目录
Resource Info Paper http://arxiv.org/abs/2505.21493 Code & Data https://github.com/sail-sg/VeriFree Public arXiv Date 2025.08.14
Summary Overview
现在 RL 主要集中在 math 和 code 任务上,如果要泛化到其他领域往往需要一个 LLM 用来验证模型答案。但是这样可能存在 reward hacking 的问题,并且额外引入了一个 LLM 往往也会带来更多的计算资源开销问题。作者提出了一种不需要 verify model 的方法(VeriFree)在 RL 中进行训练。具体是将 reference answer 拼到模型生成的 reasoning path 后根据其概率计算相关指标作为 reward。
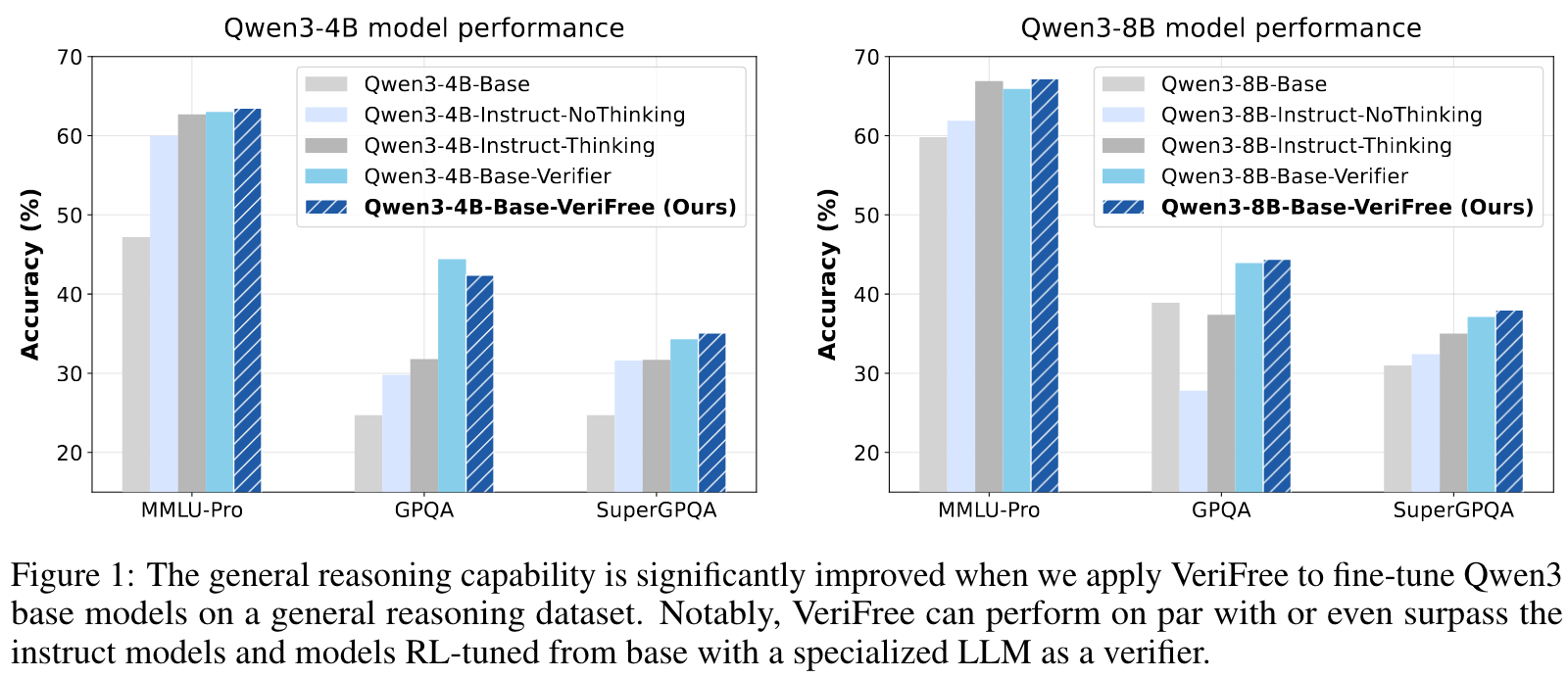
Main Content
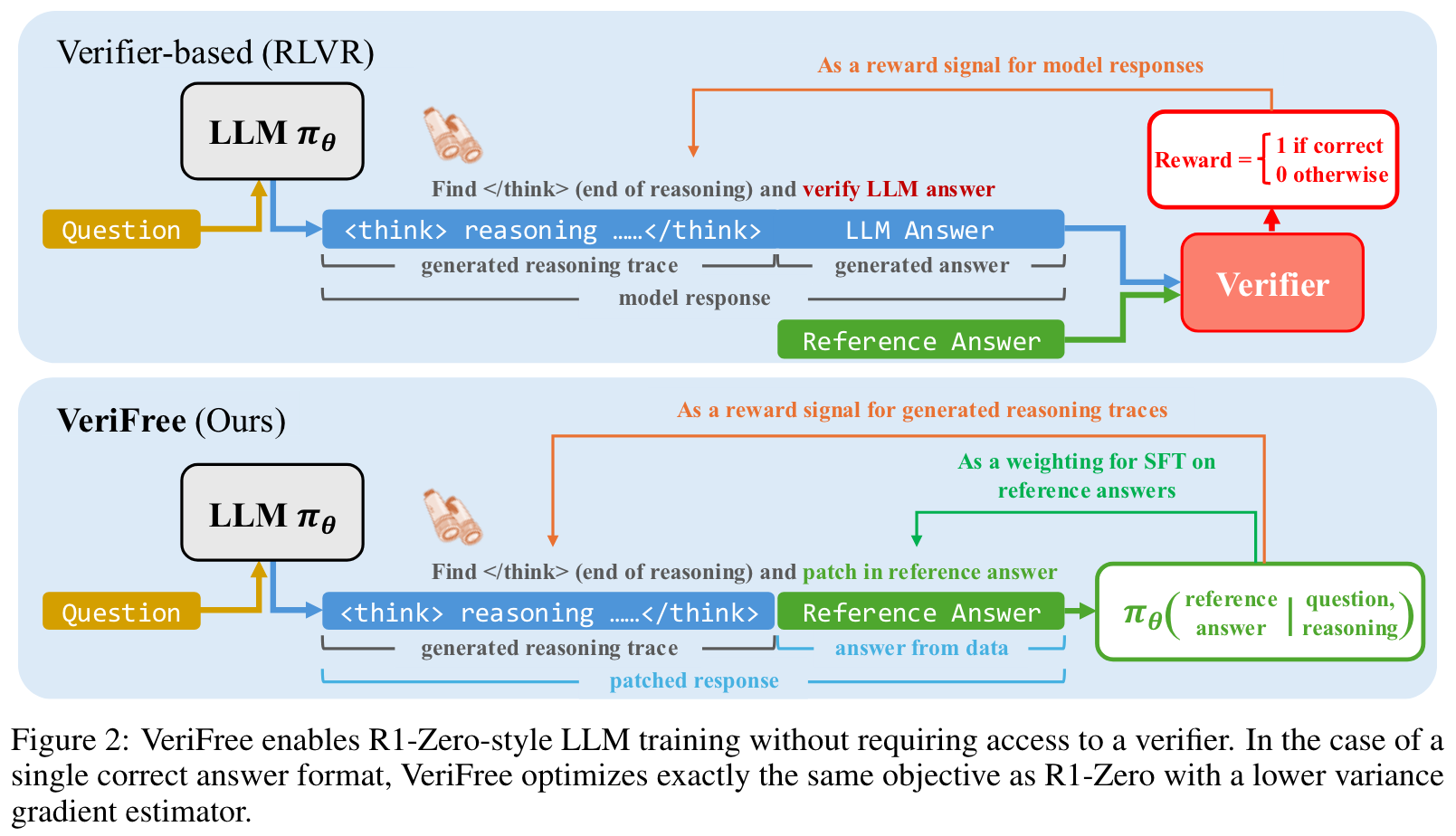
Reasoning is critical far beyond math and coding; however, the difficulty of answer verification in general reasoning tasks poses a major obstacle to applying this training paradigm to broader domains. To address this limitation, we investigate how to extend R1-Zero-style training to tasks where rule-based answer verification is not possible.
Given a question, we only generate the reasoning trace and concatenate it with the reference answer from the dataset. We then evaluate the likelihood of the reference answer conditioned on the question and the generated reasoning trace. This likelihood serves both as a reward signal for policy gradients on the reasoning trace and as a weighting term for supervised training of the reference answer.
where , , and .

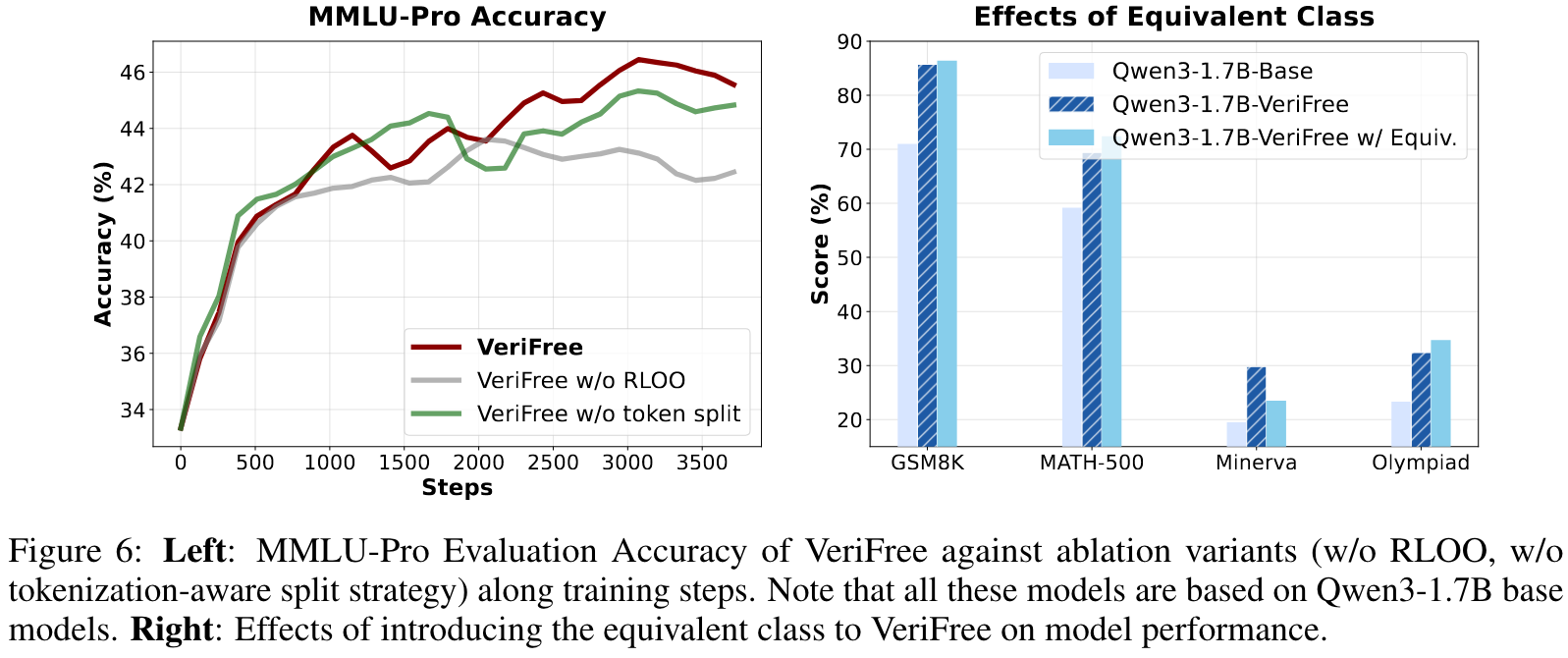
这篇文章也考虑到了一个很实际的问题,虽然解码出来的字符串我们能够很明显地知道哪一部分是 reasoning,哪一部分是 answer,但是在 tokenization 时,修改一两个字符串可能会对直接对整个 encode 出来的 token 造成巨大的影响。

Experiments
Evaluations: MMLU-Pro, SuperGPQA, GPQA, MATH-500, OlympiadBench, Minerva Math, GSM8K, AMC and AIME 24.
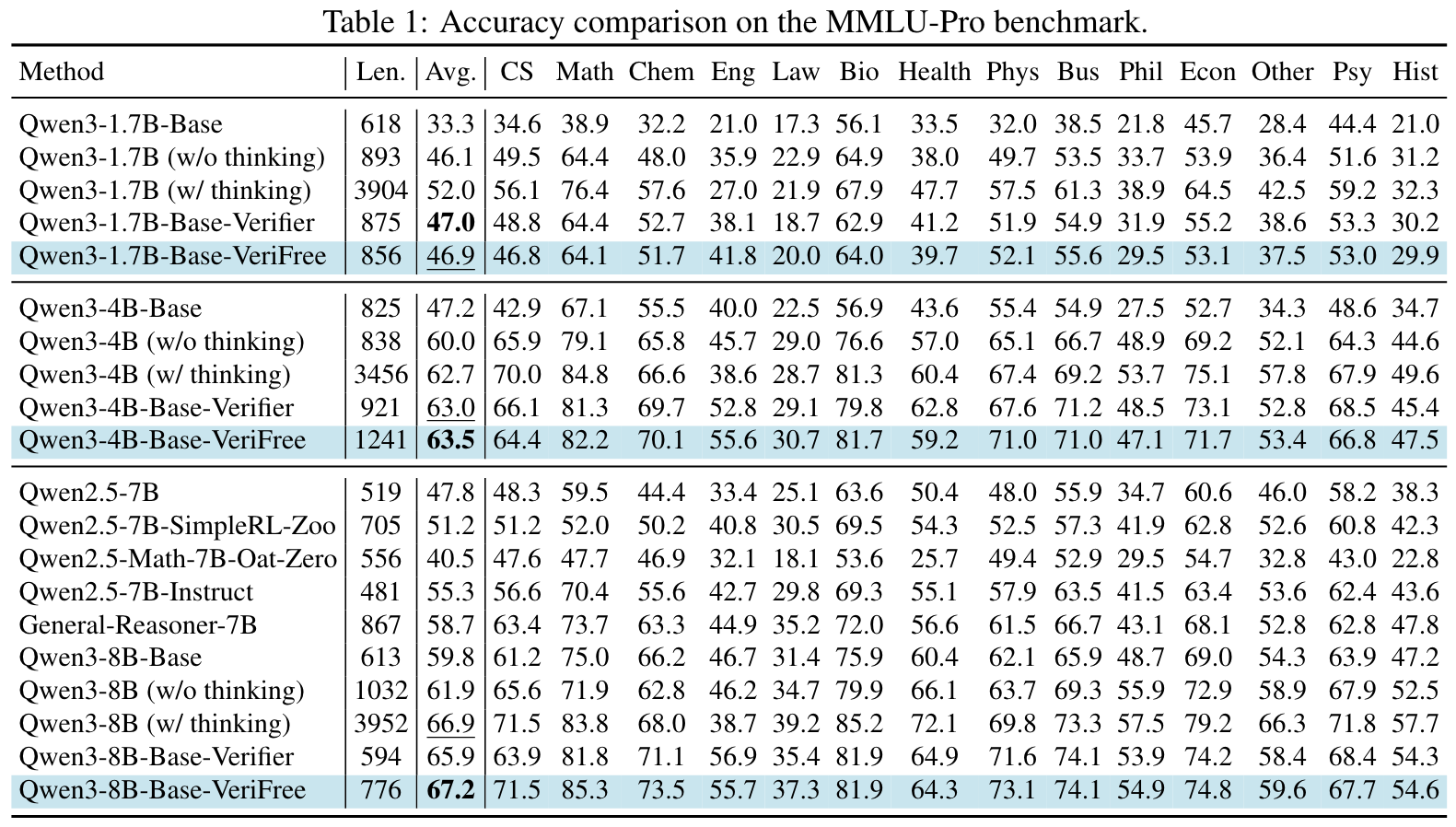
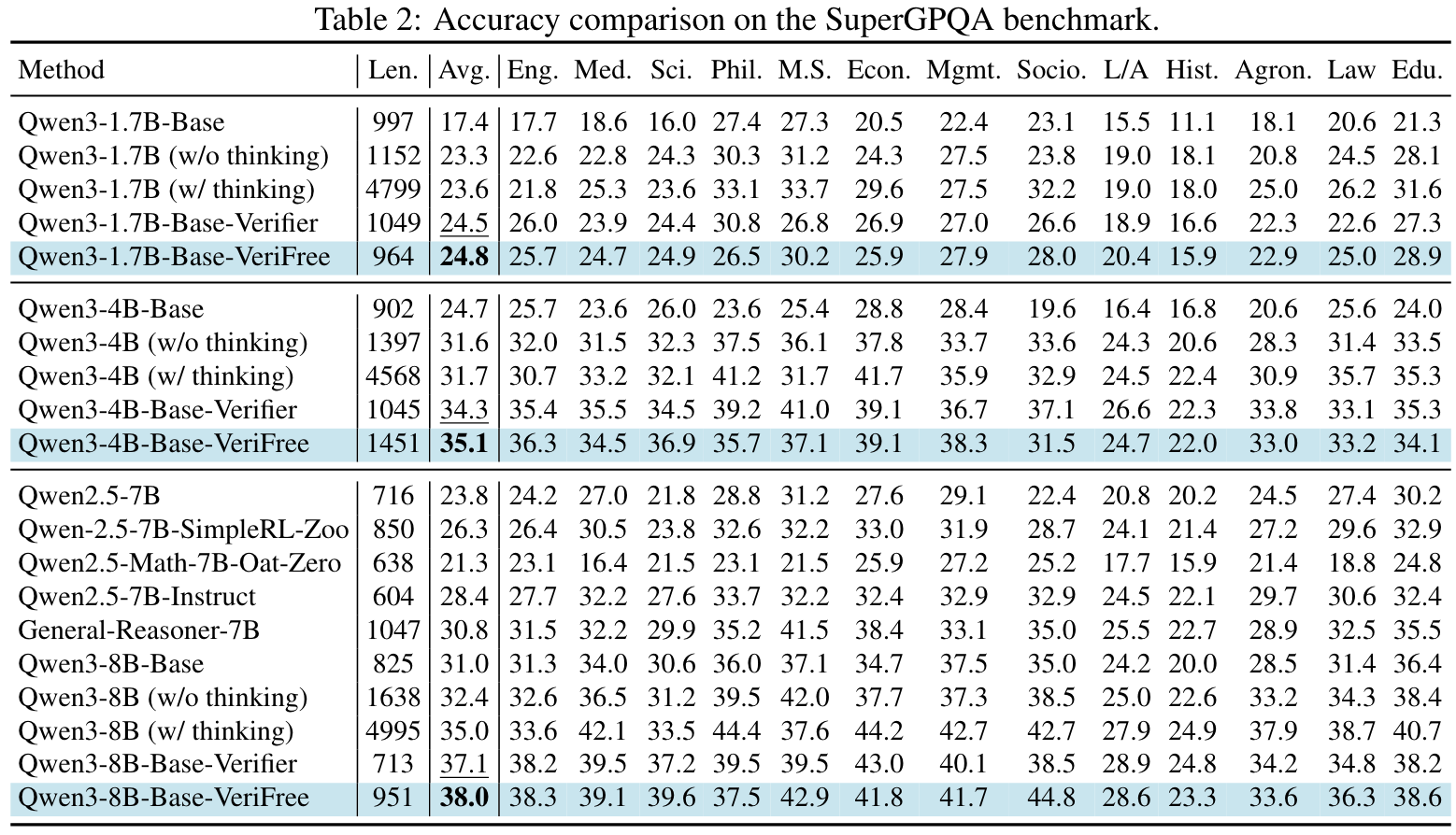
Main results:
- VeriFree improves general reasoning capabilities.
- VeriFree leads to better learning efficiency. VeriFree consistently outperforms the baseline, achieving higher accuracy with fewer training steps.
- Model confidence is a good reasoning capability proxy.
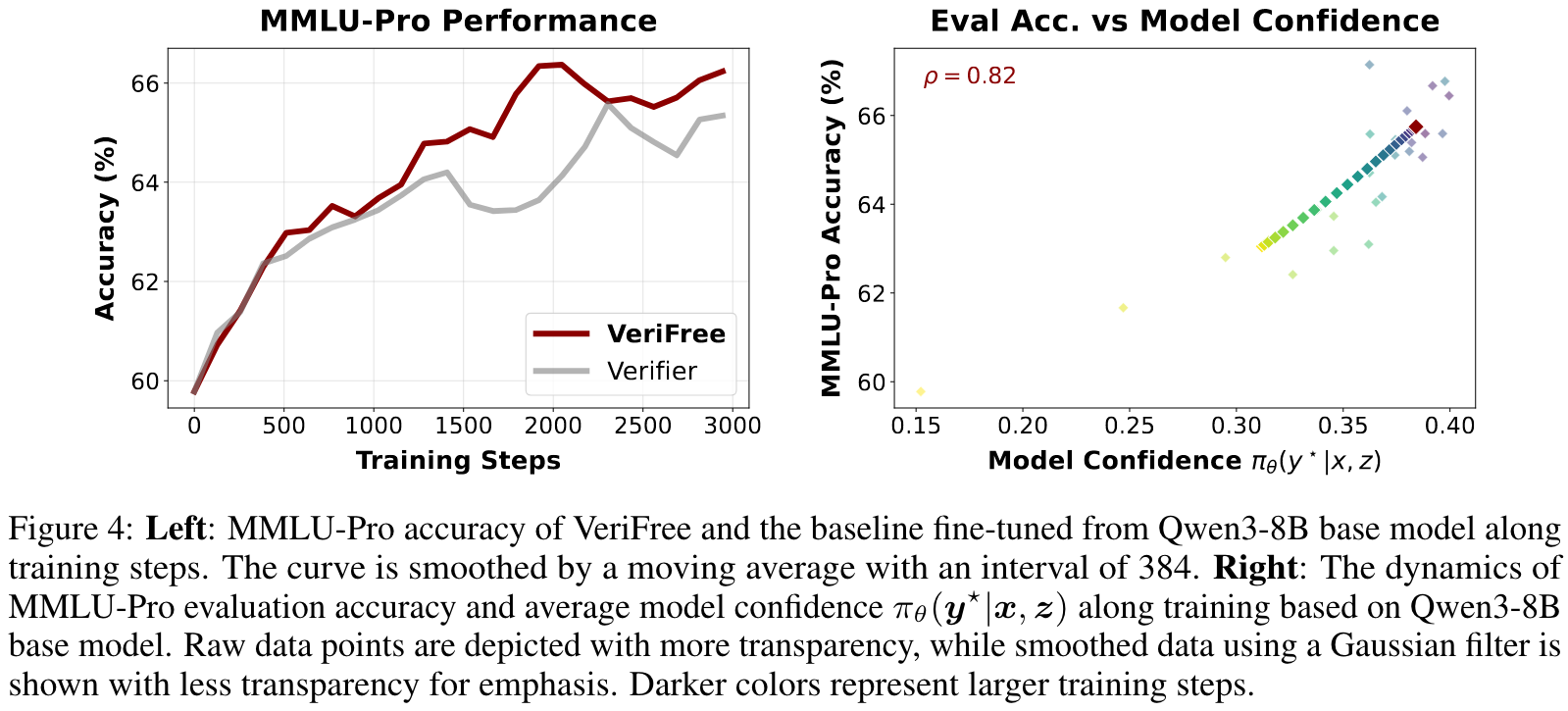
Ablation study:
🤖
-
论文的创新之处与独特性:
- 创新点:提出Verifier-Free方法(VeriFree)
论文通过取消对显式验证器的依赖,提出了一种无需规则或模型验证器的强化学习方法,用于训练大型语言模型(LLM)的通用推理能力。这种方法直接优化生成参考答案的概率,避免了传统方法中对验证器的依赖以及由此带来的计算负担和潜在的奖励欺骗问题。 - 理论贡献:梯度等价性与方差降低分析
论文基于唯一答案假设,推导了Verifier-Free优化目标的梯度等价性,并证明了该方法的梯度估计器相比传统Verifier方法具有更低的方差。这种理论分析为其方法的稳定性和高效性提供了坚实的数学基础。 - 实践贡献:更广泛的适用领域
VeriFree方法扩展了传统仅适用于数学和代码领域的R1-Zero风格训练范式,使其能够应用于化学、法律、经济学等难以进行规则验证的领域。 - 性能提升:在多项基准测试中的表现
实验结果表明,VeriFree不仅在多个推理任务中超越了基于验证器的方法,还显著减少了训练过程中的计算资源需求,提升了模型的学习效率。
- 创新点:提出Verifier-Free方法(VeriFree)
-
论文中存在的问题及改进建议:
- 唯一答案假设的局限性
VeriFree方法假设每个问题只有一个正确答案,这在实际应用中可能不够全面。例如,在开放性问答或多解问题中,参考答案可能具有多种形式。建议引入多答案处理机制,例如通过扩展等价类的定义来支持多种正确答案。 - 对复杂推理任务的适应性不足
尽管VeriFree在一般推理任务中表现良好,但其在处理多步骤复杂推理问题时的能力仍需进一步验证。改进建议包括结合链式推理(Chain-of-Thought)生成更长的推理路径,并优化推理路径质量。 - 数据质量的依赖性
论文使用了经过高质量过滤的数据集,但在实际场景中,数据质量可能难以保证。建议进一步研究如何在低质量或噪声数据环境下提升模型性能,例如引入鲁棒性训练机制或数据增强技术。 - 缺乏对跨领域迁移能力的深入探索
虽然论文展示了VeriFree的领域迁移能力,但实验主要集中在数学和一般推理任务上。建议进一步研究该方法在跨语言、跨模态推理任务中的适应性。
- 唯一答案假设的局限性
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 研究路径1:多答案支持的Verifier-Free优化
扩展VeriFree方法以支持多种正确答案形式,探索如何利用答案等价类来提升模型的推理能力。 - 研究路径2:结合链式推理的Verifier-Free方法
将链式推理(CoT)与VeriFree结合,通过优化推理路径的生成概率来提升复杂推理任务的性能。 - 研究路径3:跨模态Verifier-Free推理能力
探索VeriFree方法在跨模态推理任务(如文本与图像结合推理)中的应用,研究如何在多模态输入下优化模型的推理能力。
- 研究路径1:多答案支持的Verifier-Free优化
-
为新的研究路径制定的研究方案:
-
研究路径1:多答案支持的Verifier-Free优化
- 研究方法:
- 构建包含多种正确答案形式的训练数据集,定义答案等价类。
- 修改VeriFree的优化目标,使其能够同时优化多个参考答案的生成概率。
- 设计实验对比多答案支持的VeriFree与原始方法的性能差异。
- 研究步骤:
- 数据预处理:使用现有数据集扩展答案等价类。
- 模型训练:在扩展后的数据集上应用多答案支持的VeriFree方法。
- 性能评估:使用多领域基准测试(如MMLU-Pro、SuperGPQA)评估模型性能。
- 期望成果: 提出一种支持多答案的Verifier-Free方法,显著提升模型在开放性问答任务中的表现。
- 研究方法:
-
研究路径2:结合链式推理的Verifier-Free方法
- 研究方法:
- 使用链式推理生成推理路径,并将其与参考答案拼接。
- 优化推理路径生成概率,同时权衡路径质量与答案正确性。
- 比较链式推理增强的VeriFree方法与传统方法在复杂推理任务中的表现。
- 研究步骤:
- 数据扩展:引入需要多步骤推理的任务数据集。
- 模型训练:结合链式推理生成与VeriFree优化目标进行联合训练。
- 性能评估:使用复杂推理基准测试(如Minerva Math、OlympiadBench)评估模型性能。
- 期望成果: 提出一种结合链式推理的Verifier-Free方法,显著提升模型在复杂推理任务中的能力。
- 研究方法:
-
研究路径3:跨模态Verifier-Free推理能力
- 研究方法:
- 构建跨模态推理数据集(如文本与图像结合任务)。
- 修改VeriFree方法以支持跨模态输入,优化模型在多模态条件下生成正确答案的概率。
- 设计实验验证跨模态Verifier-Free方法的有效性。
- 研究步骤:
- 数据收集:构建文本与图像结合的推理任务数据集。
- 模型训练:在跨模态数据集上应用改进的VeriFree方法。
- 性能评估:使用跨模态基准测试(如VQA、图像描述任务)评估模型性能。
- 期望成果: 提出一种跨模态Verifier-Free方法,显著提升模型在多模态推理任务中的表现。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!