目录
Resource Info Paper http://arxiv.org/abs/2312.10302 Code & Data https://github.com/pldlgb/nuggets Public ArXiv Date 2024.03.25
Summary Overview
当前的指令调优实践通常依赖于扩展数据集大小,而没有明确的策略来确保数据质量,这可能会无意中引入噪声并降低模型性能。
为了应对这一挑战,我们引入了 NUGGETS,这是一种新颖且高效的方法,它采用一次性学习从广泛的数据集中选择高质量的指令数据。
Nuggets 利用基于候选示例对不同锚集的复杂度的影响的评分系统,有助于选择最有益的数据以进行指令调整。
Main Content
尽管用于指令调整的数据集的大小有所增加,但一些工作表明较小但有价值的数据集往往更有效地利用法学硕士的能力。
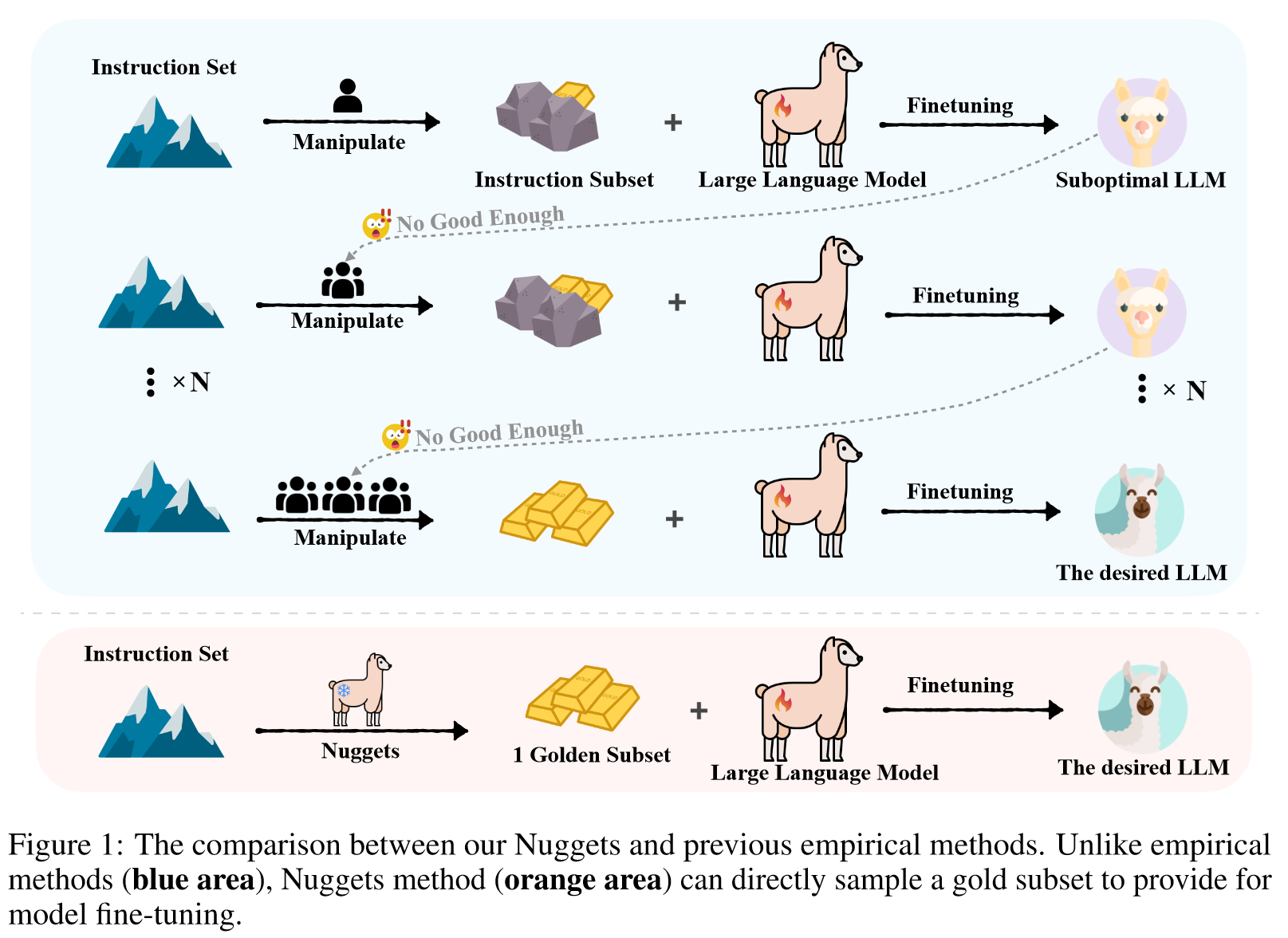
我们相信,在大量可用数据中存在最佳指令组合,但识别它们的高效、低成本方法却很少被探索。
Nuggets,一种简单而有效的方法,利用法学硕士本身作为数据探索者,通过一次性(上下文)学习,从庞大的教学数据集中选择有益的数据。
具体来说,我们首先选择一个涵盖多个任务的集合作为锚集,其余示例作为候选集。依次从候选集中选择一个示例作为上下文学习的一次性示例,然后通过观察其对每个锚示例的困惑度的影响来评分。该分数可以推断anchor和候选示例之间的依赖关系,并作为数据选择的参考标准。
Contributions:
- In this paper, we introduce Nuggets, a method that adaptively assesses the quality of instruction examples using large language models. Nuggets enables us to extract the most valuable data from a vast pool of instruction data for the purpose of fine-tuning.
- With the proposed Nuggets, a series of superior model fine-tuning results are achieved by using only 1% instruction examples. This provides strong evidence for the effectiveness of our strategy compared to using entire 100% examples.
- Comprehensive experiments indicate that our assumptions regarding golden instructions are well-founded. This insight may potentially provide some guidance for future endeavors in data quality screening.
在本文中,我们提出大型语言模型 (LLM) 可以通过上下文学习隐式地充当谨慎地数据探索者,这样可以进一步指导自己识别必要的训练样本。
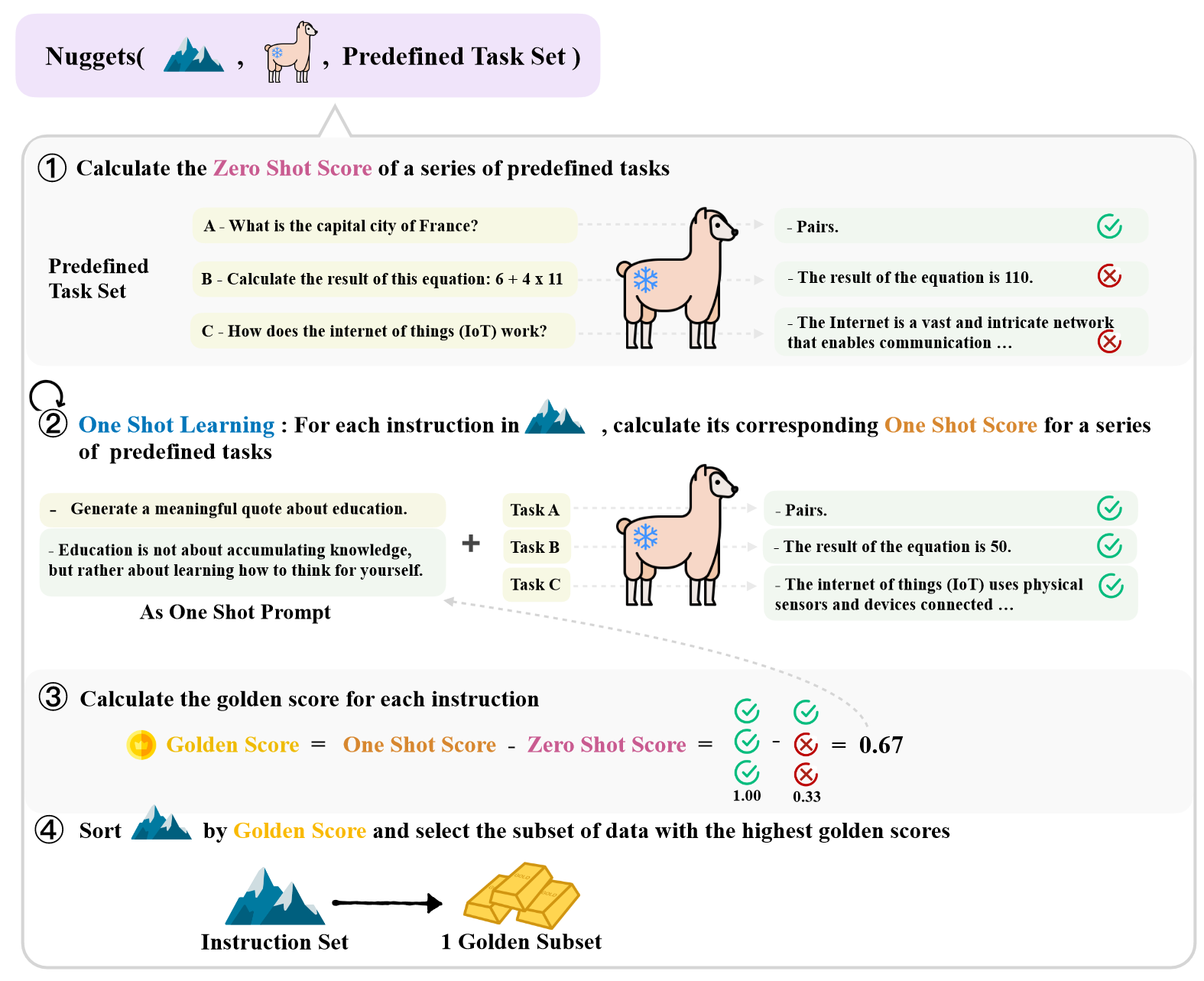
首先,我们使用一组预定义的任务(表示为零样本分数)评估大型语言模型在各种任务上的熟练程度。然后,我们将指令数据集中的每个示例作为一次性提示,将其连接在预定义任务的前面,并重新计算模型对这些任务的完成水平,称为一次性分数。通过利用一次射击和零次射击分数之间的差异,我们可以计算每条指令的黄金分数。一旦我们获得了所有指令的黄金分数,我们就可以选择得分最高的子集作为黄金子集,然后将其直接提供给模型进行微调。
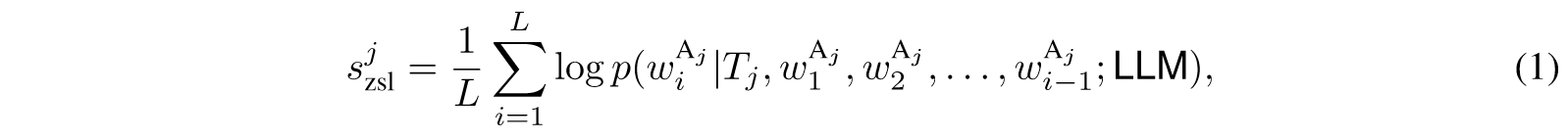
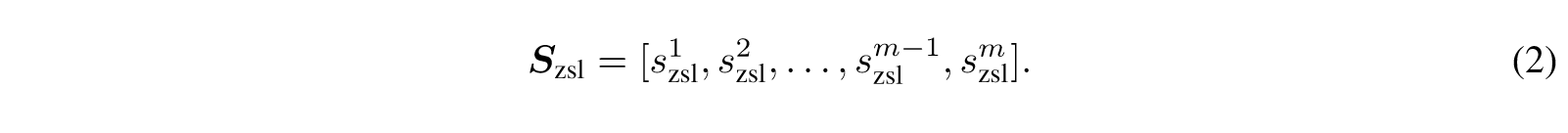

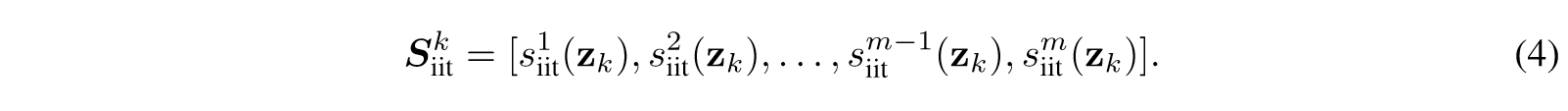
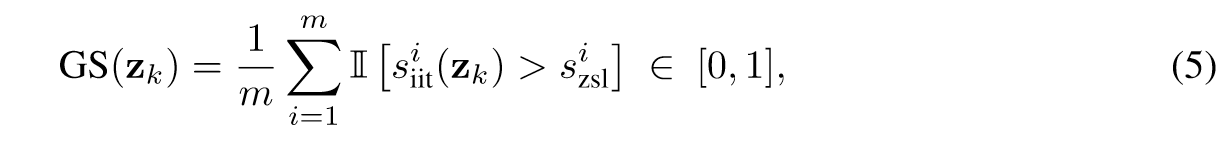
Related Work
Instruction Construction
以前的方法的微调指令数据集通常是手动创建的或针对特定任务定制的。
- Self-Instruct:从初始任务池中随机选择了一些实例,并将它们用作演示来指示语言模型生成新指令以及相应的输入输出。
- Evo-Instruct:以逐步的方式逐步修改原始指令,从而可以精确控制生成指令的难度和复杂性。
- Tree-Instruct:通过指示LLM将指定数量的新节点附加到现有指令的语义树而不是直接操作文本序列来指导它们。
另一方面,一些研究侧重于通过利用更少但更高质量的指令示例来增强语言模型的性能。
- LIMA:通过战略性地选择一千个高质量数据点进行学习,展示了强大性能
- InstructMining:引入了一组选定地自然语言指标,用于评估指令跟踪数据质量
- ALPAGASUS:利用外部强大模型ChatGPT的功能来直接评估每个示例
Experiments
Metrics
- MT-Bench: 评估八个类别的指令跟踪能力:写作、角色扮演、提取、推理、数学、编码、STEM 和人文学科
- Aplaca-Eval: 将模型生成的响应与 Davinci-003 响应进行比较。该数据集使用win_rate作为评估指标。
Models
LLaMa-7b
Datasets
-
Alpaca dataset / Alpaca-GPT4
鉴于 Alpaca 数据集自然地表现出这些特征,我们从中随机选择了 1,000 个示例来形成预定义的任务集。
-
MT-Bench
-
Aplaca-Eval
Baselines
LLaMa-7b
Results
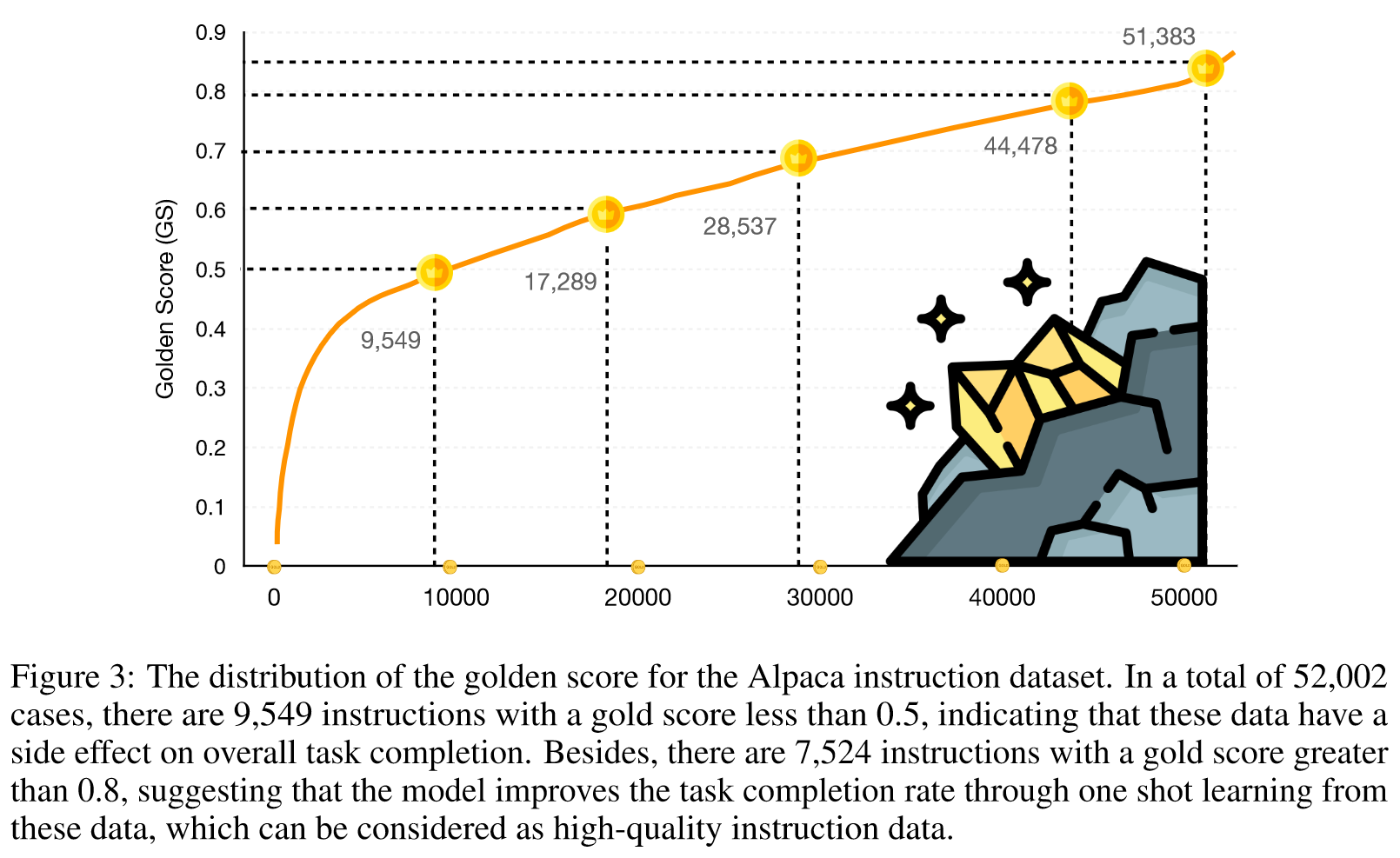
我们使用具有黄金分数的不同示例子集对 LLaMA 进行指令调整:小于 0.5、大于 0.5、大于 0.8、大于 0.85 以及完整数据集。微调模型分别命名为Alpaca≤0.5、Alpaca>0.5、Alpaca>0.8、Alpaca>0.85和Alpacafull。
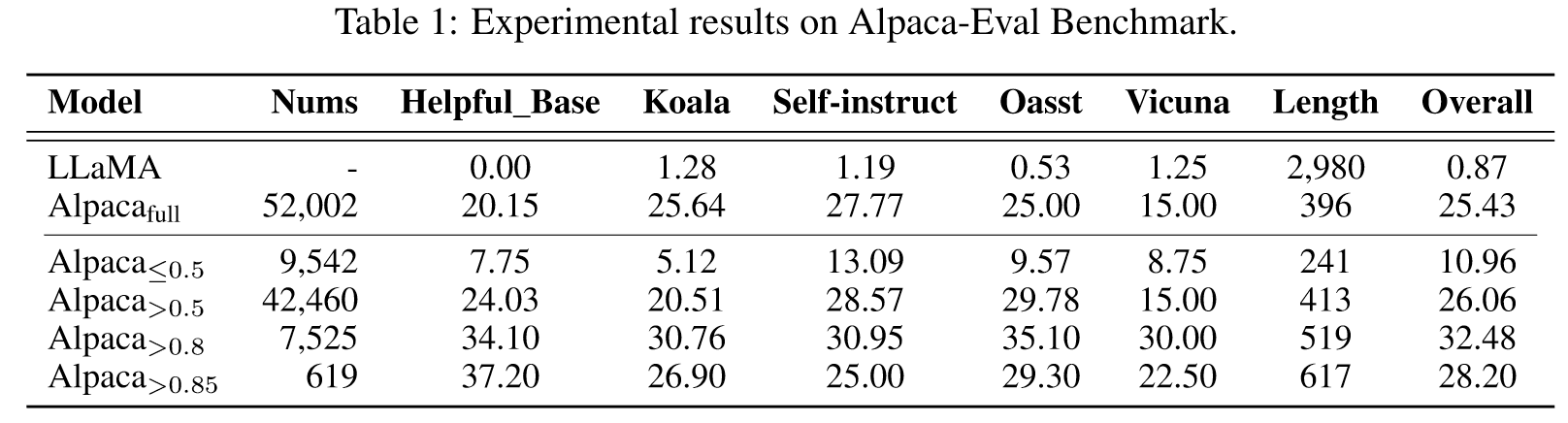
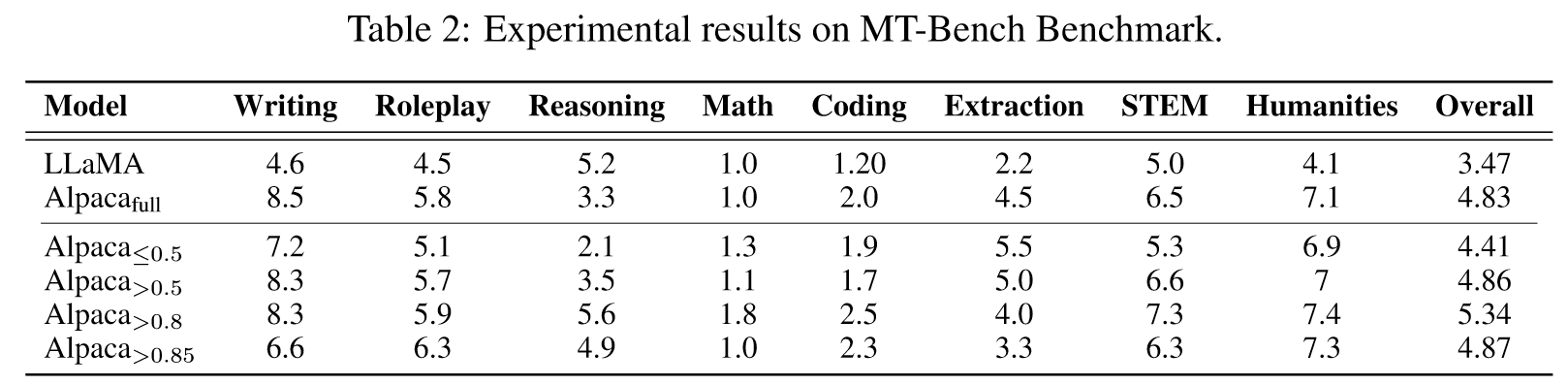
我们还注意到,合并较低质量的指令会对模型微调产生不利影响。当我们看到 Alpaca≤0.5 的性能落后于 Alpacafull,而 Alpaca>0.5 的性能略优于 Alpacafull 时,这一趋势就很明显了。值得注意的是,Alpaca>0.85,仅使用 1% 的数据集进行微调,就取得了与 Alpacafull 相当甚至超越的结果。这强调了我们的数据选择方法的有效性。
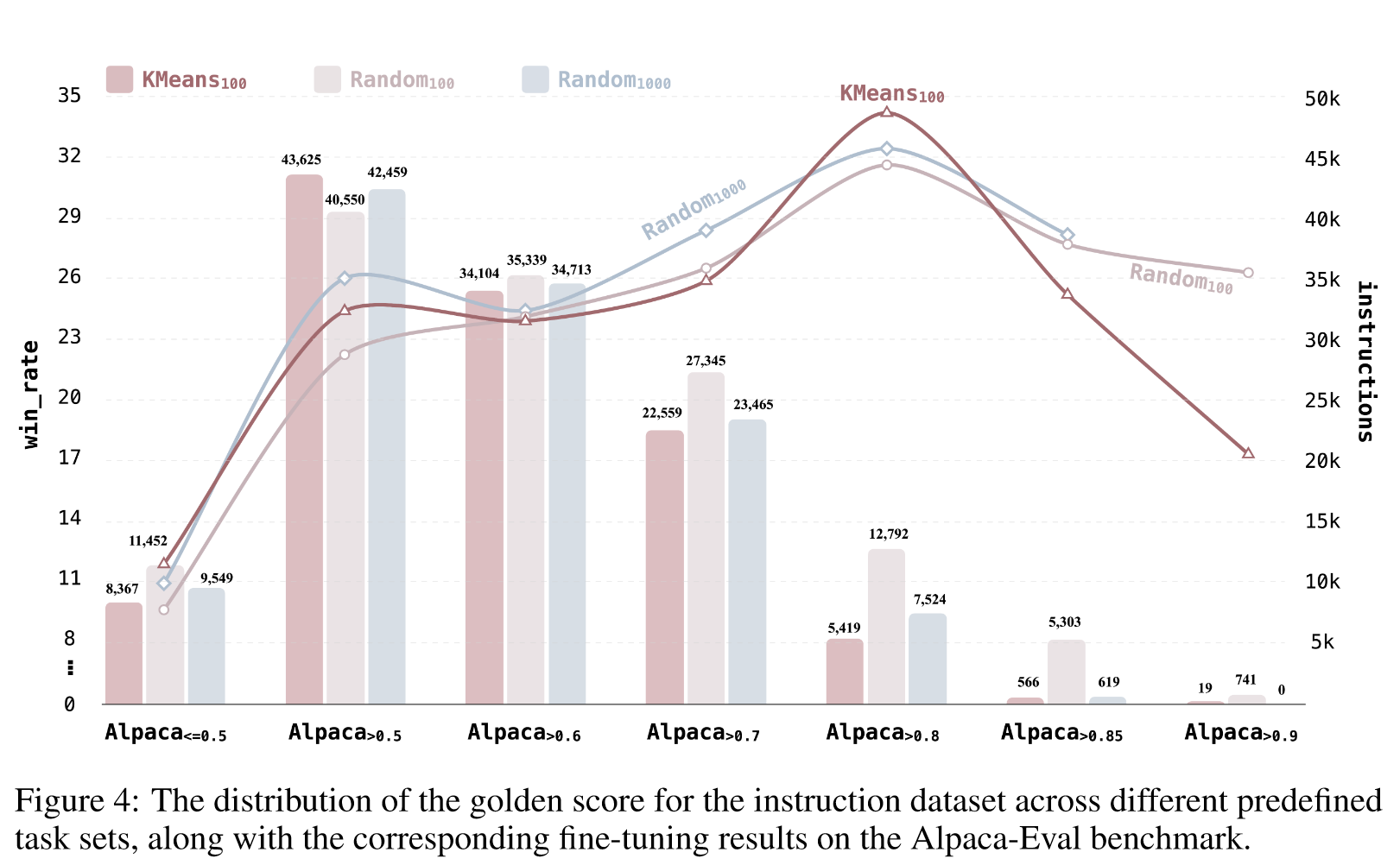
Ablation on Predefined Task Sets
为了评估不同的预定义任务集如何影响微调指令数据的选择,我们添加了两个额外的预定义任务集变体。一个是从 Alpaca 数据集中随机抽取的示例,但任务集大小较小,仅限 100 个示例。另一种方法需要使用 KMeans 算法将 Alpaca 数据集聚类为 100 个簇,并选择每个簇的质心作为任务集的示例。
表3中的结果表明,通过随机采样,增加任务集的大小可以增强高质量指令数据的识别。
然而,当使用 KMeans 为任务集挑选更多不同的示例时,就会发生转变。 KMeans 仅用了 100 个示例,就超越了通过随机采样获得的 1,000 个示例的结果。在本例中,Alpaca>0.8 仅用 5,419 个示例就提供了卓越的性能,而 Random1000 则提供了 7,524 个示例。这一结果也间接证实了我们关于黄金指令定义的假设的有效性。

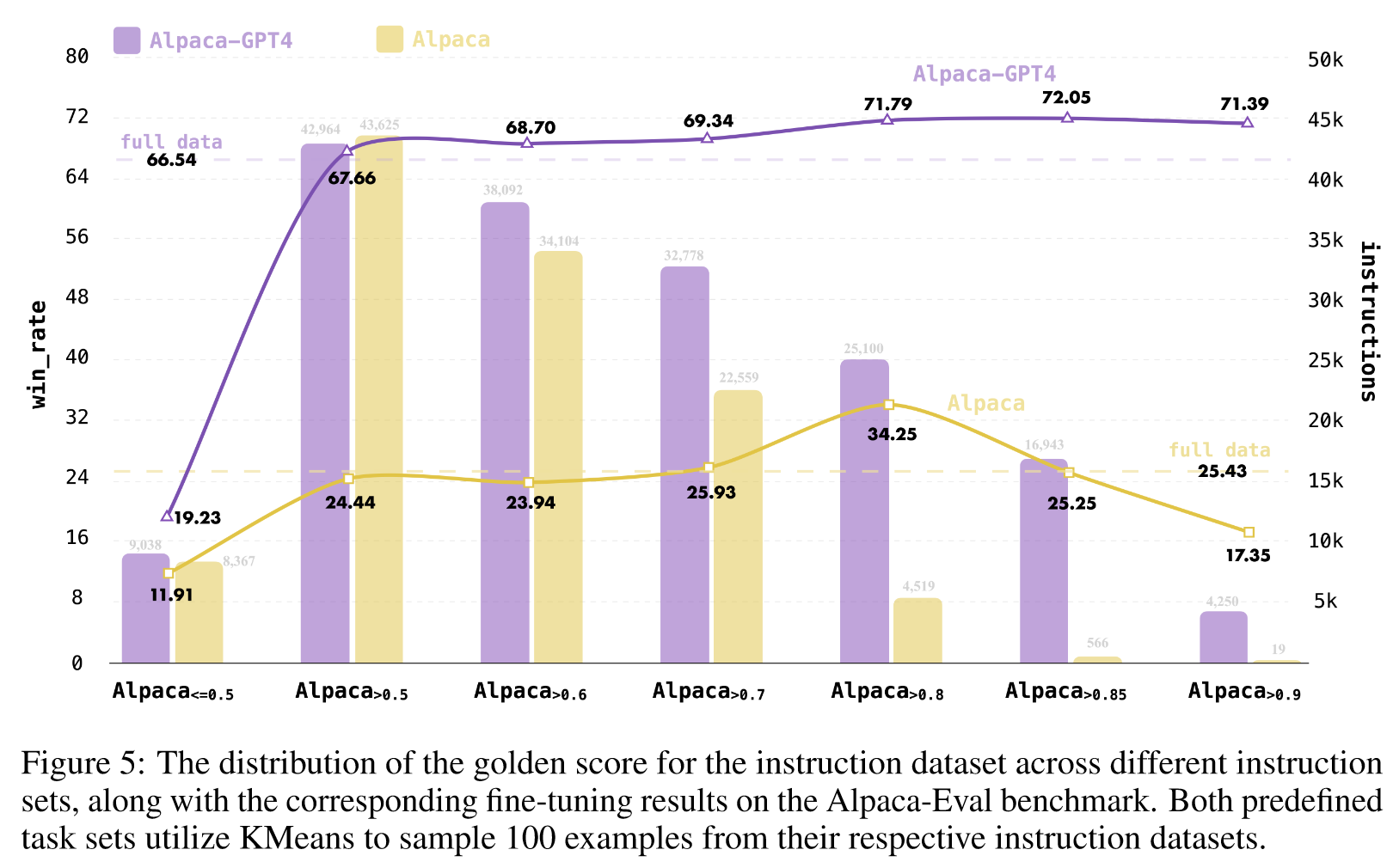
Ablation on Instruction Set
为了更深入地研究 Nuggets 在不同指令数据集上的泛化能力,我们利用 Alpaca-GPT4 数据集进行了一系列实验。
Case Study

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 创新方法:论文引入了"Nuggets"方法,它利用大型语言模型(LLM)进行一次性学习,从而从庞大的指令数据集中选择高质量的指令数据。这种方法优于传统的依赖整个数据集的指令调整方法,因为它能有效识别出对模型表现提升最大的数据子集。
- 高效的数据选择:Nuggets方法能识别出对多种任务表现有显著影响的指令示例,实现高效数据筛选。它通过比较每个指令示例对预定义任务集(锚定集)的困惑度影响来打分,从而挑选出最有价值的数据进行指令调整。
- 实验验证:通过在两个基准测试(MT-Bench和Alpaca-Eval)上的实验验证,论文展示了使用Nuggets筛选出的顶尖1%的示例进行指令调整,比使用整个数据集的传统方法表现更好。
-
论文中存在的问题及改进建议:
- 一致性和泛化性的挑战:Nuggets方法依赖于特定的预定义任务集来评估指令的有效性。这可能会导致对这些任务有偏好的指令选择,而对其他可能同样重要的任务类型则可能忽视。
- 改进建议:拓展和多样化预定义任务集,以包含更广泛的任务类型和场景。这样可以更全面地评估指令数据的质量和适用性。
- 算法复杂度和计算资源:Nuggets方法在处理大型数据集时可能需要显著的计算资源和时间。
- 改进建议:研究并实现更高效的数据处理和评分机制,减少计算负担和时间开销。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 多模态数据集的Nuggets应用:将Nuggets方法扩展到多模态数据集,评估其在处理非文本数据(如图像、视频)时的效果。
- 跨语言应用:探索Nuggets方法在多语言环境中的应用,研究其在不同语言和文化背景下的适用性和效果。
- 自适应数据集生成:基于Nuggets的反馈,开发自适应机制自动生成或优化指令数据集,以提升模型在特定任务或领域的性能。
-
为新的研究路径制定的研究方案:
- 多模态数据集的Nuggets应用:
- 研究方法:扩展Nuggets算法以支持多模态输入,例如结合图像描述和文本指令。
- 步骤:选择或创建包含多模态数据的指令数据集,实施Nuggets算法,分析并比较多模态数据和纯文本数据的效果差异。
- 预期成果:验证Nuggets方法在多模态环境下的适用性和有效性。
- 跨语言应用:
- 研究方法:对Nuggets算法进行适配,以支持多种语言。
- 步骤:在不同语言的数据集上应用Nuggets,评估其对不同语言环境的适应性。
- 预期成果:在多语言环境中有效地筛选高质量指令数据。
- 自适应数据集生成:
- 研究方法:开发一种基于Nuggets反馈的数据集自动生成或优化机制。
- 步骤:根据Nuggets的评分和反馈,自动生成或调整指令数据集,以专注于提高特定任务的表现。
- 预期成果:能够根据模型的特定需要动态生成或调整指令数据集,优化模型性能。
- 多模态数据集的Nuggets应用:
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!