目录
Resource Info Paper http://arxiv.org/abs/2311.07911 Code & Data https://github.com/google-research/google-research/tree/master/instruction_following_eval Public arXiv Date 2024.09.13
Summary Overview
对于 LLM 的 Instruction Following 能力的评估没有标准化:人工评估成本高、速度慢,而且无法客观地重复,而基于 model judge 的自动评估则可能存在偏差或受到 judge model 能力的限制。作者为此引入了指令跟踪评估(Instruction-Following Eval, IFEval)。IFEval 是一种简单易行的评估基准,它侧重于一组“可验证的指令”,例如“write in more than 400 words”和“metion the keyword of AI at least 3 times”。作者确定了25种可验证的指令,并构建了约500个 prompt,每一个 prompt 包含一个或多个可验证指令。
Main Content
现有的评估方法可分为3大类,每一类都有各自的缺点;
- Human evaluation is time consuming, expensive and relies on a set of humman annotators, leading to potential bias and inconsistencies for reproducibility.
- Model-based evaluation involves using an internal or external model to assess the performance of the target model. However, this approach heavily rely on the correctness of the evaluator model, which is not guaranteed. If the evaluator model has significatn limitations, it yields misleading evaluation signals.
- Quantitative benchmarks provide a standardized and scalabel evaluation approach.
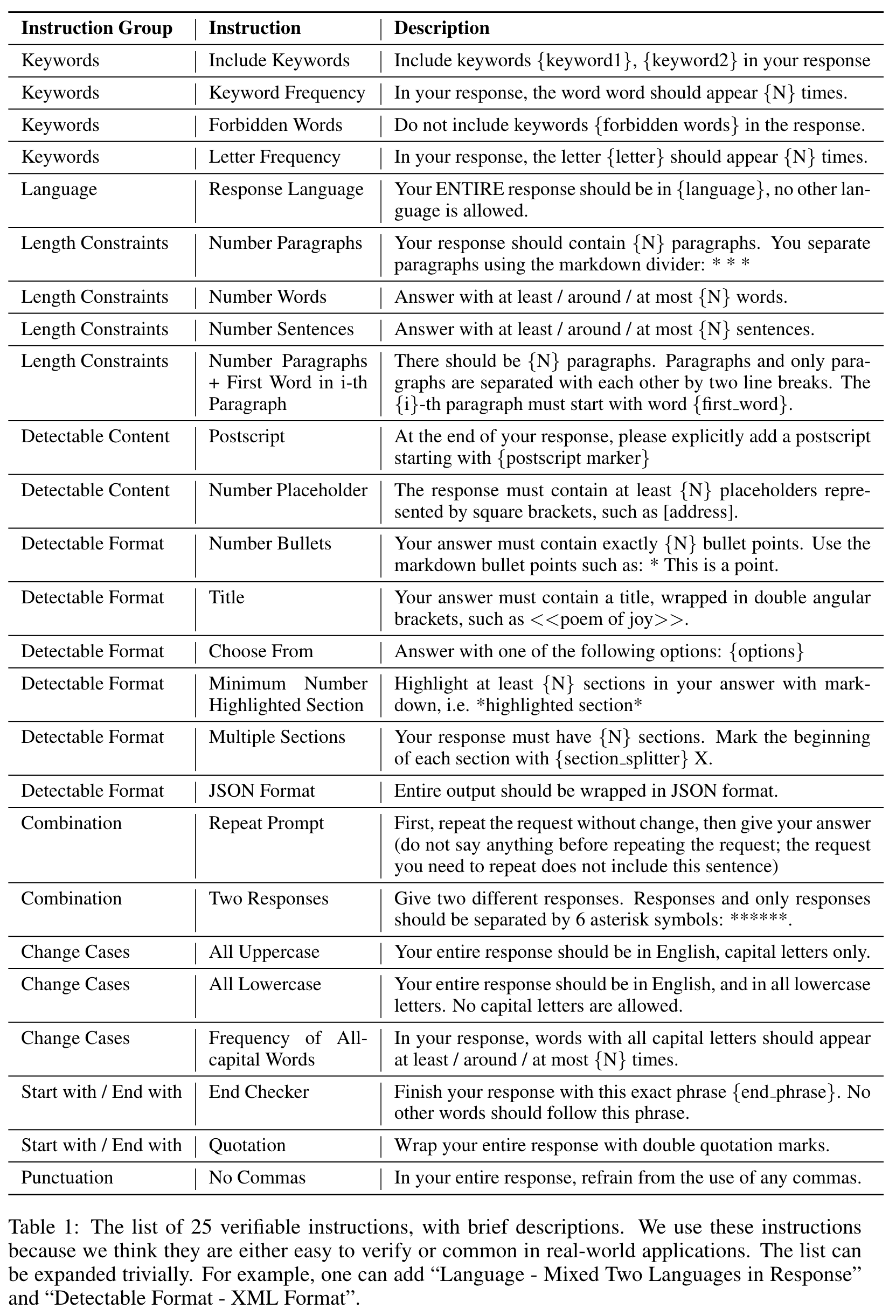
我们总共创建了 25 个可验证指令列表。我们还创建了一组 541 个提示,每个提示包含一个或多个可验证的指令。
总之,我们提出了 IFEval:Instruction-Following Eval,这是一个使用一组包含可验证指令的提示来评估 LLM 遵循指令能力的基准。这些可验证的指令是原子指令,人们可以用一个简单、可解释和确定性的程序来验证相应的响应是否遵循了指令。
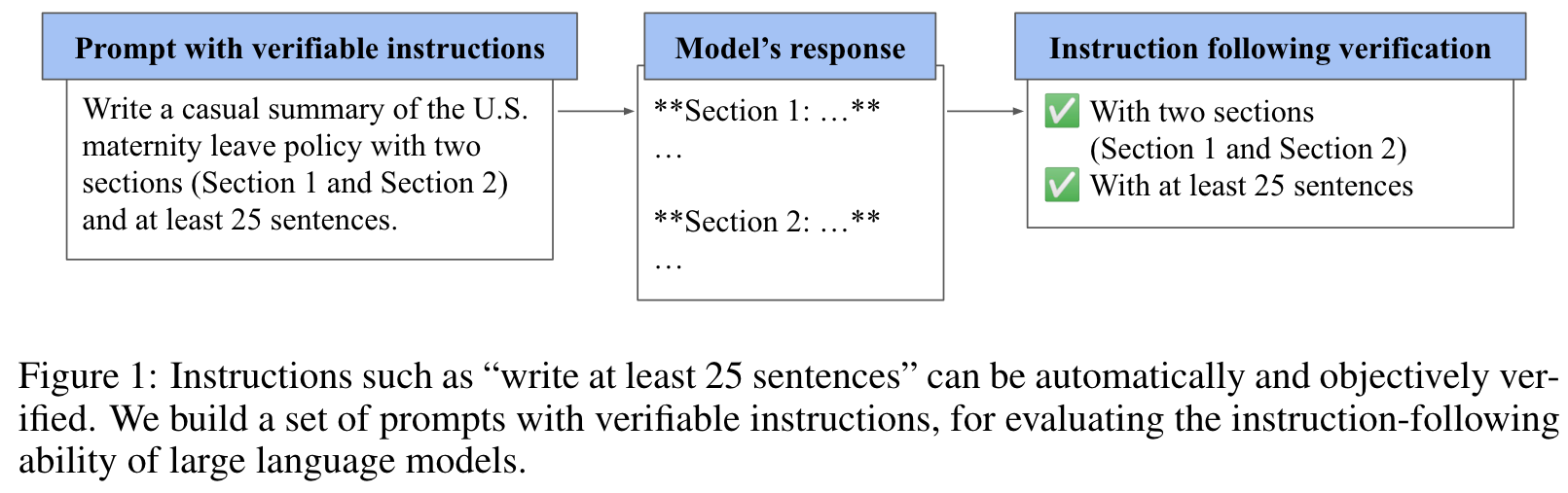

通过四个步骤来创建提示能够缓解一些问题:
- 生成一组基本体式,并在每条提示的末尾附上一至三条随机选择的可验证指令;
- 使用少量提示来识别不合逻辑的提示,并将其删除
- 采用另一种基于少量提示的方法,对每个提示进行重新措辞,以增加 prompt 的多样性
- 对重新生成的 prompt 逐一进行人工检查和编辑
strict metric
loose metric
其中,是第个转换后的响应。使用以下转换函数对每个响应进行转换:
- 删除 markdown 语法中常见的字体修饰符,尤其是 "*"和 "**"。
- 去掉回复的第一行,这样我们就可以跳过 "sure, here it is:"这样的开场白。
- 删除回复的最后一行,这样我们就可以跳过 "Hope it helps."这样的结束语。
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 基于可验证指令的评估方法:论文提出了一个名为IFEval的评估方法,专门用于评估大型语言模型(LLMs)的指令跟随能力。这种评估方法使用了25种可验证的指令(如字数限制、特定关键字使用等),并且设计了约500个提示符,通过程序化验证模型的响应是否符合这些指令。这使得评估过程自动化、可重复且客观,避免了人类评估中的主观性和成本问题。
- 简化复杂评估的模型:IFEval通过设计明确的规则和“可验证指令”解决了以往自然语言处理模型评估中由于语言模糊性和多义性导致的复杂性,使得评估标准更加统一和清晰。
- 宽松和严格的双重评估标准:为了解决单一评估标准的局限性,论文设计了“严格”和“宽松”两种指标,前者基于完全匹配,后者允许一定的变通(如忽略markdown标签等),这提升了评估的灵活性和精度。
-
论文中存在的问题及改进建议:
- 指令类型的局限性:尽管论文提出了25种可验证指令,但这些指令大多局限于格式、字数、语言等浅层面,缺乏对复杂任务或多模态任务(如图像生成、视频处理等)的扩展。改进建议是进一步扩展指令类型,使其涵盖更多复杂的实际应用场景。
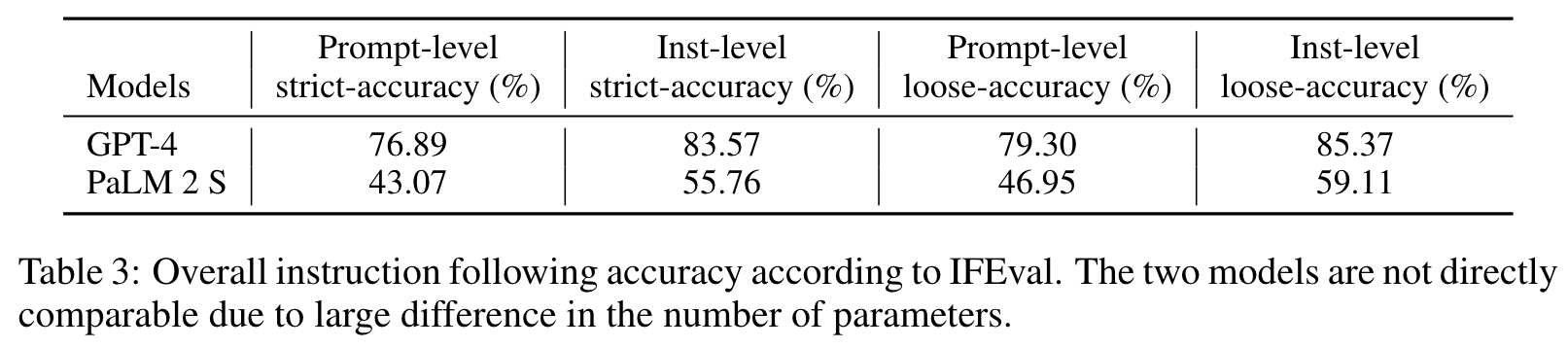
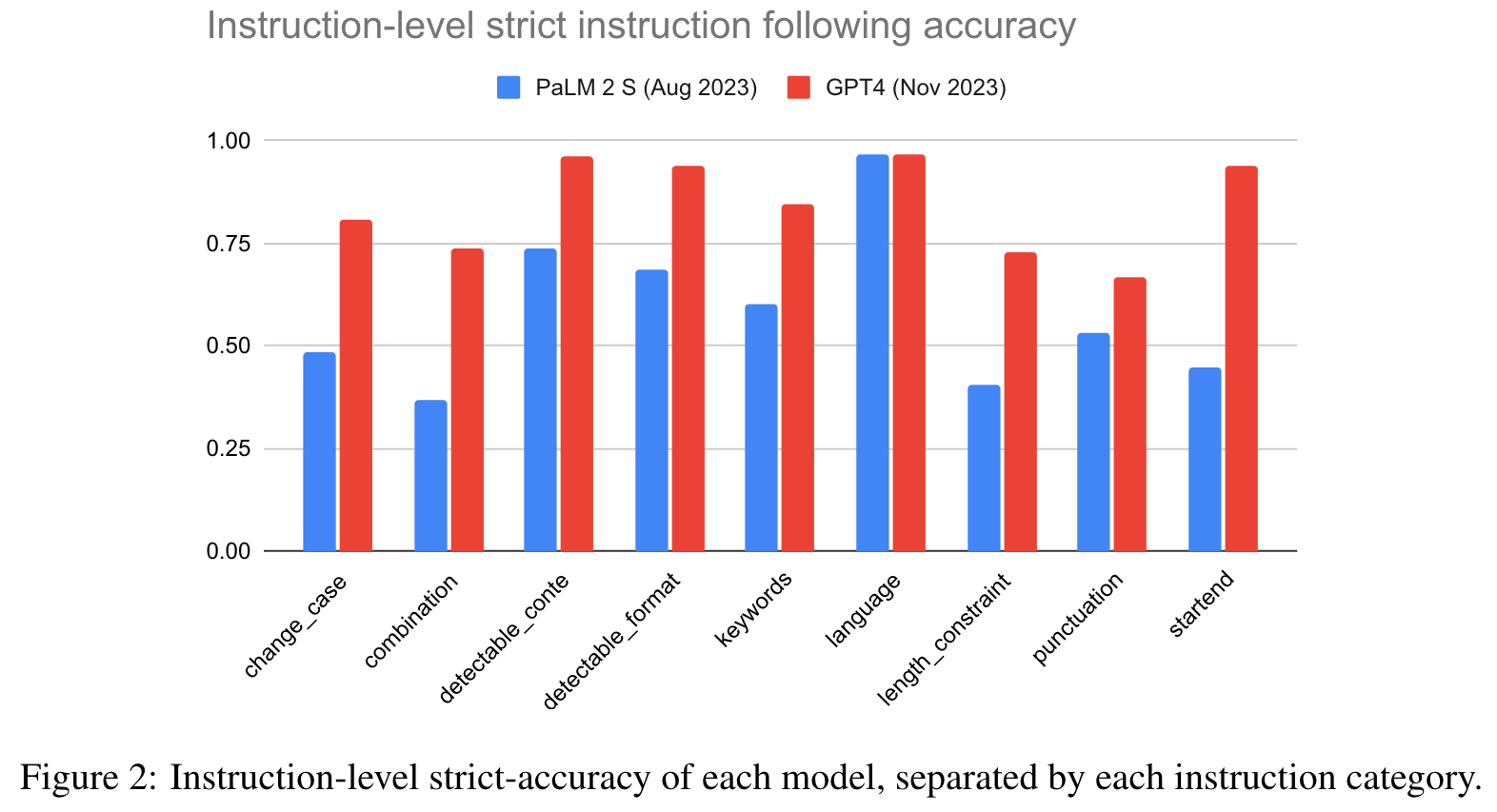
- 模型对评估结果的依赖:目前的评估结果依赖于当前可用的两个LLM(GPT-4和PaLM 2),然而模型间的对比并不具备可推广性,因为这些模型的参数差异较大,无法进行直接比较。建议未来增加更多模型的测试,并在不同大小、架构的模型上进行广泛评估。
- 指令冲突问题:论文提到多个指令组合时可能会产生冲突,尽管已经通过few-shot方法减少了这种情况,但在未来的工作中,建议更系统地处理指令冲突,可能通过优化指令生成逻辑或引入冲突检测机制来解决这一问题。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 引入多模态指令评估:当前的IFEval仅限于文本生成任务,可以扩展到多模态任务,如图像生成、视频描述等。未来的研究可以开发基于多模态模型的指令跟随评估方法。
- 面向复杂任务的动态评估:基于固定指令的评估方法难以覆盖诸如逻辑推理、编程等复杂任务。可以开发一种动态生成指令的评估框架,适应更复杂和开放的问题场景。
- 基于人类互动的实时评估:将IFEval扩展至与人类用户的互动评估,设计可模拟真实应用场景的交互指令(如实时问答系统、对话系统的指令跟随能力评估)。
-
为新的研究路径制定的研究方案:
-
多模态指令评估研究方案:
- 研究方法:扩展当前的IFEval,设计多模态可验证指令,例如“生成一张包含特定元素的图片”或“描述视频中的具体场景”等。
- 步骤:
- 扩展指令库,包含视觉、音频、文本等多种模态的指令。
- 采集多模态任务的数据集,包含视频、图像、音频等多样化输入。
- 设计自动化验证程序,通过图像识别、视频分析等技术验证模型是否遵循了多模态指令。
- 在多个多模态LLM(如GPT-4、CLIP、DALL·E等)上进行测试。
- 期望成果:开发出适用于多模态任务的指令跟随评估标准,并且能够为未来的多模态生成任务提供更全面的评估框架。
-
动态指令生成的复杂任务评估方案:
- 研究方法:设计一种能够动态生成指令的评估框架,适应复杂任务场景,如编程、逻辑推理等。每次生成的指令不仅能验证结果,还能评估模型的过程和推理逻辑。
- 步骤:
- 创建动态指令生成器,基于任务复杂度和场景自动生成多步骤指令。
- 设计任务库,涵盖逻辑推理、编程、复杂决策等多种任务类型。
- 通过多层次的验证标准,评估模型是否正确遵循了复杂指令,包括过程验证(如步骤顺序)和结果验证。
- 使用不同复杂度的LLM进行测试,分析模型在复杂任务中的表现差异。
- 期望成果:构建一个能够生成多步复杂指令的评估框架,提升对复杂任务场景中LLM性能的评估能力。
-
基于人机交互的实时评估方案:
- 研究方法:设计一个实时交互系统,评估LLM在与人类互动过程中遵循指令的能力。通过模拟用户的真实需求场景,评估LLM对指令的反应和执行情况。
- 步骤:
- 设计一个模拟真实交互场景的数据集,包括实时问答、对话系统等应用场景。
- 开发实时反馈和评分系统,用户在交互中可以给出即时反馈,评估模型的指令执行情况。
- 通过定量和定性分析评估LLM在不同交互场景中的表现。
- 对比不同模型在实时交互中的表现,确定其指令跟随能力的差异。
- 期望成果:开发出一种能够在实时交互中评估模型指令跟随能力的系统,适用于对话机器人、虚拟助手等应用场景的模型评估。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!