目录
Resource Info Paper http://arxiv.org/abs/2303.11366 Code & Data https://github.com/noahshinn/reflexion Public Neurips Date 2024.04.09
Summary Overview
这是一篇Agent的工作。本文提出了Reflexion,一种不通过更新权重,而是语言反馈来增强语言代理。具体来说,Reflexion agents口头反映任务反馈信号,然后在情景记忆缓冲区中维护自己的反射文本,以便在后续试验中做出更好的决策。
Main Content
Reflexion这类似于人类如何迭代地学习以几次的方式完成复杂的任务——通过反思之前的失败,以便为下一次尝试形成改进的攻击计划。
设计了3种reflective feedback:
- simple binary enviornment feedback
- pre-defined heuristics for common failure cases
- self-evaluation (binary classification using LLMs (desicion-making) or self-written unit tests (programming))
Adavantages:
- 轻量级的,不需要对LLM进行微调
- 与难以执行准确的信用分配的标量或向量奖励相比,它允许更细致的反馈形式(例如,有针对性的行动变化)
- 它允许比以前的经历更明确和可解释的情景记忆形式
- 它为未来剧集中的行动提供了更明确的提示
Contributions:
- 我们提出了 Reflexion,这是一种“口头”强化的新范例,它将策略参数化为代理的记忆编码与 LLM 参数的选择配对。
- 我们探索了法学硕士中自我反思的这种新兴特性,并根据经验表明,自我反思对于通过少量试验学习复杂任务非常有用。
- 我们推出 LeetcodeHardGym,这是一个代码生成 RL 健身房环境,由 19 种编程语言的 40 个具有挑战性的 Leetcode 问题(“困难级别”)组成。
- 我们表明,Reflexion 在多个任务的强大基线上实现了改进,并在各种代码生成基准上实现了最先进的结果。
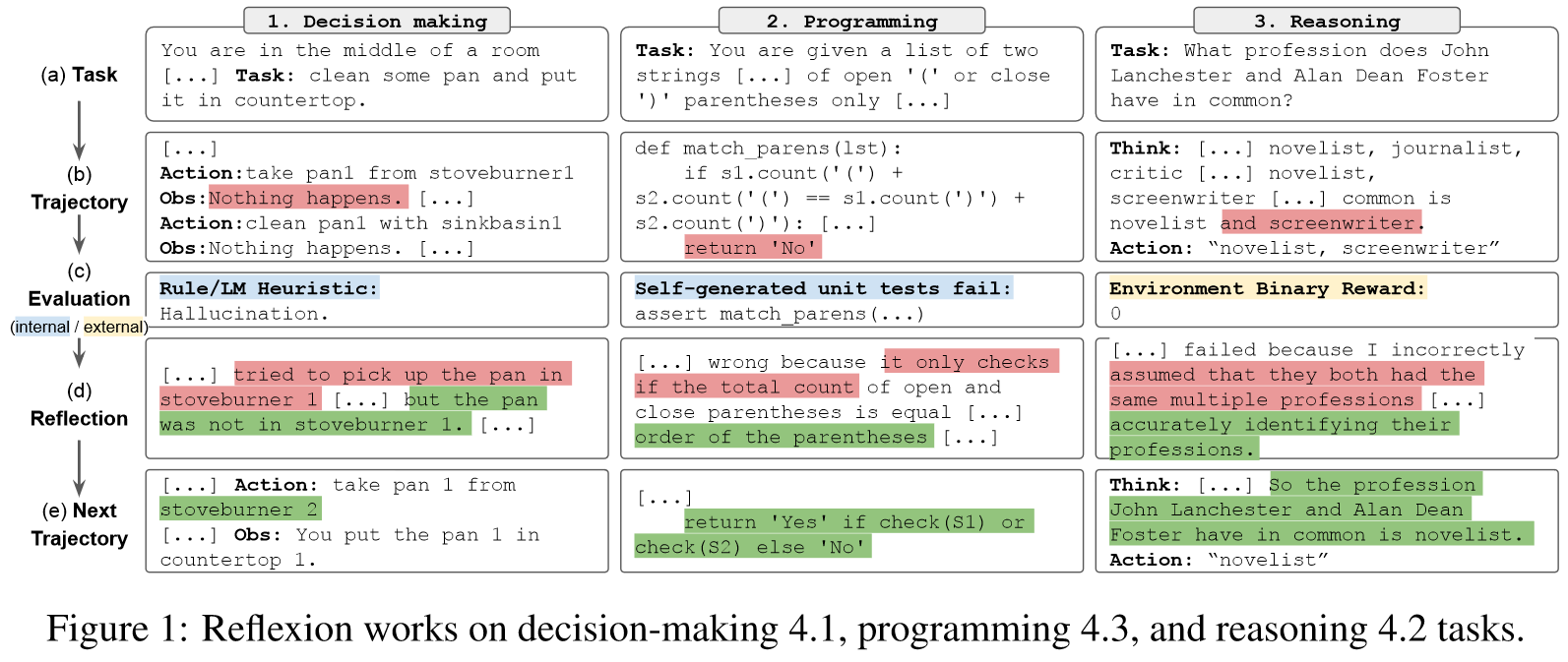
: an Actor, generates text and actions
: an Evaluator model, scores the outputs produced by
: a Self-Reflection model, generates verbal reinforcement cues to assist the Actor in self-improvement
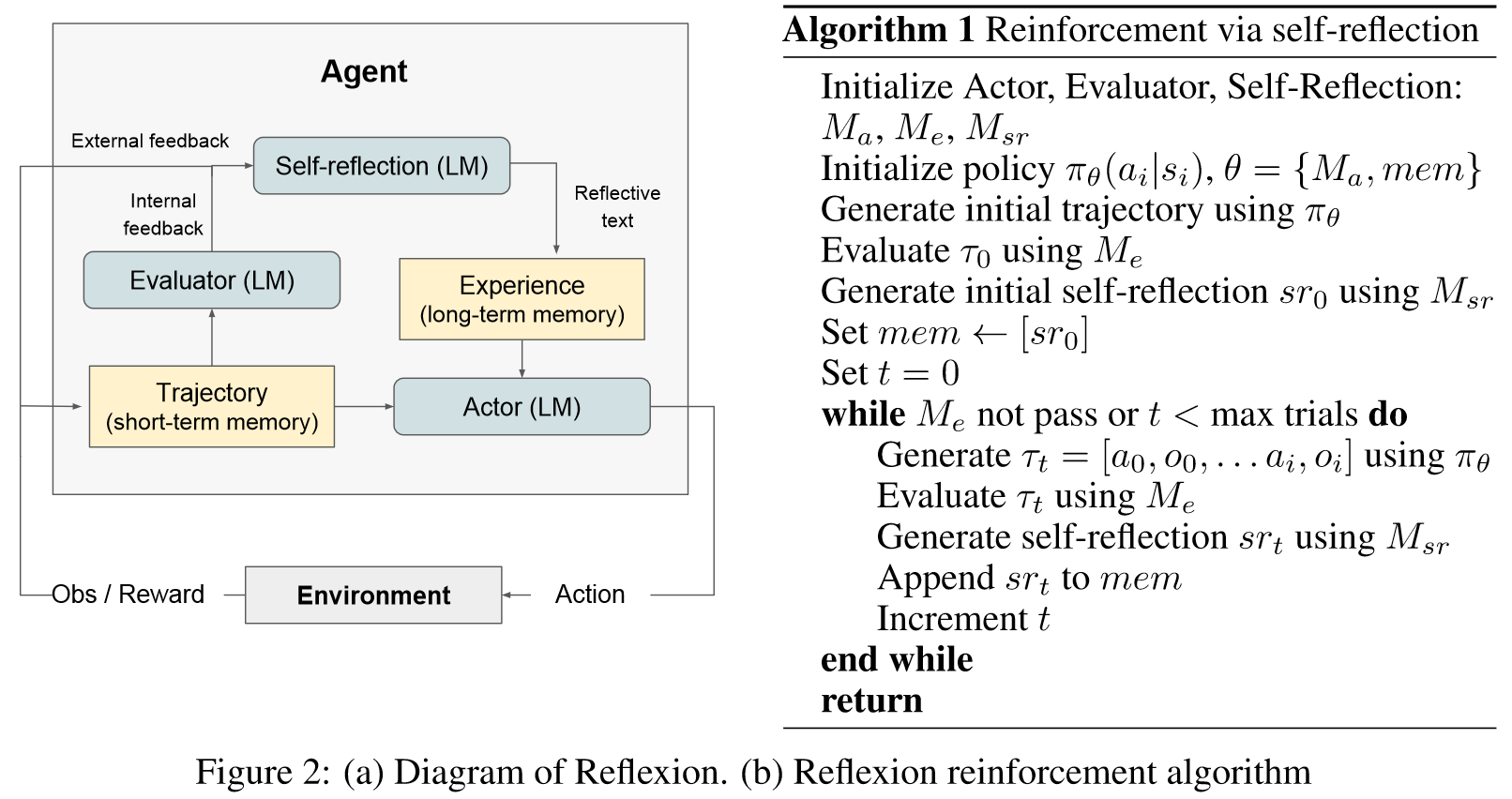
Memory: 反射过程的核心组成部分是短期记忆和长期记忆的概念。在推理时,Actor 根据短期和长期记忆做出决定,类似于人类记住最近的细粒度细节,同时也回忆从长期记忆中提炼出的重要经验。在强化学习设置中,轨迹历史充当短期记忆,而自我反思模型的输出则存储在长期记忆中。这两个记忆组件协同工作,提供特定的背景,但也受到多次试验中吸取的经验教训的影响,这是反射代理相对于其他法学硕士行动选择工作的关键优势。
The Reflexion process
在第一个试验种,Actor通过与环境交互产生轨迹。然后评估器产生一个分数,其计算公式为。只是的标量奖励,随着特定的任务性能提高而提高。在第一次实验后,为了将放大为可用于LLM改进的反馈形式,自我反思模型分析集合以生成存储在mem中的摘要。是对实验的口头经验反馈。Actor,Evaluator和Self-Reflection模型通过循环试验一起工作,知道Evaluator认为是正确的。反射的记忆成分对于其有效性十分关键。每次试验后,都会附加到mem中。在实践中,我们通过存储经验的最大数量(通常设置为1-3)来限制mem,以遵守最大上下文LLM限制。
在这项工作中,我们提出了反射,一种利用言语强化来教导智能体从过去的错误中学习的方法。我们的经验表明,通过利用自我反思,反射智能体的性能明显优于当前广泛使用的决策方法。在未来的工作中,Reflexion 可以用于采用在传统 RL 设置中经过深入研究的更先进的技术,例如自然语言中的价值学习或离策略探索技术。
Experiments
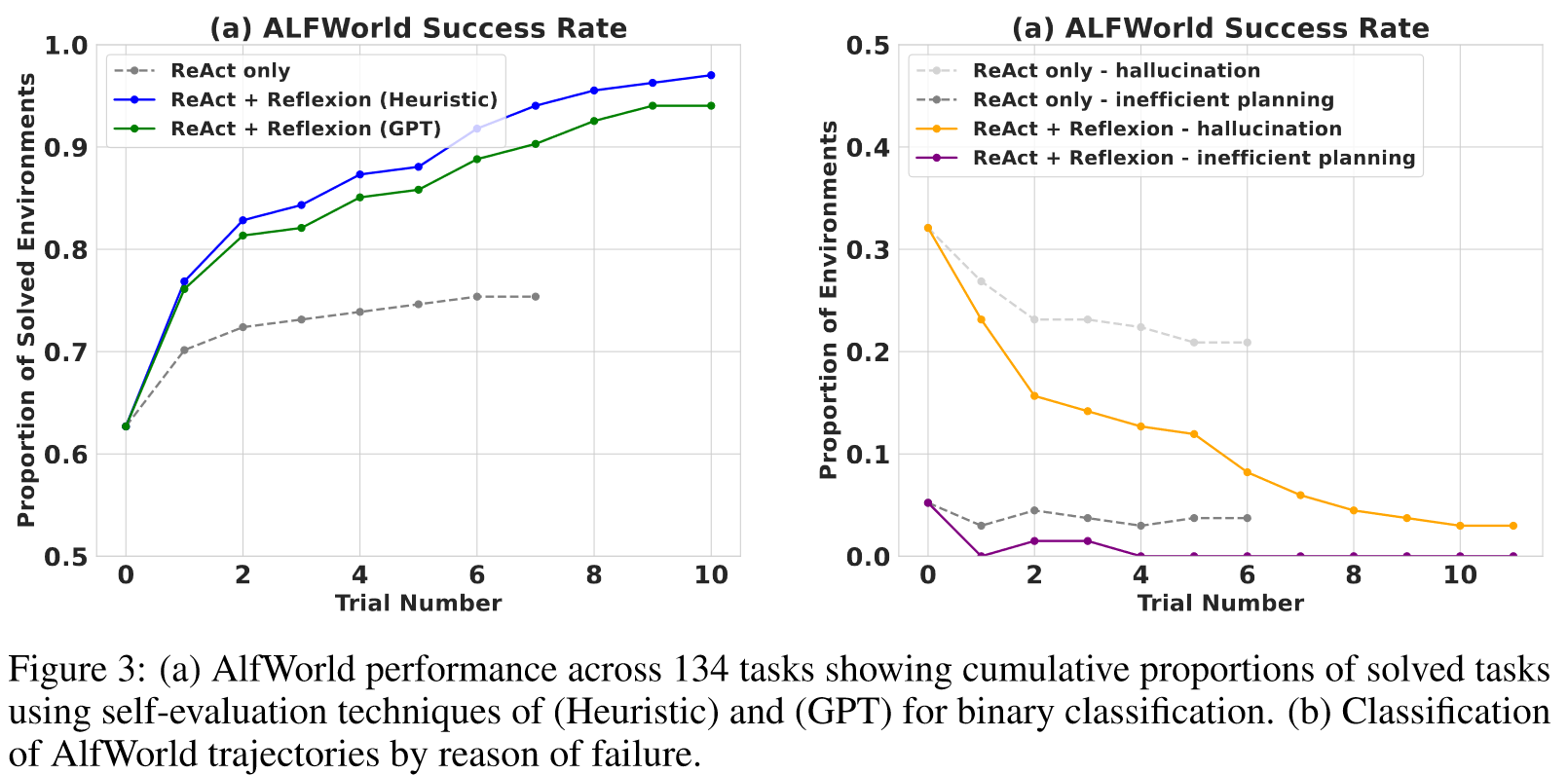
Sequential decision making: ALFWorld
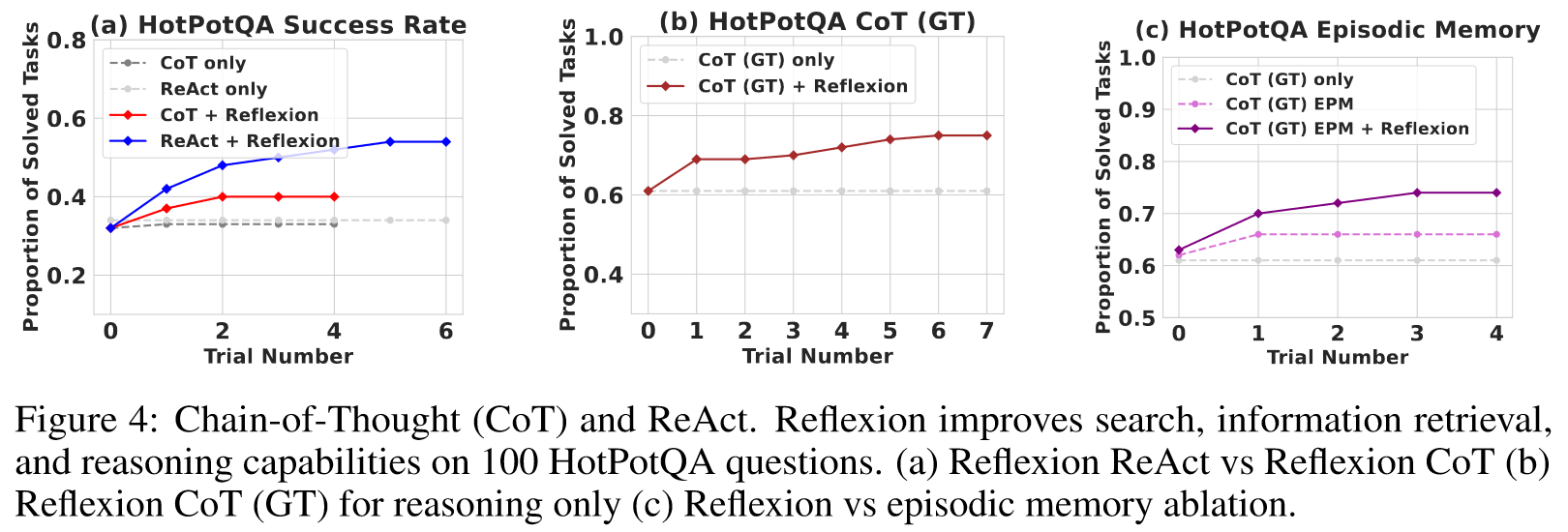
Reasoning: HotpotQA
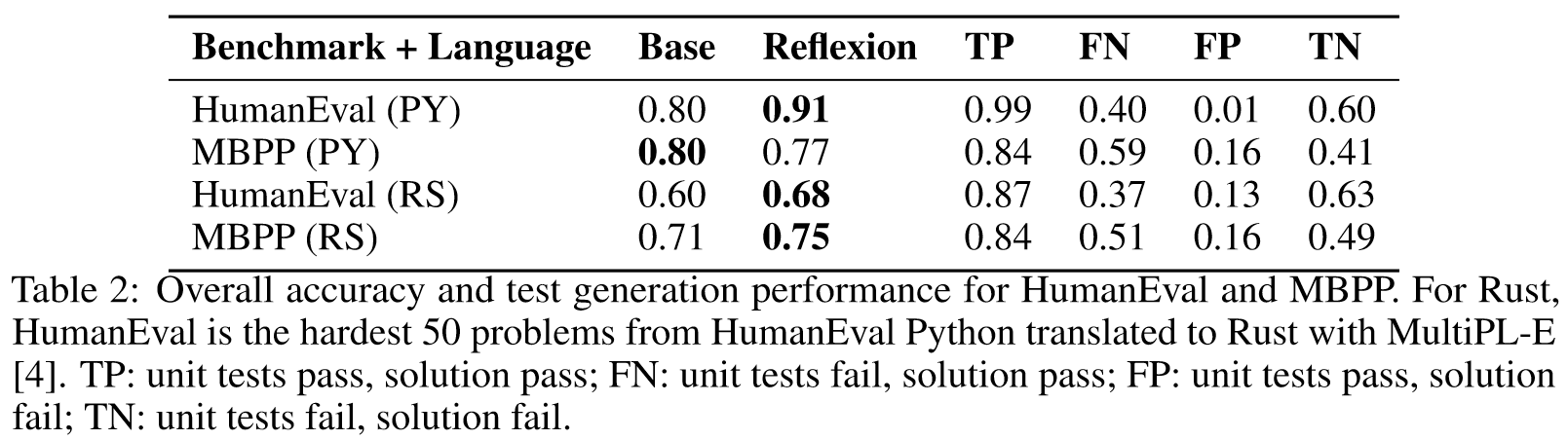
Programming: MBPP, HumanEval, LeetcodeHardGym

Ablation study

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
论文提出了一种名为“Reflexion”的新框架,该框架创新性地通过语言反馈来强化语言代理,而不是通过更新权重。这种方法将环境反馈转化为文本总结,进而作为额外上下文用于LLM代理在下一轮中的决策。Reflexion的优势在于不需要对LLM进行微调,能够处理更复杂的反馈形式,并且通过反思体验建立了一种更明确且可解释的情节记忆。特别是在多任务环境中,Reflexion在决策制定、推理和编程任务上均展现出优越的性能。
-
论文中存在的问题及改进建议:
a. 依赖LLM自我评估能力:Reflexion的效果在很大程度上取决于LLM自我评估的准确性。若LLM在特定任务上缺乏足够的先验知识或者误判情况,可能导致不准确的自我反思和学习方向。
b. 记忆窗口的限制:Reflexion使用有限大小的记忆窗口来存储反思体验,这可能限制了模型从长期经验中学习的能力。
c. 改进建议:可以考虑将Reflexion与其他类型的机器学习技术结合,如强化学习,以提高在复杂环境下的决策能力。同时,研究如何优化记忆机制,以支持更有效的长期学习。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
a. 跨模态学习:探索Reflexion在处理非文本任务(如图像和声音处理)中的应用,利用语言模型在多模态数据中提取和融合信息。
b. 多任务和多领域适应性:研究如何通过一种统一的Reflexion框架处理多种不同的任务和领域,比如结合自然语言处理和机器视觉。
c. 强化学习与Reflexion的结合:研究如何将传统强化学习算法与Reflexion框架相结合,以提高在复杂环境中的学习和适应性。
-
为新的研究路径制定的研究方案:
a. 跨模态学习方案:首先确定适用于语言模型的多模态数据集,并设计实验来评估Reflexion在处理非文本任务上的有效性。其次,开发新的算法来融合不同模态的数据,并在此基础上进行反思和学习。
b. 多任务和多领域适应性方案:开发一种能够处理多种类型任务的统一Reflexion框架,包括自然语言处理、机器视觉等。进行广泛的实验,评估模型在不同任务和领域上的表现和适应性。
c. 强化学习与Reflexion结合方案:研究如何将Reflexion与现有的强化学习算法相结合,特别是在环境建模和策略优化方面。通过实验验证组合模型在多步决策和复杂任务中的表现。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!