目录
Resource Info Paper https://arxiv.org/abs/2502.20122 Code & Data https://github.com/TergelMunkhbat/concise-reasoning Public arXiv Date 2025.03.19
Summary Overview
作者认为典型的推理路径 (Reasoning Path) 中包含了许多冗余令牌,从而产生了无关的推理成本。为了让模型的推理路径更加简洁,作者构造相关的微调数据,并对模型进行微调,从而提升效果。
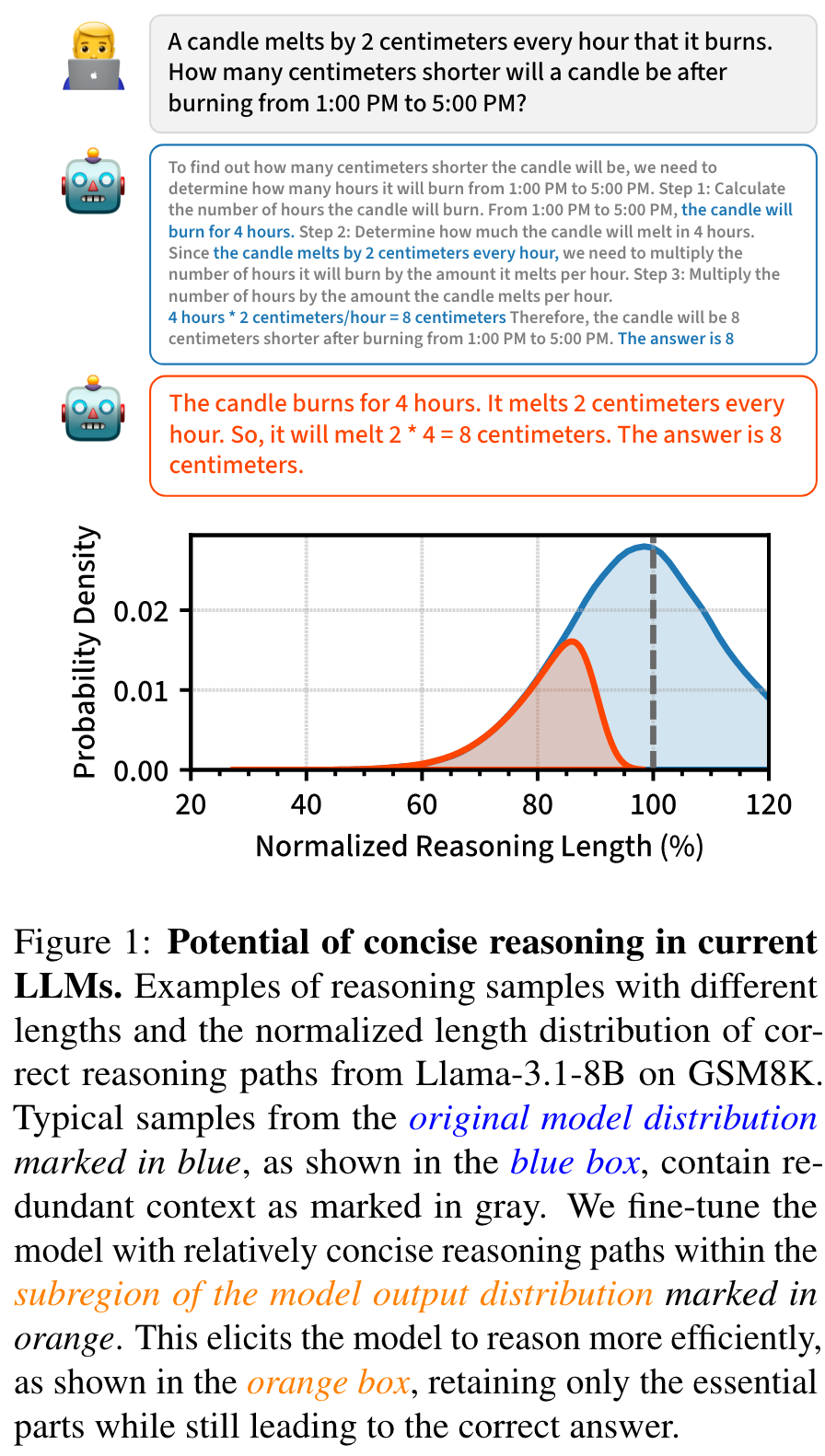
图 1 中所示的推理路径长度分布揭示了一个 insight:在模型的输出分布中,存在更有效的推理路径,并且模型有简化推理的潜力。
Main Content
作者们使用的是 Self-training 的方法微调模型,因为他们认为 Self-training 不仅仅去掉了对于其他模型的依赖,并且有助于模型保持推理能力,因为训练数据是来源于模型自己的数据分布。
数据集构造方法:
- BoN(Naive Best-of-N Sampling): 使用 BoN 来采样不同的推理路径。对于每一个问题生成了 N 个推理路径,并且选出其中最短的一个推理路径。如果一个问题不存在正确的推理路径,则将这个问题给移出数据集。
- FS (Few-shot conditioned sampling): 根据三种 few-shot 样例的来源不同,又可以分为下面三种
- FS-Human: Human annotated examples
- FS-GPT-4o: Examples from GPT-4o
- FS-Self: Self-generated samples
- FS-BoN(Few-shot conditioned BoN sampling): 使用 GPT-4o 的examples + BoN
- Augmentation for FS and FS-BoN: 将 zero-shot 和 few-shot 的数据融合,取出其中最短的回复作为最终数据。因为在 few-shot 中生成的数据可能存在一些问题。
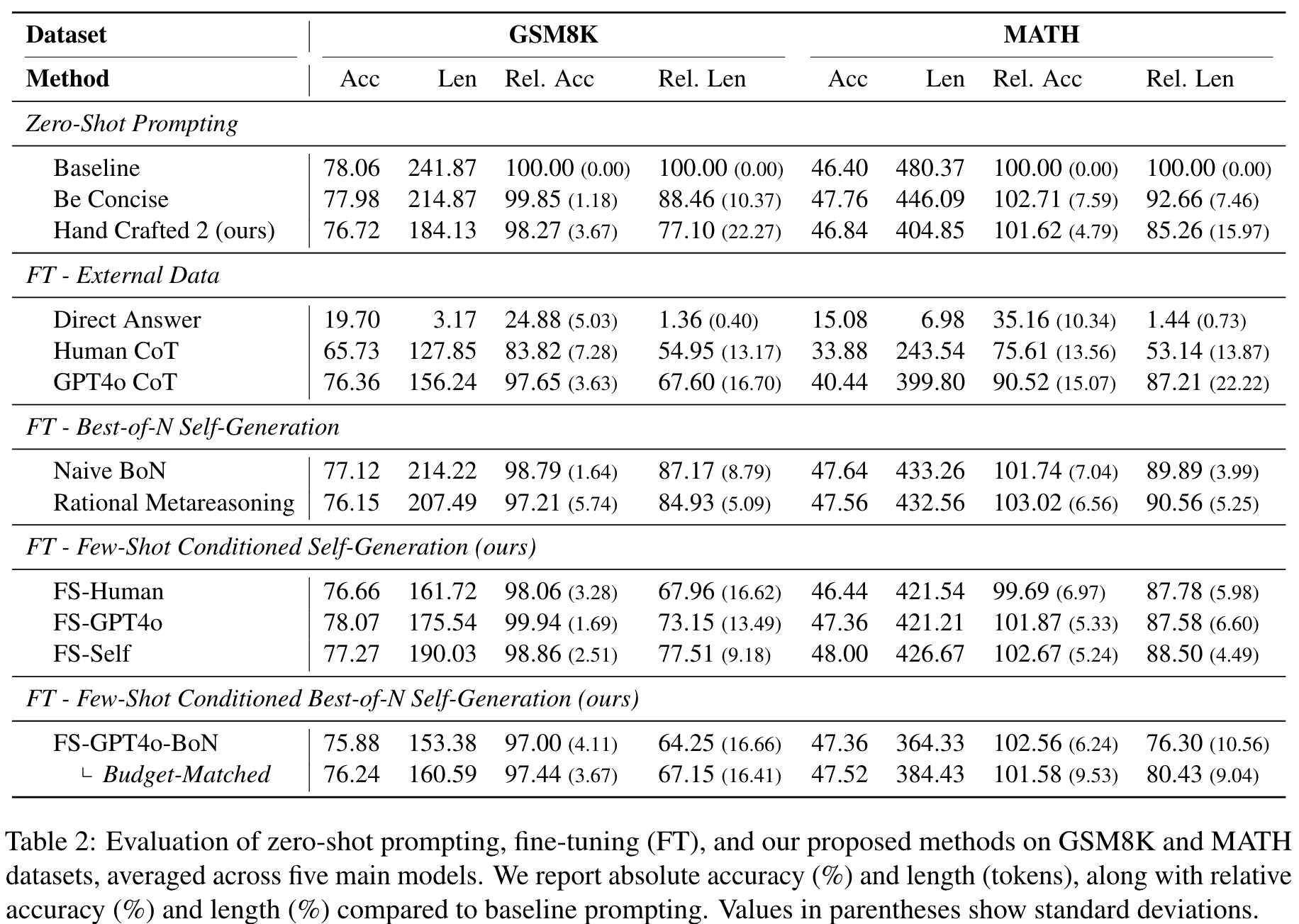
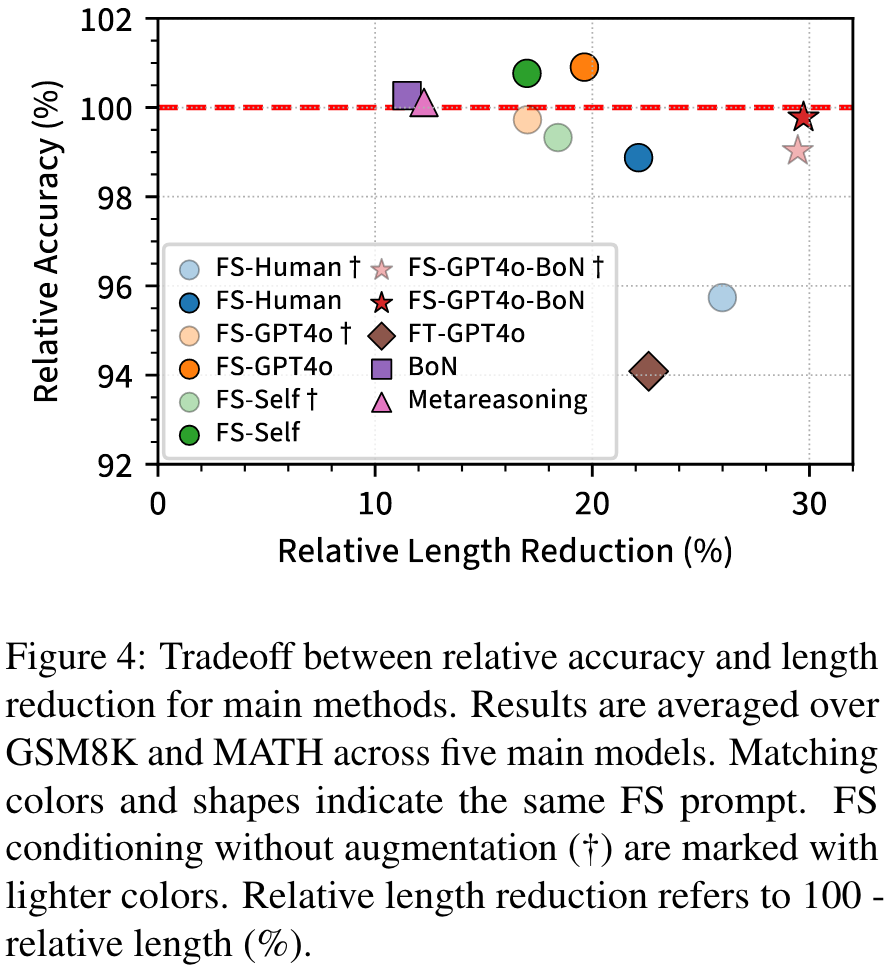
Example:

我们认为,将简洁的推理监督或奖励纳入培训管道可能对模型效率有益,尤其是对于具有冗长内部推理的“思考”模型。
🤖
- 论文的创新之处与独特性:
论文的主要创新点在于探索了如何在不牺牲推理质量的前提下减少大语言模型(LLM)链式思考推理过程中所需的token数量。具体创新之处包括:
-
聚焦于原始CoT框架的简化:不同于其他研究扩展CoT能力的方向,该论文回归基础,专注于如何使基本CoT推理过程更加高效。这一方向在当前大模型推理成本高昂的背景下具有重要的实用价值。
-
提出了"简洁推理"(Concise Reasoning)的概念:论文探讨了减少推理过程中token数量的最简单方法,这对于资源受限的环境尤为重要。
-
与最新研究成果的结合:论文将其研究与最新的LLM发展(如OpenAI的模型、DeepSeek系列模型等)相关联,显示了其在当前研究前沿的定位。
关键学习点:
- 理解LLM推理过程中计算资源与推理质量之间的权衡关系。
- 认识到简洁推理在保持推理质量的同时可以显著降低计算成本和延迟。
- 了解如何将基础CoT优化方法应用到更复杂的推理框架中。
- 论文中存在的问题及改进建议:
基于提供的片段,我发现以下潜在问题及改进建议:
-
研究范围限制:论文仅关注原始CoT框架,虽然提到可能适用于long-CoT,但缺乏对这种可迁移性的实证验证。建议进行实验验证简洁推理技术在其他CoT变体(如meta-CoT、long-CoT)中的有效性。
-
评估指标不明确:从片段中无法清楚看出论文使用了哪些具体指标来衡量"简洁性"与"推理质量"之间的平衡。建议建立更全面的评估框架,包括token减少率、推理准确度、推理时间等多维度指标。
-
缺乏在不同复杂度任务上的系统性测试:没有明确说明简洁推理技术在不同难度和领域任务上的表现差异。建议在MATH数据集等不同难度级别的任务上进行系统性测试,分析简洁推理的适用边界。
-
理论基础阐述不足:论文似乎缺乏对为什么简洁推理能够保持推理质量的理论解释。建议深入探讨简洁推理的认知科学基础,可参考Rational Metareasoning相关研究。
- 基于论文的内容和研究结果,提出的创新点或研究路径:
创新点1:自适应简洁推理框架 开发一个能够根据问题复杂度动态调整推理详细程度的框架。简单问题使用极简推理,复杂问题则保留更多推理步骤。这种方法可以在系统层面优化资源分配,进一步提高整体效率。
创新点2:多模态简洁推理 将简洁推理概念扩展到多模态领域,研究如何在视觉-语言推理任务中减少必要的推理步骤和token数量。例如,在图像描述或视觉问答任务中,探索如何减少中间推理步骤但保持准确性。
创新点3:简洁推理的可解释性研究 探索简洁推理过程中保留的关键步骤与模型内部表征之间的关系。这可以帮助我们理解LLM推理的本质,并为更可解释的AI系统提供见解。
创新点4:简洁推理的知识蒸馏 研究如何将大型模型的简洁推理能力蒸馏到更小的模型中。这可能创造出既高效又精确的小型专家模型,适用于资源受限环境。
- 为新的研究路径制定的研究方案:
研究方案1:自适应简洁推理框架
研究方法:
-
第一阶段:构建问题复杂度评估模块,能够在推理前或推理早期阶段评估问题难度
- 收集并标注不同复杂度的问题数据集
- 训练复杂度分类器,输入为问题,输出为复杂度评分
- 验证分类器在未见数据上的泛化能力
-
第二阶段:设计自适应推理控制器
- 基于复杂度评分动态决定推理详细程度
- 开发推理压缩算法,能根据复杂度保留关键推理步骤
- 实现自动调节机制,平衡token使用与推理准确性
-
第三阶段:系统集成与评估
- 将复杂度评估模块与推理控制器集成
- 在多个基准测试上评估系统性能
- 与固定简洁度的推理方法进行比较
预期成果:
- 一个能根据问题复杂度自动调整推理详细程度的端到端系统
- 相比固定简洁度方法,在相同平均token使用量下取得更高的整体准确率
- 复杂问题的准确率提升,同时简单问题的处理效率显著提高
- 关于问题复杂度与最优推理详细程度关系的实证发现
研究方案2:多模态简洁推理
研究方法:
-
第一阶段:多模态推理过程分析
- 收集视觉-语言推理任务的详细推理过程
- 分析视觉和语言信息在推理中的贡献
- 识别可简化的冗余步骤和必须保留的关键步骤
-
第二阶段:多模态简洁推理技术开发
- 设计视觉信息压缩技术,提取关键视觉特征
- 开发多模态推理简化算法,减少中间推理步骤
- 构建模态间信息互补机制,利用一个模态的信息减少另一模态的冗余
-
第三阶段:实验验证与优化
- 在视觉问答、图像推理等任务上测试
- 比较完整推理与简洁推理在准确性和效率上的差异
- 针对不同类型的多模态任务优化简洁推理策略
预期成果:
- 多模态简洁推理的理论框架和实现方法
- 在保持准确率的前提下,减少30-50%的多模态推理token使用量
- 多模态任务中视觉和语言信息对推理贡献的新见解
- 适用于资源受限环境的高效多模态推理系统
研究方案3:简洁推理的可解释性研究
研究方法:
-
第一阶段:推理步骤重要性量化
- 开发评估单个推理步骤对最终结果贡献的方法
- 通过消融实验识别关键推理步骤
- 建立推理步骤重要性排序机制
-
第二阶段:内部表征与推理步骤的关联分析
- 收集模型在完整推理和简洁推理过程中的激活值
- 分析关键推理步骤与模型内部表征的关系
- 探索推理简化如何影响模型的注意力机制
-
第三阶段:可解释性框架构建
- 基于发现开发推理过程可视化工具
- 构建解释简洁推理决策的方法
- 设计人类可理解的推理简化规则
预期成果:
- 量化评估推理步骤重要性的方法论
- 揭示LLM内部表征与推理步骤之间的关系
- 更可解释的简洁推理框架,能够说明为什么保留或删除特定推理步骤
- 推理过程可视化工具,帮助理解简洁推理的工作原理
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!