目录
Resource Info Paper http://arxiv.org/abs/2506.02397 Code & Data https://github.com/AgenticIR-Lab/OThink-R1 Public arXiv Date 2025.06.05
Summary Overview
造了一批 Fast / Slow Thinking 的混合微调数据,然后使用了一个增加了 KL 散度的 Loss 进行 SFT。
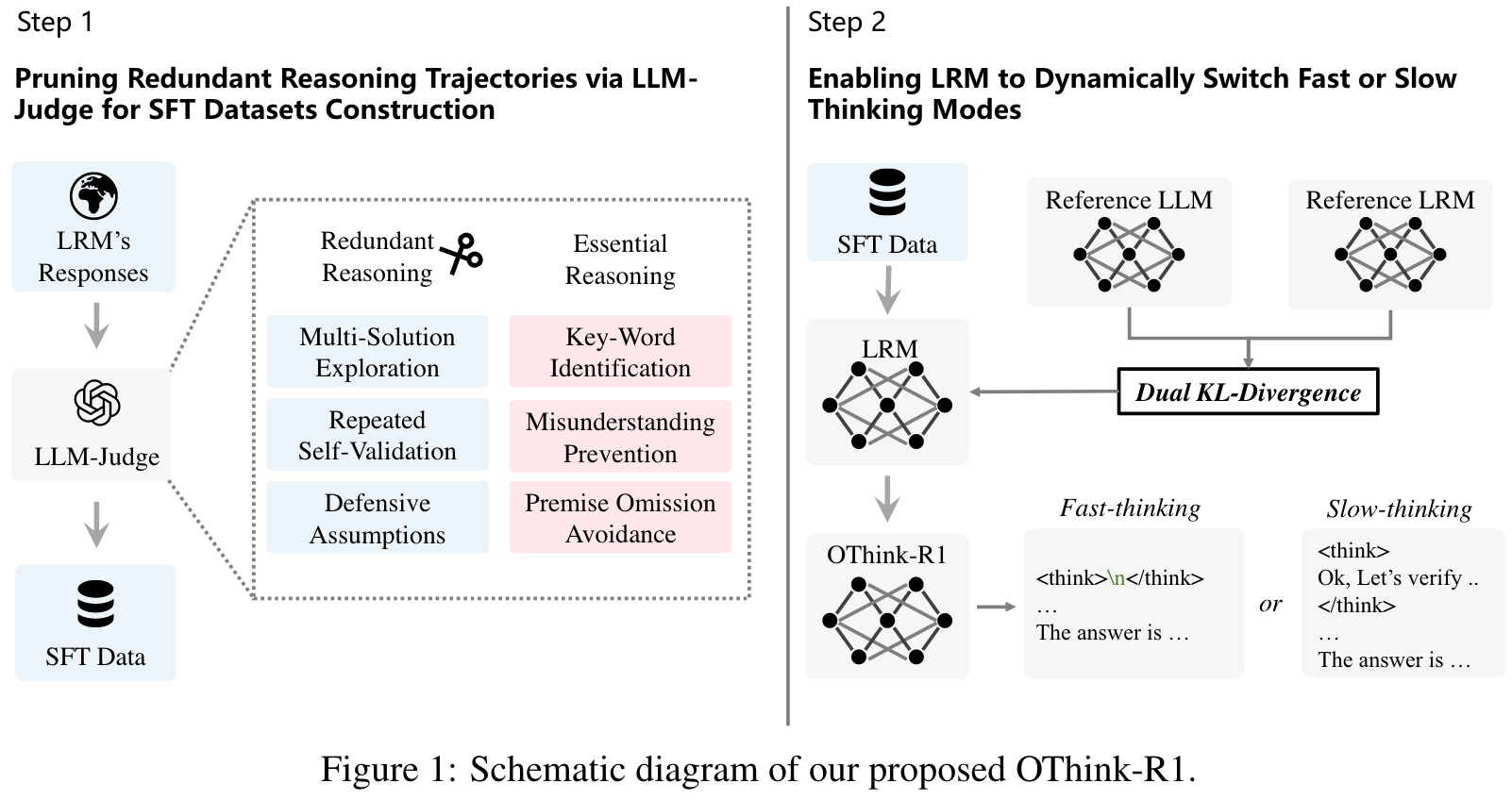
Main Content
Two challenges:
- How to idnetify which scenarios that fast thinking is sufficient?
- How to empower LRMs to autonomously select the appropriate reasoning mode?
Three characteristic patterns of redundant reasoning:
- Multi-Solution Exploration: Persistent exploration of alternative solutions despite determining a correct answer.
- Repeated Self-Validation: Excessive re-validation of every intermediate steps in final solutions.
- Defensive Assumptions: Being overly cautious, take extraneous hypotheses into consideration based on internal knowledge, rather than problem-specific constraints.

🤖
核心创新点
动态思维模式切换机制
OThink-R1的最大创新在于提出了一种内在的快/慢思维模式切换机制,这是首次将认知科学中的双系统理论成功应用于大型推理模型(LRMs)。该机制能够让模型自主判断问题复杂度,并动态选择适当的推理模式。
推理冗余识别方法
论文系统性地分析了LRMs的推理轨迹,并提出了利用识别范式和LLM-Judge将推理轨迹分类为"冗余推理"或"必要推理"的方法。这种分类方法为优化推理效率提供了理论基础。
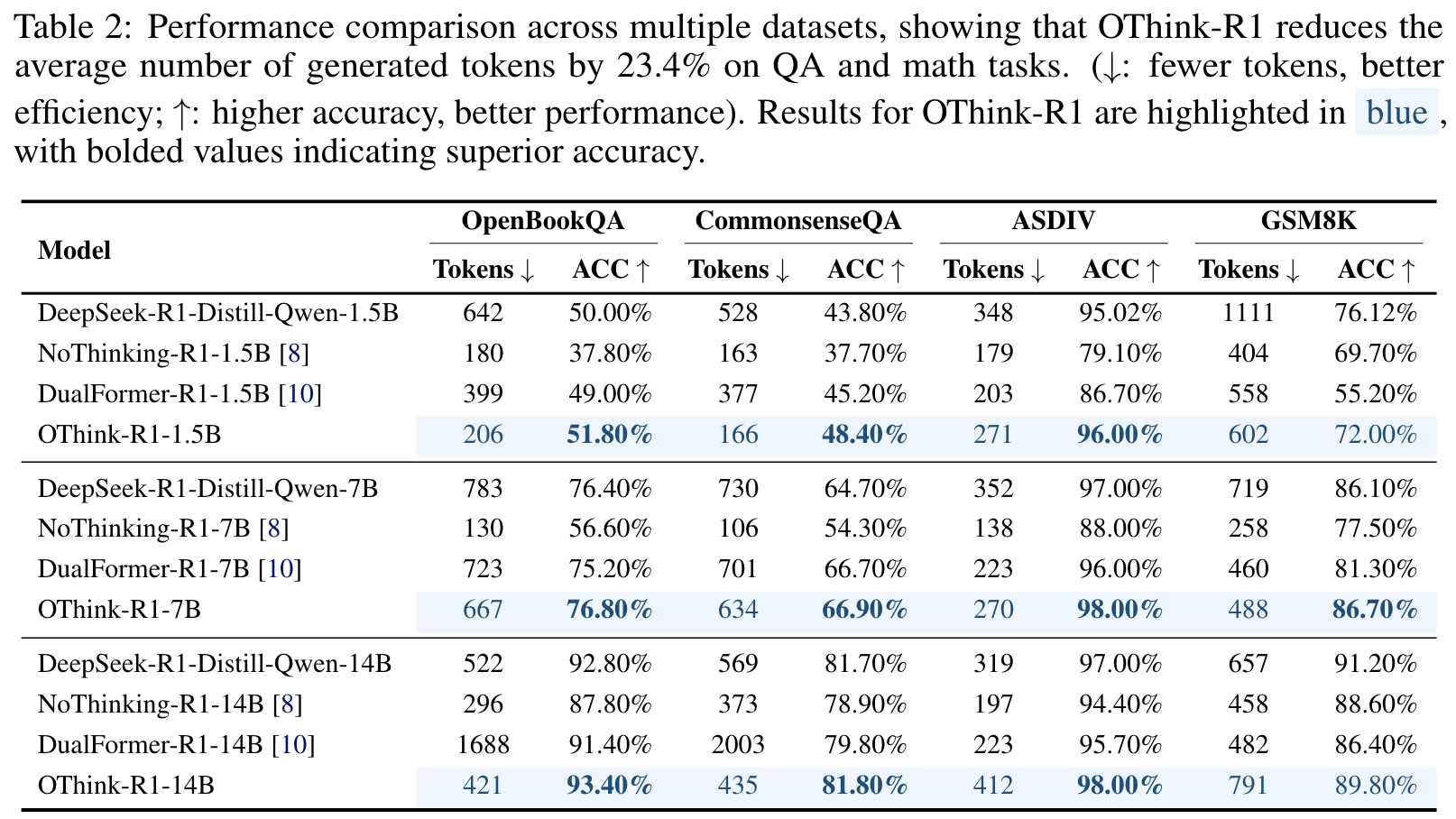
计算效率的显著提升
实验结果表明,OThink-R1在保持准确率的同时,平均减少了约23%的推理冗余。这一成果直接解决了LRMs产生比非推理LLMs多9.78倍token的效率问题。
关键学习点
-
混合范式的必要性:单一的静态推理模式无法适应不同复杂度的任务,灵活的混合模式是未来发展方向。
-
认知科学启发的AI设计:人类认知理论可以有效指导AI系统设计,特别是在推理策略选择方面。
-
效率与性能的平衡:通过智能的模式切换,可以在不牺牲性能的前提下大幅提升计算效率。
-
论文中存在的问题及改进建议:
主要问题
模式切换标准的模糊性
论文虽然提出了使用LLM-Judge进行分类,但具体的判断标准和阈值设置缺乏详细说明。这可能导致在实际应用中难以复现和调优。
缺乏多样化任务评估
实验主要集中在数学和问答任务上,对于其他类型的推理任务(如代码生成、逻辑推理、创意写作等)的适用性未得到充分验证。
动态切换的开销分析不足
论文未详细分析模式切换本身带来的计算开销,这在实际部署中可能是一个重要考量因素。
改进建议
-
建立更精确的复杂度评估体系:开发基于任务特征的多维度复杂度评分系统,包括逻辑深度、知识广度、推理步骤等指标。
-
扩展评估基准:在更多样化的任务集上进行评估,包括多模态推理、长文本理解等场景。
-
引入自适应学习机制:让模型能够从历史决策中学习,不断优化模式切换的决策边界。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
创新研究方向一:多粒度推理模式
不仅限于快/慢两种模式,而是设计包含超快速(直觉)、快速(模式识别)、中速(结构化推理)、慢速(深度分析)的多层次推理体系。
创新研究方向二:协同推理网络
构建多个专门化的推理模块,通过动态路由机制实现模块间的协同工作,不同模块可以并行处理问题的不同方面。
创新研究方向三:元推理优化器
开发一个专门的元模型,用于预测和优化主模型的推理路径,实现推理过程的实时优化和资源分配。
创新研究方向四:认知负载感知推理
引入认知负载理论,让模型能够评估用户的理解能力和需求,动态调整输出的详细程度和推理深度。
- 为新的研究路径制定的研究方案:
研究方案一:多粒度推理模式系统
研究方法
- 理论建模:基于认知科学和信息论,建立多粒度推理的数学模型
- 架构设计:设计支持四种推理模式的统一神经网络架构
- 训练策略:开发分层强化学习算法,让模型学习选择最优推理粒度
研究方案二:协同推理网络架构
研究方法
- 模块化设计:开发专门化的推理模块(逻辑、数学、语言、常识等)
- 动态路由:设计基于注意力机制的智能路由系统
- 协同训练:开发新的多任务学习范式
研究方案三:元推理优化器
研究方法
- 元学习框架:采用MAML等元学习算法训练优化器
- 推理轨迹分析:收集和分析大量推理轨迹数据
- 在线优化:开发实时推理路径优化算法
研究方案四:认知负载感知推理系统
研究方法
- 用户建模:构建用户认知能力评估模型
- 自适应生成:开发根据用户需求调整输出的算法
- 交互式优化:通过用户反馈持续改进
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!