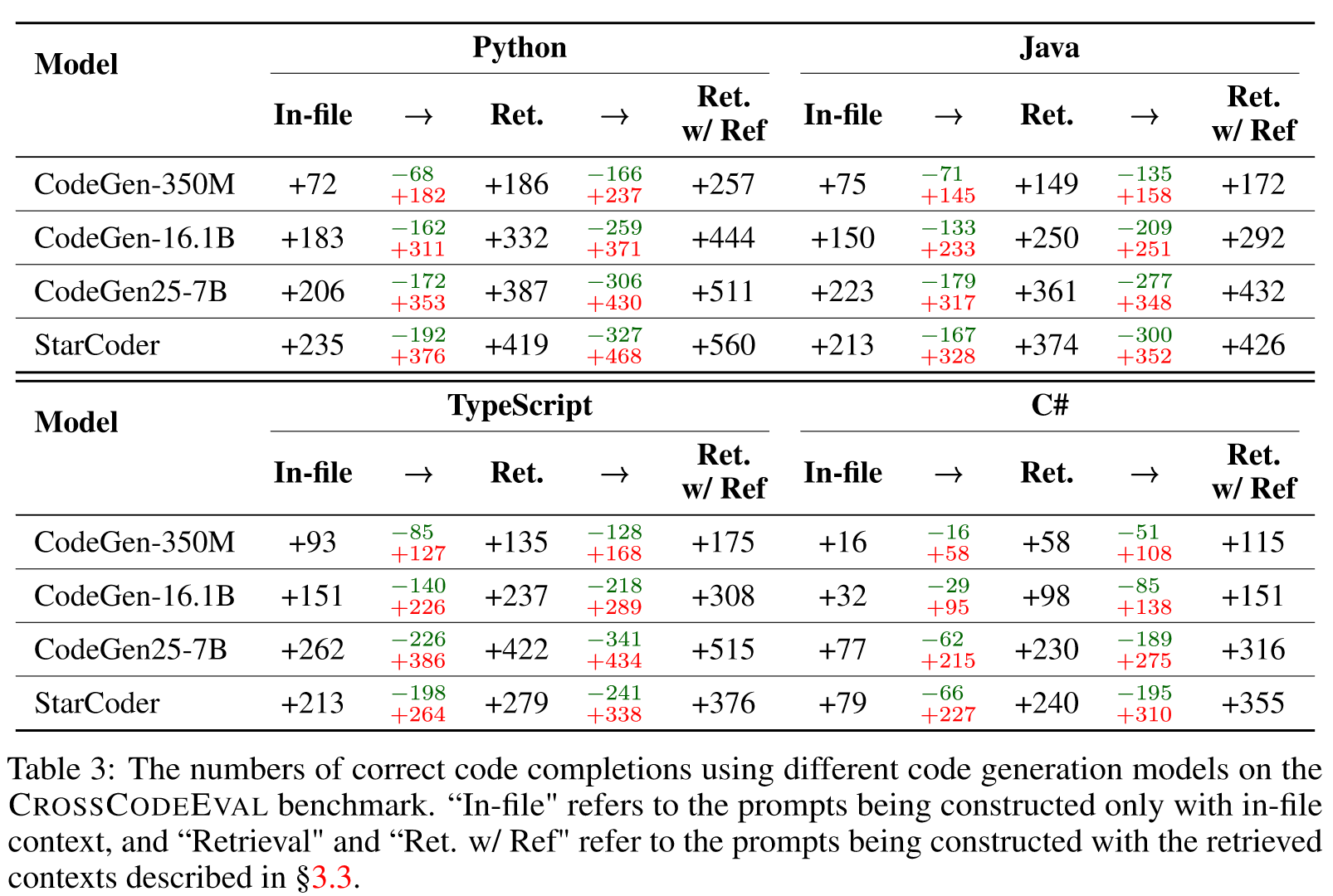
我们推出了 CROSSCODEEVAL,这是一种用于跨文件代码完成的多样化多语言基准。 CROSSCODEEVAL 需要跨文件上下文理解才能准确地完成代码。我们使用基于静态分析的方法来识别代码中的跨文件上下文用法,并采取措施确保数据集具有高质量,并且与流行代码 LM 的预训练数据集相比,数据泄漏最少。我们对流行的代码语言模型进行了实验,结果表明,包含跨文件上下文可以显着提高代码完成的准确性,这表明 CROSSCODEEVAL 是评估跨文件代码完成功能的有效基准。此外,即使是具有最佳检索方法的最佳模型,仍然存在很大的改进空间,这凸显了在利用广泛的上下文进行代码补全和更好的代码检索器方面需要进一步进步。在这两个方向上,CROSSCODEEVAL 都是一个关键基准。我们设想 CROSSCODEEVAL 可以填补评估需要跨文件上下文的代码完成的空白,并促进未来在这个方向上各个维度的研究。
Experiments
Metrics
-
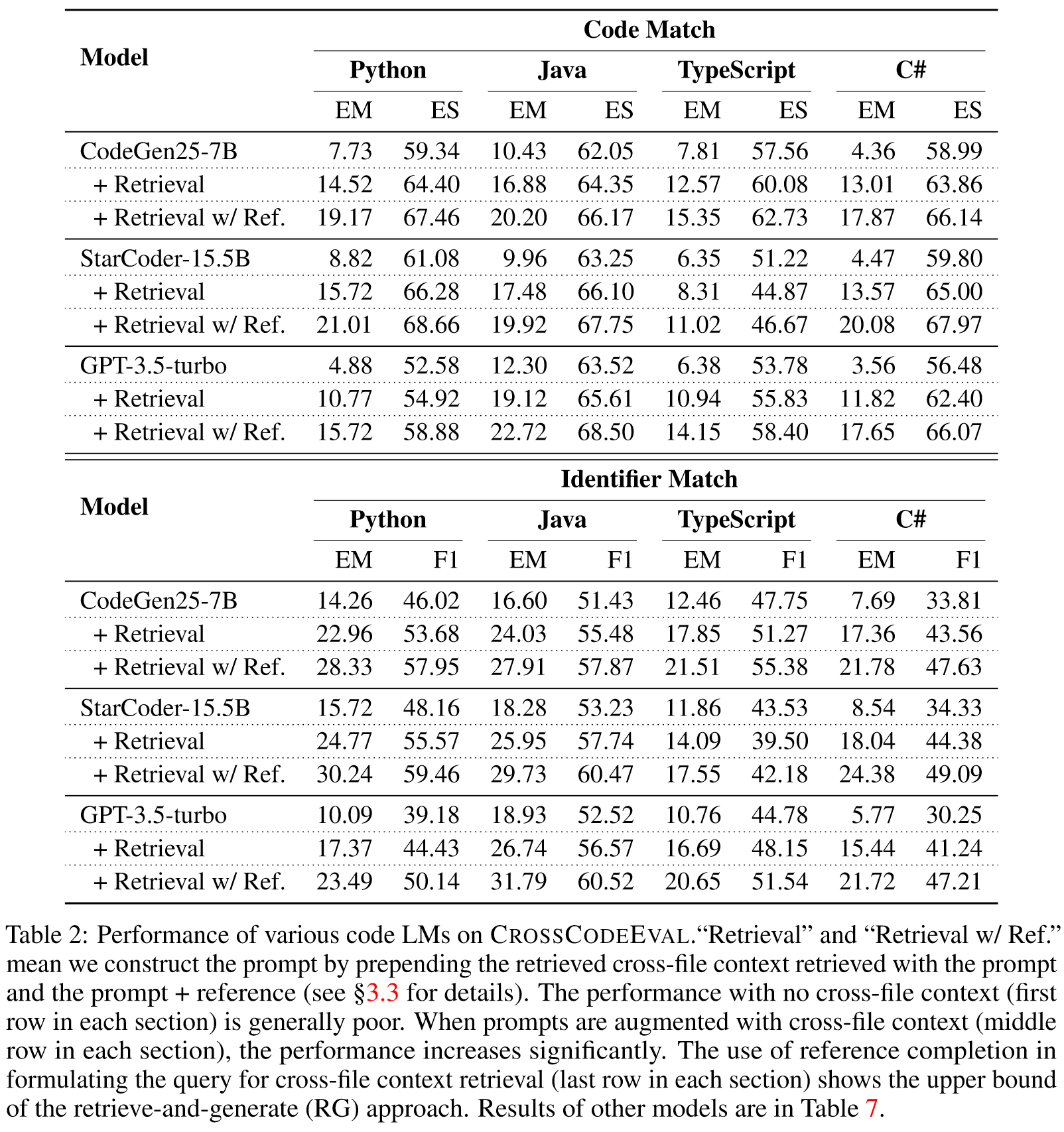
Code Match: 代码匹配指标直接将生成的代码与参考进行比较,并使用精确匹配 (EM) 和编辑相似度 (ES) 进行测量。这些指标有助于评估代码完成过程的整体准确性,同时考虑标识符、关键字、运算符、分隔符和文字等元素。
-
Indetifier Match: 该指标评估模型预测正确应用程序编程接口 (API) 的能力。为了执行此评估,我们首先解析代码并从模型预测和参考中提取标识符,从而产生两个有序的标识符列表。然后,我们将预测的标识符与参考进行比较,并以 EM 和 F1 分数报告结果。
Models
- CodeGen
- StarCoder
- GPT-3.5-turbo
Baselines
- Only In-File Context: 在标准实践中,通过考虑提供的代码上下文,利用预训练的语言模型以零样本的方式执行代码完成。根据实践,我们使用代码 LM (3.1) 进行实验,其中为它们提供了当前文件的代码上下文。如图 3 所示,基线提示仅包含文件内上下文。
- Retreived Cross-file Context: 受到最近提出的用于存储库级代码补全的检索并生成 (RG) 框架(Zhang 等人,2023)的有效性的启发,我们采用它进行跨文件上下文检索。8 在 RG 框架中,检索数据库是通过迭代扫描存储库中的文件并提取连续 M 行(在我们所有的实验中,M = 10)的非重叠代码片段来构建,这些代码片段是跨文件上下文检索的候选者。检索查询是使用文件内上下文的最后 N 行(我们设置 N = 10)构建的。我们使用 BM25 (Robertson et al., 2009) 来计算查询和候选(跨文件上下文块)之间的相似度,并使用前 5 个相似的代码片段作为跨文件上下文,请参阅“检索上下文”在图 3 中。我们认为此类上下文最多有 512 个 BPE 令牌,其余令牌将被截断,图 3 说明了检索到的上下文以及模型完成的相应提示。查询后,RG 框架成功检索了实用程序的另一个文件中的 CaseConverter 的类定义,我们进一步将类定义作为代码注释包装到模板中,并将其用作跨文件上下文。将检索到的上下文添加到文件内上下文。
- Retrieval with Reference: 为了量化 RG 框架检索的跨文件上下文的上限影响,我们设计了“参考检索”进行比较。在这种设置中,我们不仅使用文件内上下文(如标准检索设置),还使用具体来说,查询是通过使用文件内上下文和引用完成的串联的最后 N 行来构造的,而不是仅在标准检索设置中使用文件内上下文。我们将检索到的上下文(即“Retrieval w/ Ref. Context”)添加到文件内上下文中以构造此设置的提示。
Results
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: CROSSCODEEVAL的创新之处在于提出了一个跨文件的代码补全评测基准,针对多语言环境下代码的生成和完善提供了评估。这一基准通过静态分析方法自动识别需要跨文件上下文的代码片段,从而模拟现实软件开发中的复杂依赖关系。该研究强调了在没有跨文件上下文的情况下,即使是先进的代码语言模型也难以实现高效的代码补全,而引入这种上下文则显著提高了模型的表现。这一发现对于理解和改进代码自动补全工具具有重要的理论价值和实践意义。
-
论文中存在的问题及改进建议: 尽管CROSSCODEEVAL在跨文件代码补全的评估上具有创新性,但论文中也存在一些潜在问题。首先,尽管涵盖了四种编程语言,但可能不足以全面代表所有编程语境,尤其是在不同领域和架构下的具体需求。此外,该研究主要关注语法和静态分析,而在语义理解方面的探讨较少,这可能限制了模型在理解复杂代码逻辑方面的能力。针对这些问题,建议在未来的工作中扩展更多的编程语言和编码风格,同时增加对代码的语义分析和理解,以更全面地评估和提高代码补全模型的性能。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 多维度代码语义理解:开发能够深入理解代码语义的模型,如通过增强模型的能力来推断代码中的设计模式和架构意图。
- 实时代码补全系统:研究在实际编程环境中动态引入跨文件上下文的实时代码补全系统,实现更加智能和适应性强的编程辅助。
- 代码生成与修复的融合:探索代码补全技术与自动程序修复(APR)技术的结合,用以提升代码质量和安全性。
-
为新的研究路径制定的研究方案:
-
多维度代码语义理解:
- 研究方法:利用深度学习与图网络,结合代码的静态结构和动态行为数据,训练模型以识别和理解复杂代码结构。
- 步骤:(1)收集和标注大规模的代码库,包括代码的设计模式和架构信息;(2)设计并实现一个混合模型,结合图网络分析代码间关系,深度学习理解代码功能;(3)在多种语言和框架下验证模型效果。
- 期望成果:能够自动识别代码中的设计模式,预测潜在的错误和改进点,提高代码质量和开发效率。
-
实时代码补全系统:
- 研究方法:开发一个基于插件的实时代码补全工具,该工具能够根据开发环境动态调整推荐策略。
- 步骤:(1)分析现有IDE和编程环境,集成跨文件分析工具;(2)实现一个实验原型,支持动态代码分析和推荐;(3)通过用户研究,优化系统性能和用户体验。
- 期望成果:开发出一套完善的实时代码补全系统,能够在多种编程环境中提供准确的代码补全建议,提升开发效率和代码质量。
-
代码生成与修复的融合:
- 研究方法:研究代码自动生成和修复的交叉点,开发一种新的混合模型,能同时进行代码生成和错误修复。
- 步骤:(1)收集和分析存在缺陷的代码库,标注修复前后的变化;(2)设计一个融合模型,结合生成模型和修复模型的特点,进行联合训练;(3)在真实世界的代码库上进行测试和优化。
- 期望成果:实现一个高效的代码自动生成与修复系统,能够减少开发中的错误,提高代码的可靠性和安全性。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!