目录
Resource Info Paper https://arxiv.org/abs/2503.16419 Code & Data https://github.com/Eclipsess/Awesome-Efficient-Reasoning-LLMs Public arXiv Date 2025.03.28
Summary Overview
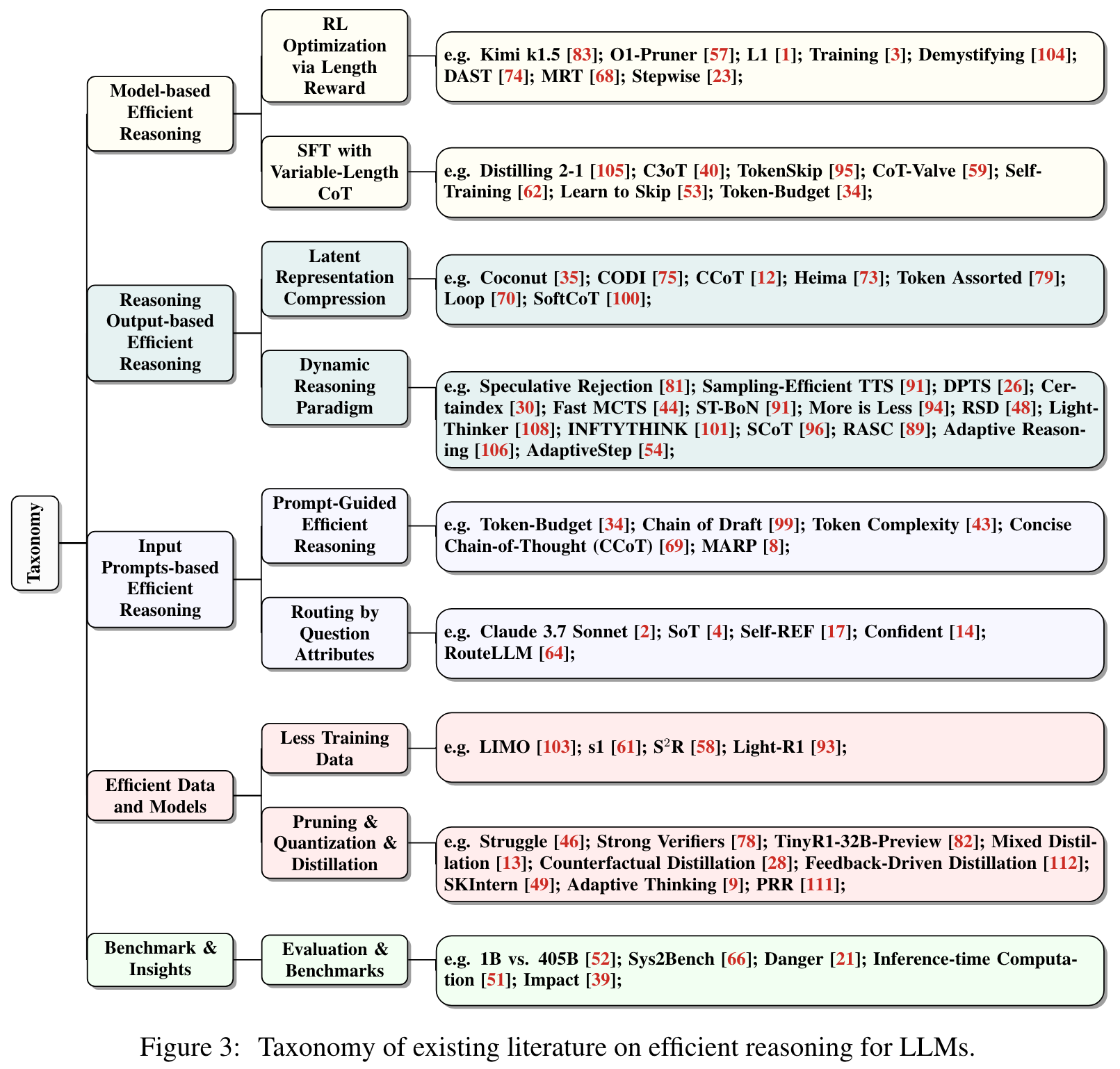
作者针对于 Reasoning Model 中的 Overthinking 问题撰写了一个综述。将现有的工作分为了三类:model-based efficient reasoning, reasoning output-based efficient reasoning, input prompts-based efficient reasoning.
Main Content
Efficient Reasoning seeks to optimize reasoning length while preserving reasoning capabilities, offers practical benefits such as reduced computational costs and improved responsiveness for real-world applications. Despite its potential, efficient reasoning remains in the early stages of research.
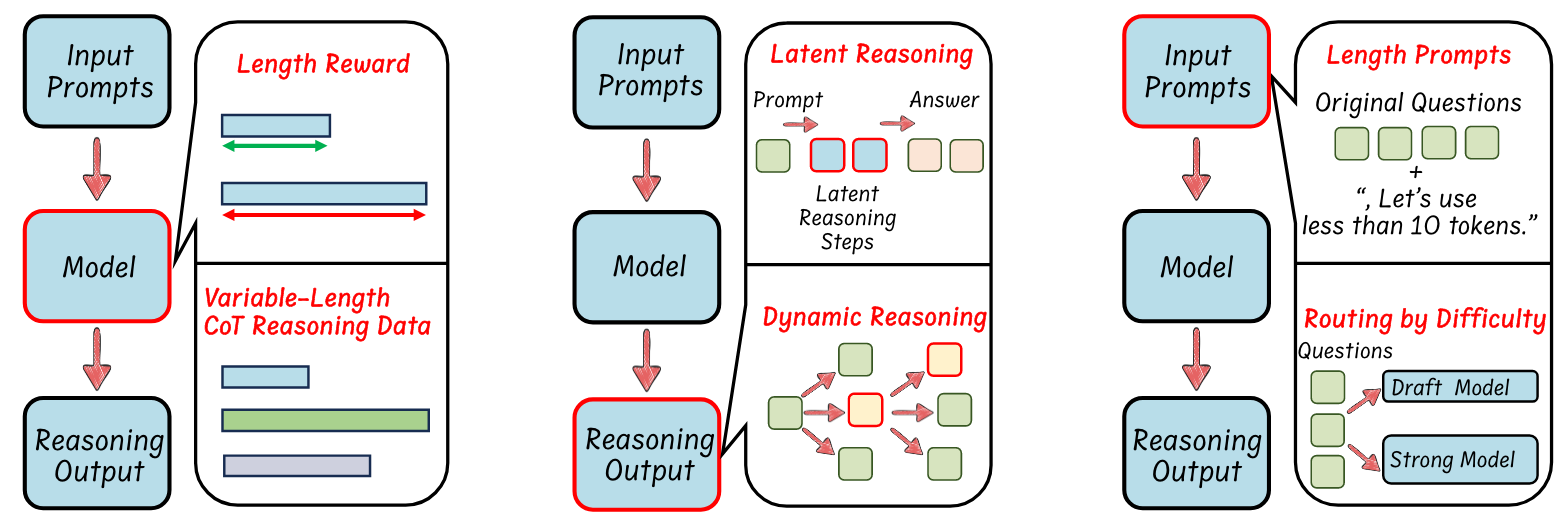
- Model-based efficient reasoning: Consider optimizing full-length reasoning models into more concise reasoning models or directly traininig efficient reasoning models.
- Reasoning output-based efficient reasoning: Aims to dynamically reduce reasoning steps and length during inference.
- Input prompts-based efficient reasoning: Seek to enhance reasoning efficiency based on input prompt properties such as difficulty or length control.
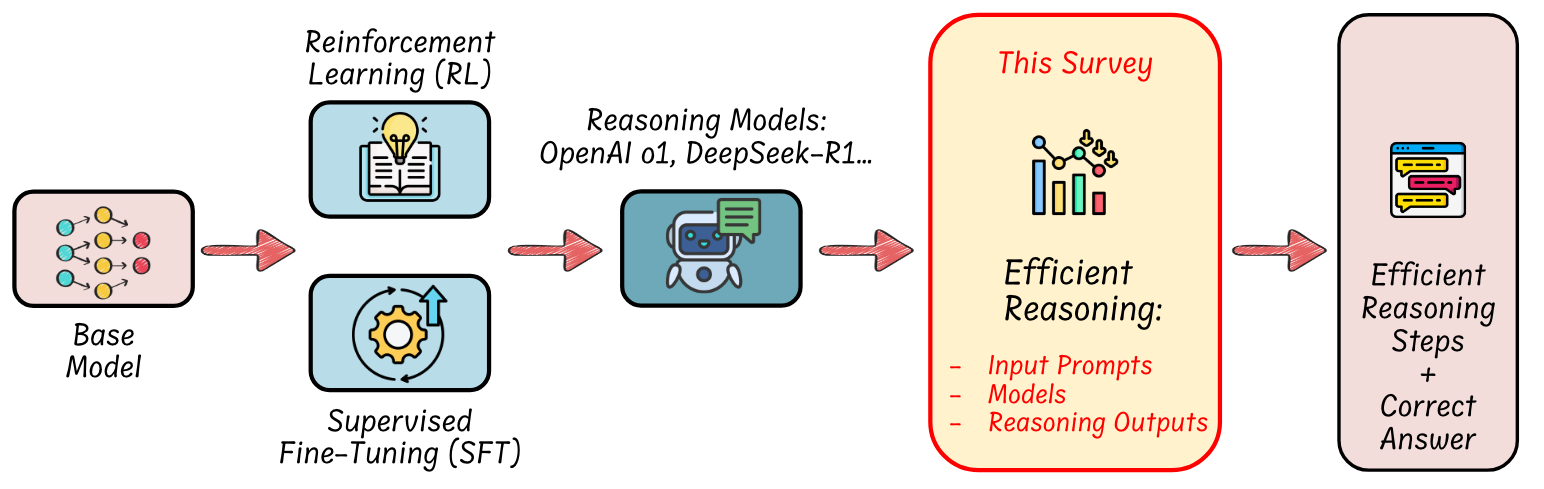
Efficient reasoning in LLMs emphasizes smart and concise reasoning by optimizing the length of generated reasoning sequences and reducing unnecessary thinking steps.
在长期的COT推理模型中,“过度思考现象”是指LLM会产生过度详细或不必要地详细的推理步骤,最终降低其解决问题的效率的情况。
Model-based Efficient Reasoning
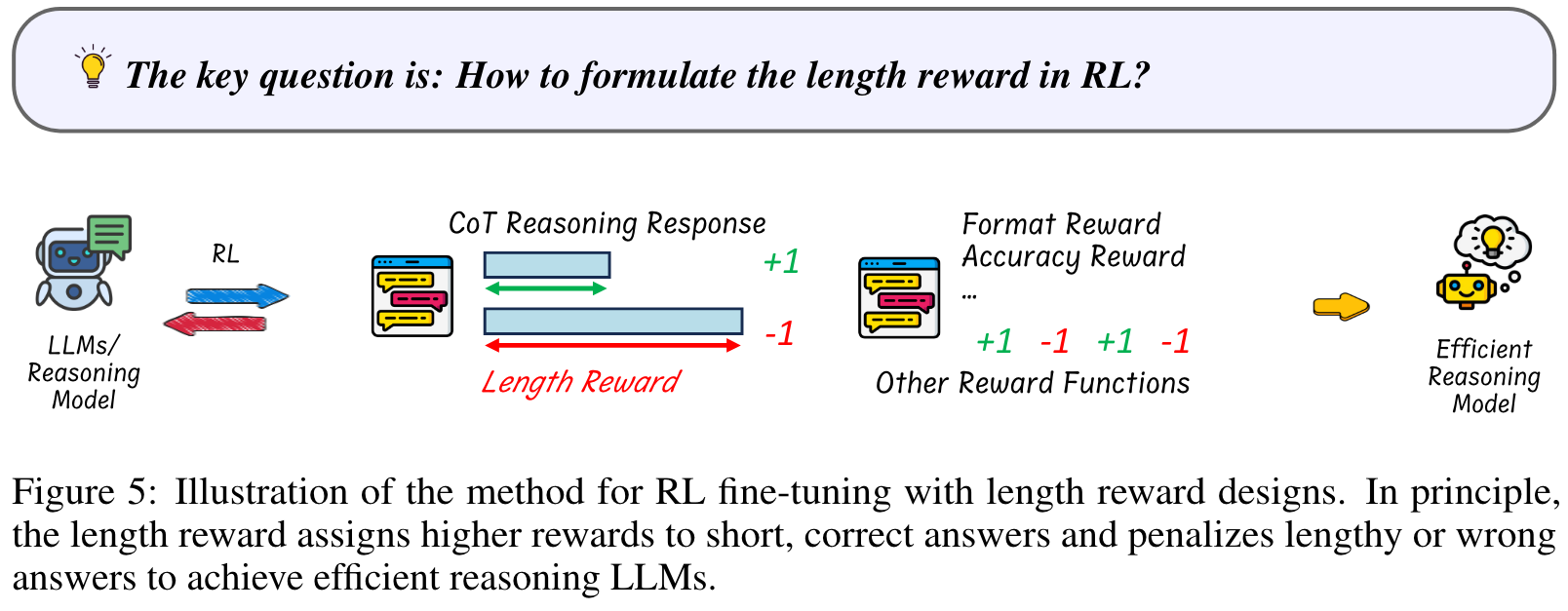
RL with Length Reward Design
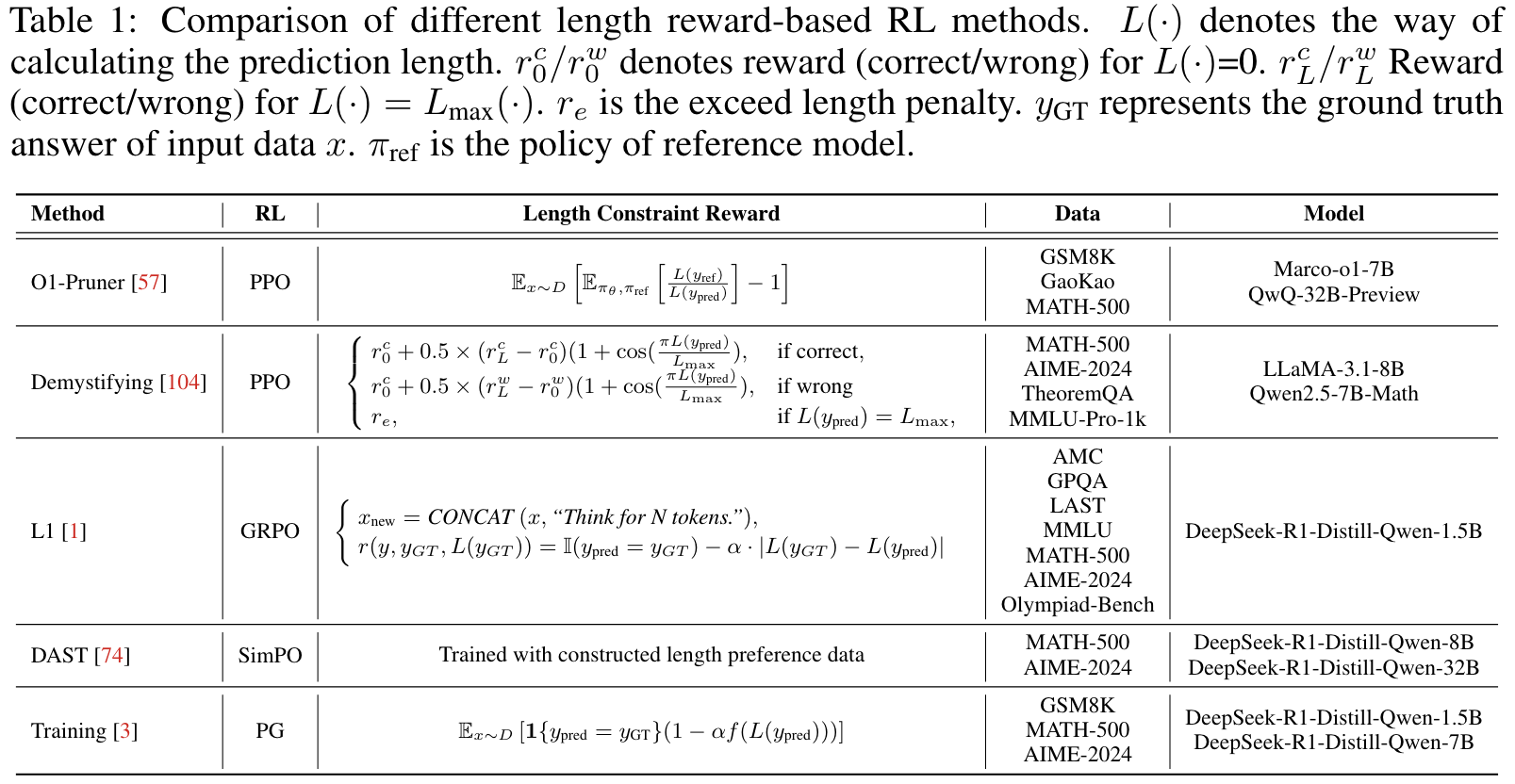
原则上,length reward 将更高的分数分配给了简短,正确的答案,同时惩罚长度过长或是不正确的答案,从而优化了推理路径的长度。
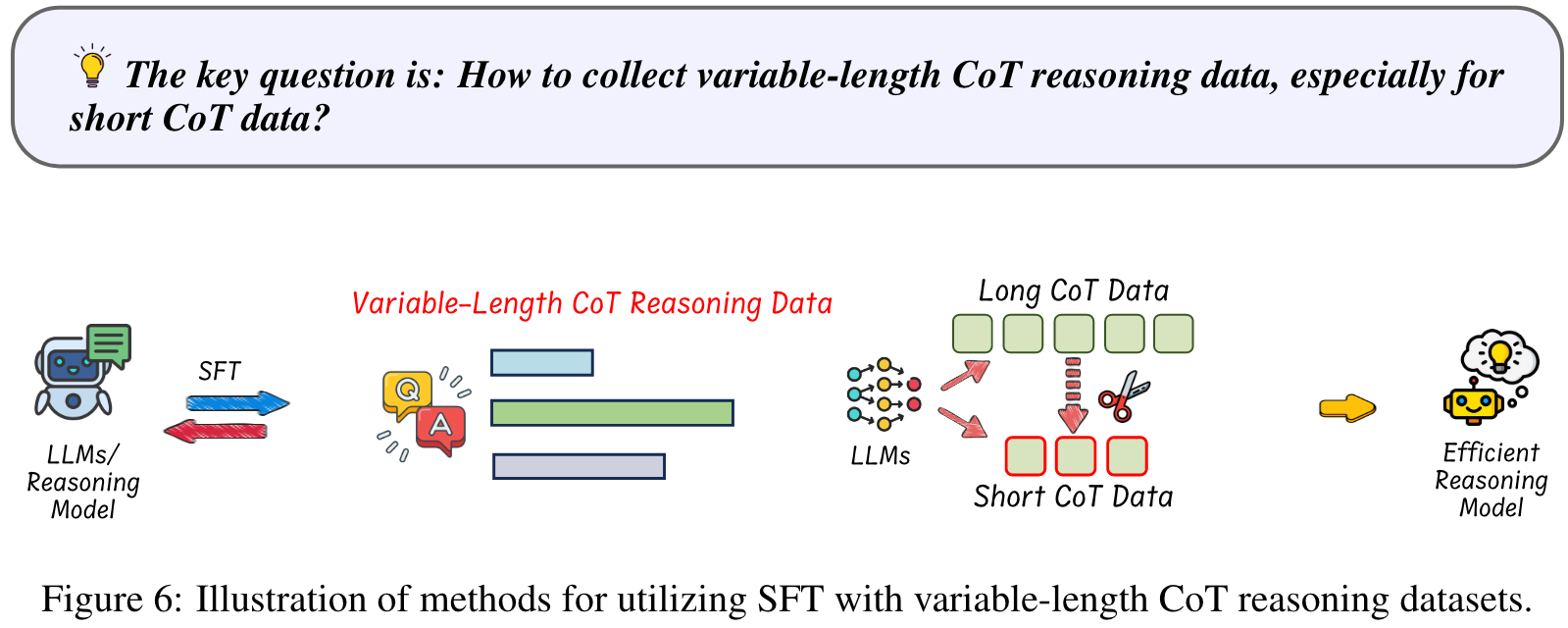
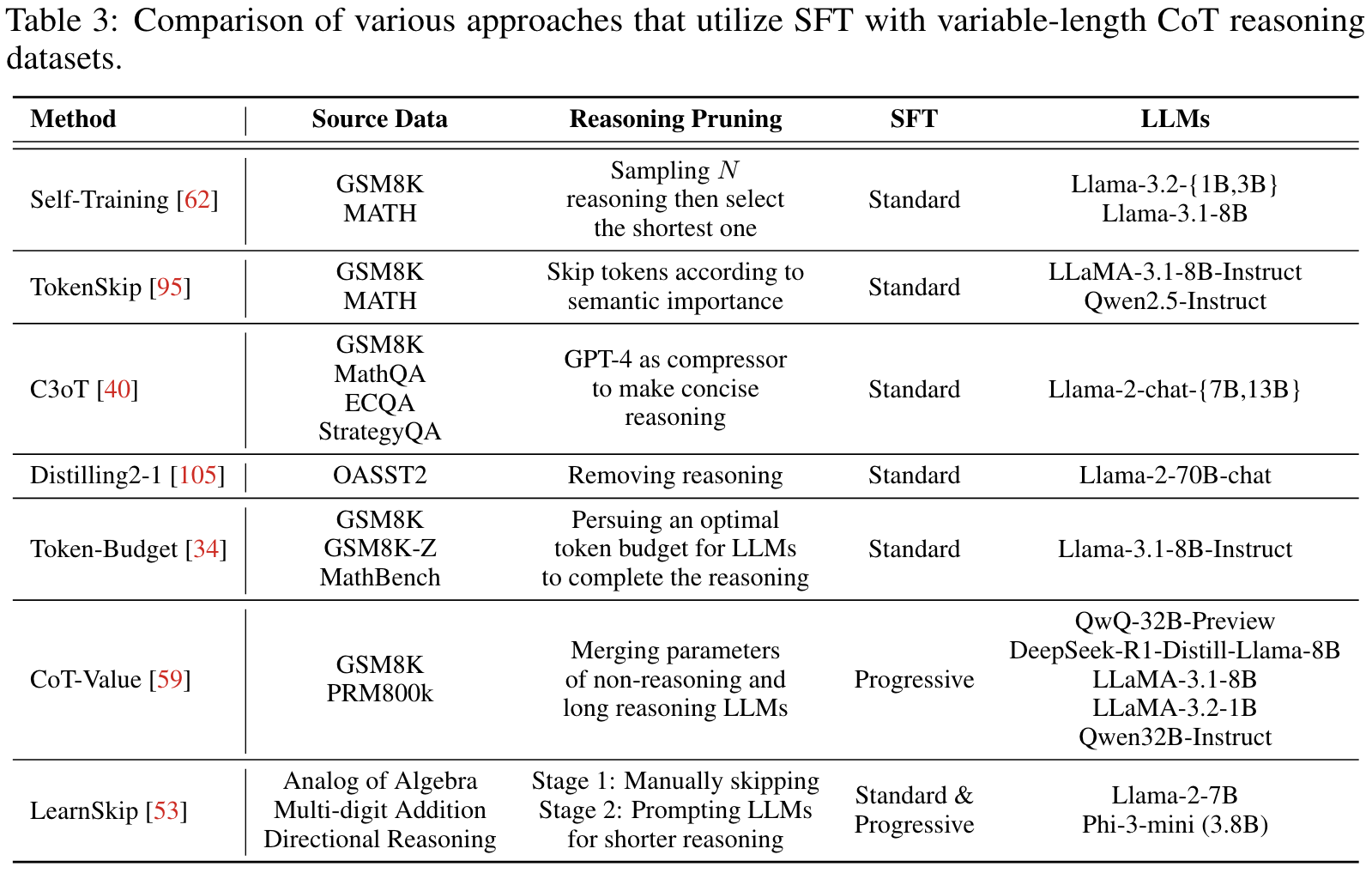
SFT with Variable-Length CoT Data
- Constructing variable-length CoT reasoning datasets via various methods.
- Applying SFT with collected data on reasoning models to enable LLMs to learn compact reasoning chains that encapsulate effective knowledge.
Reasoning Output-based Efficient Reasoning
With fewer (or no) explicit textual intermediate steps, several new methods focus on compressing or replacing explicit CoT with more compact latent representations.
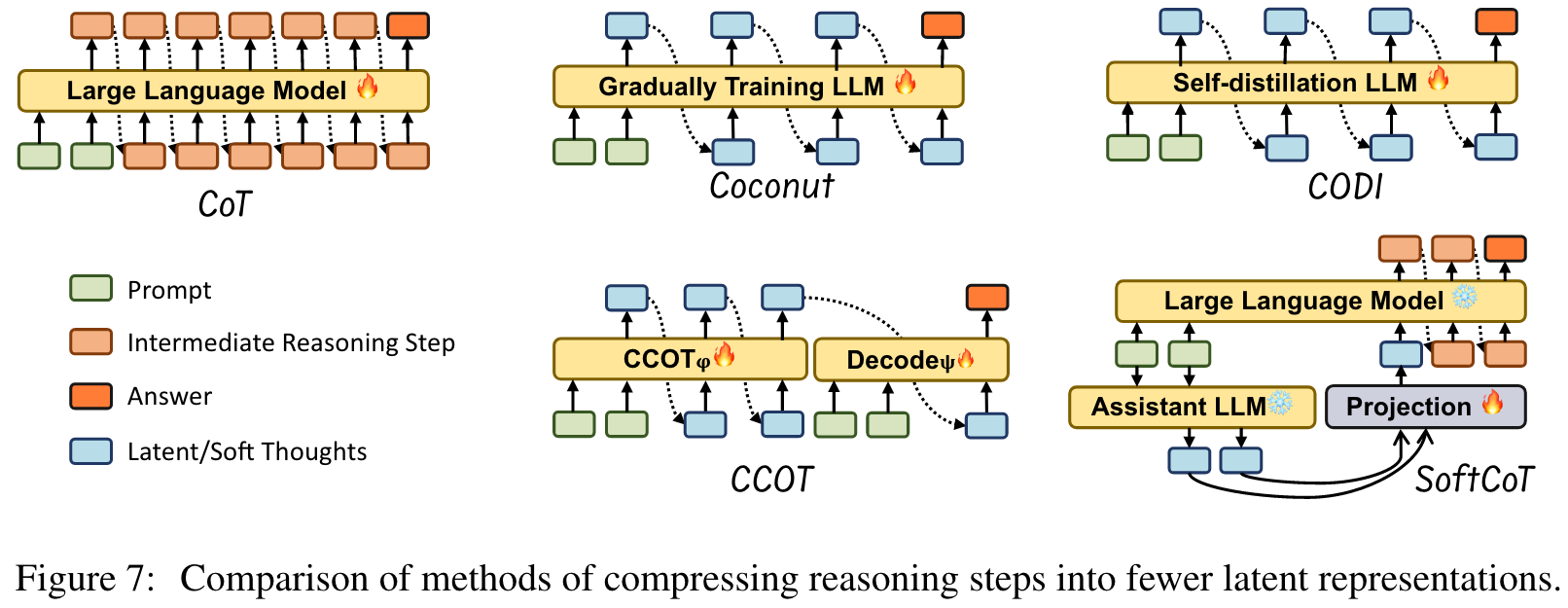
研究表明,循环模型隐含地产生潜在的思想,使它们能够通过连续的循环模拟COT推理的多个步骤。
🤖
1. 论文的创新之处与独特性: - **首次系统化研究高效推理**:论文是第一篇系统性综述高效推理(Efficient Reasoning)领域的工作,明确提出了“高效推理”的重要性,并将相关研究分为三大方向:基于模型的高效推理、基于推理输出的高效推理、以及基于输入提示的高效推理。这种分类方式为后续研究提供了清晰的框架。 - **揭示“过度思考”现象**:论文深入探讨了“过度思考”(Overthinking)现象,即模型在解决简单问题时生成冗长且冗余的推理路径,从而增加计算成本。通过案例分析,该问题的实际影响得到了量化,凸显了优化推理长度的重要性。 - **多样化的技术总结**:论文涵盖了强化学习(RL)中的长度奖励设计、变长推理数据的监督微调(SFT)、隐式推理表示的压缩、动态推理范式等多个方向的技术手段,并详细分析了每种方法的优缺点。 - **提出新的评估框架**:除了传统的准确性指标外,论文引入了推理效率、推理长度、以及“过度思考分数”等新评估指标,为未来的高效推理研究提供了更全面的评估视角。 - **跨领域应用与讨论**:论文讨论了高效推理在自动驾驶、医疗、嵌入式AI等领域的潜在价值,强调其在实际应用中的经济和社会效益。 2. 论文中存在的问题及改进建议: - **对方法的定量比较不够全面**:尽管论文总结了多种高效推理方法,但缺乏对这些方法在统一基准下的定量比较,例如不同方法在推理长度、准确性、计算成本之间的权衡。 - **改进建议**:未来工作可以设计一个综合性的基准测试框架(如统一数据集和评估指标),对各类方法进行系统性比较。 - **对小模型推理能力的分析较浅**:论文提到小模型(SLMs)的推理能力,但主要集中于蒸馏和压缩技术,对小模型在不同任务上的实际性能和局限性缺乏深入讨论。 - **改进建议**:进一步研究小模型在特定任务下的推理能力,并探索如何通过任务适配或轻量化技术提升其性能。 - **对动态推理范式的实际实现讨论不足**:论文提到动态推理(如长度过滤、基于信心的早停等),但缺乏对这些方法在实际系统中的部署复杂性和性能影响的深入讨论。 - **改进建议**:研究如何在实际应用中高效实现动态推理范式,包括硬件优化和推理时间的分布式管理。 3. 基于论文的内容和研究结果,提出的创新点或研究路径: - **创新点1:基于多模态输入的高效推理**:结合视觉、语言和语音等多模态输入,研究如何通过压缩推理路径,实现跨模态推理任务的高效性。 - **创新点2:自适应推理路径生成**:开发能够根据任务难度、用户需求动态调整推理长度的模型,提升推理效率的同时保证结果准确性。 - **创新点3:推理效率与安全性的联合优化**:研究如何在保持推理效率的同时,增强模型的安全性,例如防止生成有害内容或错误推理。 4. 为新的研究路径制定的研究方案: - **研究路径1:基于多模态输入的高效推理** - **研究方法**: 1. 构建一个多模态推理数据集,包括视觉问答、图文推理、多模态翻译等任务。 2. 设计一种多模态推理模型,结合视觉和语言模态,通过隐式表示压缩推理路径。 3. 利用强化学习设计奖励函数,鼓励模型生成简洁但准确的推理路径。 - **研究步骤**: 1. 数据预处理与标注,确保多模态数据的一致性与质量。 2. 模型训练与微调,测试不同模态融合策略对推理效率的影响。 3. 实验评估,比较多模态模型与单模态模型在推理效率和准确性上的表现。 - **期望成果**:提出一种高效的多模态推理框架,在多个跨模态任务中实现推理路径的显著压缩。 - **研究路径2:自适应推理路径生成** - **研究方法**: 1. 基于模型的不确定性估计,动态调整推理路径的长度。 2. 利用元学习方法,让模型在训练时学习如何根据任务难度调整推理路径。 - **研究步骤**: 1. 构建一个包含不同难度级别问题的数据集。 2. 设计一个动态推理模块,结合不确定性估计和任务特征进行路径调整。 3. 通过实验验证动态推理模块在不同任务上的适应性和性能。 - **期望成果**:开发出一种自适应推理模型,能够在保证准确性的前提下显著降低推理长度。 - **研究路径3:推理效率与安全性的联合优化** - **研究方法**: 1. 在推理过程中引入安全性评估模块,实时检测可能的错误或有害推理。 2. 结合强化学习和监督学习,优化模型在效率和安全性之间的平衡。 - **研究步骤**: 1. 构建一个包含潜在有害推理样本的训练数据集。 2. 设计一个安全性评估指标,并将其加入推理奖励函数中。 3. 通过实验比较不同模型在推理效率和安全性上的表现。 - **期望成果**:提出一种高效且安全的推理模型,能够在实际应用场景中显著降低推理成本,同时避免生成错误或有害内容。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!