目录
Resource Info Paper https://arxiv.org/abs/2305.11206 Code & Data https://huggingface.co/datasets/GAIR/lima Public Neurips Date 2024.04.01
Summary Overview
大语言模型的训练分为两个阶段:
- 从原始文本进行无监督预训练,以学习通用表示;
- 大规模指令调整和强化学习,以更好地适应最终任务和用户偏好
我们通过训练 LIMA 来衡量这两个阶段的相对重要性,LIMA 是一个 65B 参数 LLaMa 语言模型,仅在 1,000 个精心策划的提示和响应上使用标准监督损失进行微调,没有任何强化学习或人类偏好建模。LIMA 表现出了非常强大的性能,仅从训练数据中的少数示例中学习遵循特定的响应格式,包括从规划旅行行程到推测替代历史的复杂查询。
总而言之,这些结果强烈表明,大型语言模型中的几乎所有知识都是在预训练期间学习的,并且只需要有限的指令调整数据来教导模型产生高质量的输出。
Main Content
然而,我们证明,只要有强大的预训练语言模型,只需对 1,000 个精心策划的训练示例进行微调即可实现非常强大的性能。
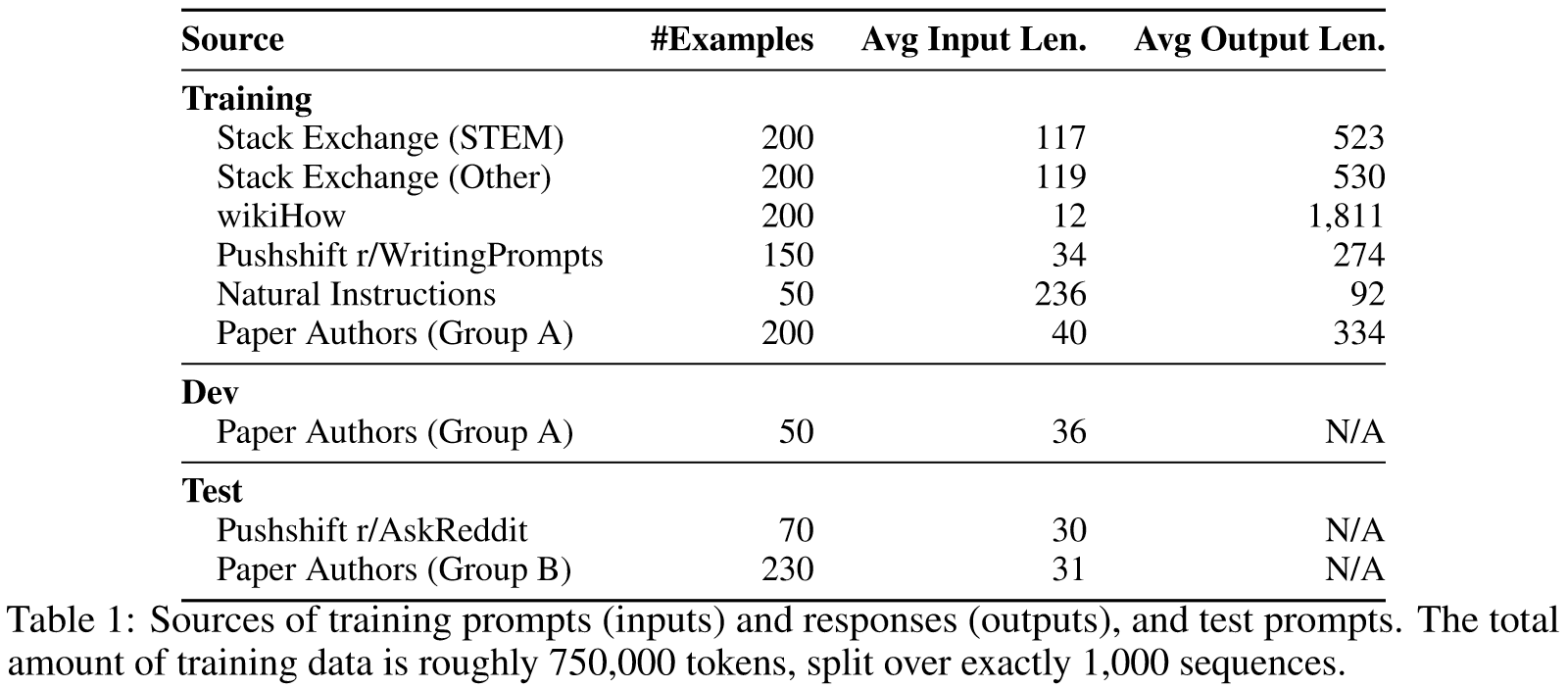
我们训练 LIMA,这是一个预训练的 65B 参数 LLaMa 模型,在这组 1,000 个演示中进行了微调。
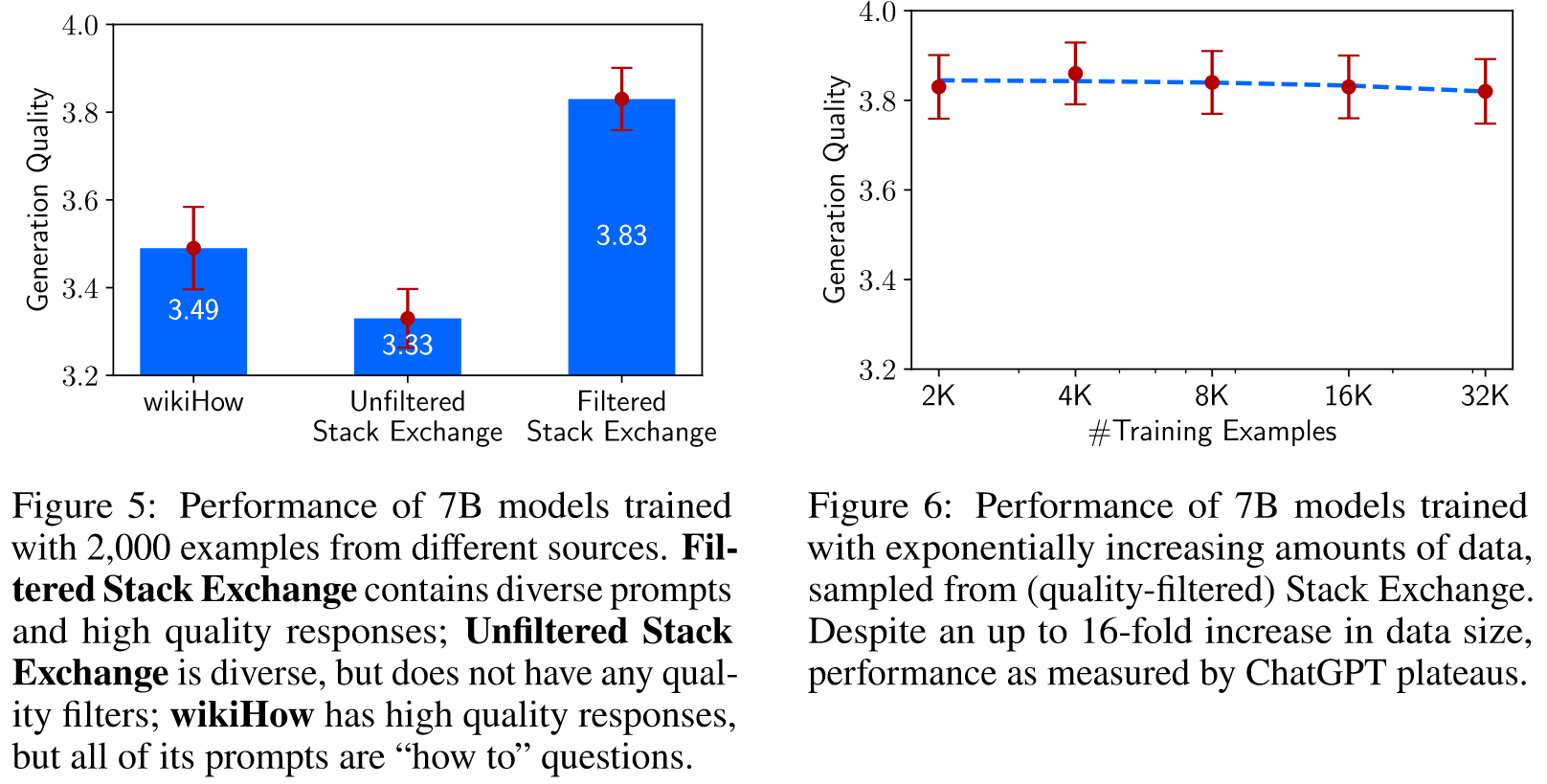
消融实验表明,当扩大数据数量而不扩大即时多样性时,回报会大幅递减,而优化数据质量时会带来巨大收益。
Superficial Alignment: 模型的知识和能力几乎完全是在预训练期间学习的,而对齐则教导模型在与用户交互时应使用哪种格式的子分布。
如果这个假设是正确的,并且对齐很大程度上与学习风格有关,那么表面对齐假设的推论是,人们可以用一小部分示例充分调整预训练的语言模型。
Experiments
Baselines
- Alpaca 65B
- OpenAI's DaVinci003
- Bard
- Claude
- GPT-4
Results
在每个步骤中,我们都会向注释者提供由不同模型生成的单个提示和两个可能的响应。注释者被要求标记哪个响应更好,或者两个响应是否明显优于另一个。
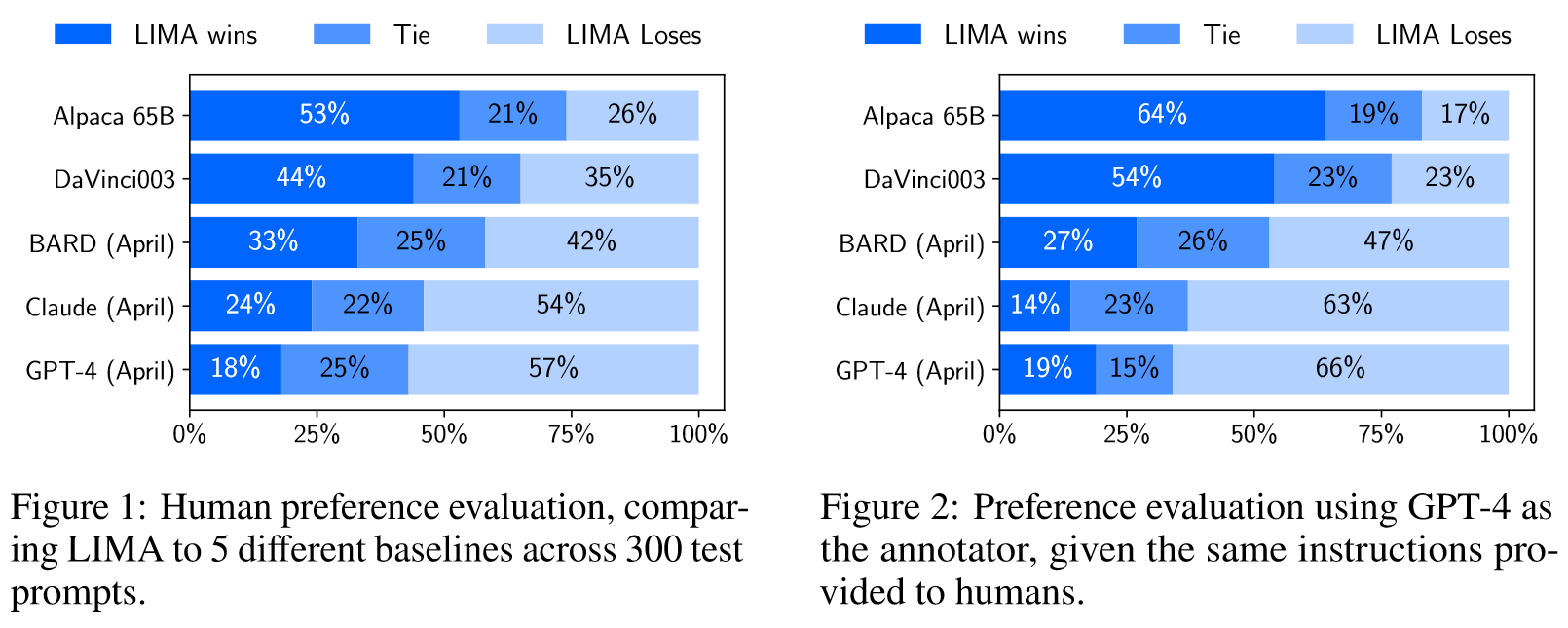
我们将每个示例标记为以下三类之一: 失败,响应不符合提示的要求;通过,响应符合提示要求;非常好,该模型对提示提供了出色的响应。
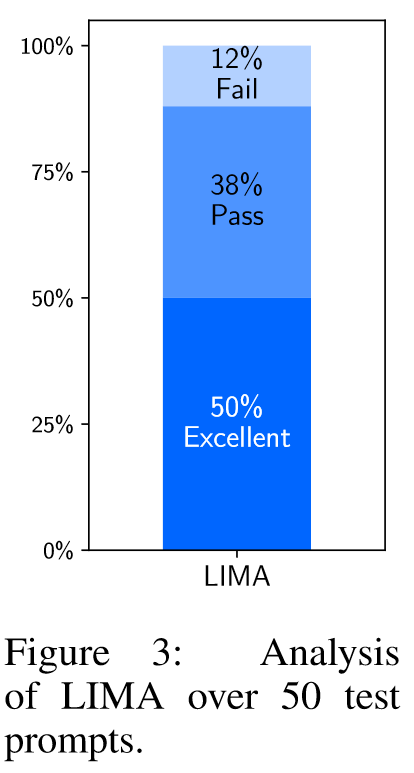
Why is Less More? Ablations on Data Diversity, Quality, and Quantity
然后,我们对每个测试集提示抽取 5 个响应,并通过要求 ChatGPT (GPT-3.5 Turbo) 对响应的有用性按照 1-6 的李克特量表进行评分来评估响应质量(具体模板请参阅附录 D)。
Case Study
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: 本文展示了一种新型的自然语言处理模型——LIMA,其独特性在于只通过1000个精心策划的提示和回应进行微调,而无需任何增强学习或人类偏好建模。这种方法挑战了传统的大规模指令调整和增强学习的必要性,强调了预训练在语言模型发展中的关键作用。论文的关键发现在于展示了预训练过程中获取的知识量远超过特定指令调整或增强学习的过程。这一发现对于理解和提升大型语言模型的学习和适应能力具有重要意义。
-
论文中存在的问题及改进建议: 尽管LIMA在实验中展示出了强大的性能,但其依然存在一些限制。例如,该模型在处理对话或复杂任务时可能不如专门通过人类反馈或大量数据训练的模型那样健壮。另一个问题是,精心策划的1000个训练示例可能无法全面覆盖所有可能的用户提示和场景,这限制了模型的通用性和灵活性。为改善这些问题,建议对模型进行更全面的测试,包括不同领域和任务类型的提示,以评估其泛化能力。此外,可以探索结合少量精心策划的例子与更大规模的自然数据集,以提升模型的适应性和鲁棒性。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 多模态融合:考虑将LIMA与视觉或声音数据相结合,创建一个多模态的交互模型。这可以拓展模型的应用场景,如图像描述、音视频内容分析等。
- 跨语言和文化适应:开展跨语言和文化背景的适应性研究,探索模型在处理不同语言和文化背景下的数据时的性能,以及如何提升其跨文化理解和生成能力。
- 专业领域的知识融入与生成:针对特定的专业领域(如医学、法律、金融)进行定制化模型训练,使模型能够生成更具专业深度和精准度的内容。
-
为新的研究路径制定的研究方案:
- 多模态融合研究方案:首先,搜集和标注跨媒体数据集,包括文本、图片和音频数据。然后,设计和实现一种新的多模态神经网络架构,使其能够同时处理和整合不同类型的数据输入。最后,通过实验评估模型在多模态任务(如图像描述生成、音视频内容分析)上的表现。
- 跨语言和文化适应研究方案:首先,构建一个多语言和多文化的数据集,确保覆盖广泛的语言和文化背景。接着,利用迁移学习和多任务学习方法来训练和微调LIMA模型。最后,通过一系列跨文化和跨语言的NLP任务来评估模型的性能。
- 专业领域知识融入与生成研究方案:首先,收集特定领域的大规模专业文本数据。然后,对LIMA模型进行定制化微调,使其学习和理解特定领域的知识。最后,通过专业知识生成任务(如案例分析、研究报告生成)来评估模型的专业知识生成能力。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!