目录
Resource Info Paper https://openreview.net/pdf?id=qZMLrURRr9 Code & Data / Public ICML Date 2025.06.26
Main Content
Eureka 在 ERL 中应用了协同优化的想法,用于奖励生成:EA 将 LLM 生成的奖励函数进行群体进化,而 RL 则用于训练策略来评估最佳 reward function。但是 Eureka 具有两个限制:
- Greedy Exploitation: Eureka 仅根据每次迭代的最佳 reward function 而改善,这可能会导致奖励函数不是最优的结果。
- Suboptimal Parameter Assignment: Reward functions 通常包含许多参数,例如权重或系数。Eureka 借助于 LLM 直接进行设置,这通常是次优的。这样可能导致无法提供精确的知道。
作者为了解决上述问题,进一步扩展 ERL,提出了 R*
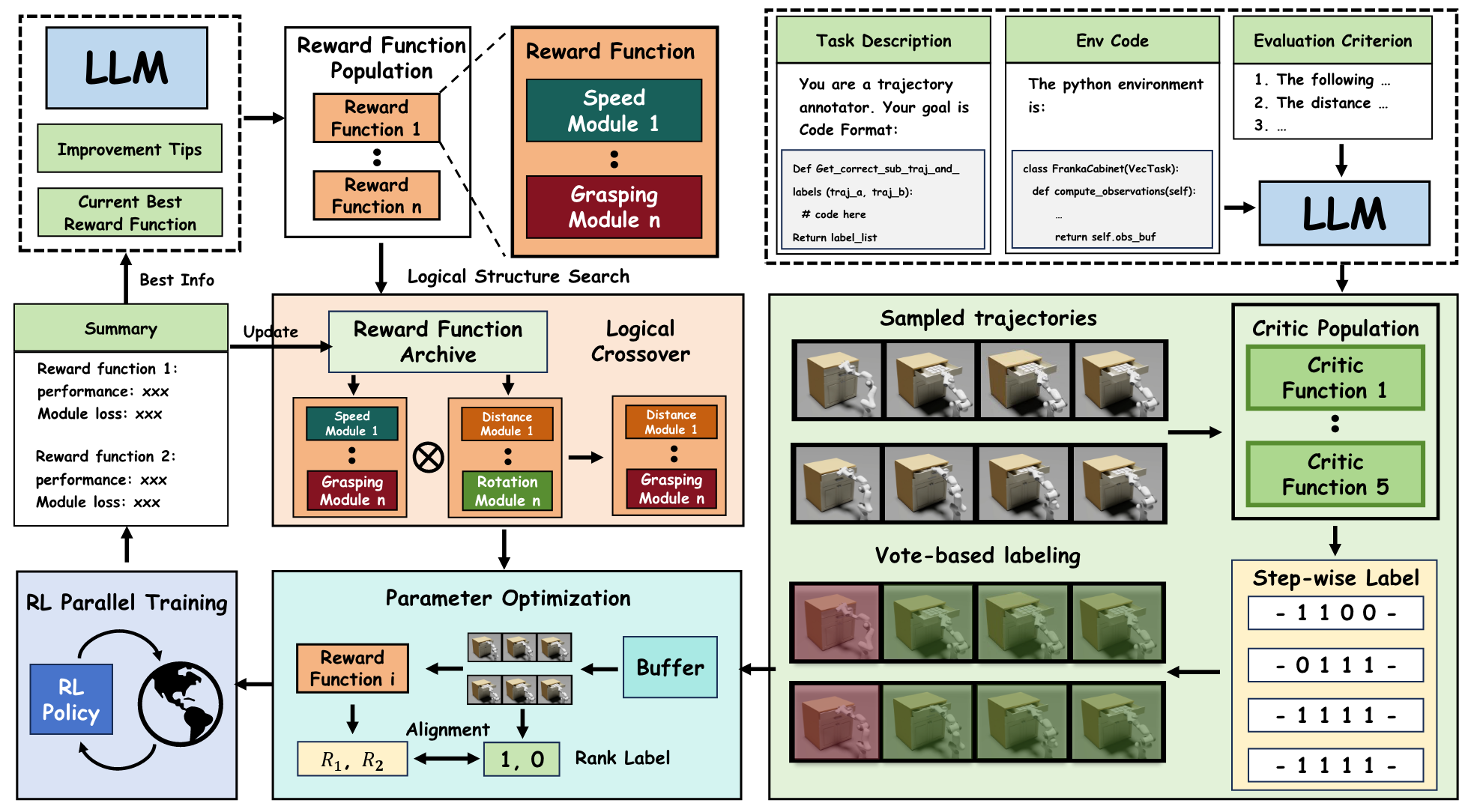
Two Stages: the initialization stage and the evolutionary improvement stage.
The initialization stage consists of two key steps: (1) Initializing the reward function population, which provides the foundation for subsequent reward function design; (2) Initializing the critic population, wich is used to collect trajectory segment pairs with high-quality labels.
- Rward Population Initialization. R* leverages LLM to generate the initial reward function population by providing the task description and environment code infomation . To facilitate more efficient structure search in subsequent stages, we design the prompt to guide the LLM in generating reward functions composed of multiple reward modules.
- Critic Population Initialization. In addition to the reward population, R* also needs to generate a critic population , with each individual represented as a code function. These critics are used to compare trajectories and provide step-wise comparison labels. Similar to the reward population, R* takes task descriptoins , environment code , and the prompt as inputs to generate the critic population .
After completing the initialization stage, we proceed to the reward function evolutionary improvement stage, which consists of three steps: population evaluation, evolution, and parameter optimization.
- Reward Population Evaluation. For each reward function in the reward population , we train PPO in parallel to solve the task using Isaac Gym. During training, we record the success rates of the learned policies, along with other relevant statistics, such as the mean, maximum, and minimum values of each reward module. The reward functions, along with their fitness values, are then stored in the reward function archive . The success rate of the policy serves as the reward function fitness.
- Reward Population Evolution. We select the reward function with the highest fitness, along with its associated learning information, to serve as feedback. Through the LLM reflection mechanism, we perform evolution operations such as modifying, deleting or adding modules to improve the reward function, thereby creating a new improved reward function. To fully exploit the high-quality reward functions discovered, we select parent reward functions from the reward function archive based on their fitness. Module-level crossover is then applied to these parents to generate new individuals, facilitating further exploration of the reward design space.
- Reward Parameter Optimization. Using the critic population , we extract trajectory segments and apply comparision labels to the segments, creating a labeled trajectory buffer . The reward functions are then optimized based on , allowing them to better evaluate segment quality and guide policy learning.

Experiments
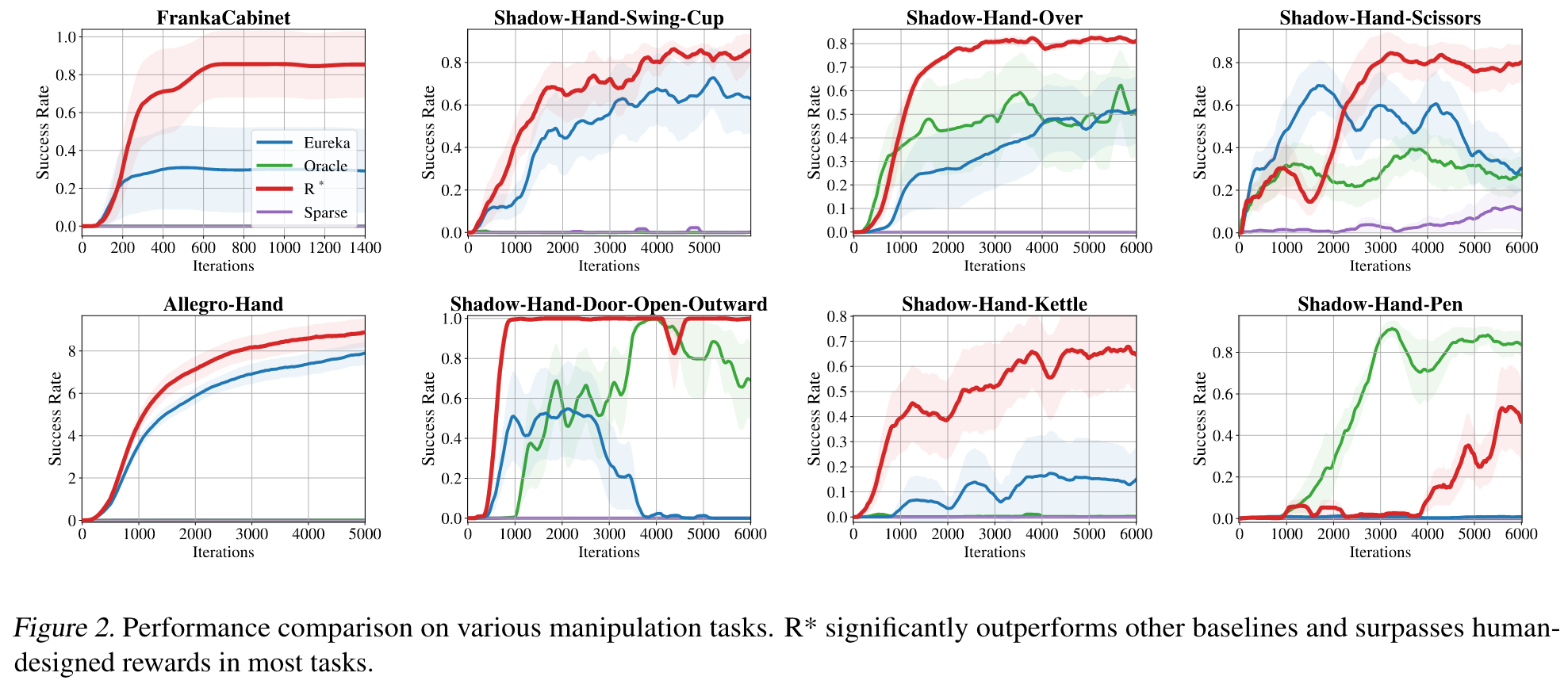
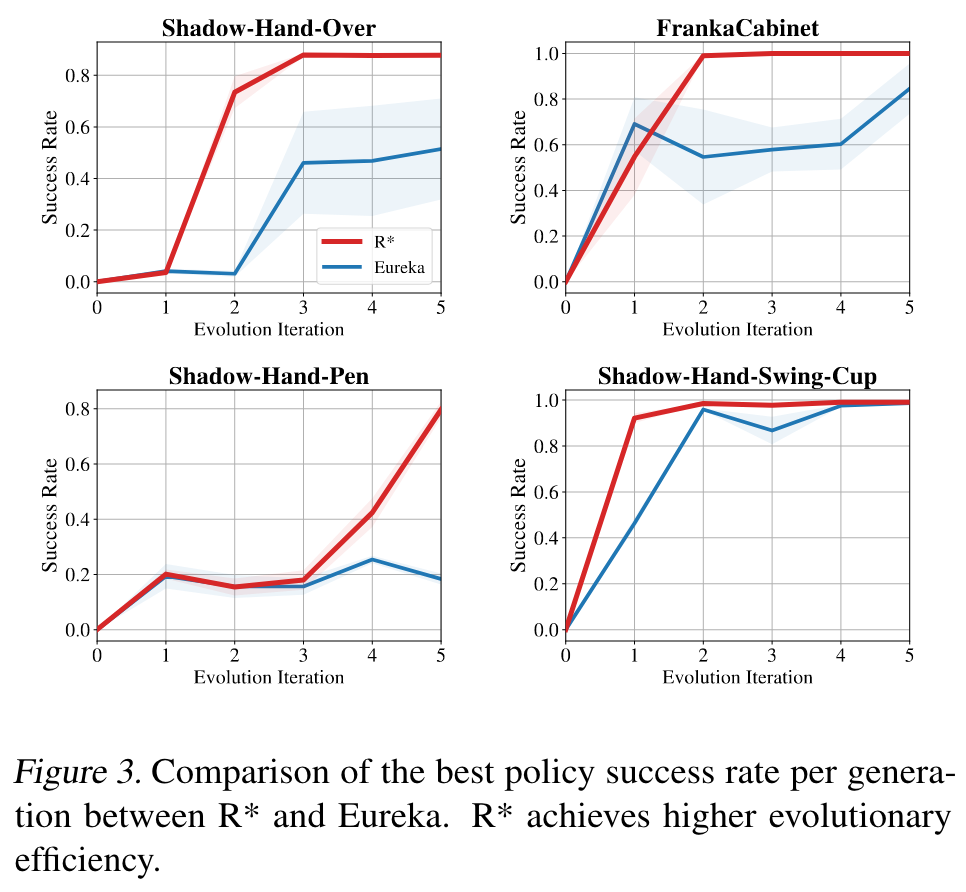
🤖
-
论文的创新之处与独特性:
- 创新点1:奖励函数设计的分解与模块化方法
本文提出了一种名为R*的框架,将奖励函数设计分解为两个独立的阶段:奖励结构演化和参数对齐优化。通过模块化的奖励函数设计,结合模块级别的交叉操作和LLM(大型语言模型)的反思机制,极大提升了奖励函数的搜索效率和学习稳定性。这种模块化设计思路为复杂任务的奖励函数优化提供了新的视角。 - 创新点2:基于LLM的奖励函数生成与优化
本文首次系统性地将LLM引入奖励函数生成和优化流程中,利用其强大的编码能力和领域知识生成高质量的奖励函数,并通过LLM辅助的模块改进、删除和添加操作实现奖励函数的持续优化。 - 创新点3:基于投票机制的轨迹分段标注
提出了基于批评函数的逐步投票机制,用于对轨迹分段进行高置信度的标注。通过结合多个批评函数的结果,解决了单一函数标注质量不高的问题,为奖励函数参数优化提供了可靠的训练数据。 - 创新点4:实验证明R*超越人类设计的奖励函数
在8个机器人控制任务中的实验结果表明,R*生成的奖励函数在性能和收敛效率上均优于现有强基线方法(如Eureka)和人类设计的奖励函数,这证明了其在复杂任务中的实际应用潜力。
- 创新点1:奖励函数设计的分解与模块化方法
-
论文中存在的问题及改进建议:
- 问题1:对LLM的依赖性较高
R*框架中大量依赖LLM的生成能力,包括奖励函数和批评函数的生成。然而,LLM生成的代码可能存在语法或逻辑错误,尽管文章提到通过交叉生成补充失败的个体,但这种方法可能增加计算成本。
改进建议:引入自动化代码验证和修复机制,例如通过静态代码分析或小规模环境测试提前发现并修复错误,降低LLM生成代码的失败率。 - 问题2:模块化交叉操作的随机性较强
虽然模块级别的交叉操作在探索奖励函数设计空间时表现出一定的有效性,但其随机性可能导致生成的个体质量不稳定。
改进建议:在交叉操作中引入启发式策略,例如基于模块性能的权重分配,优先选择高质量模块进行交叉,从而提高新个体的整体质量。 - 问题3:对真实世界任务的适应性不足
本文的实验主要基于模拟环境,假设低层信息(如距离、速度)完全可用。但在真实世界任务中,通常只能获取高层视觉信息,这限制了方法的通用性。
改进建议:探索将视觉语言模型(VLM)与R框架结合,利用视觉特征提取方法(如YOLO)从图像中提取关键变量,进一步扩展R在真实场景中的适用性。 - 问题4:缺乏对生成奖励函数的可解释性分析
尽管R*生成的奖励函数在性能上优于人类设计的奖励函数,但未深入分析这些奖励函数的结构特性(如模块的贡献度)。
改进建议:引入奖励函数的可解释性分析框架,例如通过模块重要性分析或特征归因方法,揭示奖励函数中关键模块的作用。
- 问题1:对LLM的依赖性较高
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:引入多模态信息的奖励函数设计框架
将视觉和语言模型(如VLM和LLM)结合,用于处理仅有视觉观测的复杂任务。例如,通过视觉模型提取关键物体的位置信息,再结合LLM生成奖励函数。 - 创新点2:自适应模块化奖励函数生成方法
开发一种动态模块化生成方法,根据任务需求实时调整奖励模块的数量和类型,避免冗余模块对学习效率的影响。 - 创新点3:奖励函数的可解释性增强机制
建立奖励函数的可解释性分析框架,量化每个模块对整体性能的贡献,并通过可视化工具展示奖励函数的优化过程。
- 创新点1:引入多模态信息的奖励函数设计框架
-
为新的研究路径制定的研究方案:
-
研究路径1:引入多模态信息的奖励函数设计框架
研究方法:- 使用视觉模型(如YOLO或CLIP)提取任务场景中的关键特征(如物体位置、目标距离)。
- 将提取的特征转化为结构化变量,并输入LLM生成奖励函数。
- 在模拟环境和真实机器人任务中验证生成奖励函数的有效性。
研究步骤:
- 数据准备:收集包含视觉信息的机器人任务数据集。
- 模型训练:训练视觉模型以提取任务关键特征。
- 框架设计:将视觉模型与R*框架结合,实现奖励函数的多模态生成。
- 性能评估:在多种任务中比较多模态奖励函数与单模态奖励函数的性能差异。
期望成果: - 提出一种适用于视觉观测任务的奖励函数生成框架。
- 实验证明多模态信息能够提高奖励函数的质量和学习效率。
-
研究路径2:自适应模块化奖励函数生成方法
研究方法:- 基于任务描述和环境反馈,动态调整奖励模块的数量和类型。
- 使用强化学习或元学习方法优化模块选择策略。
研究步骤:
- 模块生成:设计一组通用的奖励模块库。
- 策略优化:训练一个元学习模型,根据任务反馈选择最优的模块组合。
- 实验验证:在多种任务中测试自适应模块化方法的性能。
期望成果: - 提出一种动态模块化奖励函数生成方法,显著提高复杂任务的学习效率。
- 实现模块选择的自动化,减少对人类专家的依赖。
-
研究路径3:奖励函数的可解释性增强机制
研究方法:- 使用特征归因方法(如Shapley值或集成梯度)分析奖励函数中各模块的贡献度。
- 设计可视化工具展示奖励函数优化过程和模块的重要性。
研究步骤:
- 分析方法开发:选择适合奖励函数的归因方法,并开发分析工具。
- 可视化设计:设计交互式界面,展示奖励函数的结构和优化过程。
- 实验验证:通过用户研究评估可解释性工具对开发者的帮助。
期望成果: - 提出一种奖励函数的可解释性分析框架,帮助开发者理解和优化奖励函数。
- 提供可视化工具,提升奖励函数设计的透明性和可信度。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!