Resource Info Paper https://arxiv.org/abs/2401.05856 Code & Data https://figshare.com/s/fbf7805b5f20d7f7e356 Public CAIN Date 2024.01.05
这篇文章主要研究的是 RAG 系统,从 SE 的角度去研究 RAG 系统 (投的是 CAIN),并且总结了7个 FP (Failure Point)。
RAG system 的目的:
- 减少LLMs的幻觉问题;
- 将资料与生成的答复联系起来,即注入新的知识 (not finetuning);
- 消除用元数据注释文件的需要 (原文是 "remove the need for annotating documents with meta-data",个人不是很明白在讲哪方面😇);
两个重要的启示: (感觉是 SE 的相关看法)
- 只有在运行过程中才能对 RAG 系统进行验证;
- RAG 系统的稳健性是逐渐形成的,而不是一开始就设计好的;
We conclude with a list of potential research directions on RAG systems for the software engineering community. ——"Seven Failure Points When Engineering a Retrieval Augmented Generation System"
当涉及到新数据或是特定领域的知识时,LLMs 存在局限性。有两个解决方法:
- Finetuning
- RAG
文章主要探讨的问题:
- What are the failure points that occur when engineering a RAG system?
- What are the key considerations when engineering a RAG system?
RAG 的工作原理是将自然语言查询转换为嵌入式查询,然后用嵌入式查询对一组文档进行语义搜索。然后将检索到的文档传递给大型语言模型,生成答案。
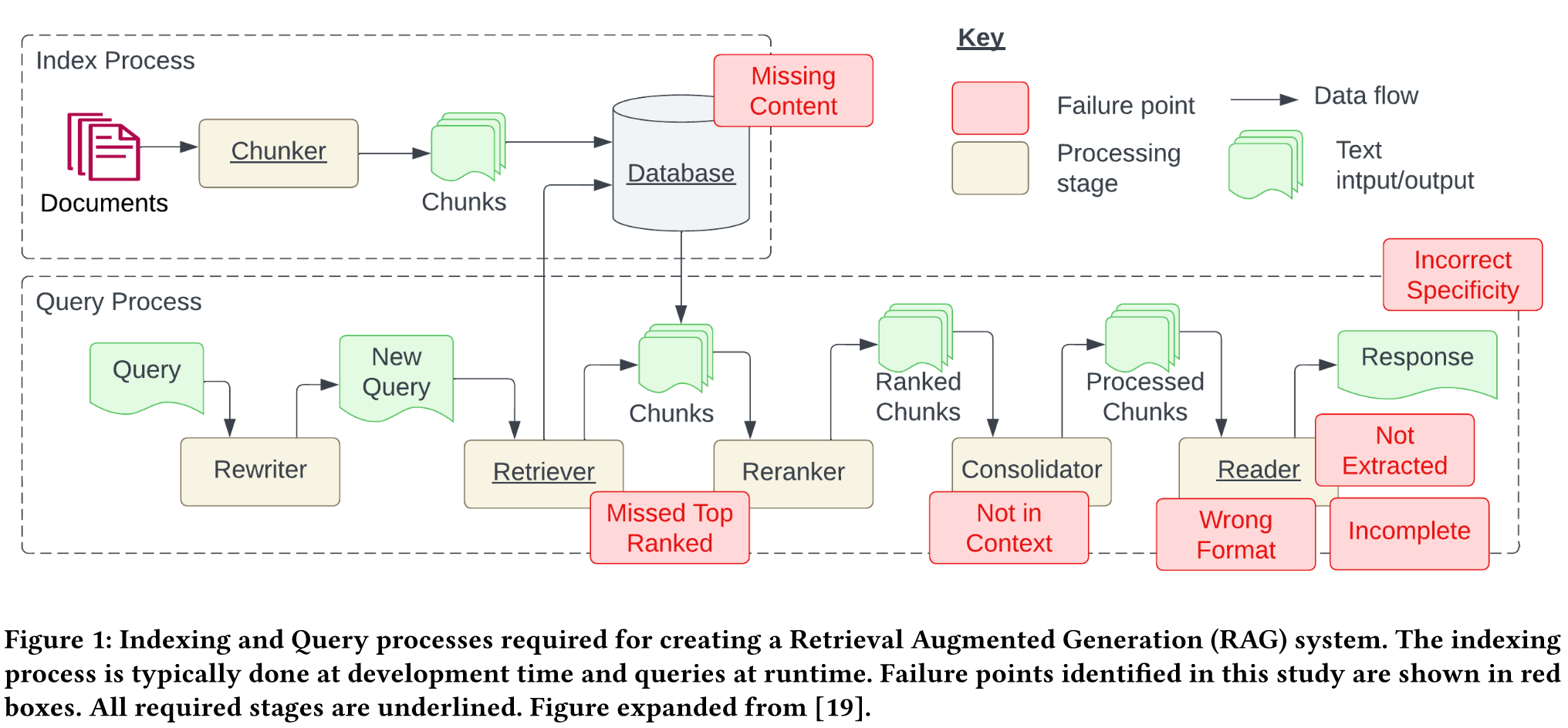
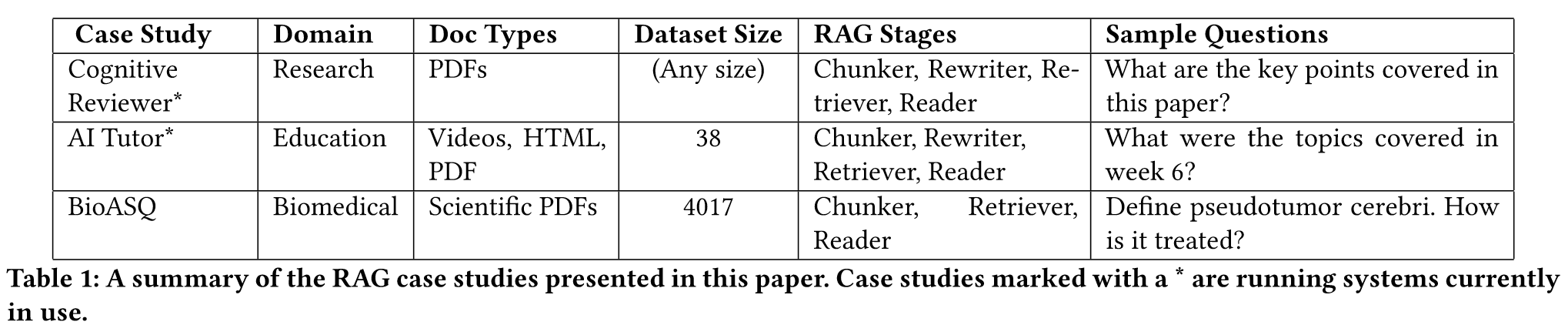
文中研究的3个 case:
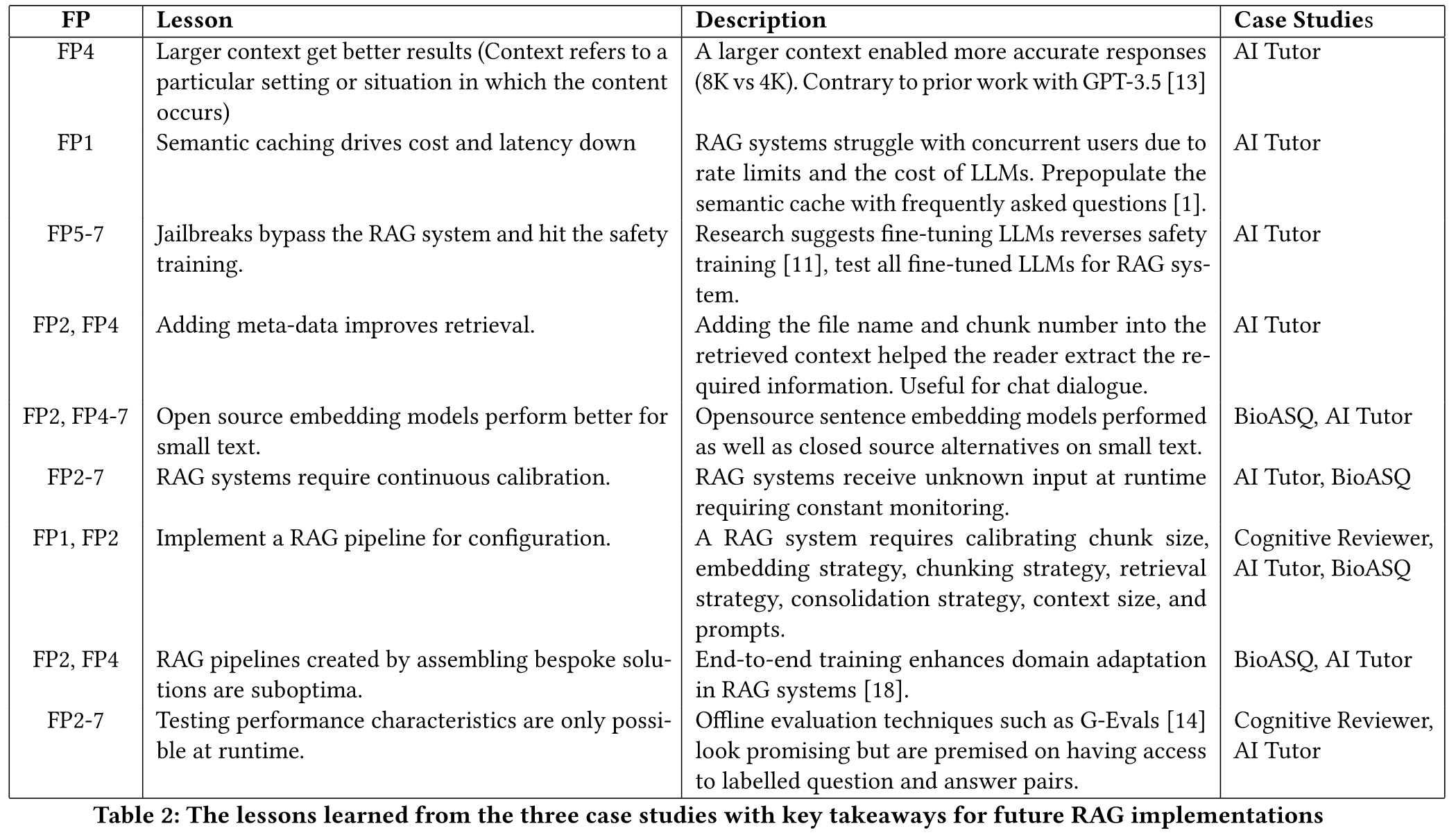
7 FPs:
- Missing Content 第一种失败情况是提出的问题无法从现有文件中找到答案。在这种情况下,RAG 系统会给出类似 "对不起,我不知道 "的回复。但是,对于与内容相关但没有答案的问题,系统可能会受骗上当,给出答复。
- Missed the Top Ranked Documents 问题的答案在文档中,但排名不够靠前,无法返回给用户。理论上,所有文档都会被排序并用于下一步。但在实际操作中,会返回排名前 K 的文档,其中 K 是根据性能选择的值。
- Not in Context - Consideration strategy Limitations 从数据库中检索到有答案的文档,但没有生成答案。这种情况发生在从数据库返回许多文档并进行合并处理以检索答案时。
- Not Extracted 在这种情况下,上下文中存在答案,但大语言模型未能提取出正确答案。通常情况下,当上下文中存在过多噪音或矛盾信息时,就会出现这种情况。
- Wrong Format 该问题涉及以表格或列表等特定格式提取信息,而大型语言模型忽略了该指令。
- Incorrect Specificity 答案在回复中返回,但不够具体或过于具体,无法满足用户的需求。当 RAG 系统设计者对给定问题(如学生的教师)有预期结果时,就会出现这种情况。在这种情况下,应在提供答案的同时提供具体的教育内容,而不仅仅是答案。当用户不确定如何提问而过于笼统时,也会出现不正确的具体性。
- Incomplete 不完整的答案并非不正确,而是遗漏了部分信息,即使这些信息在上下文中可以提取。例如,"文件 A、B 和 C 中涉及的要点是什么?更好的方法是分别提出这些问题。
同时文中还专门讨论了 6.1 Chunking and Embeddings。个人认为也是在 RAG 中需要重视的部分,万物皆可 Embedding😋,而 Chunking 听起来很简单而往往被忽略掉。
Chunking and Embeddings:
-
给文档分块听起来微不足道。然而,分块的质量会在很多方面影响检索过程,尤其是分块的嵌入会影响分块与用户查询的相似度和匹配度。分块有两种方法:基于启发式的分块(使用标点符号、段落结尾等)和语义分块(使用文本中的语义来告知分块的起点和终点)。进一步的研究应探讨这些方法之间的权衡及其对嵌入和相似性匹配等关键下游流程的影响。建立一个系统的评估框架,在查询相关性和检索准确性等指标上对分块技术进行比较,将使该领域受益匪浅。
-
嵌入是另一个活跃的研究领域,包括为多媒体和多模态块(如表格、数字、公式等)生成嵌入。在系统开发过程中或为新文档编制索引时,通常会创建一次块嵌入。查询预处理会极大地影响 RAG 系统的性能,尤其是在处理负面或模糊查询时。需要进一步研究架构模式和方法,以解决嵌入的固有局限性(匹配的质量取决于具体领域)。
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!