目录
Resource Info Paper http://arxiv.org/abs/2404.11018 Code & Data / Public arXiv Date 2024.09.11
Summary Overview
最新扩展的上下文窗口使我们能够使用数百或数千个示例来研究 ICL ,这就是 many-shot 机制。从 few-shot 到 many-shot,观察到了 LLM 在各种生成任务上的显著增加。但是可用的手工生成的示例的缺乏限制了 many-shot,为了减少这种限制,作者设计了两类方法:1. Reinforced ICL 使用模型生成的示例进行替代。2. Unsupervised ICL 完全删除了利用仅保留了问题。两类方法都对于 many-shot 有积极的影响。
Main Content
Many-shot learning - 使用大量的示例进行 ICL,可以更好地指定任务,减少对微调的需求,并可能使 LLM 更具通用性和适应性。
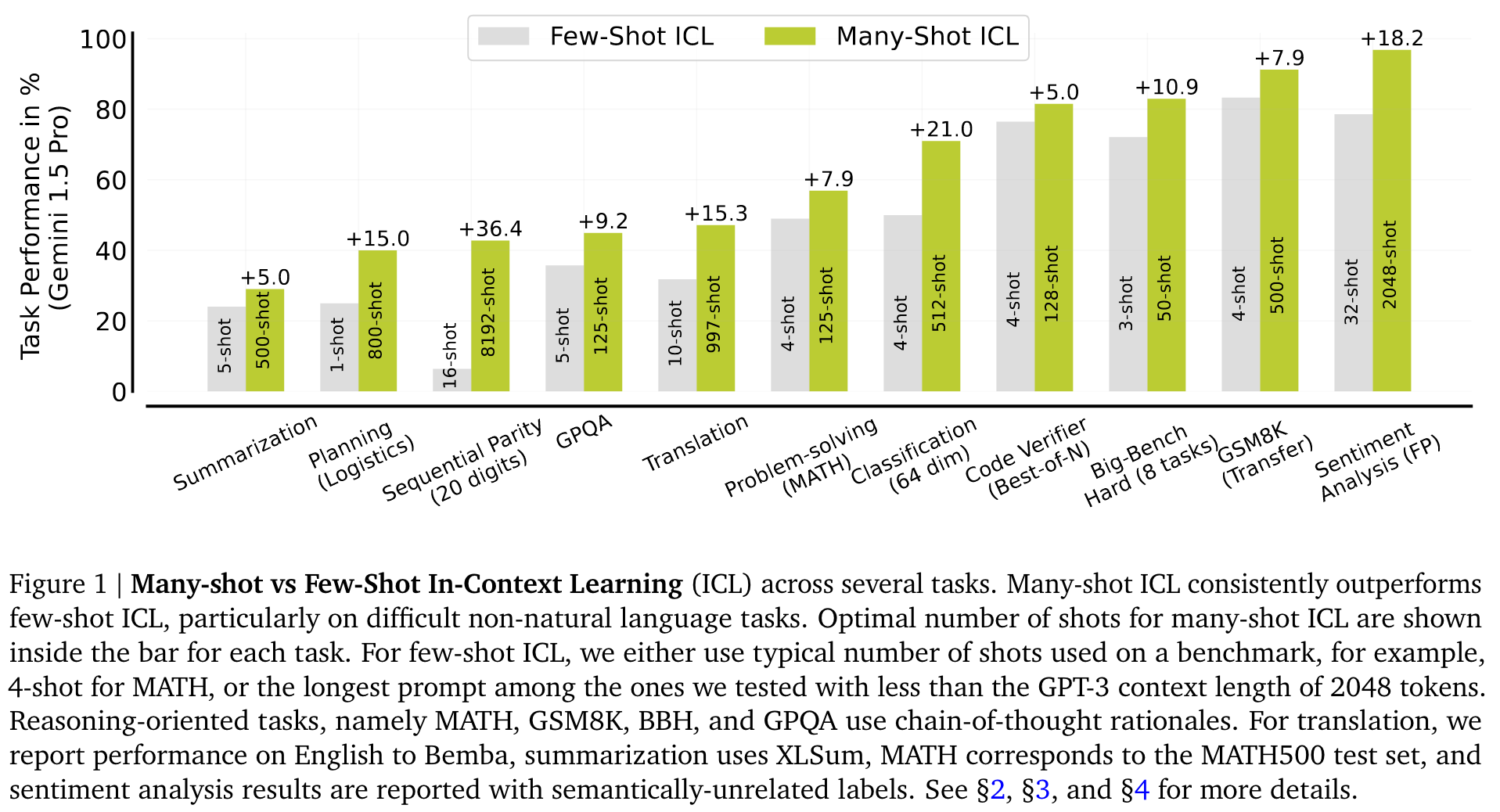
使用成百上千的 shot 学习效果明显优于使用少量 shot 的ICL (Figure 1)。
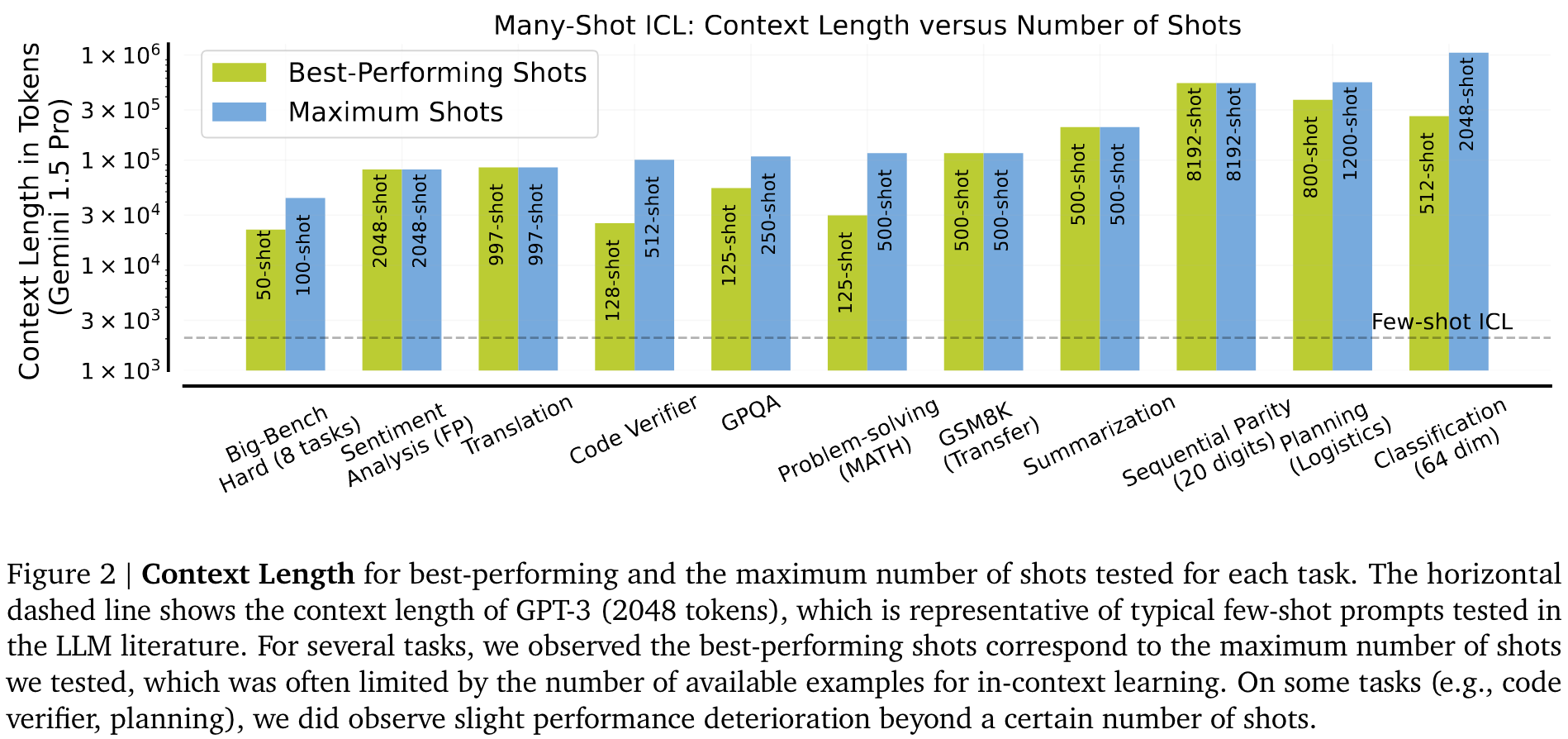
通常只有当 shot 数量达到数十万个 token 时,才能实现最高性能 (Figure 2)。我们发现,在 MATH、GPQA 和 Big-Bench Hard 等问题解决任务中,reinforced ICL 和 unsupervised ICL 比使用手工生成的 few-shot 效果更有效。
Contributions:
- Scaling ICL: 使用了 Gemini 1.5 Pro 系统地评估了 ICL 在各种任务不同规模的上下文示例下的性能。结果表明,从 few-shot 到 many-shot 时,性能会出现大幅提升。
- Reforced and Unsupervised ICL: 发现使用模型生成的理由或是只使用问题能够减少对于手工生成数据的依赖。
- Analysing ICL: many-shot ICL 能够克服预训练偏差,性能与微调相当,并且可以学习非 NLP 任务,而 few-shot ICL 在这些任务中则是十分的吃力。还揭示了 next-token prediction loss 可能并不能很好地预测 ICL 的性能。
为了获得可靠的结果,作者使用不同的随机数种子对每个 K-shot prompt进行多次随机抽样,并报告平均性能以及单个 seed 的性能。为了确保使用 K-shot prompt 逐步提供更多信息,设置中的 任何 K-shot 都包括少于 K-shot 提示中的所有上下文示例。
Scaling In-Context Learning
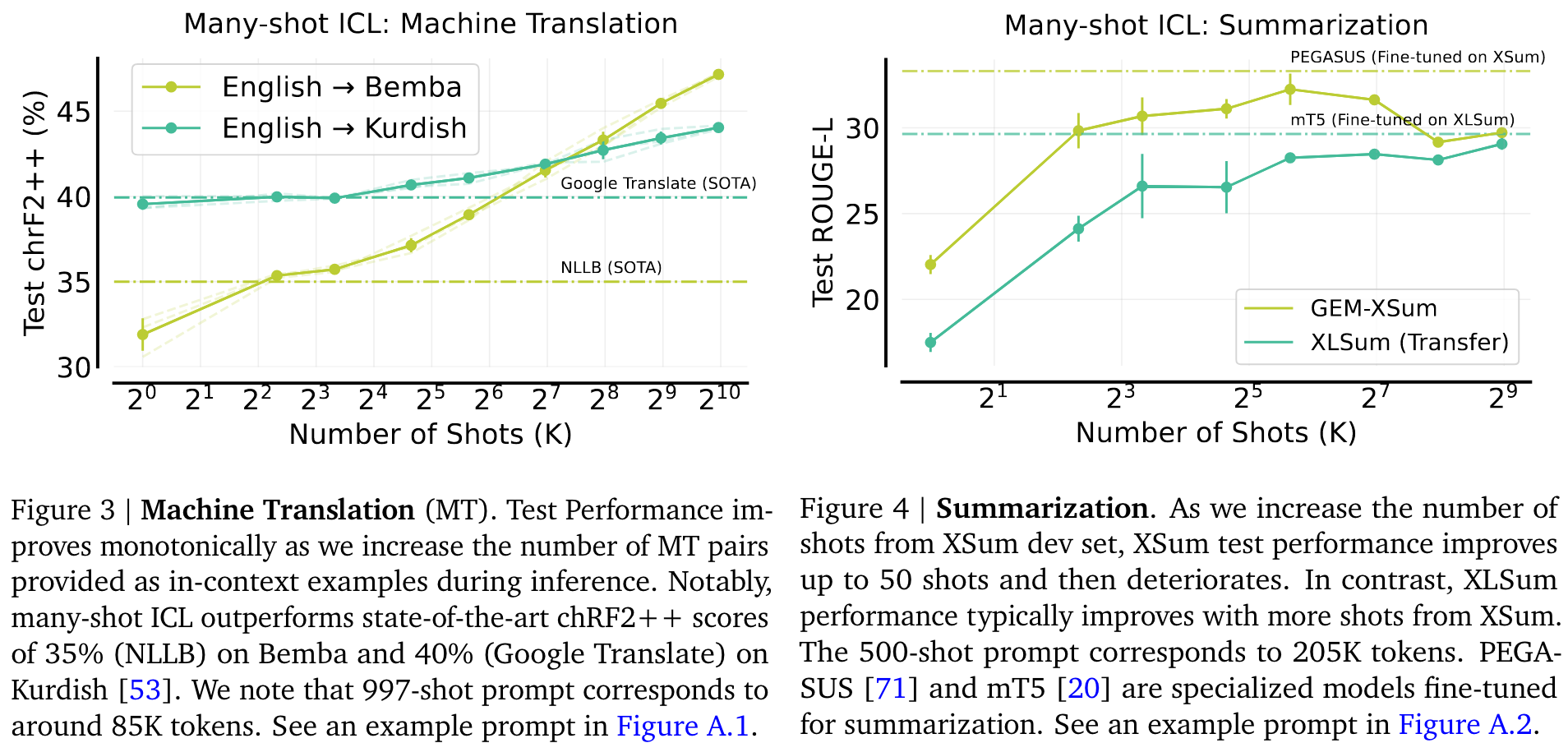
- Machine Translation**
使用 chrF2++ 对测试集中的前 150 个句子进行了性能评估,chrF2++ 是基于生成译文和参考译文之间字符和单词 n-gram 重合度的标准指标。
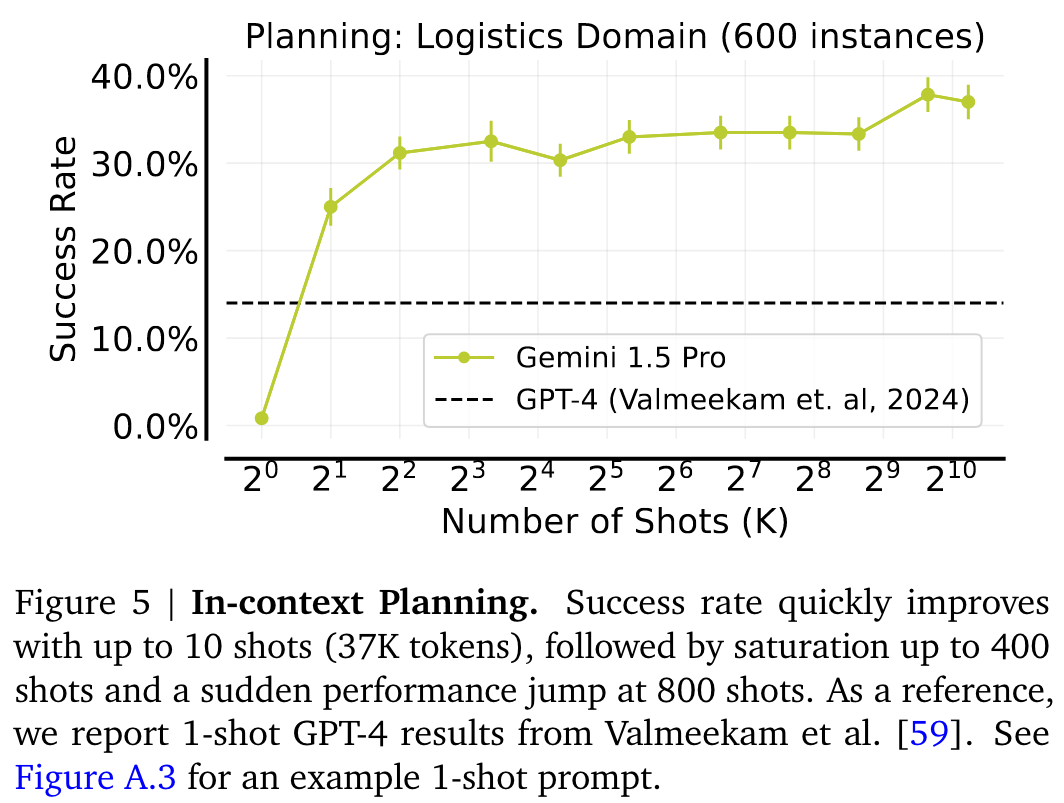
- Planning: Logistics Domain
- Reward Modelling with Many-Shot ICL: Learning Code Verifiers
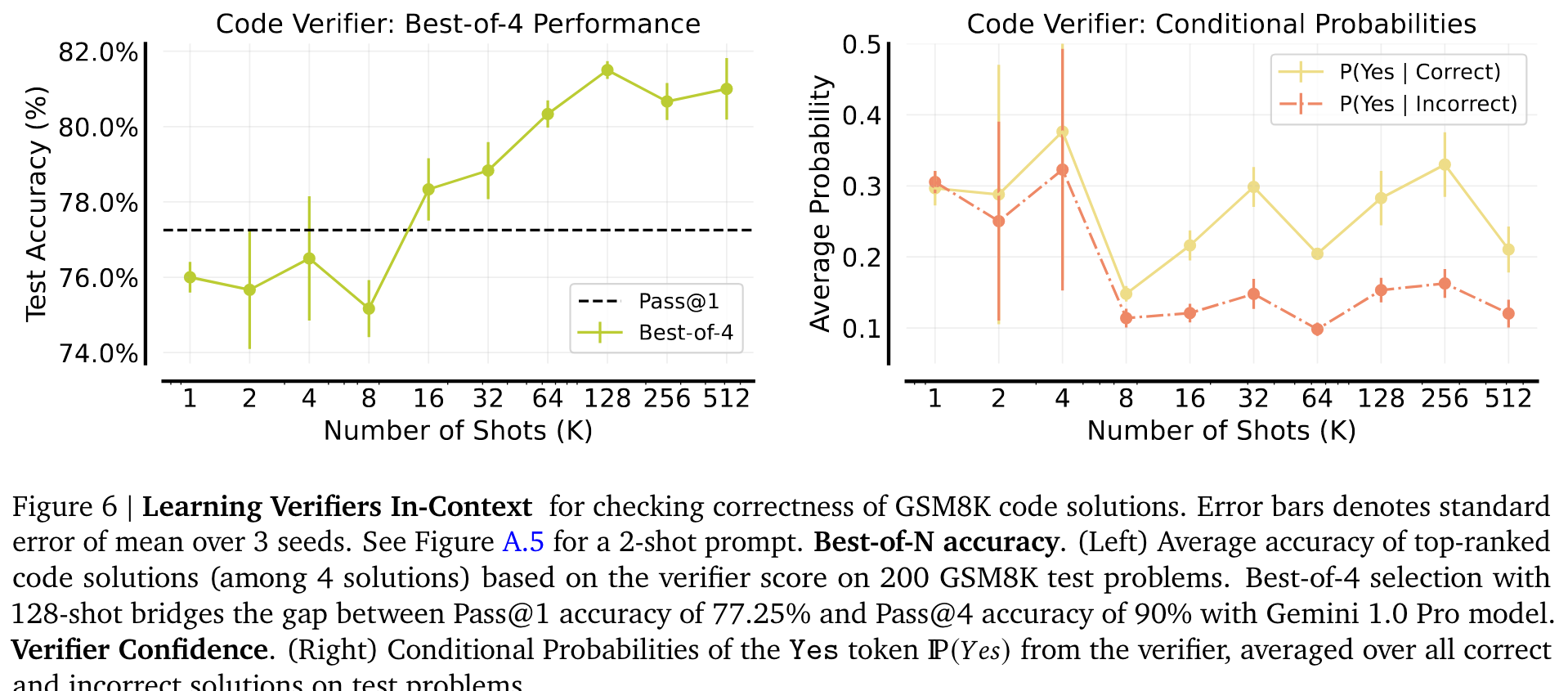
Many-shot learning without Human-Written Rationales
- Reinforced ICL
- Unsupervised ICL: 由以下部分组成 1.前言,如"You will be provided questions similar to the ones below." 2.未解决的输入或问题列表 3. zero-shot instruction 或带有所需输出格式输出的 few-shot prompt
当 LLM 已经掌握了解决任务所需的知识时,在提示中插入任何可以缩小任务所需知识范围的信息都会有所帮助。
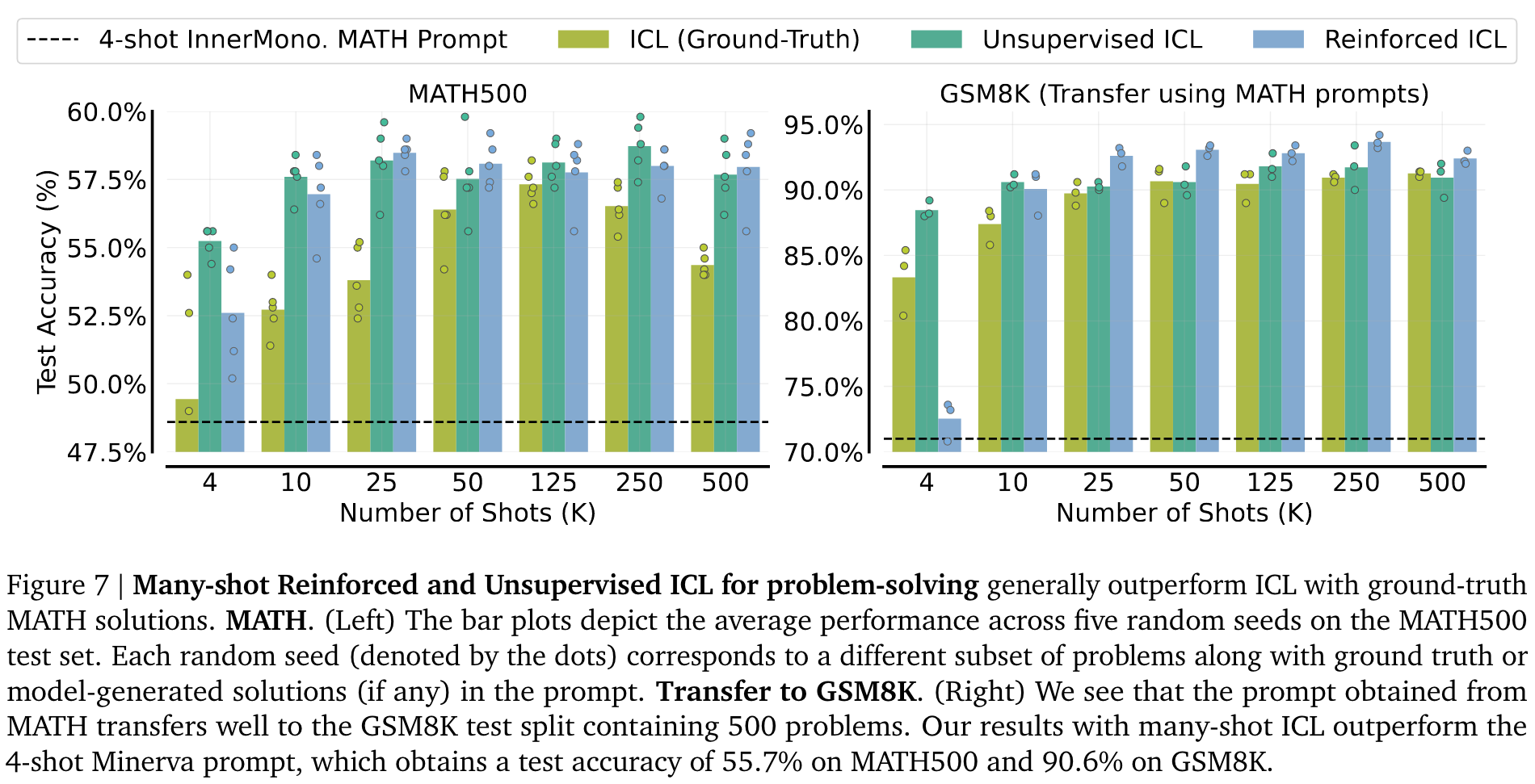
Singh 等人发现,根据 MATH 数据生成的模型数据集微调的模型,可提高 GSM8K 的测试性能,而 GSM8K 的问题分布与 MATH 不同。
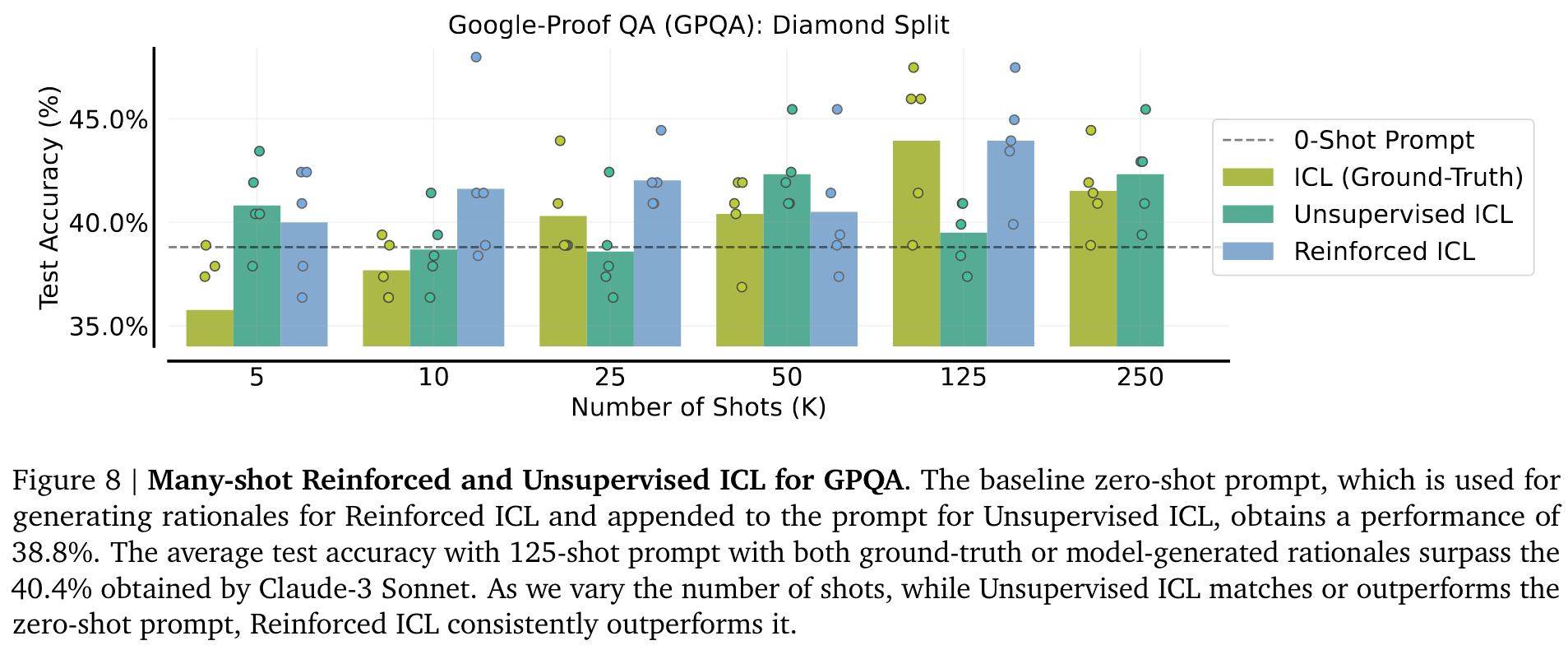
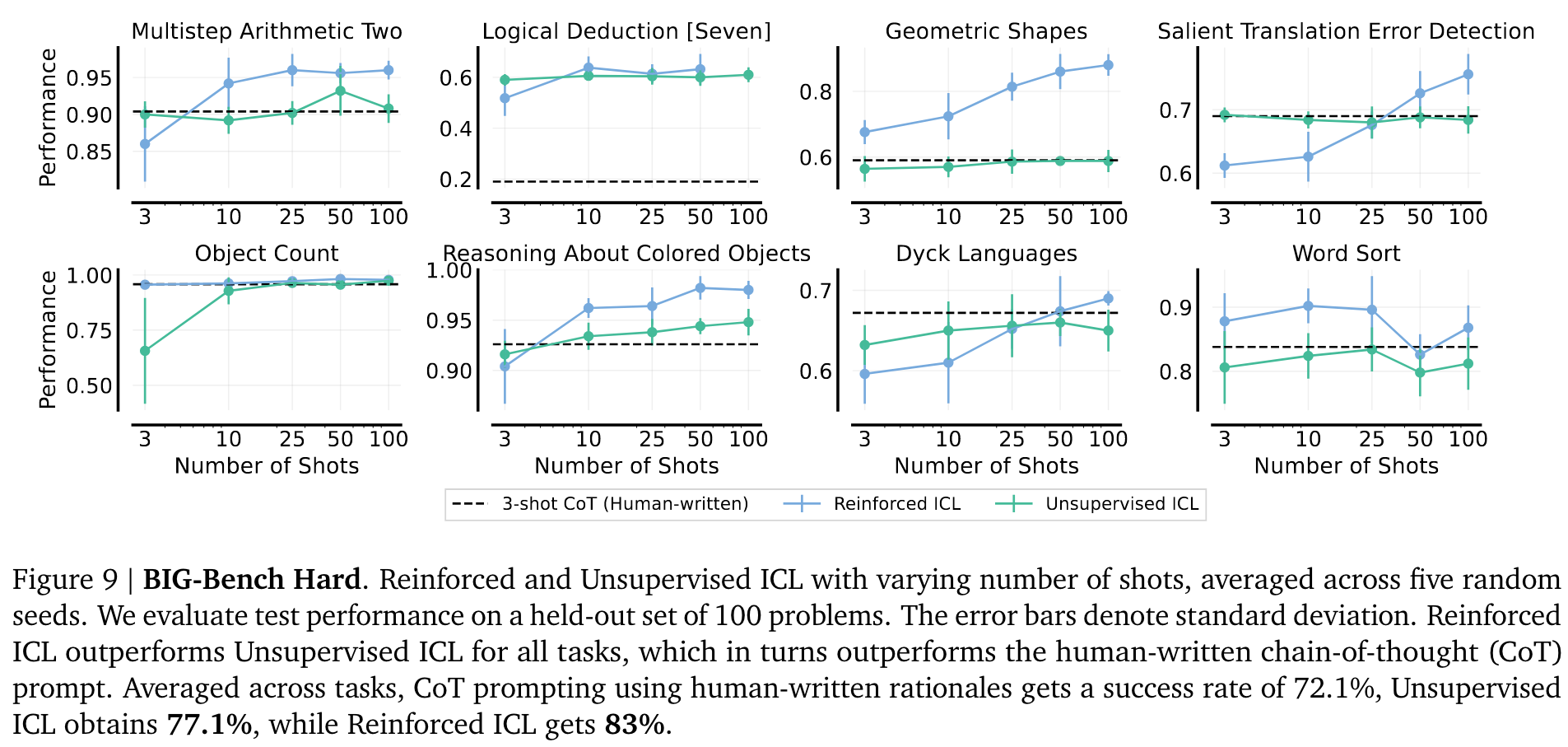
如 Figure 9 所示,在几乎所有的任务中,Reinforced ICL 都大大优于 Unsupervised ICL,而 Unsupervised ICL 又优于标准的 3-shot CoT prompt。
Analyzing Many-Shot ICL
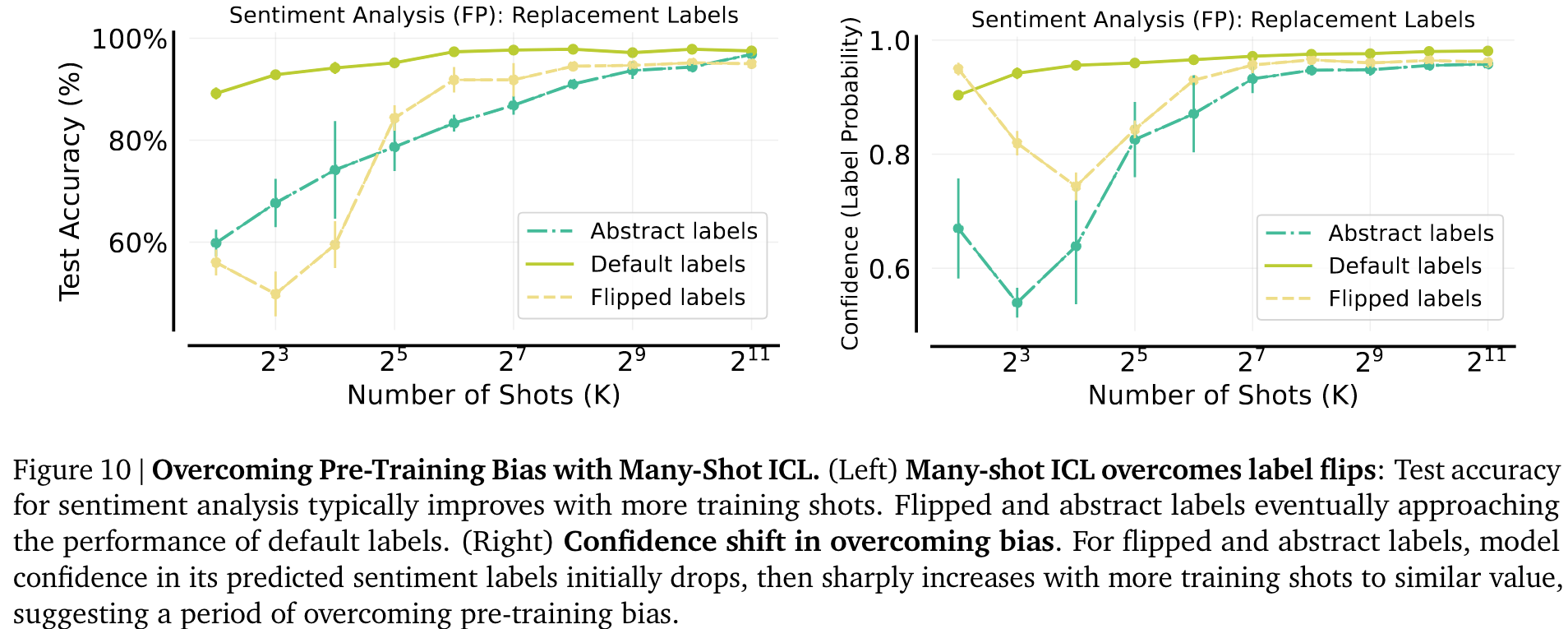
这表明,在 shot 较少的 ICL 中,模型难以克服预先训练中存在的偏差。然而,随着 shot 的增加,翻转标签和抽象标签的性能显著提高,接近默认标签的性能。

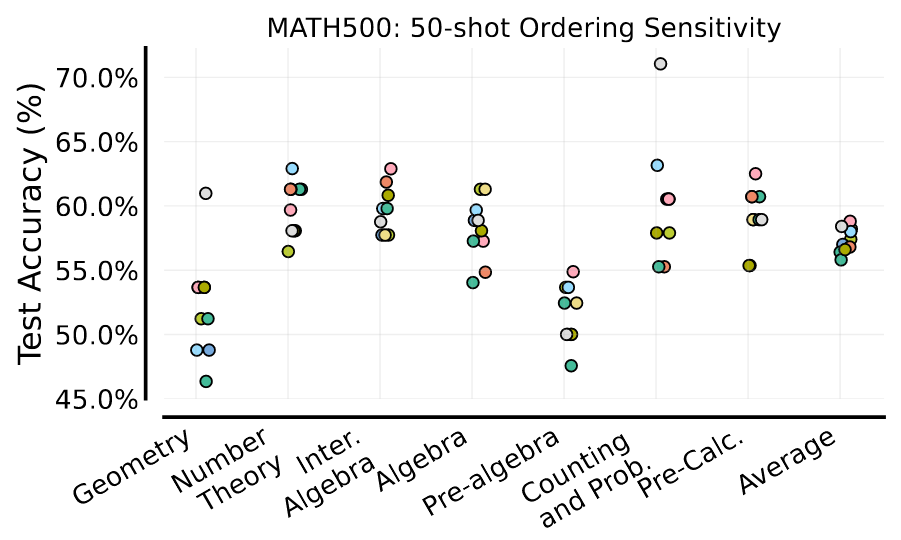
具体来说,我们对来自 MATH 训练拆分的固定 50 个上下文示例的十种不同随机排序进行了评估,并对保留的 MATH500 测试集进行了性能评估。
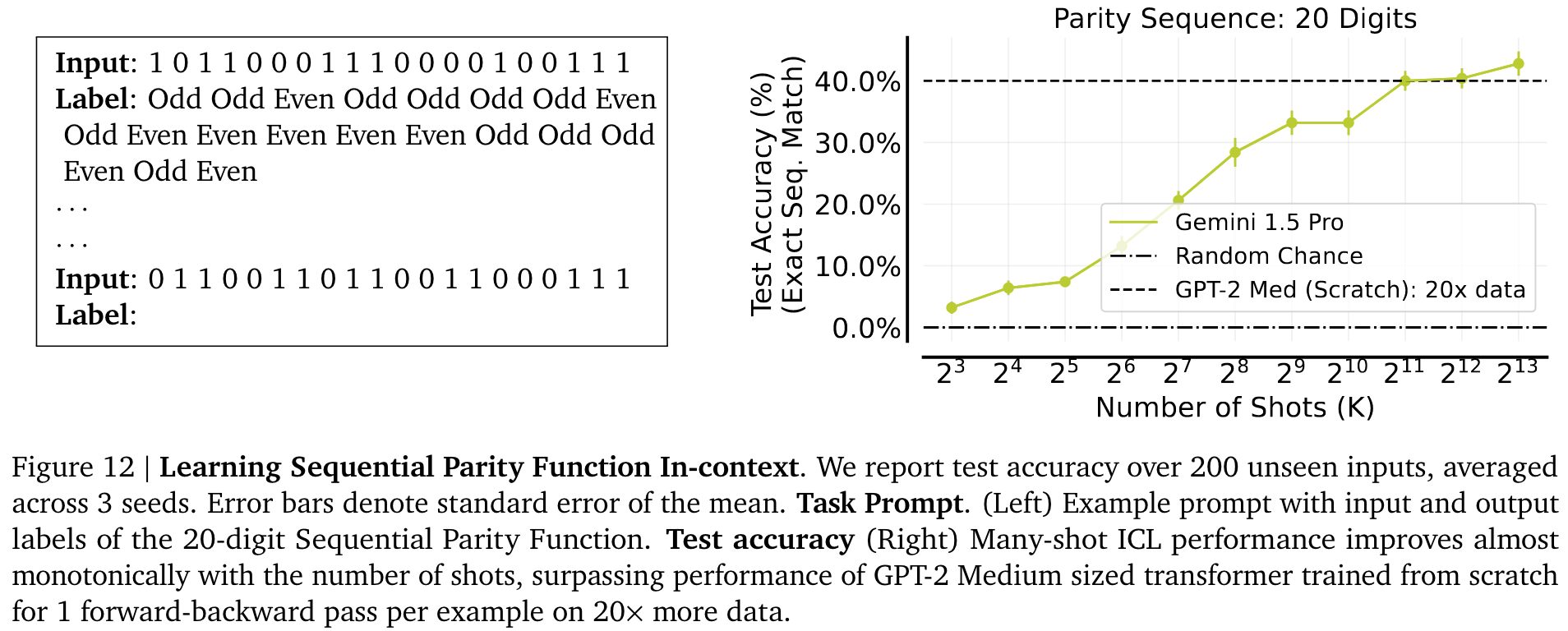
相比之下,多镜头 ICL 不需要任何训练,但推理成本较大,而 KV 缓存可以大幅降低推理成本。
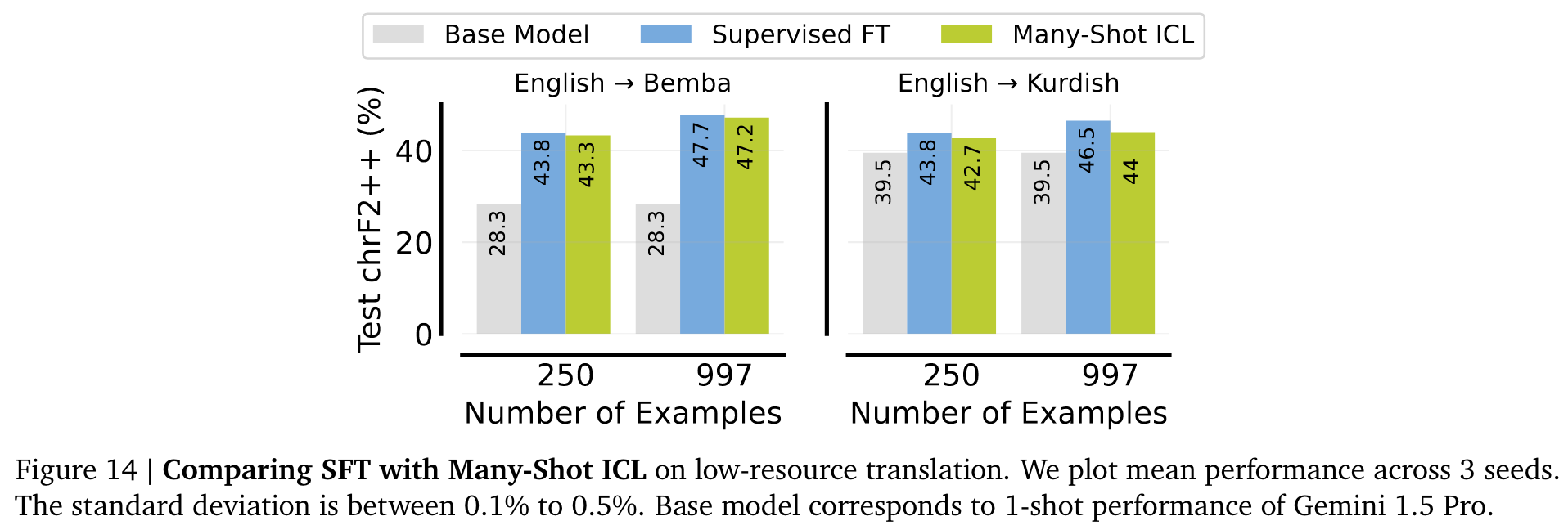
此外,多镜头性能很可能成为评估长语境模型质量的一个有价值的指标,超越了流行的大海捞针测试。
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 扩展的上下文窗口与多示例学习:该论文通过扩展LLM的上下文窗口,首次在自然语言处理中深入研究了多示例情境学习(Many-Shot In-Context Learning,ICL)的性能。传统的少示例ICL仅处理少量输入-输出示例,而多示例ICL则能够处理成百上千个示例,大幅提高了模型在生成任务和判别任务中的表现。
- 克服预训练偏差:论文发现,多示例ICL在任务复杂度增加时,能够显著克服预训练模型的偏差,这是在少示例学习中难以做到的。论文指出,ICL在数学问题解决和推理任务中的表现与模型微调(fine-tuning)相当。
- 模型生成推理链与无监督学习:引入了强化ICL和无监督ICL两种新方式,以应对多示例学习对人类生成数据的高需求。通过使用模型生成的推理链替代人类推理链,论文成功在一些复杂推理任务中取得了显著效果。
-
论文中存在的问题及改进建议:
- 上下文窗口对性能的影响:尽管论文指出了多示例ICL的显著优势,但部分任务在示例数目增加后,性能反而有所下降(例如MATH任务)。这表明仅增加示例数未必总是带来性能提升。改进建议是进一步研究ICL中示例顺序和不同示例组合对性能的影响,优化示例的选择和排序策略。
- 负对数似然与实际性能不一致:论文指出,负对数似然(NLL)并不能很好地预测ICL在复杂问题上的表现。这揭示了当前评估指标的局限性。建议进一步探索更适合评估ICL的指标,例如多样性生成、推理深度等。
- 对模型生成推理链的信任问题:虽然模型生成推理链在强化ICL中取得了较好的表现,但可能出现假阳性问题,即错误的推理链导致正确的最终答案。建议结合更多质量控制机制,例如在推理链生成过程中引入多样性采样或通过其他验证模型进行交叉验证。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 研究点1:多任务多示例ICL的示例排序策略优化:研究示例在多任务环境下的排序与组合如何影响ICL性能。
- 研究点2:跨领域知识迁移下的多示例ICL:探索多示例ICL在跨领域任务中的迁移能力,尤其是在完全未知领域中的表现。
- 研究点3:自适应示例选择与自我监督的结合:开发自适应的示例选择策略,并结合自我监督机制,减少对高质量人类生成数据的依赖。
-
为新的研究路径制定的研究方案:
-
研究点1:多任务多示例ICL的示例排序策略优化
- 研究方法:在多任务(如翻译、推理、分类)环境下,使用强化学习方法训练示例选择器,以确定最优示例排序策略。通过示例的排列组合来评估不同任务下的ICL性能。
- 步骤:
- 收集多任务数据集,确保每个任务有足够的示例。
- 训练一个强化学习代理,针对每个任务学习最优的示例排序。
- 比较不同排序策略对模型在每个任务上的表现。
- 优化示例选择机制,使其适应不同任务需求。
- 期望成果:提高多任务情境下的ICL表现,并且减少示例排序对模型性能的负面影响。
-
研究点2:跨领域知识迁移下的多示例ICL
- 研究方法:设计实验,验证ICL在跨领域任务中的泛化能力,尤其是在预训练数据中没有覆盖的任务上。使用不同领域的数据进行训练,研究模型如何迁移学习。
- 步骤:
- 从不同领域(如医学、法律、工程等)收集任务数据。
- 设计实验,分别在同领域和跨领域设置下进行ICL训练。
- 评估模型在跨领域任务中的迁移性能,并分析影响迁移效果的因素。
- 期望成果:验证多示例ICL在跨领域任务上的迁移能力,提出改进的多示例ICL模型,提升其跨领域泛化能力。
-
研究点3:自适应示例选择与自我监督的结合
- 研究方法:开发一个基于自我监督的示例选择机制,使得模型能够自动筛选出对任务最有帮助的示例,并不断自我改进。结合强化ICL,减少对人类生成数据的依赖。
- 步骤:
- 设计自我监督机制,允许模型生成并验证自身推理链。
- 训练模型学习哪些示例对任务完成最为关键,并动态调整示例选择。
- 在多种任务上测试自适应示例选择的效果,并对比传统的固定示例选择方法。
- 期望成果:减少多示例ICL对人工生成数据的依赖,提高任务推理的质量与效率。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!