目录
Resource Info Paper https://arxiv.org/abs/2109.05687 Code & Data / Public EMNLP Date 2024.12.14
Summary Overview
最近预处理的语言模型从数百万到数十亿个参数延伸。因此,需要在各种下游任务中进行有限的训练语料库微调一个非常大的审计模型。在本文中,我们提出了一种直接而有效的微调技术,即,该技术通过策略性地掩盖了反向传播的过程,从而更新了 PLM 的部分参数(称为child network)通过策略性地掩盖了 non-child network 的梯度。
Main Content
作者提出了一种有效的微调技术,即 ,它可以直接通过在反向传播的过程中策略性的掩盖 non-child network 的梯度更新 child network 的参数。
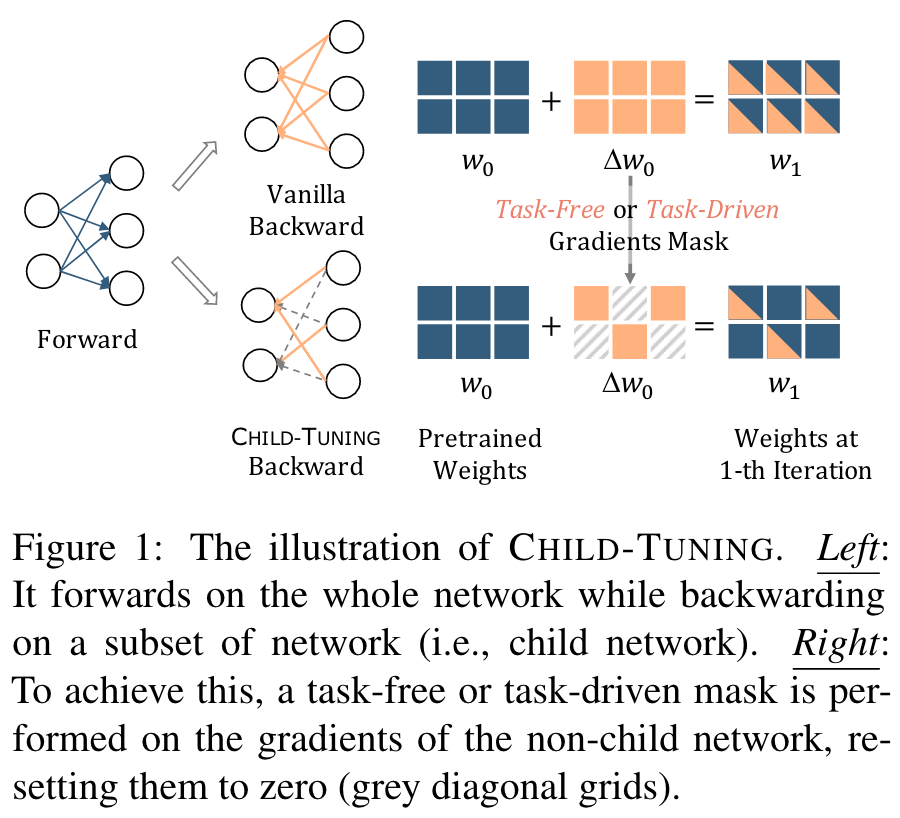
Child-tuning 进一步根据是否与任务有关分为 和 。在没有任务数据的情况下通过Bernoulli分布选择child network,它将噪声引入梯度中,因此防止了模型在小型数据集上的过拟合,具有更好的泛化性。利用下游任务数据来检测与任务相关的参数。
原本的模型参数更新:
Task-Free Variant:
具体而言,在从伯诺利分布中绘制的t-th迭代中生成0-1蒙版,其概率:
越高,子网络越大,因此更新更多的参数。
Task-Driven Variant:
具体而言,我们采用Fisher信息估计,以找到特定下游任务的参数的高度相关子集。 Fisher信息是提供估计随机变量有关分布参数的信息的好方法。
正式地,我们为-th参数提供了Fisher信息,如下所示:
Experiments
Datasets
- GLUE benchmark
- NLI datasets
Results

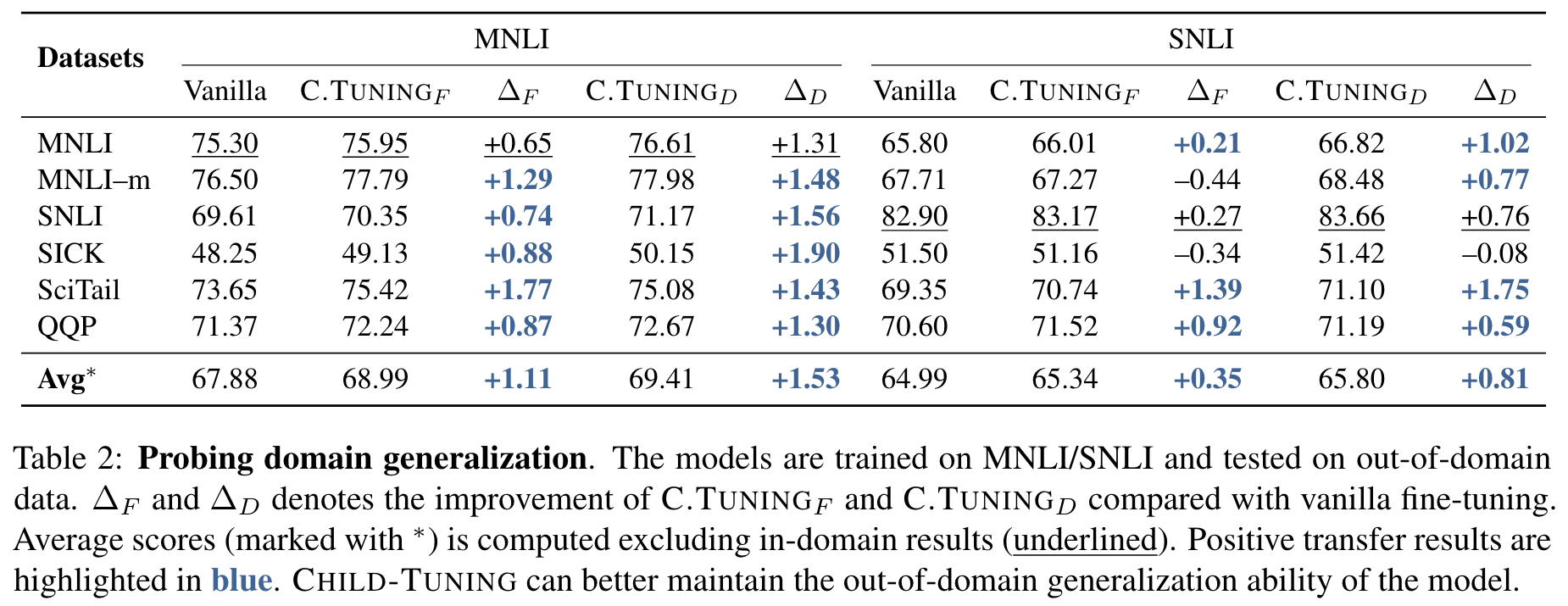
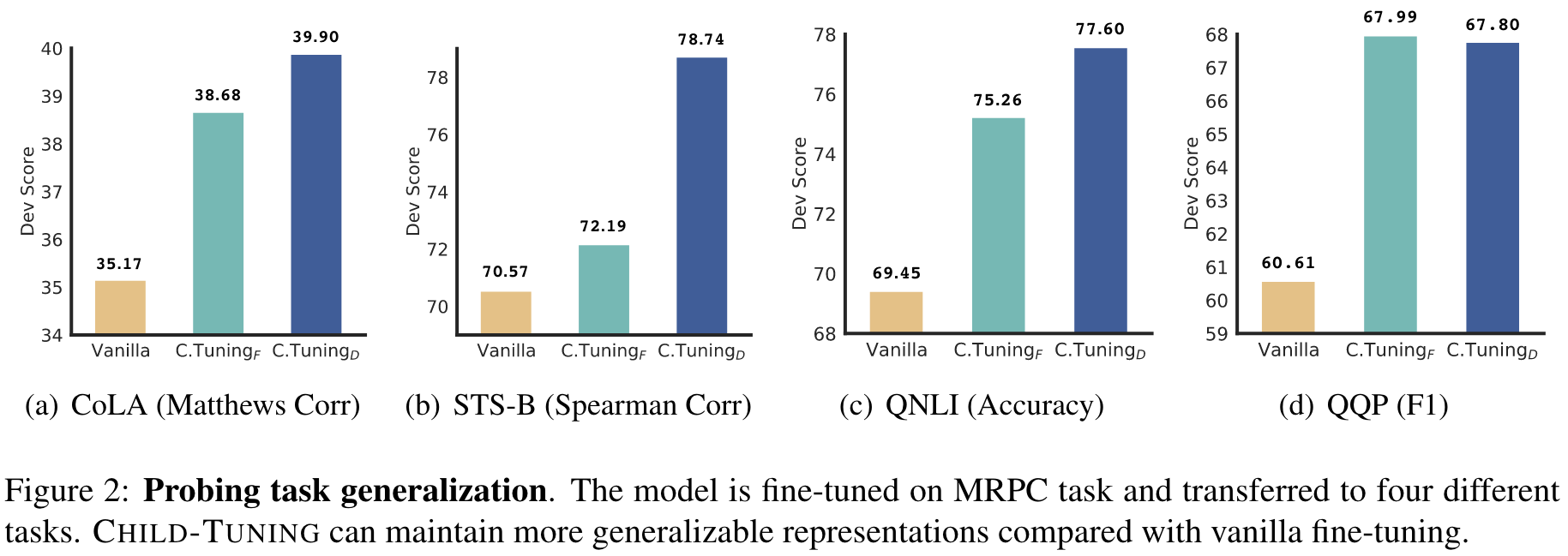
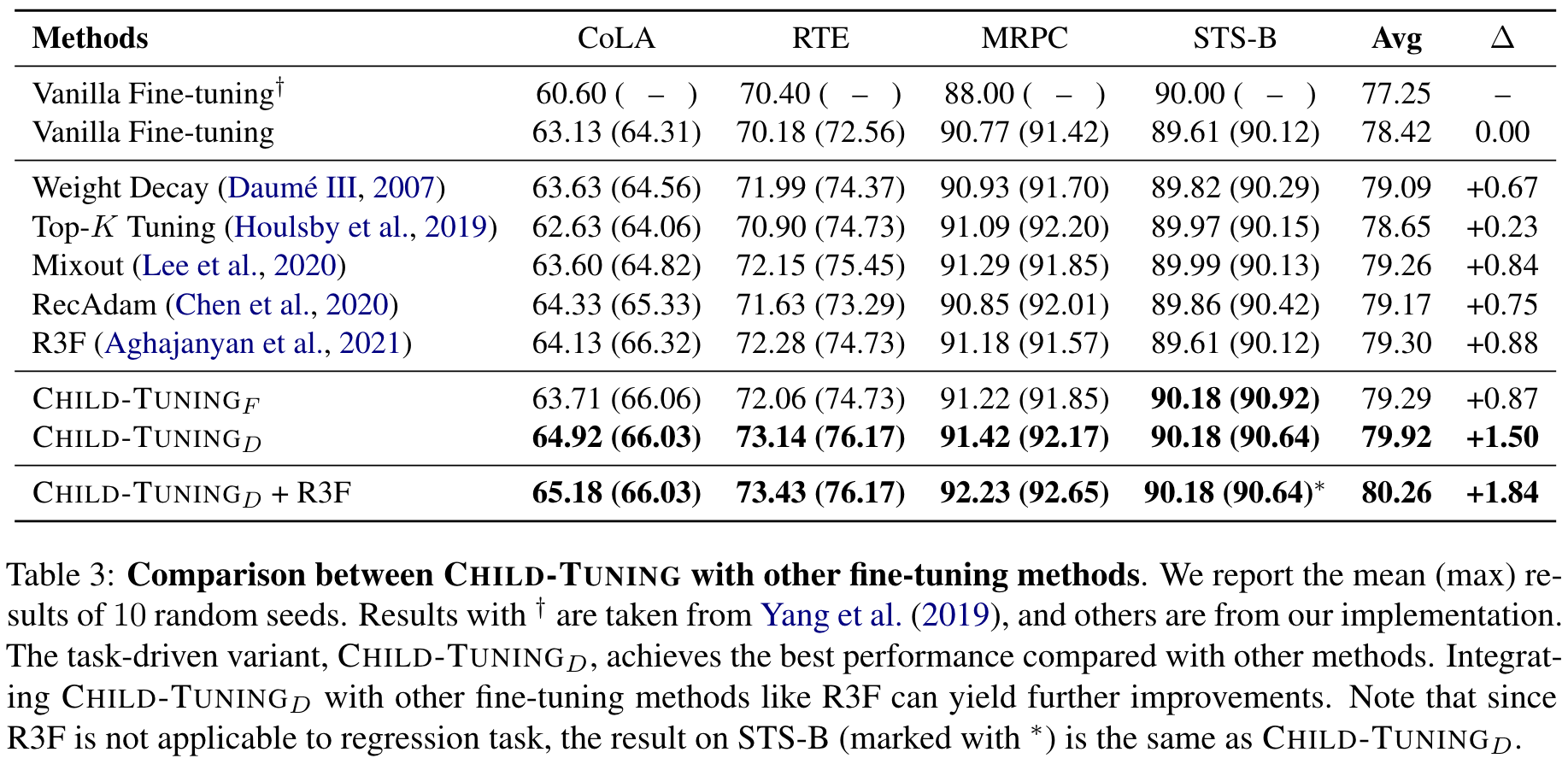
Results in Low-resource Scenarios
由于过度拟合的风险升高,因此在极小的数据集上进行微调的大型模型可能非常具有挑战。因此,在本节中,我们仅通过几个培训示例探讨了的效果。为此,我们将所有数据集都置于GLUE中为1K培训示例,并在其中进行微调。
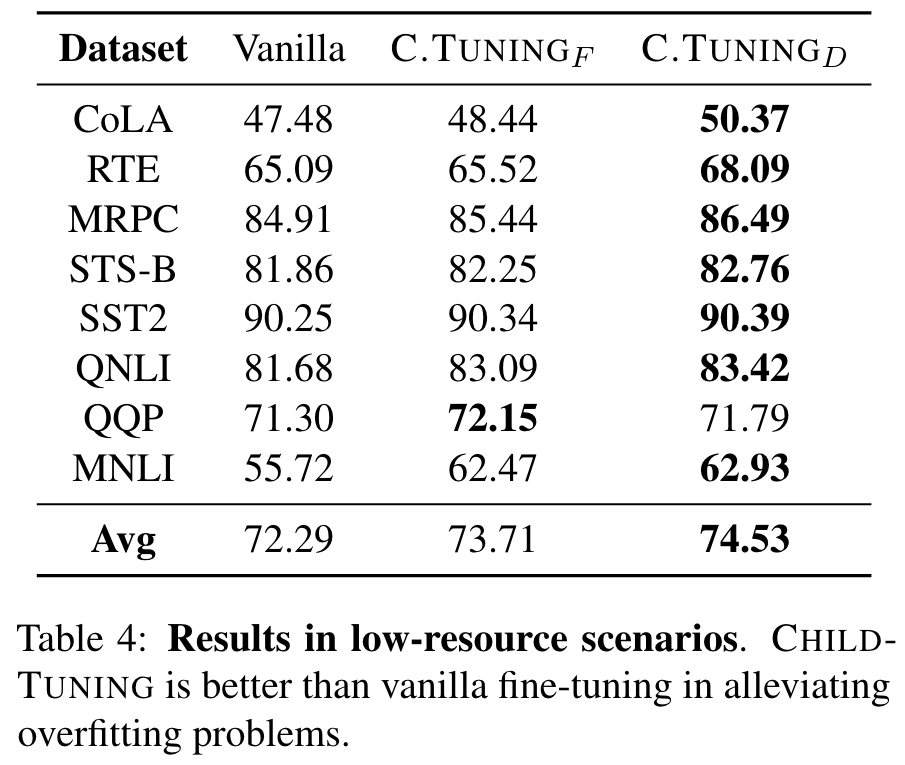
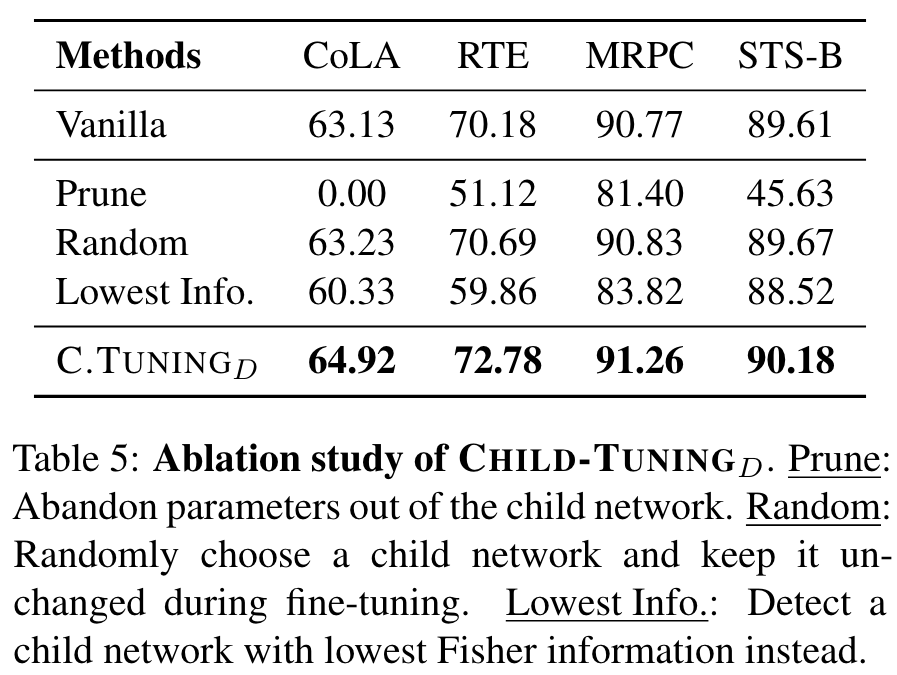
Is the Task-Driven Child Network Really that Important to the Target Task?
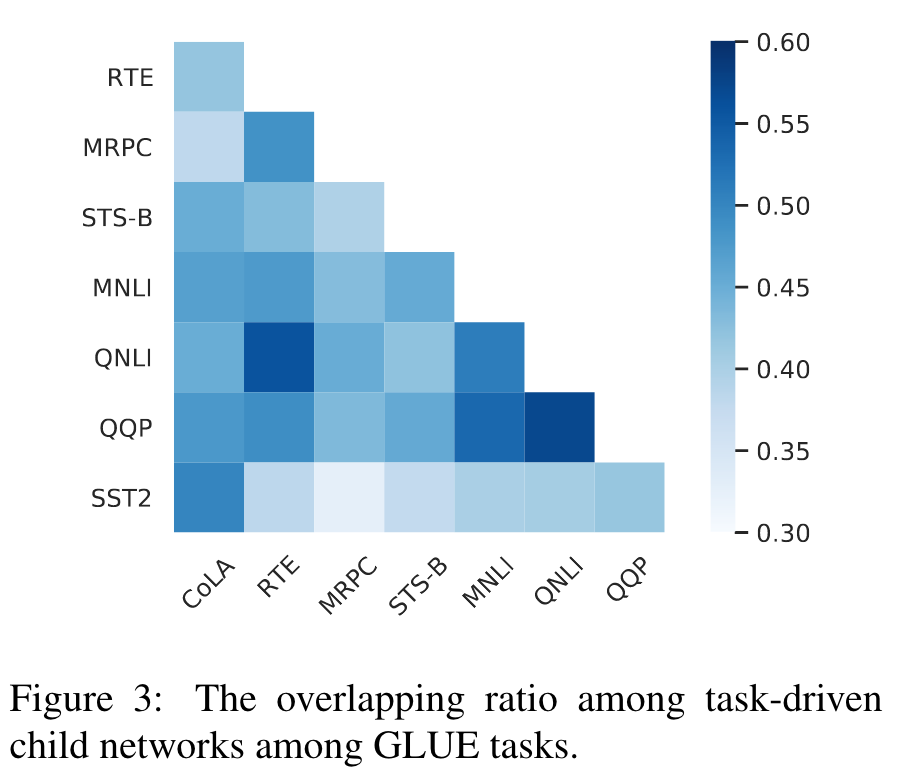
What is the Relationship among Child Networks for Different Tasks?
随着任务驱动的child network与任务相关,我们进一步探讨了child network之间的关系以进行不同的任务。为此,我们可视化不同任务驱动的child network之间的重叠率,在那里我们使用jaccard相似性系数,计算任务和之间的重叠率。
Case Study
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 创新点1:提出CHILD-TUNING方法
论文提出了一种新的微调技术CHILD-TUNING,通过在反向传播过程中对非子网络的梯度进行屏蔽,仅更新子网络的参数。这种方法避免了对整个模型参数的过度调整,同时保留了预训练模型的知识,尤其在小数据集上表现出色。 - 创新点2:任务无关与任务驱动两种子网络选择策略
提出两种子网络选择策略:任务无关的CHILD-TUNINGF(基于伯努利分布随机选择子网络)和任务驱动的CHILD-TUNINGD(基于Fisher信息矩阵选择最相关的子网络)。任务驱动方法更具针对性,能够有效降低模型假设空间。 - 创新点3:广泛的实验验证与性能提升
通过在GLUE基准测试和跨任务迁移实验中验证,CHILD-TUNING在多种预训练语言模型(如BERT、RoBERTa、ELECTRA等)上均表现出显著的性能提升,并在任务泛化和领域迁移上优于其他微调方法。
- 创新点1:提出CHILD-TUNING方法
-
论文中存在的问题及改进建议:
- 问题1:任务驱动子网络选择的计算开销较高
任务驱动的CHILD-TUNINGD需要在微调前计算Fisher信息矩阵,这在大规模预训练模型上可能导致较高的计算成本。- 改进建议:探索更高效的子网络选择方法,例如通过稀疏正则化或梯度重要性评分动态选择子网络。
- 问题2:对不同任务的子网络重叠性缺乏深入分析
论文中虽然讨论了子网络的重叠性,但未进一步分析这种重叠性对模型性能和迁移能力的具体影响。- 改进建议:引入更细粒度的分析,例如子网络在不同任务上的共享参数比例对性能的具体贡献。
- 问题3:对低资源场景的优化仍有改进空间
虽然CHILD-TUNING在低资源场景下表现较好,但其在极端低资源数据下(例如仅百条样本)仍可能面临过拟合。- 改进建议:结合数据增强技术或对抗训练方法,进一步提升CHILD-TUNING在极低资源场景下的鲁棒性。
- 问题1:任务驱动子网络选择的计算开销较高
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:动态子网络选择策略
探索一种动态子网络选择方法,在训练过程中根据梯度变化动态调整子网络,从而平衡模型的适应性与泛化能力。 - 创新点2:跨任务共享子网络的优化
针对不同任务的子网络重叠性,研究如何设计一个共享子网络框架,使得多个任务能够共享部分参数,同时保留任务特定的能力。 - 创新点3:基于CHILD-TUNING的多模态模型微调
将CHILD-TUNING扩展到多模态模型(如视觉-语言模型)中,研究如何在多模态场景下选择子网络以提升微调效率和性能。
- 创新点1:动态子网络选择策略
-
为新的研究路径制定的研究方案:
- 研究路径1:动态子网络选择策略
- 研究方法:基于梯度重要性评分动态调整子网络。在每个训练迭代中,计算各层参数的梯度方差或梯度幅值,选择变化最显著的参数作为子网络的一部分。
- 研究步骤:
- 初始化模型参数,随机选择初始子网络。
- 在每个训练迭代中,计算梯度变化并更新子网络。
- 比较动态子网络选择与固定子网络选择的性能差异。
- 期望成果:验证动态子网络选择策略在不同任务上的性能提升,尤其是在数据稀缺场景中的优势。
- 研究路径2:跨任务共享子网络的优化
- 研究方法:设计一个多任务共享框架,利用共享子网络处理不同任务,同时通过任务特定模块捕获任务独有特性。
- 研究步骤:
- 构建一个多任务学习框架,定义共享子网络和任务特定子网络。
- 使用CHILD-TUNING的任务驱动方法选择共享子网络。
- 在GLUE基准测试和跨任务迁移任务上验证框架性能。
- 期望成果:证明共享子网络能够提升多任务学习的效率和性能,同时减少模型参数量。
- 研究路径3:基于CHILD-TUNING的多模态模型微调
- 研究方法:将CHILD-TUNING方法扩展到多模态模型(如CLIP、BLIP等),研究如何在视觉和语言特征之间选择子网络。
- 研究步骤:
- 对多模态模型的视觉和语言模块分别应用CHILD-TUNING,探索任务驱动的子网络选择。
- 比较多模态模型在单模态任务和多模态任务上的性能。
- 研究子网络选择对多模态对齐和表示学习的影响。
- 期望成果:验证CHILD-TUNING在多模态场景中的有效性,提出一种高效的多模态微调方法。
- 研究路径1:动态子网络选择策略
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!