目录
Resource Info Paper http://arxiv.org/abs/2402.13669 Code & Data https://github.com/sail-sg/sdft Public ACL Date 2024.07.07
Summary Overview
为了解决LLM再微调后出现的灾难性遗忘和再其他任务上表现下降的问题,作者提出了 Self-Distillation Fine-Tuning (SDFT)。作者认为这是因为微调数据集与 LLM 中的参数知识分布之间存在的差距所导致的,于是使用模型本身生成的蒸馏过后的数据进行微调以匹配其原始分布来指导微调,从而弥补分布差距。

Main Content
为了解决这个问题,如图 1 所示,SDFT 首先提示种子 LM 生成与任务数据集中存在的原始响应保持语义等效的响应,从而生成精炼数据集。图 2 描绘了重写的代表性示例。重写后,自生成的响应在后续微调期间充当代理目标。通过该方法,SDFT 本质上保持了原始分布,避免了分布转移,从而保留了能力。
数据蒸馏时所使用的prompt:

实验结果如下:
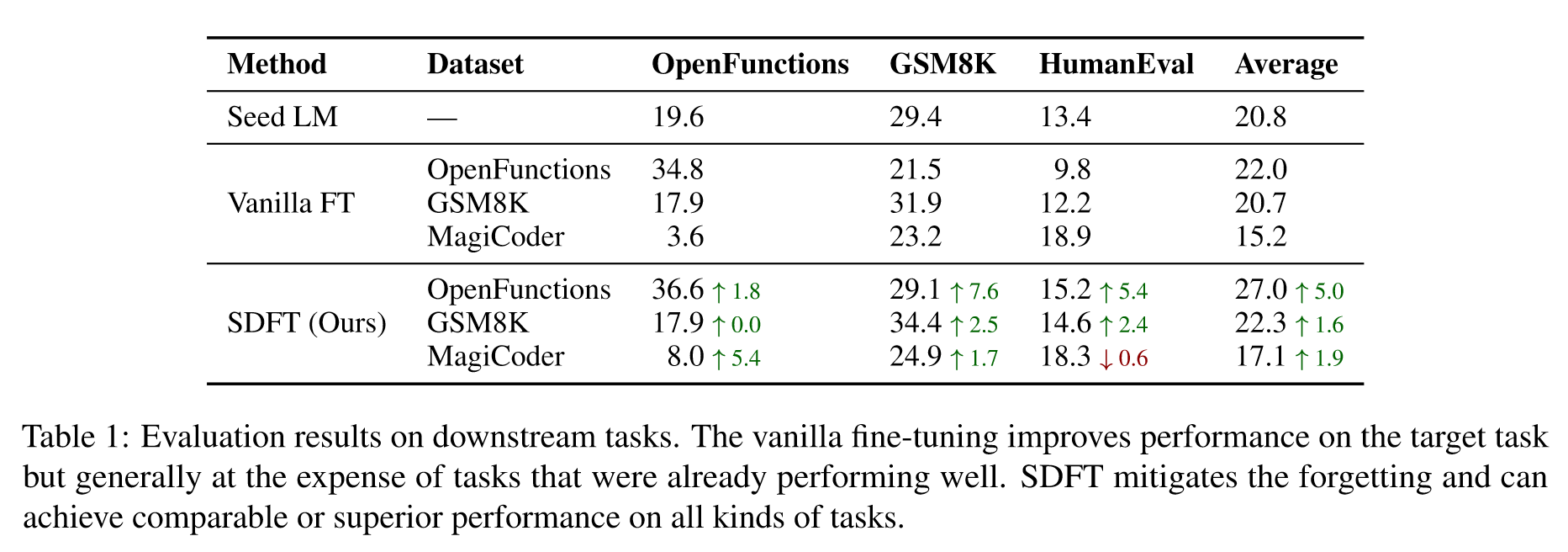
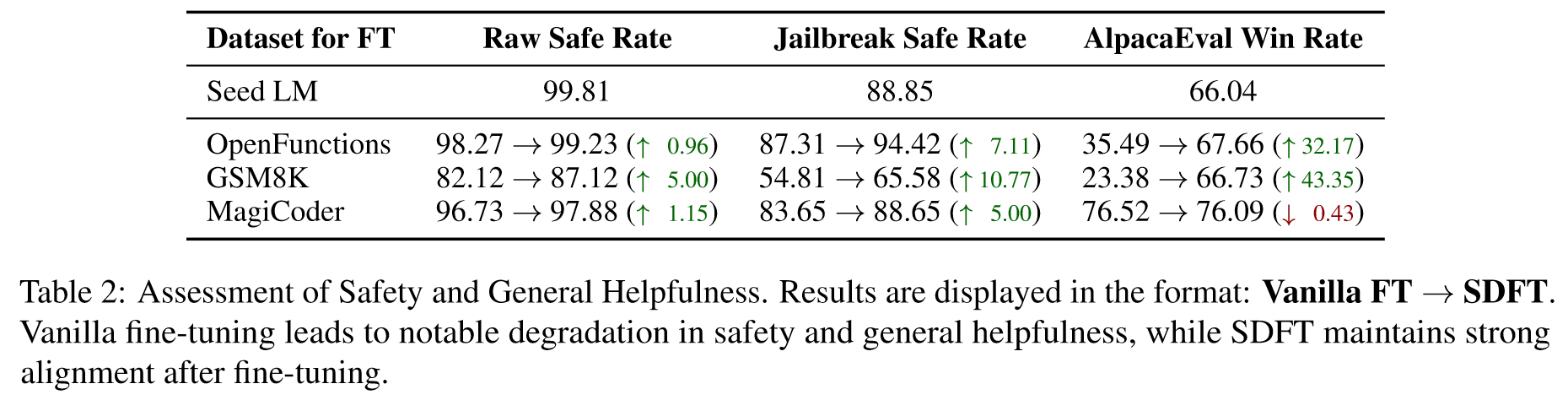
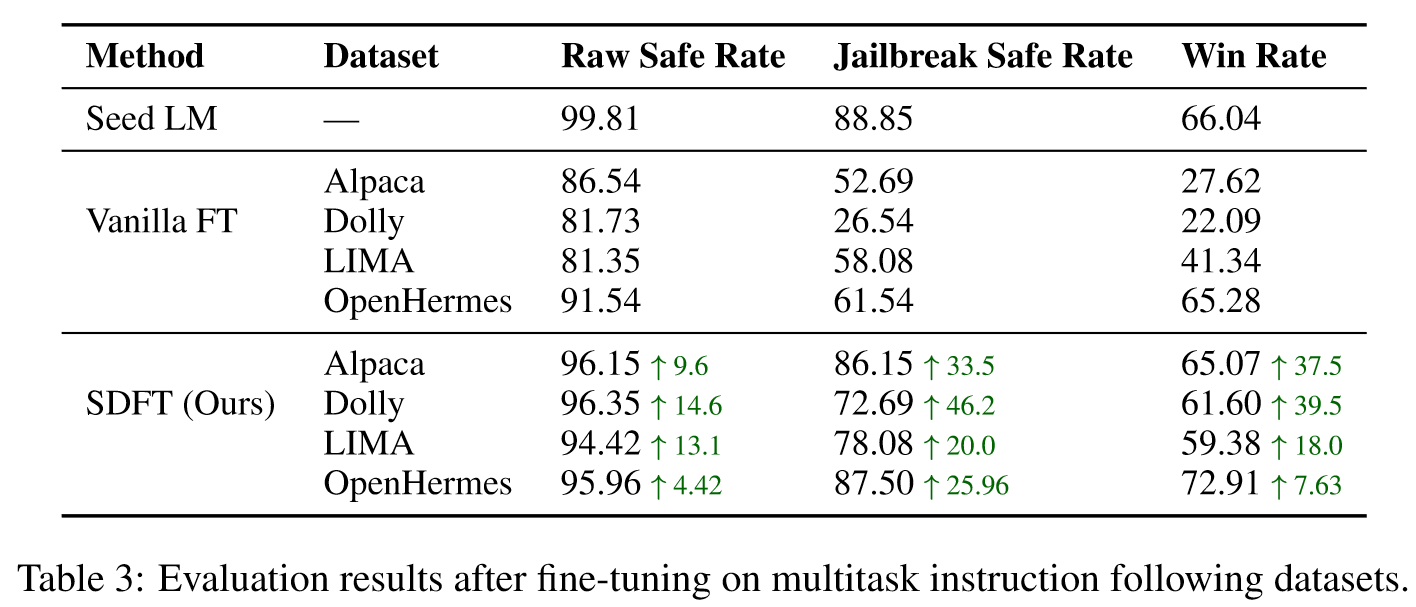
🤖ChatGPT
ChapGPT
1. 论文的创新之处与独特性:
本文提出了自蒸馏微调(SDFT)方法,这是一种创新的方法,旨在解决微调大型语言模型(LLM)时出现的灾难性遗忘问题。其创新性在于采用生成的蒸馏数据集来桥接任务特定数据集与模型原始分布之间的差距。与传统的直接在新数据集上调整模型的微调方法不同,SDFT保持了LLM的通用能力,并在不显著丧失任务无关性能的情况下,增强了其在特定下游任务上的表现。
2. 论文中存在的问题及改进建议:
尽管SDFT显示出了有希望的结果,但它主要集中在任务数据集与LLM最初训练数据相近的情景中,这可能限制了其在高度专业化或与预训练数据显著不同的任务中的适用性。此外,评估主要关注某些类型的任务(如数学推理和代码生成),可能无法充分展示该方法在更广泛的NLP应用中的多样性。
改进建议:
- 扩展测试到更多领域: 未来的工作可以扩大测试场景的范围,包括更多涉及创造性或主观输出的任务,如故事生成或开放式对话。
- 与其他持续学习策略结合: 将SDFT与其他持续学习技术(如经验重放或弹性权重固化)结合,可能会在保留过去知识和适应新信息方面取得更好的效果。
3. 基于论文的内容和研究结果,提出的创新点或研究路径:
- SDFT在跨领域应用: 研究SDFT在不同领域(如生物医药文本处理或法律文件分析)的有效性和适应性,验证其鲁棒性和可扩展性。
- SDFT与多模态数据: 将SDFT扩展到可以处理多模态数据的版本,如将视觉或音频输入与文本结合,这在任务如视频描述和多模态情感分析中越来越重要。
- 在联邦学习环境中应用SDFT: 在数据隐私问题阻止跨不同实体共享原始数据的联邦学习设置中应用SDFT。
4. 为新的研究路径制定的研究方案:
跨领域应用SDFT:
- 目标: 评估SDFT在不同专业领域中的适应性和有效性。
- 方法: 在一系列NLP任务上应用SDFT,如法律文件摘要、生物医学信息提取和多语种翻译。
- 预期成果: 确定SDFT的泛化能力,并识别成功应用其所需的领域特定挑战或要求。
SDFT与多模态数据:
- 目标: 开发并测试能够处理多模态输入的SDFT版本,提高模型在更复杂实际任务中的适用性。
- 方法: 在SDFT框架中加入图像和音频处理流程,并在如视频字幕和音视频事件检测等任务上进行测试。
- 预期成果: 创建一个能够理解和生成多模态内容的更多功能的模型,为SDFT在多媒体内容分析中开辟新的应用。
在联邦学习环境中应用SDFT:
- 目标: 使SDFT适应联邦学习环境,允许在分布式数据集中保护隐私的微调。
- 方法: 修改SDFT以在联邦学习框架中运作,其中只共享节点之间的模型更新,不共享数据本身。
- 预期成果: 开发一种在数据不能集中托管的情景中部署SDFT的方法,从而提高微调过程的隐私性和安全性。
这些提案旨在扩展SDFT的应用性,推动在NLP及其它领域中微调方法的可能性。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!