目录
Resource Info Paper https://arxiv.org/abs/2501.12570 Code & Data https://github.com/StarDewXXX/O1-Pruner Public arXiv Date 2025.03.18
Summary Overview
本文针对于当前 Reasoning LLM 出现的 Long-CoT 问题进行改进,提出来 Length Harmonizing Fine-Tuning (O1-Pruner) 的方法,使用 RL 的方法微调模型,使其输出的 CoT 长度降低。同时文章中还注意到一个现象,并非是越长的 CoT 能获得越好的效果。
Main Content
我们观察到,漫长的推理LLM中的推理过程经常表现出重要的裁员,从而导致计算资源的使用效率低下。我们的方法引入了 Length-Harmonizing Reward,该奖励明确地奖励了更短的解决方案,同时惩罚准确性退化。
A Simple Experiment:
我们从 MATH 测试集中随机选择了64个问题(对于QWQ-32B,我们首先过滤了 hard samples)。对于每个问题,我们使用 MARCO-O1 和 QWQ-32B 生成了512个解决方案。对于每个问题,我们将所有候选解决方案分为4个间隔,并随后计算每个间隔的准确率。
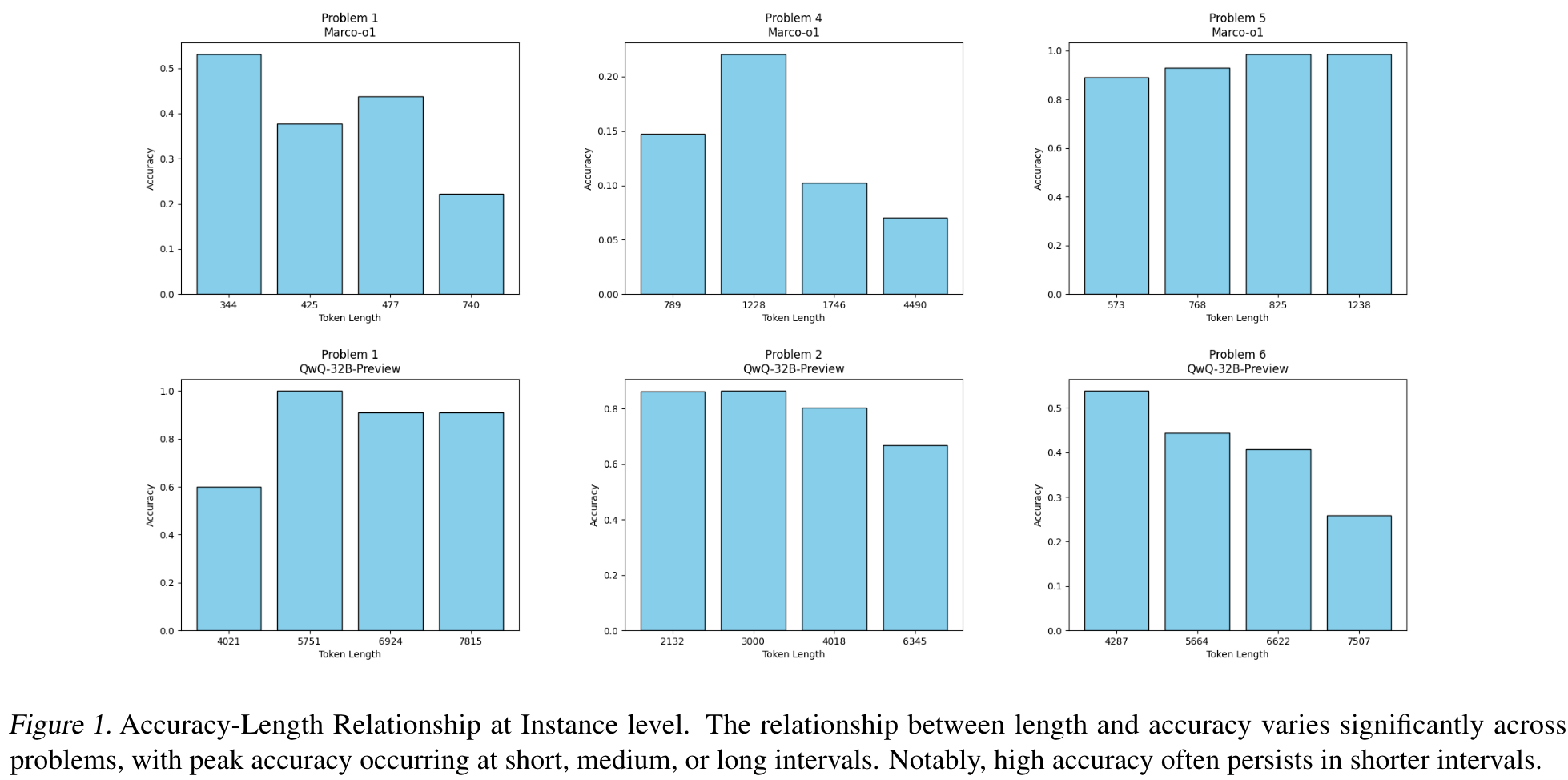

因此,我们可以得出结论,在推理过程中,长期思考模型表现出长度不和谐的现象,这在推理阶段导致了冗余的计算开销。这种推理的冗余性可以得到缓解,因为即使在较短的长度下仍保持高精度。
Length-Harmonizing Fine-Tuning (O1-Pruner)
To address this, we propose an optimizatoin objective that ensures no degradation in accuracy while tackling the issue from two perspectives. First, at the overall level, we aim to shorten the reasoning paths. Second, we encourage the model to output shorter answers for simpler problems, while for more complex problems, we guide the model to learn the correct reasoning paths, which, according to the inference scaling law, typically involve longer reasoning sequences.
We subtract a constant 1 from the optimization objective to ensure that the initial expected value of the optimization is zero.
Constraint condition:
Therefore, we can establish our optimization objective as:
To solve this constrained optimization problem, we incorporate constraint into the objective function as a penalty term. Specifically, the constraint on accuracy is added to the objective with a penalty weight
By reorganizing the terms related with reference model , we have:
In practice, we approximate the expection terms related with by sampling. For each , we sample for times from and calculate the mean value:
This approach is widely employed in Policy Gradient with Baseline. Furthermore, a recently proposed method GRPO adopts a similar technique to reduce training overhead. Based on this technique, our objective can be approximated as:
Defining the Length-Harmonizing Reward , the loss function of off-policy-version Length-Harmonizing Fine-Tuning is

Evaluation Metric
-
Accuracy
-
Length
-
AES: Accuracy-Efficiency Score (AES).
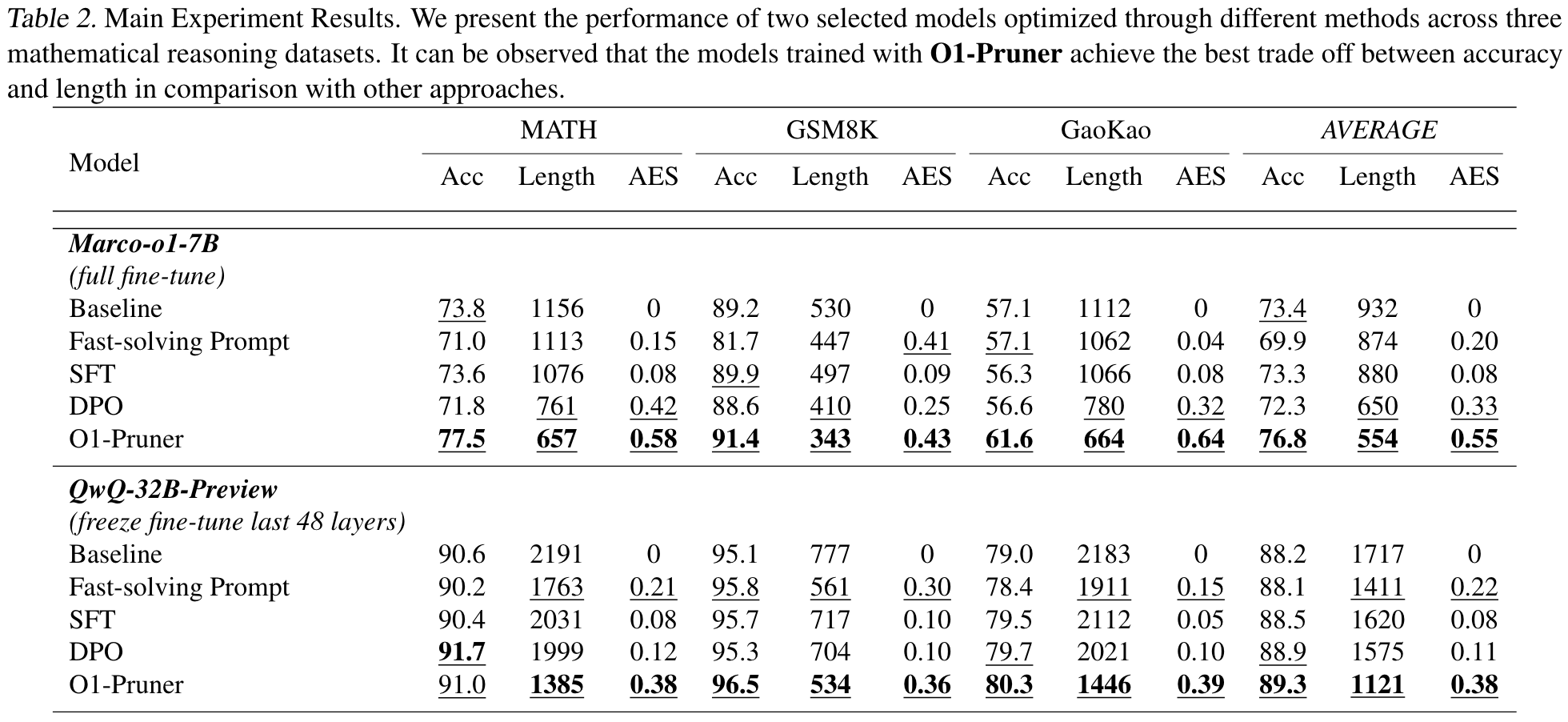
Main Result
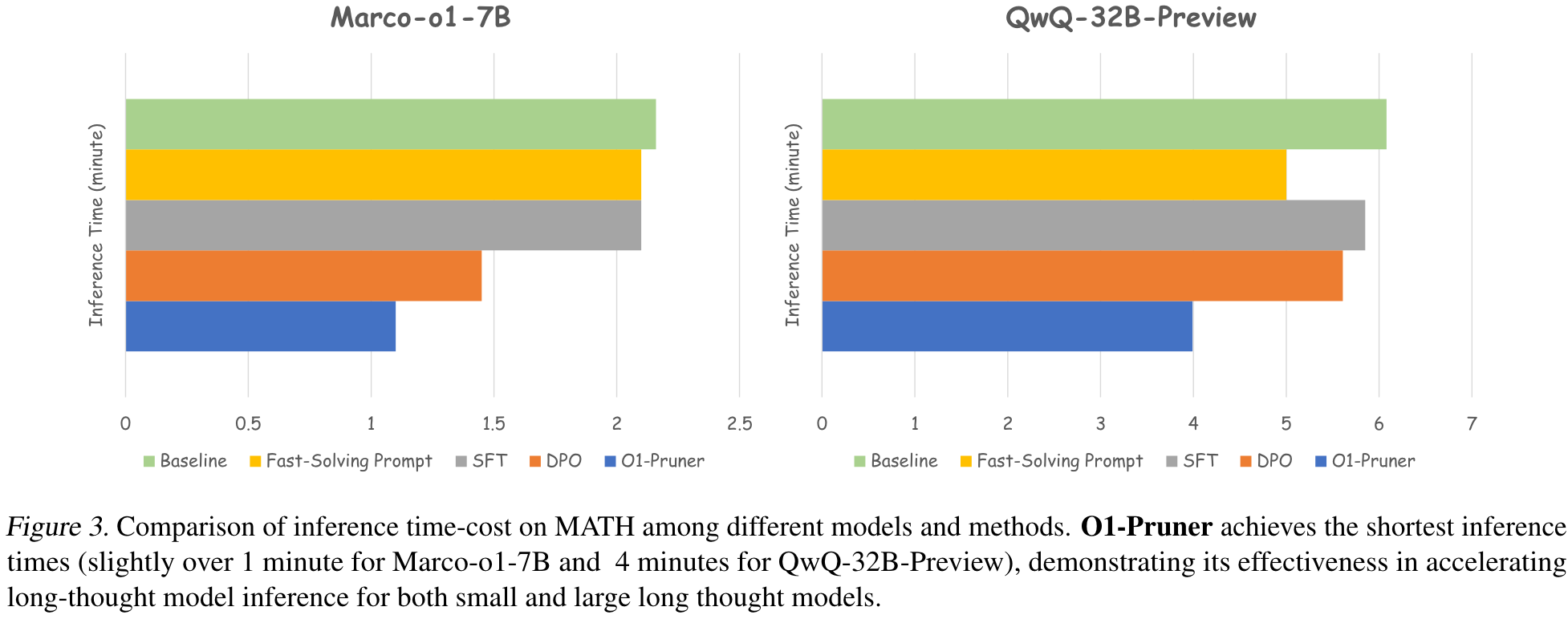
Inference Time-Cost Analysis
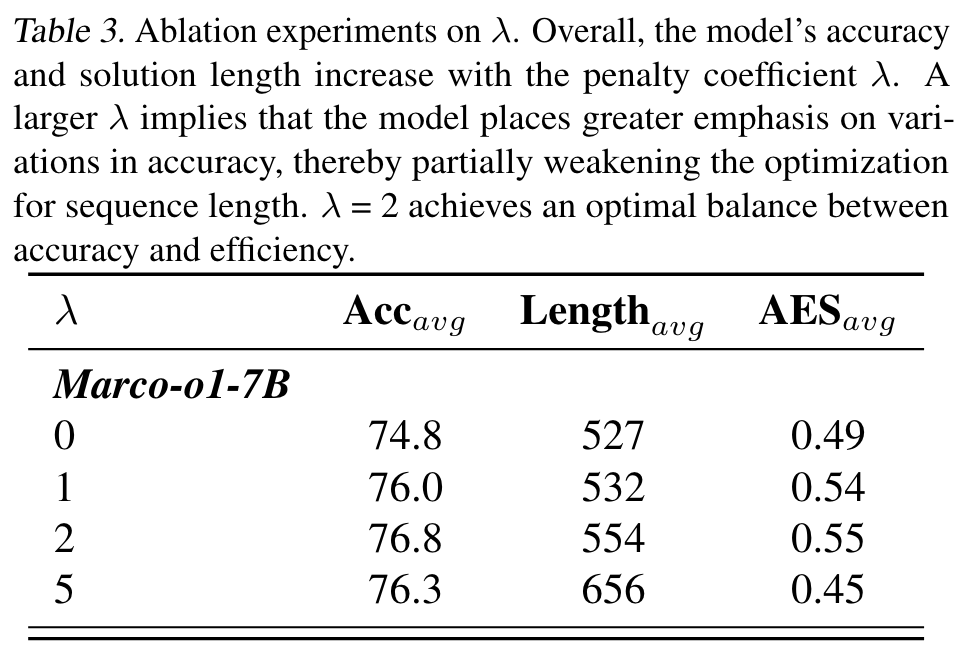
Abalatoin Study
We select several different values of and evaluate the model accordingly.
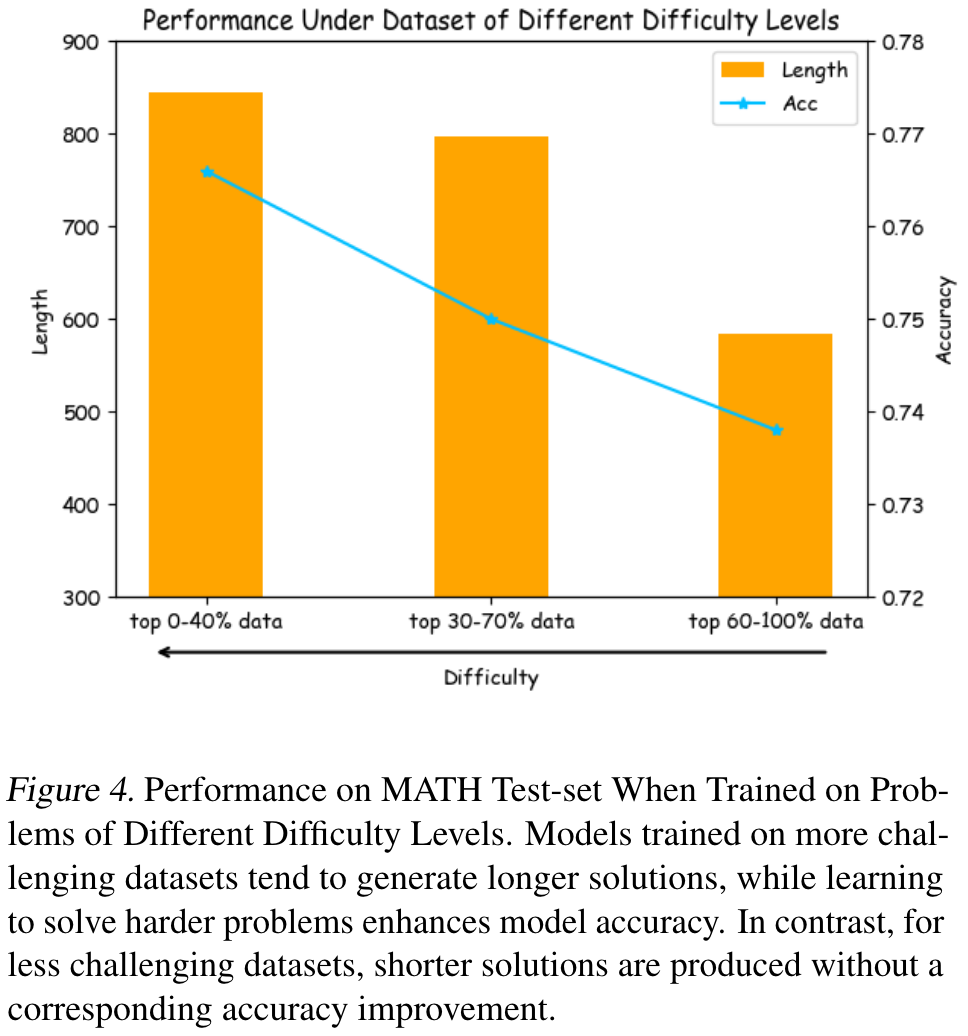
Ablation on Difficulty Levels.
🤖
对"O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning"论文的分析
根据提供的内容,这篇论文似乎聚焦于大型语言模型(LLM)的推理能力优化,特别是通过"O1-Pruner"方法来实现类似O1模型的推理剪枝效果。以下是我的分析:
1. 论文的创新之处与独特性:
-
推理剪枝技术创新:论文提出了"O1-Pruner"方法,这似乎是一种专注于优化LLM推理过程的技术,旨在减少推理链长度而不牺牲效果[0][2]。这与现有的"overthinking"问题解决方案形成差异化[2]。
-
长度协调微调方法:从标题可以看出,论文提出了"Length-Harmonizing Fine-Tuning"方法,这可能是一种新颖的微调策略,专门用于平衡和优化推理链的长度[0][1]。
-
效率与效果的平衡:论文似乎在保持推理质量的同时,成功减少了计算资源消耗,这对于大模型部署具有实际价值[1][2]。
-
与现有技术的整合:论文可能结合了参数高效微调(PEFT)技术,如LoRA等方法,使得优化过程更加高效[0][3]。
2. 论文中存在的问题及改进建议:
-
评估指标的全面性:从上下文来看,论文可能主要关注了推理长度和准确性,但对于推理质量的多维度评估可能不足[1][2]。建议增加更多评估维度,如推理的逻辑性、创新性和多样性等。
-
适用范围限制:论文的方法可能主要针对特定类型的推理任务(如数学推理),对于更广泛的开放域推理任务的适用性可能需要进一步验证[0][3]。建议在更多样化的任务上进行测试。
-
与其他优化方法的比较:论文可能缺乏与其他推理优化方法(如Compressed Chain of Thought、Graph of Thoughts等)的全面比较[2][3]。建议增加与这些方法的对比实验。
-
长期效果评估:论文可能缺乏对模型经过推理剪枝后长期表现的评估,特别是在处理复杂任务时的稳定性[1][3]。建议增加长期性能评估实验。
3. 基于论文的内容和研究结果,提出的创新点或研究路径:
-
自适应推理深度控制:开发一种能够根据任务复杂度自动调整推理深度的机制,而不是采用固定的剪枝策略。这可以在简单任务上进一步提高效率,在复杂任务上保持足够的推理深度[0][2]。
-
多模态推理剪枝:将O1-Pruner的概念扩展到多模态领域,研究如何在处理文本-图像等多模态任务时优化推理过程,减少不必要的计算步骤[1][3]。
-
推理剪枝与知识蒸馏结合:探索将推理剪枝技术与知识蒸馏相结合的方法,通过蒸馏优化后的推理路径来训练更小但高效的模型[0][2]。
-
元学习框架下的推理优化:开发一个元学习框架,使模型能够"学会如何推理",自动发现最优的推理策略和长度,而不需要人工设计剪枝规则[1][3]。
4. 为新的研究路径制定的研究方案:
研究方案1:自适应推理深度控制
研究方法:
- 设计一个推理控制器模块,它能够分析输入问题的复杂度并预测所需的推理步骤
- 利用强化学习训练控制器,以准确率和计算效率的加权和作为奖励信号
- 实现一个动态停止机制,当推理达到足够置信度时自动终止
研究步骤:
- 构建包含不同复杂度问题的数据集,并标注理想的推理深度
- 设计并实现推理控制器架构,包括复杂度评估和步骤预测组件
- 使用PPO或其他强化学习算法训练控制器[0][3]
- 在多个基准测试上评估自适应系统的性能,与固定剪枝策略比较
- 分析不同类型问题的推理深度分布,优化控制器策略
期望成果:
- 一个能根据问题复杂度自动调整推理深度的系统
- 在简单问题上比固定剪枝策略更高效,在复杂问题上保持更高准确率
- 关于问题复杂度与最优推理深度关系的新见解
研究方案2:多模态推理剪枝
研究方法:
- 扩展O1-Pruner框架以处理多模态输入(文本、图像、音频等)
- 设计模态特定的注意力机制,识别每个模态中的关键信息
- 开发跨模态推理路径优化算法,减少模态间不必要的交互
研究步骤:
- 收集或创建多模态推理数据集,包括不同复杂度的视觉问答和多模态推理任务
- 扩展现有的推理剪枝框架,增加模态特定的处理模块
- 设计跨模态注意力机制,用于识别不同模态中的关键信息
- 实现并训练多模态推理剪枝模型
- 在标准多模态基准测试上评估性能,特别关注计算效率和准确率的平衡
期望成果:
- 一个适用于多模态任务的推理剪枝框架
- 显著减少多模态推理任务的计算成本,同时保持竞争性能
- 关于不同模态在推理过程中重要性的新见解
研究方案3:推理剪枝与知识蒸馏结合
研究方法:
- 使用O1-Pruner优化大型教师模型的推理路径
- 设计一种蒸馏方法,将优化后的推理路径传递给较小的学生模型
- 开发路径感知的损失函数,引导学生模型学习高效推理策略
研究步骤:
- 选择合适的教师模型和一系列较小的学生模型
- 使用O1-Pruner优化教师模型的推理过程
- 收集教师模型的优化推理路径,包括中间步骤和注意力分布
- 设计蒸馏框架,包括路径模仿损失和结果匹配损失
- 训练学生模型,评估其在多个推理任务上的性能和效率
- 分析学生模型学到的推理策略,与教师模型比较异同
期望成果:
- 一种新的知识蒸馏方法,专注于传递高效推理能力
- 比传统蒸馏方法更小、更快但同样有效的学生模型
- 关于推理知识如何在不同规模模型间传递的新见解
这些研究方案建立在O1-Pruner的基础上,探索了不同方向的扩展和应用,有望进一步推动大型语言模型推理效率和能力的提升[0][1][2][3]。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!