请注意,本文编写于 729 天前,最后修改于 729 天前,其中某些信息可能已经过时。
目录
Resource Info Paper https://arxiv.org/abs/2402.14658 Code & Data https://opencodeinterpreter.github.io/ Public Arxiv Date 2024.07.25
Summary Overview
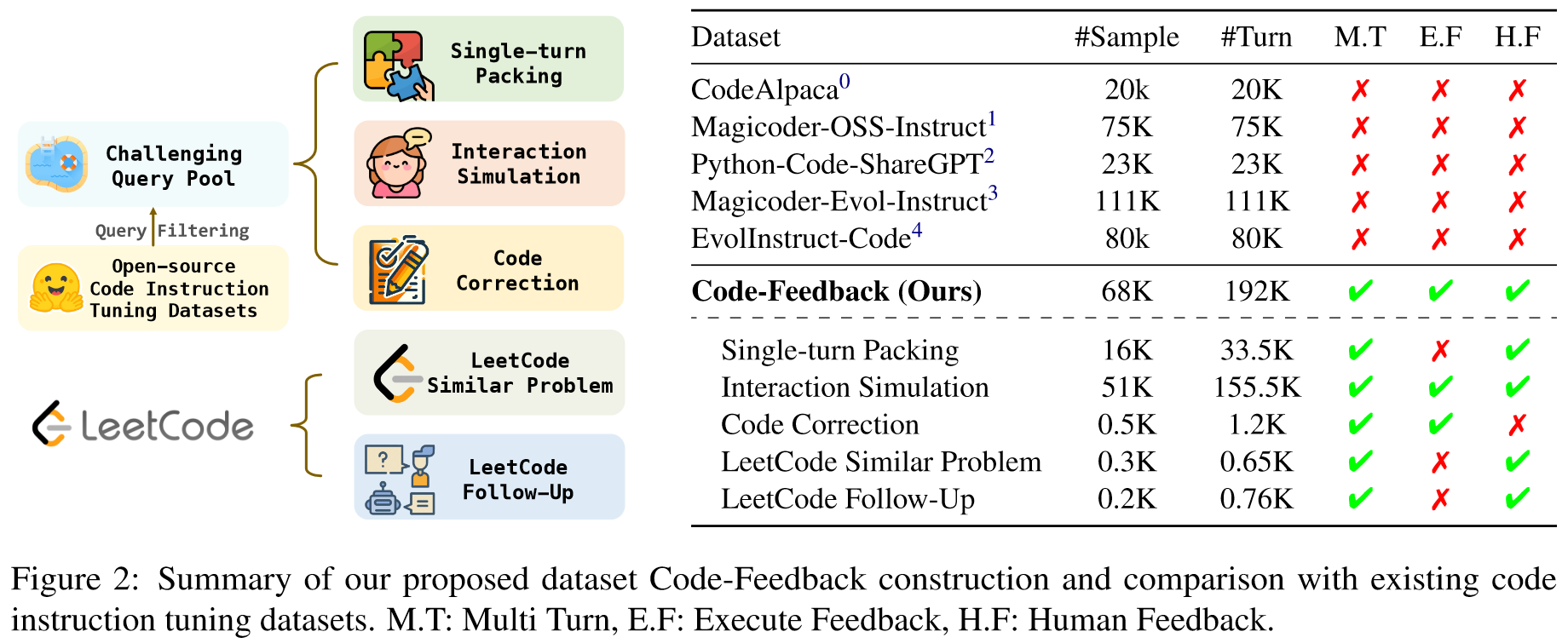
OpenCodeInterpreter 主要提出了一个 Conde-Feedback 数据集,并且在上面微调了模型 (CodeLlama & DeepSeekCoder)。
Main Content
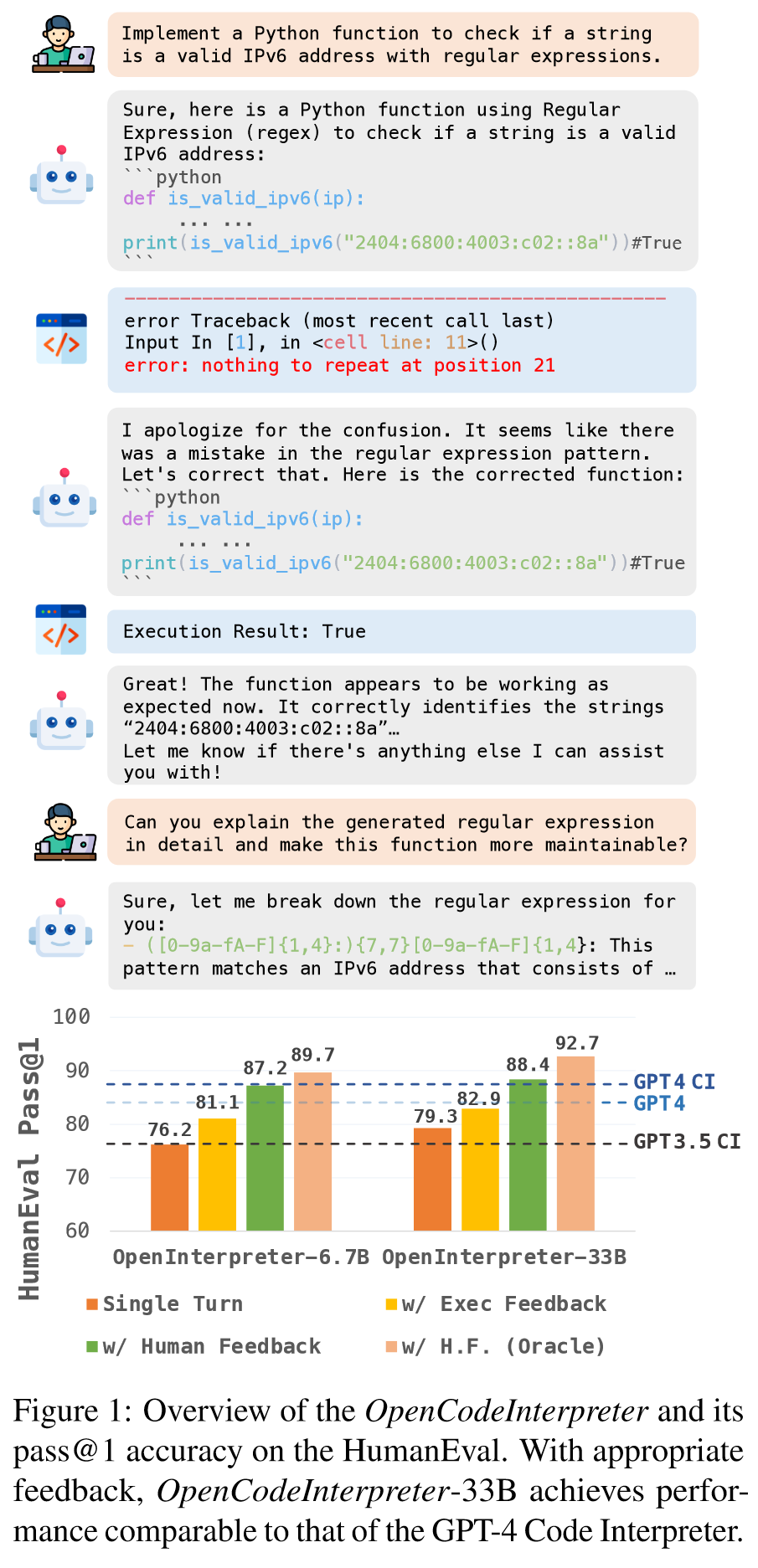
两类 Feedback:
- execution feedback: include execution outputs and diagnostics
- human feedback: comprising follow-up guidance or instructions from users
Code-Feedback 特点:
- Diverse and chanllenging real-world queries: 数据集应包含源自现实世界编码任务的广泛查询,呈现多样性和复杂性
- Multi-turn dialogue structure: 代码反馈被构造为多轮对话,包含两种类型的反馈: execution feedback & human feedback
- Interleaved text and code responses: 每个文本都应提供自然语言解释与代码片段混合在一起的响应,从而提供解决编码查询的整体方法
🤖ChatGPT
ChapGPT
基于对《OpenCodeInterpreter_2024_Zheng et al.pdf》论文的深入分析,以下是我的专业分析和原创见解:
1. 论文的创新之处与独特性:
该论文提出了OpenCodeInterpreter,一种整合编译器诊断和人类反馈进行迭代代码生成和优化的开源系统。其主要创新点包括:
- 多轮交互和反馈机制:论文通过构建Code-Feedback数据集,将多轮人类反馈和编译器反馈结合,实现代码的迭代优化和修正。这种方法显著提高了代码生成的准确性和可靠性。
- 高质量单轮数据与多轮交互数据的融合:通过将WizardCoder 110K等高质量单轮数据与多轮交互数据按比例混合,优化了模型的训练过程,使其能够更好地处理复杂的编码任务。
- 综合评估框架:在HumanEval和MBPP基准测试及其扩展版本中,该模型展示了卓越的性能,尤其在多轮代码生成和修正任务中表现出色,达到了开源模型的新标杆。
2. 论文中存在的问题及改进建议:
尽管该论文在代码生成领域取得了显著进展,但仍存在以下问题:
- 数据集局限性:尽管Code-Feedback数据集包含了多种交互数据,但其覆盖范围可能仍然有限,尤其是在处理非常规编程语言和特定领域时。建议进一步扩展数据集的多样性,涵盖更多编程语言和实际应用场景。
- 多轮交互次数限制:当前模型在多轮交互中仅限于两轮,可能无法充分处理复杂问题。可以考虑增加交互轮次,探索更复杂的交互策略。
- 用户意图理解的局限性:模型在处理用户模糊或复杂意图时可能存在困难,建议结合自然语言理解技术,增强模型对用户意图的准确把握和回应能力。
3. 基于论文的内容和研究结果,提出的创新点或研究路径:
基于论文的研究结果,可以提出以下具有研究潜力的创新点或研究路径:
- 跨语言代码生成与优化:探索多语言代码生成模型的训练方法,使模型能够理解和生成多种编程语言的代码,提高其在不同语言环境下的适用性。
- 动态交互式编程助手:开发实时交互的编程助手,能够根据用户实时输入进行动态反馈和代码修正,提升开发效率。
- 智能调试与错误修正系统:结合深度学习和编译器技术,开发一个能够自动识别和修正代码错误的智能系统,减少开发人员的调试时间和精力。
4. 为新的研究路径制定的研究方案:
研究路径一:跨语言代码生成与优化
研究方法:
- 数据集扩展:收集多种编程语言的大规模代码数据集,涵盖不同的编程范式和应用领域。
- 多任务学习:利用多任务学习方法,训练一个能够处理多种语言的通用代码生成模型。
- 迁移学习:在单一语言上预训练模型,然后通过迁移学习适应其他编程语言,提高模型的跨语言生成能力。
步骤:
- 数据集准备:收集和清洗多种编程语言的数据集。
- 模型训练:设计多任务学习框架,训练通用代码生成模型。
- 模型优化:利用迁移学习方法,在特定语言上进行微调和优化。
- 性能评估:使用跨语言基准测试评估模型性能,进行多语言代码生成实验。
期望成果:
- 一个能够高效生成和优化多种编程语言代码的通用模型。
- 提高模型在多语言环境下的适用性和生成准确性。
研究路径二:动态交互式编程助手
研究方法:
- 实时交互模块:开发一个实时交互模块,能够实时处理用户输入并提供即时反馈。
- 迭代优化机制:设计迭代优化算法,结合用户反馈和模型输出,逐步改进生成的代码。
- 用户意图理解:结合自然语言理解技术,增强模型对用户意图的理解和响应能力。
步骤:
- 实时交互模块开发:设计并实现能够实时处理用户输入和反馈的交互模块。
- 迭代优化算法:开发迭代优化算法,结合用户反馈进行代码改进。
- 意图理解增强:整合自然语言理解技术,提高模型对用户意图的准确把握。
- 用户测试:进行用户测试和反馈收集,迭代优化模型和系统。
期望成果:
- 一个能够实时与用户交互的编程助手系统。
- 提高开发效率和用户满意度的动态交互体验。
研究路径三:智能调试与错误修正系统
研究方法:
- 错误检测与分类:利用深度学习技术,开发自动错误检测与分类模块。
- 自动修正与建议:设计自动修正算法,结合编译器反馈和模型生成,提供修正建议和自动修正功能。
- 用户反馈回路:建立用户反馈回路,持续改进模型的错误检测和修正能力。
步骤:
- 错误检测模块开发:设计并实现能够自动检测代码错误的深度学习模型。
- 自动修正算法:开发结合编译器反馈的自动修正算法。
- 用户反馈机制:建立用户反馈回路,收集和分析用户反馈,优化模型性能。
- 系统集成:将错误检测和修正模块集成到开发环境中,进行全面测试和优化。
期望成果:
- 一个能够自动检测和修正代码错误的智能调试系统。
- 减少开发人员的调试时间,提高开发效率和代码质量。
通过这些研究路径的探索和实践,可以进一步提升代码生成和优化技术,为编程和软件开发带来新的突破和进展。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录