目录
Resource Info Paper http://arxiv.org/abs/2506.18254 Code & Data https://github.com/openbmb/RLPR Public arXiv Date 2025.08.11
Summary Overview
现有的 verifier 基本上都是建立在 math 或者 code 这种很容易进行验证的任务上。为了进一步推动强化学习在更多领域上的应用,很明显需要 General Verifier 来进行协助。为了应对挑战,作者的关键观察是LLM产生正确的自由形式答案的内在概率直接表明其对推理奖励的评估。作者提出了使用模型自身在 ground truth 上的概率来表示其推理路径是否正确,从而实现一种能在广泛领域应用的 verifer,并且这样这样不会引入额外的模型,并且获得了不错的效果。
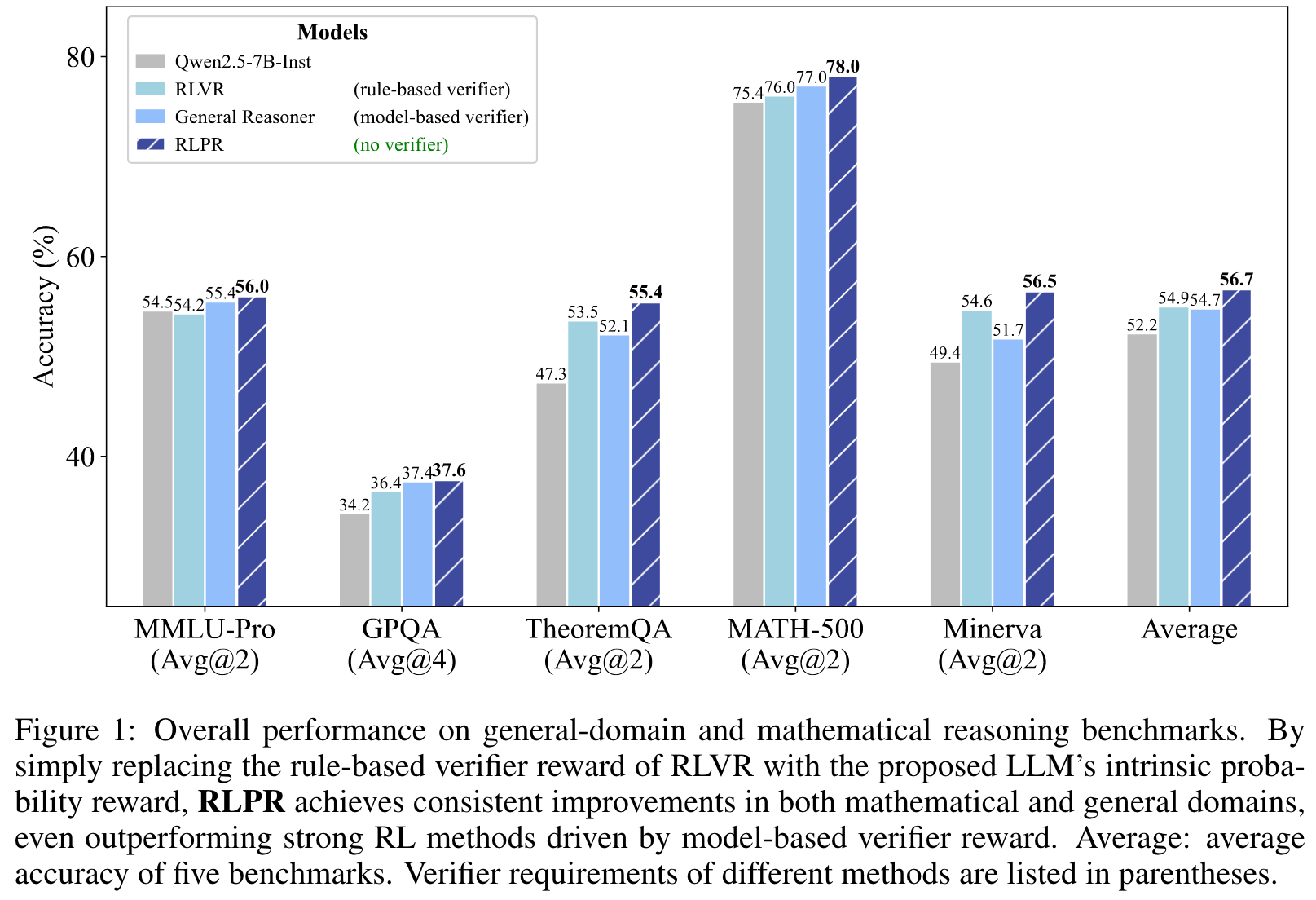
Related Work
Self-Reward Optimization Unsupervised reinforcement learning on language models using the policy model its self as a reward has recently emerged as an embarrassingly effective approach. The common idea behind the practice of self-reward is raising the probabilities of consistent answers, intuitively from the observation that concentrating on the majority brings fee improvements. Recent literature shows that entropy minimization, which naively degrades generation diversity, is a sugar for reasoning tasks, though restricted to certain model families. However, such practice might be prob-lematic for restricting exploration. In contrast to self-rewarding methods that remove diversity to exploit existing reasoning ability, our apporach builds the reward based on the reference answer, yielding reasoning performance with healthy token entropy from the clip-high trick.
Main Content
The basic insight is that LLM's intrinsic probability of generating a correct answer directly indicates its own evaluation of the reasoning reward.
RLPR introduces two key innovations:
- At the reward modeling level, we propose a simple and scalable alternative to the explicit reward from external verifiers with an instrinsic Probability-based Reward (PR), calculated by the average decoding probabilities of the reference answer tokens.
- At the training level, we propose an adaptive curriculum learning mechanism to stabilize training.
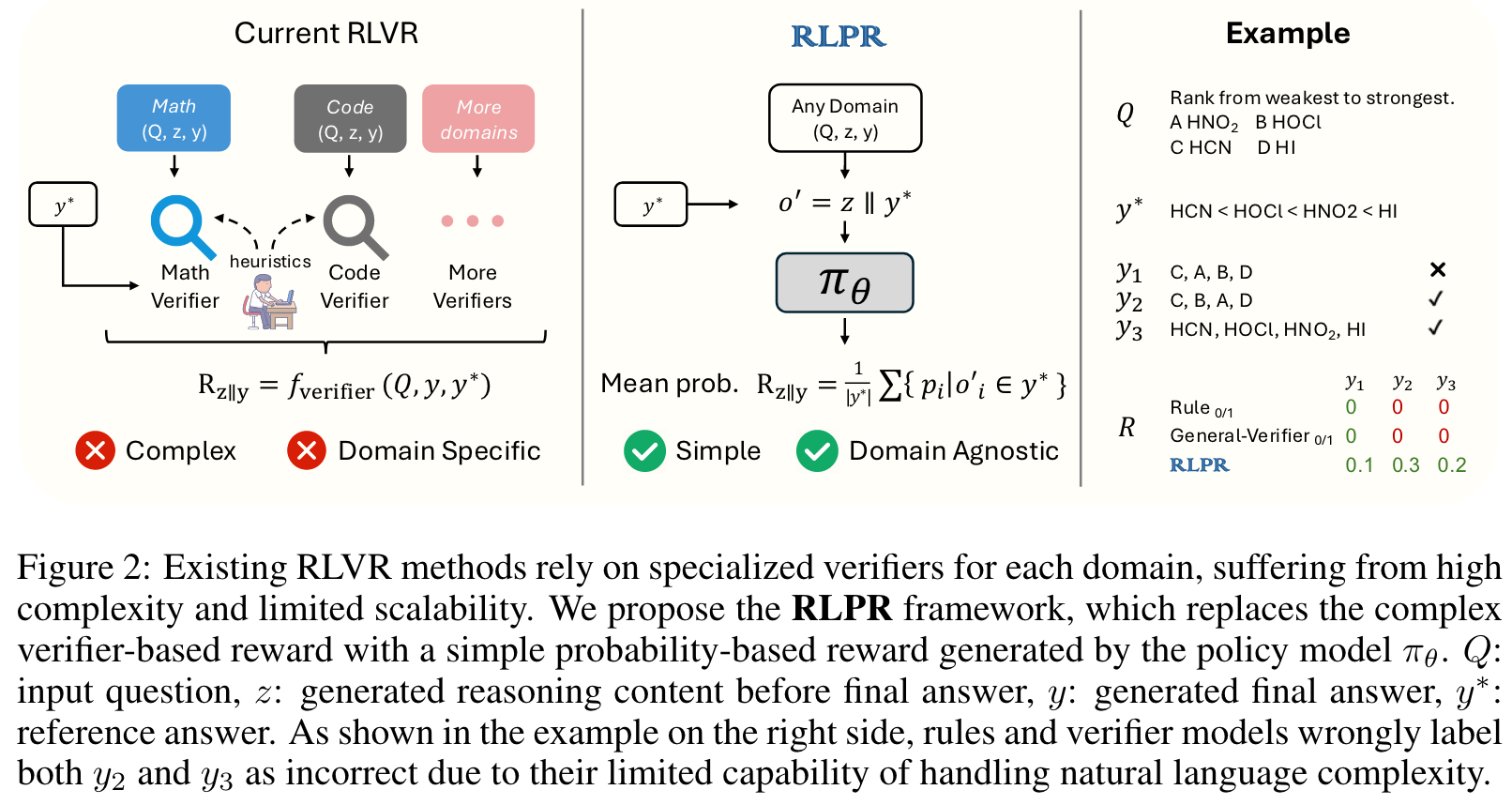
Contributions:
- We present RLPR, a simple and scalable framework that extends RLVR to general domains without using external verifiers.
- We propose a novel probability reward that eliminates the need for external verifiers and achieves better reward quality than naive likelihood as a reward.
- We introduce a novel standard deviation filtering strategy that effectively stabilizes training by removing samples with low reward standard deviation.
- We conduct comprehensive experiments to demonstrate that effectiveness of the proposed framework on various base models from Qwen, Llama and Gemma.
Probability Reward
2.2 概率奖励
受到大型语言模型(LLM)生成正确答案的内在概率直接表明其对推理质量的内部评估这一观察的启发,我们使用参考答案的逐词元解码概率作为奖励信号。与依赖特定领域验证器的现有方法(Cui et al., 2025a; Luo et al., 2025a)不同,这些方法需要大量的人工启发式方法和工程努力来构建验证器,我们的奖励计算过程仅涉及模型本身。
我们用 表示对问题 的每个响应,其中 是响应中的单个词元。为了获得概率,我们首先从完整响应序列中提取生成的答案 ,并将剩余内容表示为推理 。然后,我们通过用训练数据中的参考答案替换生成的答案来构建修改后的序列 。将此序列输入策略模型以获得概率 。概率奖励计算如下:
其中 将逐词元概率聚合为响应 的单一奖励标量。虽然使用 (概率的归一化乘积,即序列似然)反映了参考答案的整体似然,但我们观察到它引入了高方差,并且对微小变化(如同义词)过于敏感。例如,词元概率序列 和 在乘积下产生了截然不同的分数,尽管只有第一个词元存在微小差异。为了解决这个问题,我们改为采用 (平均概率),这产生了更稳健的奖励信号,并在我们的分析中展现出与答案质量更好的相关性(见图4)。我们观察到概率奖励值与生成答案 的质量高度一致,当预测答案在语义上与参考答案相似时获得高奖励,否则分配低奖励。请注意,长度归一化步骤对于GRPO(Shao et al., 2024)来说是多余的,但对于不包含组归一化的算法(如REINFORCE++(Hu et al., 2025a))可能至关重要。
Reward Debiasing
尽管基于概率的奖励与响应质量强相关,但它们也受到各种潜在因素的影响。我们将概率奖励 的贡献者记为 ,它本质上可以分解为两个潜在因素:
其中 表示推理内容的影响,而 捕获其他相关因素的特征,包括问题和参考答案。直接使用 作为奖励会引入与未观察因素 相关的偏差,可能降低奖励质量。为了缓解这个问题,我们引入基础分数 ,通过使用公式2计算直接解码参考答案 的概率分数,而不使用中间推理 。这给出 ,去偏的概率奖励计算如下:
其中裁剪操作确保奖励保持在有利的数值范围 内。这个公式有效地消除了来自 和 的潜在偏差,并将PR建模为给定生成推理 时概率的改进。我们观察到这个去偏步骤稳定了训练并增强了奖励的鲁棒性。我们目标函数的最终梯度估计器是:
其中我们优化整个响应 上的期望奖励。
Experiments
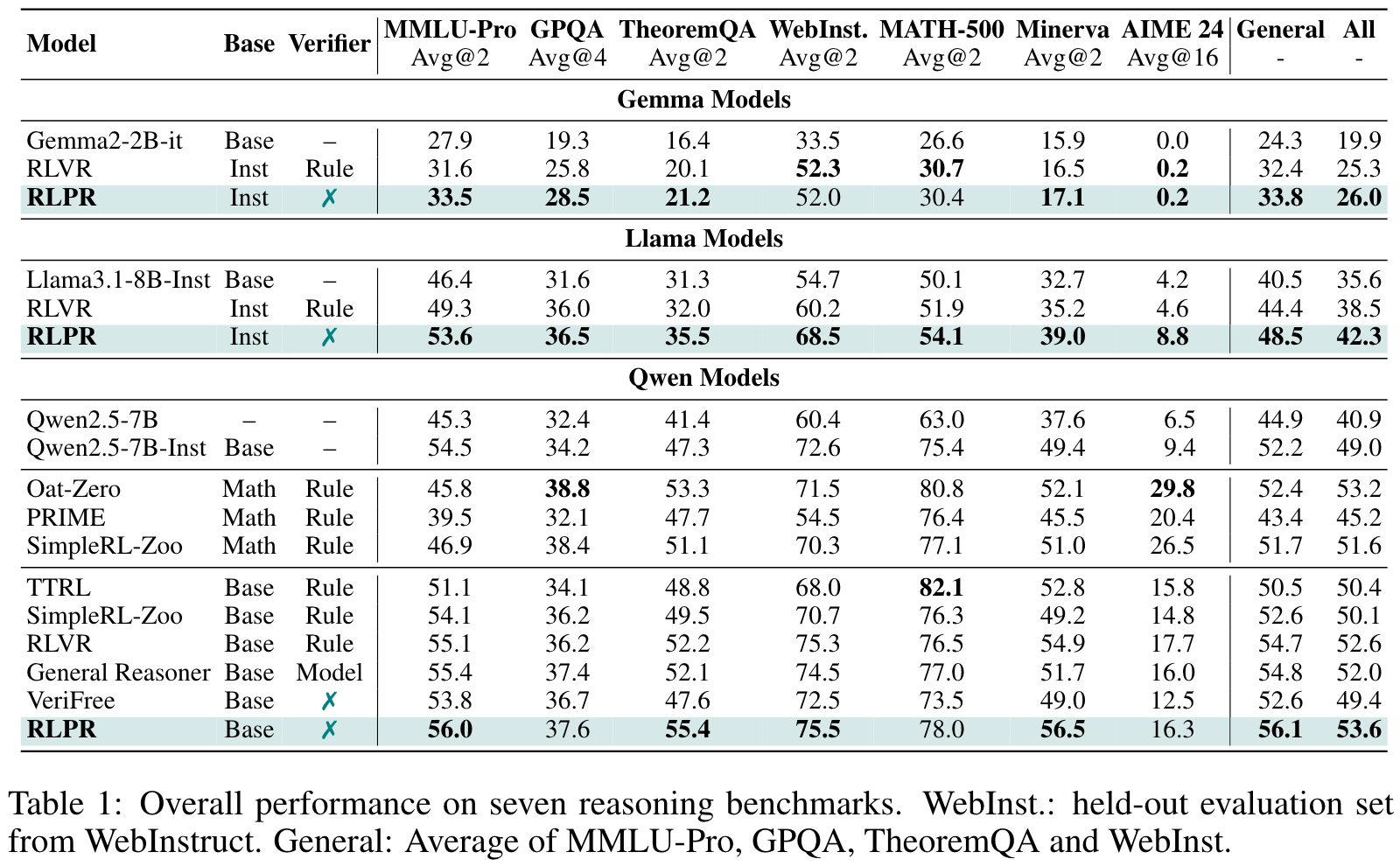
Benchmarks
- Math reasoning: MATH-500, Minerva, AIME 24
- General domains: MMLU-Pro, GPQA, TheoremQA, WebInstruct
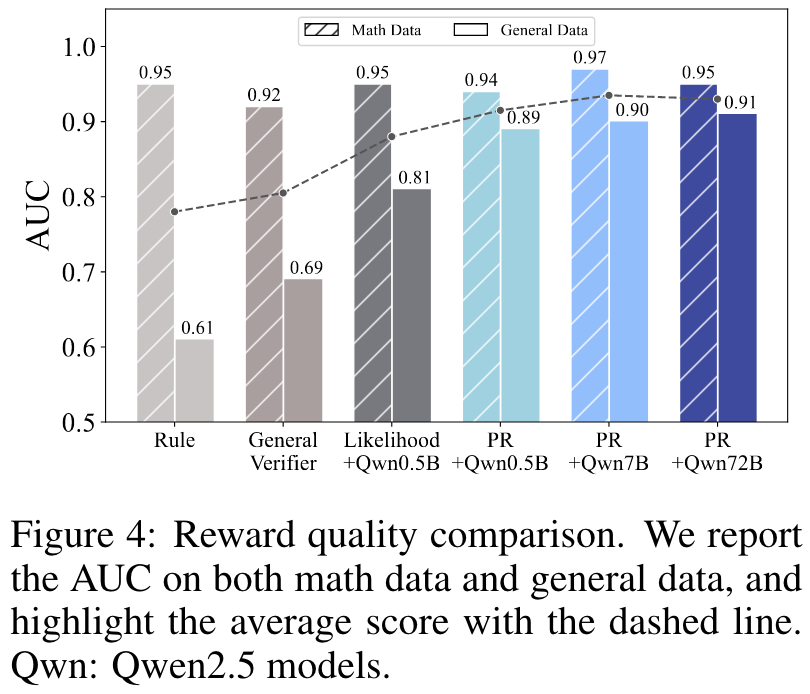
PR discriminates correct responses better than the rule-based verifier on general data. 为了评估不同奖励能够区分正确和错误回复的能力(即,将更高的奖励分配给纠正回复),作者根据各自的奖励对每个提示的回复与人工标注的 ground truth 进行 ROC-AUC 计算。
Ablation Study
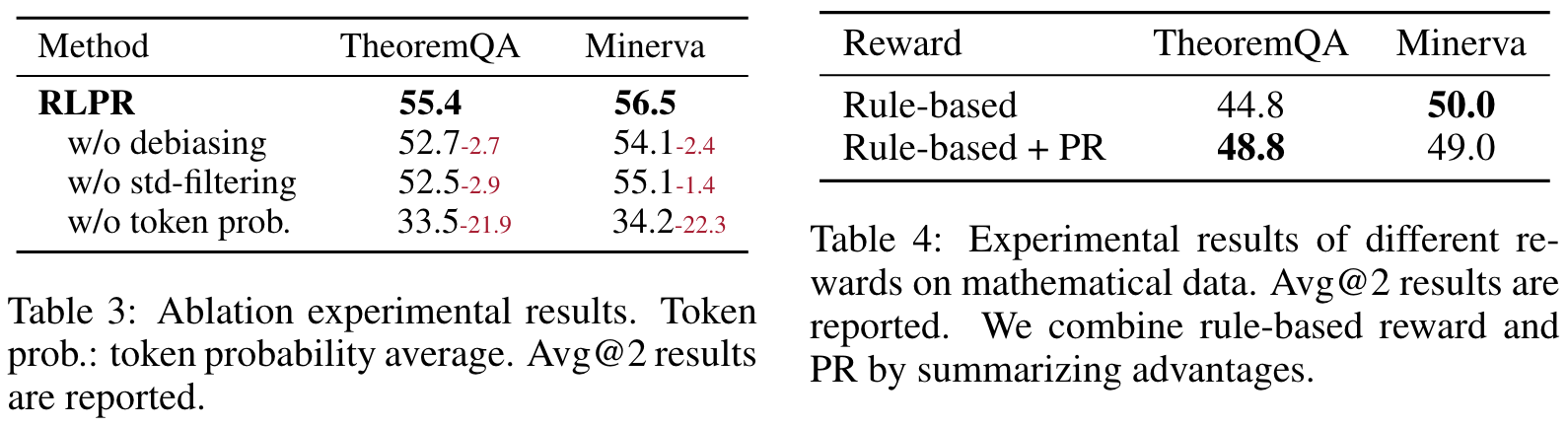
🤖
-
论文的创新之处与独特性:
- 创新点1:无验证器的奖励框架
论文提出了RLPR(Reinforcement Learning with Reference Probability Reward)框架,通过使用LLM的内在概率(Intrinsic Probability)作为奖励信号,取代传统的基于领域验证器的奖励机制。这种方法消除了对外部验证器的依赖,显著降低了复杂性并提高了可扩展性。 - 创新点2:概率奖励建模与去偏处理
提出了基于每个token概率的奖励信号,并通过去偏机制(Reward Debiasing)消除因问题或参考答案带来的偏差,从而增强了奖励的鲁棒性和稳定性。 - 创新点3:标准差过滤机制
论文设计了一种基于标准差的过滤机制,通过动态调整过滤阈值,移除过于简单或复杂的样本,从而稳定训练过程并提高最终性能。 - 关键贡献
RLPR在多个通用领域和数学推理基准上表现出色,超越了现有的强验证器模型(如General Reasoner)和无验证器方法(如VeriFree),展现了其在大规模语言模型推理能力提升方面的潜力。
- 创新点1:无验证器的奖励框架
-
论文中存在的问题及改进建议:
- 问题1:对概率奖励的深入分析不足
虽然论文证明了概率奖励的有效性,但对其在不同模型规模、不同任务复杂度下的表现变化缺乏详细讨论。建议在未来研究中进一步分析概率奖励在不同场景下的适用性及其局限性。 - 问题2:标准差过滤机制的依赖性
标准差过滤机制虽然提高了训练稳定性,但可能限制了模型对复杂问题的学习能力。建议结合动态调整机制,引入更多多样化的过滤标准(如基于问题类型或领域的权重)。 - 问题3:跨领域泛化能力的验证不足
尽管RLPR在数学和通用领域表现优秀,但其在其他复杂领域(如多模态理解或跨语言任务)中的表现尚未充分验证。建议扩展实验范围,测试RLPR的跨领域泛化能力。
- 问题1:对概率奖励的深入分析不足
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:多模态推理扩展
探索RLPR框架在多模态任务中的应用,例如图像-文本任务或视频分析任务,通过结合多模态模型的内在概率奖励,实现跨模态推理能力的提升。 - 创新点2:动态奖励信号优化
设计一种基于任务动态调整的奖励机制,根据任务复杂度或模型推理的实时反馈调整奖励信号,从而进一步提高模型的适应性。 - 创新点3:自监督推理优化
结合RLPR的概率奖励信号,开发一种自监督学习框架,通过模型自身生成的答案与参考答案的对比,进一步优化推理能力。
- 创新点1:多模态推理扩展
-
为新的研究路径制定的研究方案:
-
研究路径1:多模态推理扩展
- 研究方法:
- 构建一个多模态数据集,包括图像-文本匹配任务、视频问答任务等。
- 使用预训练的多模态模型(如BLIP或Flamingo)作为基础模型。
- 在RLPR框架下,使用模型生成的文本概率作为奖励信号,并结合视觉特征的匹配概率,设计联合奖励机制。
- 研究步骤:
- 数据预处理与任务设计,确保多模态任务的多样性与挑战性。
- 训练模型并监控奖励信号的稳定性与任务性能。
- 对比RLPR与现有多模态推理方法的表现,分析其优势与不足。
- 期望成果: 提出一种适用于多模态任务的RLPR扩展框架,显著提升跨模态推理能力,并验证其在多模态基准上的有效性。
- 研究方法:
-
研究路径2:动态奖励信号优化
- 研究方法:
- 设计一种动态调整机制,根据任务复杂度或模型当前推理质量实时调整奖励信号。
- 在多个任务基准上测试动态奖励机制的效果,包括简单任务与复杂任务。
- 研究步骤:
- 定义任务复杂度指标(如问题长度、逻辑深度等)。
- 设计动态调整算法,并与RLPR的固定奖励机制进行对比实验。
- 分析动态调整机制对训练稳定性与模型性能的影响。
- 期望成果: 提出一种动态奖励优化算法,显著提高模型在不同任务复杂度下的适应性与推理能力。
- 研究方法:
-
研究路径3:自监督推理优化
- 研究方法:
- 使用RLPR框架结合自监督学习方法,设计一种基于模型自身生成答案与参考答案的对比优化机制。
- 在多个推理任务上测试自监督优化框架的效果。
- 研究步骤:
- 构建一个高质量的自监督训练数据集,包括复杂推理任务。
- 设计对比优化算法,通过奖励信号强化模型的推理能力。
- 分析自监督优化框架对模型性能与训练效率的影响。
- 期望成果: 开发一种基于RLPR的自监督推理优化框架,显著提升模型的推理能力,并减少对人工标注数据的依赖。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!