目录
Resource Info Paper https://arxiv.org/abs/2307.06290 Code & Data / Public ArXiv Date 2024.04.10
Summary Overview
大语言模型(LLM)在最初针对广泛的功能进行预训练,然后使用指令跟踪数据集(instruction-following datasets)进行微调,以提高其与人类交互的性能。尽管微调方面取得了进步,但选择高质量数据集来优化此过程的标准化方法依然难以捉摸。在本文中,作者提出了INSTRUCTMINING,旨在自动选择优质指令跟踪数据来微调LLM。具体来说,INSTRUCTMINING利用自然语言指标作为数据质量的衡量标准,将其应用于评估未见过的数据集。在实验过程中,我们发现大型语言模型微调中存在双下降现象。基于这一观察,作者进一步利用BLENDSEARCH来帮助找到整个数据集中的最佳子集。
Main Content
最近的一项研究 LIMA 表明,即使是少量精心挑选的高质量指令数据也可以通过指令调优显着提高模型性能(Zhou et al., 2023)。为了解决这个问题,我们在评估集上使用微调模型产生的损失作为数据质量的代理。
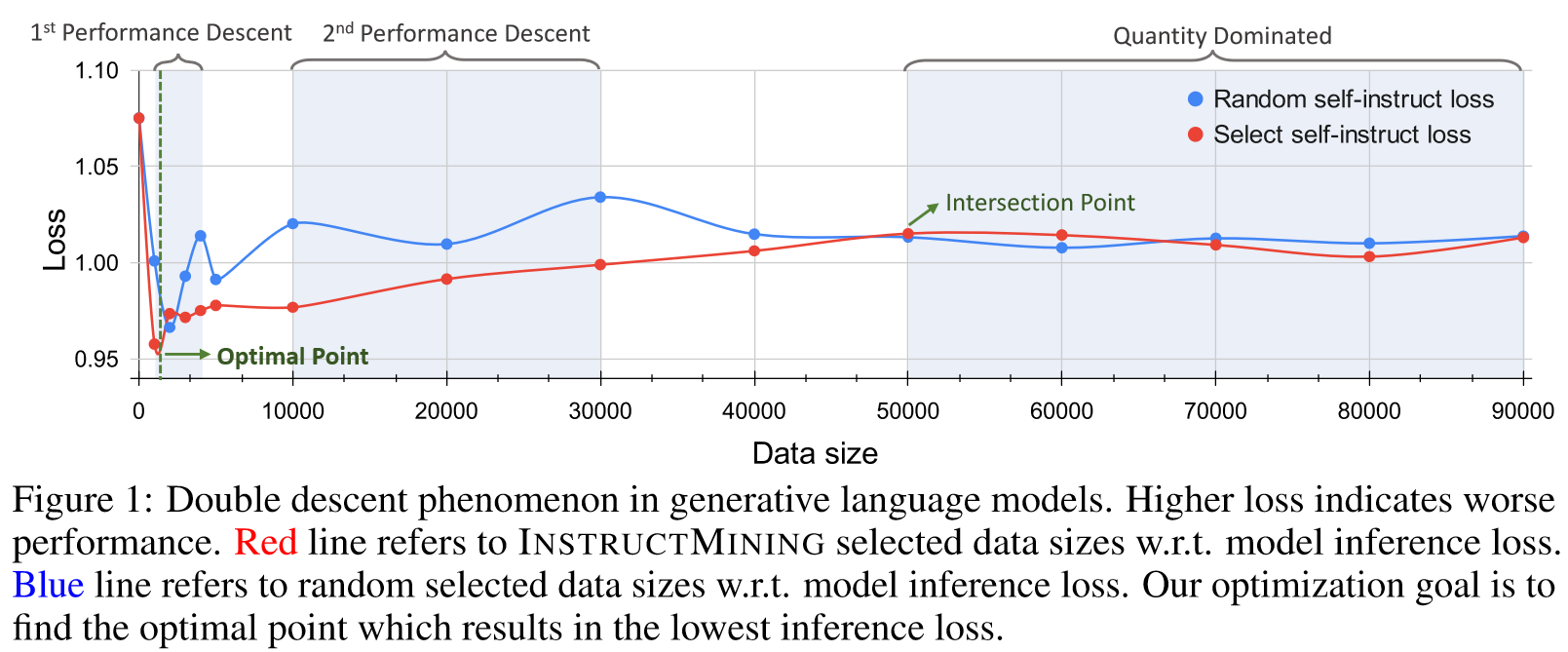
选择数据的简单解决方法是选择前个多质量的数据样本,但实践证明选择合适的本身就很困难。
双下降现象(double descent phenomenon)表明,一旦数据大小超过特定的阈值,模型性能的主要决定因素就会从数据质量转变为数据数量。在这种情况下,关注初始的一组高质量数据点(例如,)比仔细研究整个数据集更能有效地识别最佳点。
Contributions:
- 在这项工作中,我们率先应用经典数据挖掘技术,通过自主选择高质量数据来增强LLM。为了实现这一目标,我们引入了 INSTRUCTMINING,这是一种包含数据评估和选择过程的方法。
- 所提出的 INSTRUCTMINING 创新地将定制的语言指标与先进的搜索算法相结合,能够自动评估数据质量并识别微调语言模型的最佳子集。
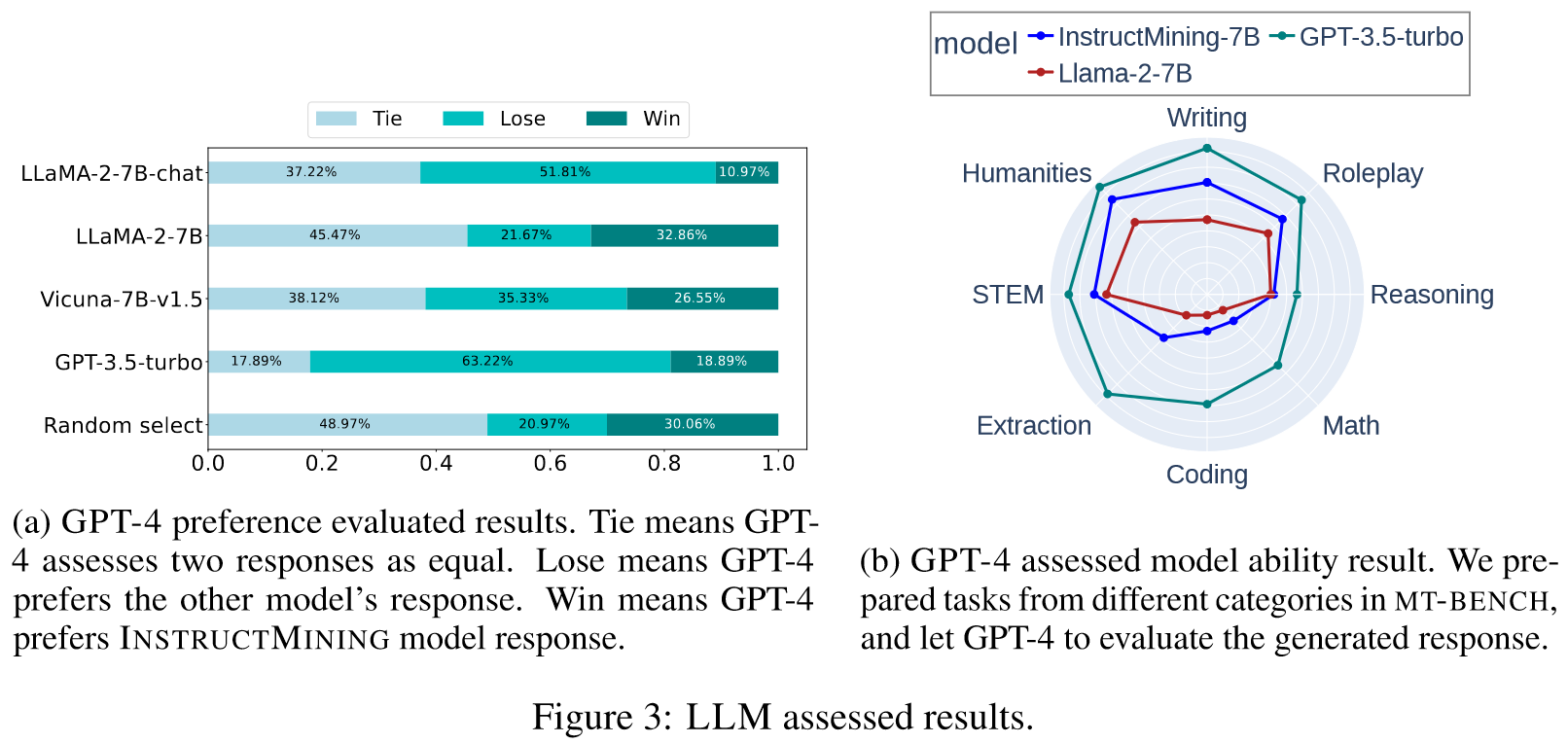
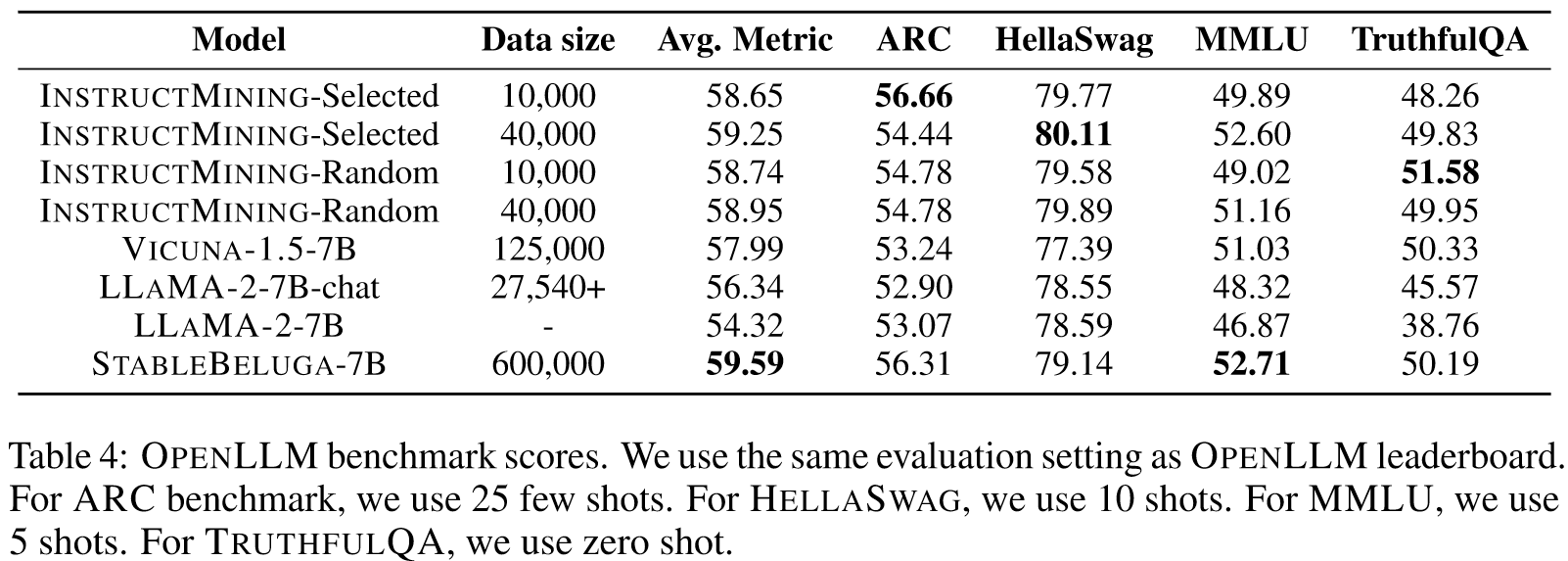
- 使用 INSTRUCTMINING 进行微调的模型在两个最流行的基准测试中展现出最先进的性能:LLM-AS-A-JUDGE 和 Huggingface OPENLLM。同时,使用较少的训练数据可以有效减少训练时间和成本。
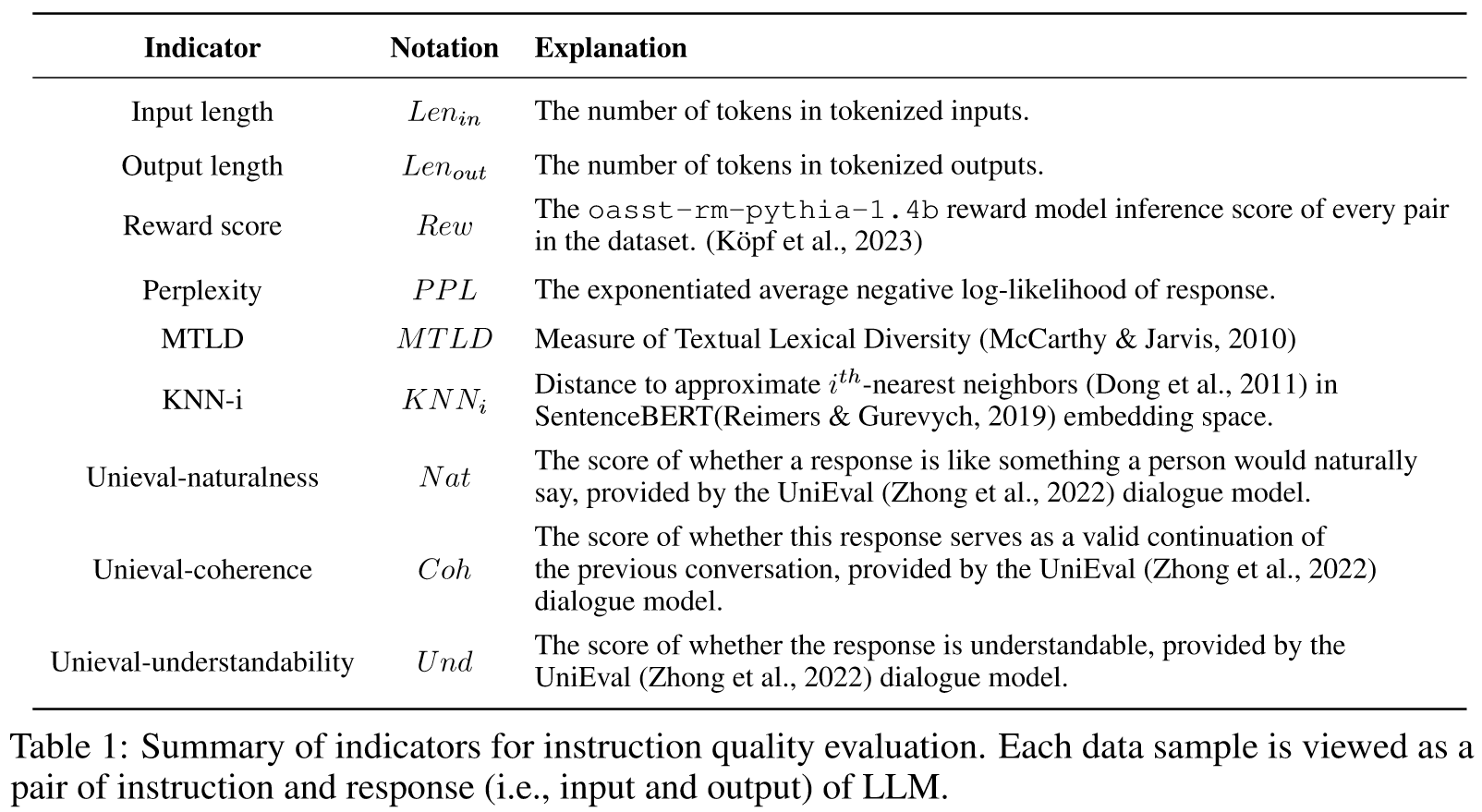
指令数据的质量可以被视为其有效引导语言模型学习以特定方式生成响应的能力。
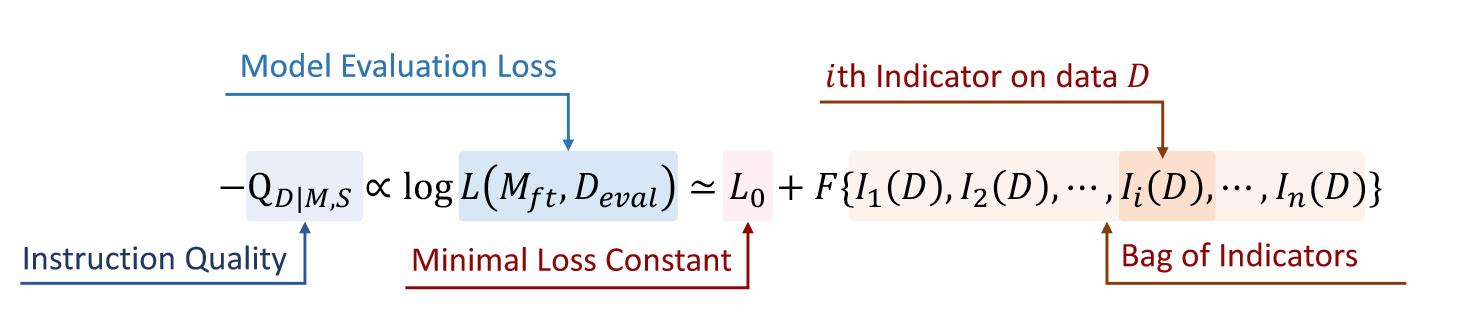
Hypothesis 1 Instruction Quality Evaluation Hypothesis: 给出指令数据集,在该数据集上微调LLM,获得。的指令质量可以通过在评估数据集上的推理损失来估计。
对于给定的指令数据集,我们计算相应的指标值。存在函数,使得可以使用来近似上述模型推理损失。
我们的实验主要集中在两个目标。第一个目标是估计建议的 INSTRUCTMINING 规则中的未知参数。第二个是评估和分析 INSTRUCTMINING 在各种微调场景下的性能。
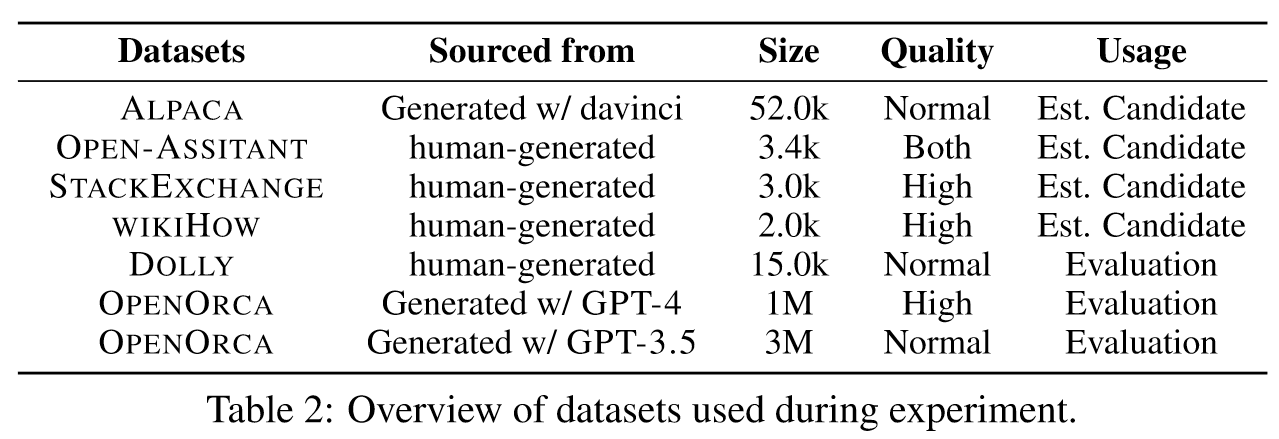
为了实现这一目标,我们首先选择几个具有不同假定质量水平的常用数据集,并将它们与随机采样的百分比融合在一起以创建微调数据集。
作者划分出了129个subset,通过最小二乘法获得了权重系数。
Quality-guided instruction selection
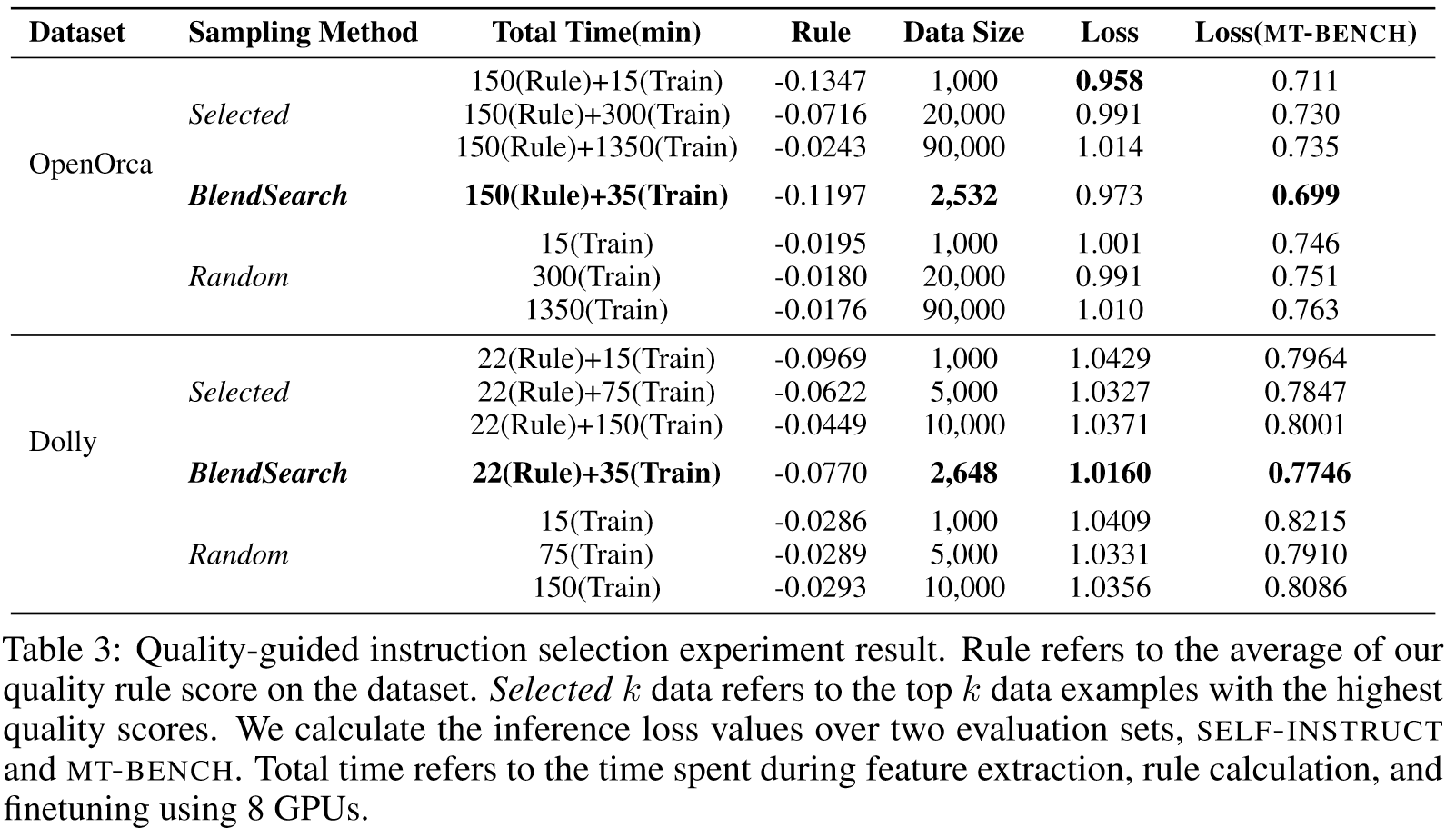
我们遵循公式 4 中估计的 INSTRUCTMINING 规则,从两个未见过的数据集中选择高质量的示例:OPENORCA 和 databricks-dolly-15k 1。
low resource: 使用 OPENORCA 数据集对 LLAMA2-7B 进行完整数据微调可能需要长达 30 小时的 8 GPU 时间。借助 INSTRUCTMINING,我们能够在大约两个小时内选择前 1,000 个数据示例,并在 15 分钟内训练出更好的LLM。
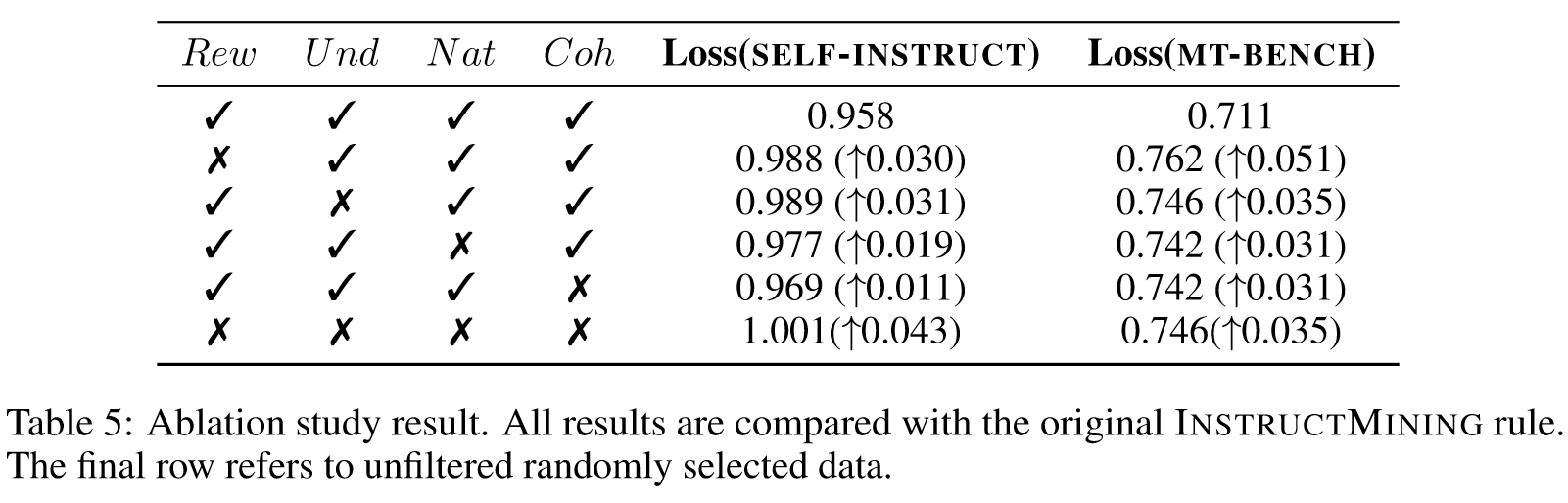
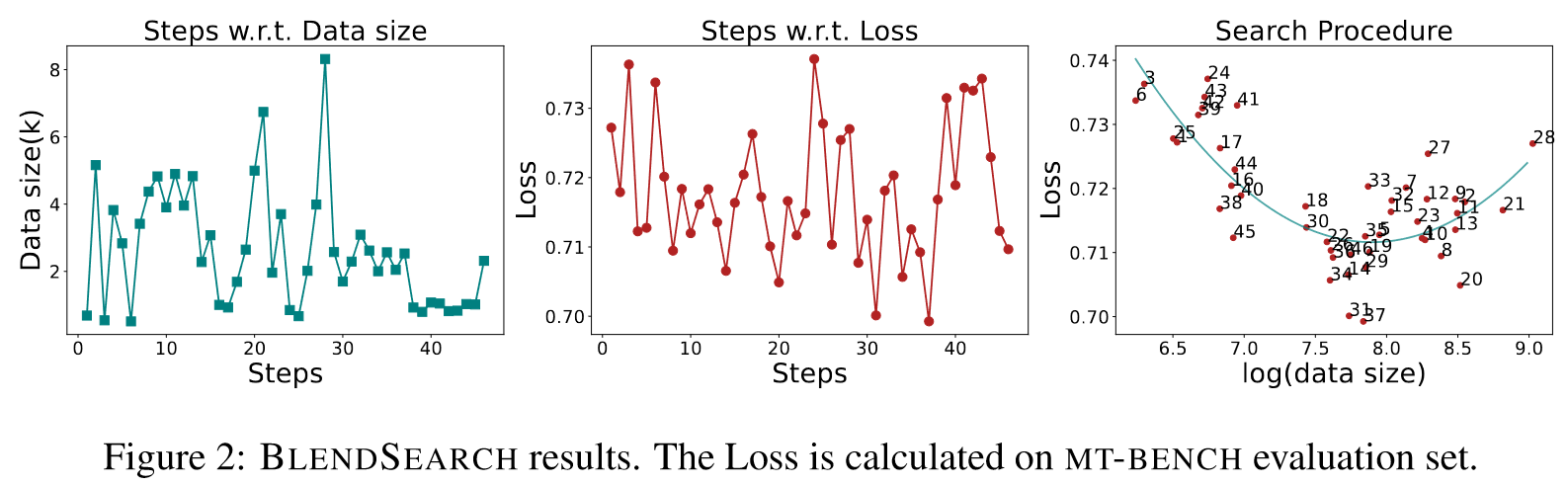
Double descent in generative language models
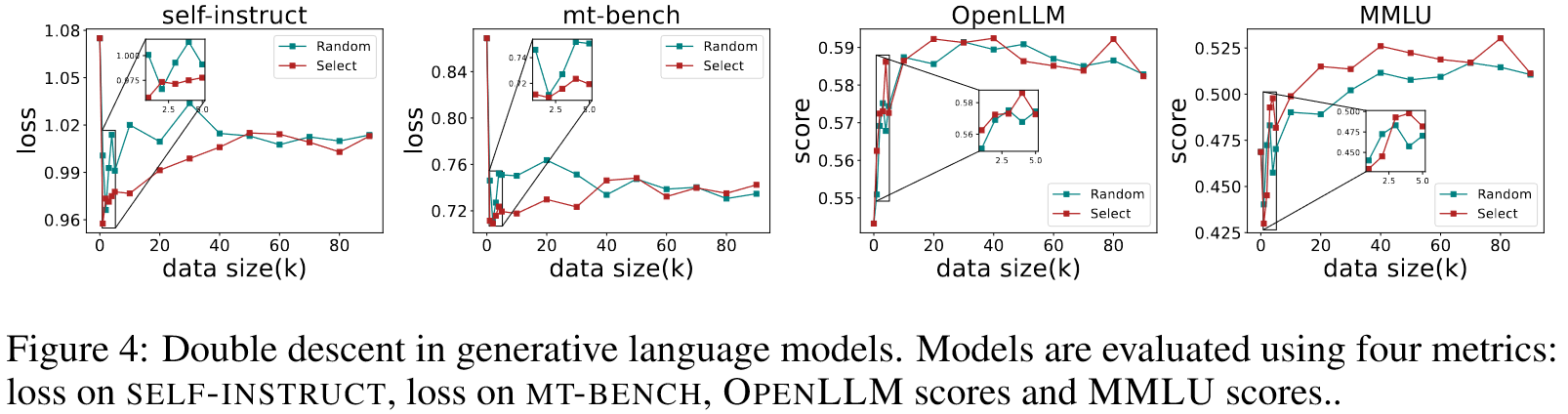
Phenomenon 1 Non-monotonicity exists in language model performance. 随着训练数据规模的增加,语言模型的性能首先变得更好,然后变得更好,然后变得更差。当数据量增加到一定程度时,性能再次变得更好。
Phenomenon 2 Balance point exists between randomly selected and quality selected data. 随着数据规模的增长,数据质量对模型性能的影响变得不再那么重要。
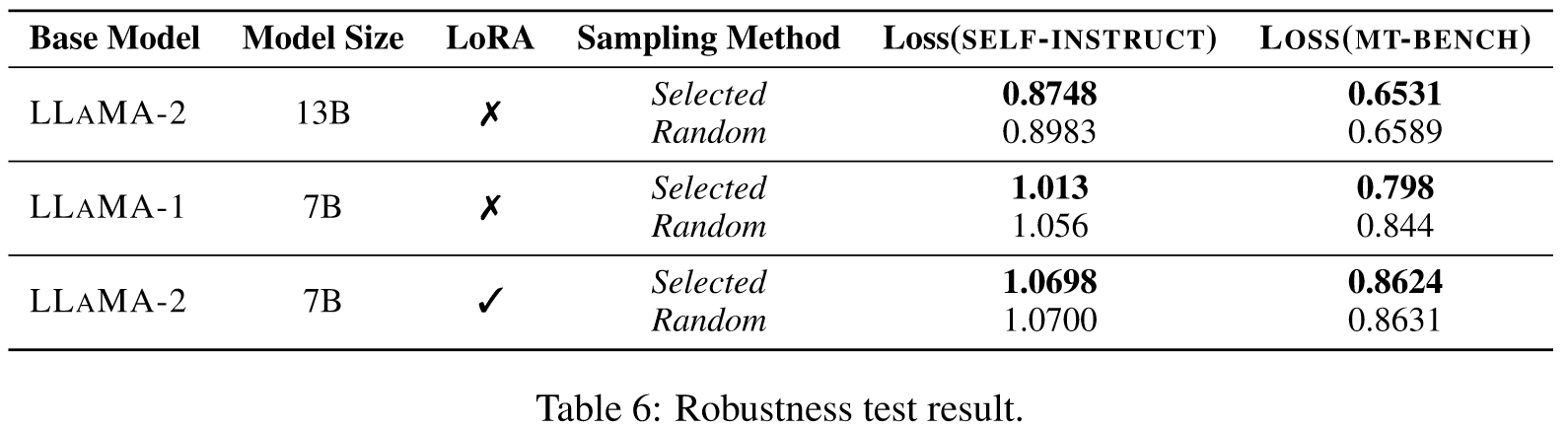
Robustness
- Different base models
- Different model sizes
- Parameter efficient settings
在本文中,我们提出了高质量的示例选择方法。已经进行了实验来估计该规则的参数,并证明我们的评估规则是有效的并且可扩展到其他微调设置。此外,我们还提出了对语言模型微调中双下降现象的观察。基于这一发现,我们进一步应用 BLENDSEARCH 来搜索最佳子集。结果表明 INSTRUCTMINING 规则是有效的且可扩展的。
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
本论文提出了一个名为“INSTRUCTMINING”的新颖方法,旨在自动挑选高质量的指令遵循数据,用于大型语言模型(LLM)的微调。这一方法的独特性在于它综合了自然语言指标和先进的搜索算法,以评估数据质量并识别用于语言模型微调的最优子集。此外,研究中发现了大型语言模型微调中的双重下降现象,并利用这一现象来辅助寻找最佳数据子集。这些创新点为LLM微调领域提供了新的研究视角和方法。
-
论文中存在的问题及改进建议:
论文中存在的主要问题是对所提出方法的鲁棒性和通用性的考量可能不足。尽管研究中展示了INSTRUCTMINING在某些基准上的优越性,但仍需深入探讨其在不同类型语言模型、不同规模数据集以及多种语言环境下的适应性和效果。改进建议包括扩大实验范围,验证方法在更广泛条件下的适用性,并深入研究方法的局限性及其应对策略。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 多模态数据微调:探索INSTRUCTMINING在多模态数据集(如结合文本、图像、音频等)上的应用,评估其在理解和生成多模态内容方面的效果。
- 跨语言适应性研究:将INSTRUCTMINING应用于不同语言的数据集,分析其在跨语言背景下的表现和调整需求。
- 长期学习能力的评估:研究INSTRUCTMINING在持续学习环境中的表现,尤其是其对新领域知识适应和历史信息保持的能力。
-
为新的研究路径制定的研究方案:
-
多模态数据微调研究方案:
- 研究方法:整合并预处理多模态数据集,利用INSTRUCTMINING进行微调,并评估其在多模态任务(如图像描述、视频理解等)上的表现。
- 预期成果:提高LLM在理解和生成多模态内容上的性能,以及在多模态任务上的准确性。
-
跨语言适应性研究方案:
- 研究方法:选择多种语言的数据集,应用INSTRUCTMINING,并比较其在不同语言背景下的效果,以及进行必要的调整以适应特定语言特性。
- 预期成果:增强LLM的跨语言适应能力,为其在多语言环境中的应用提供指导。
-
长期学习能力的评估方案:
- 研究方法:在长期学习的环境中部署INSTRUCTMINING,跟踪其性能变化,特别是在新领域知识适应和历史信息保持方面的表现。
- 预期成果:理解并改进LLM在持续学习环境中的表现,提出适应新领域和保持历史知识的策略。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!