目录
Resource Info Paper https://arxiv.org/abs/2406.18181 Code & Data / Public ASE Date 2024.12.13
Summary Overview
在这篇文章中,作者根据17个 Java 项目,使用了5个开源不同结构和参数规模的 LLM,对于单元测试 (UT) 的能力的探究,进行了全面的评估。是一篇 empirical study。
Main Content
单元测试的重点是验证每个单独的程序组件(例如每种方法)的功能,以确保其按预期工作。
Challenges:
- Generating syntactically correct tests. 单元测试生成可以作为代码生成的子问题。因此也会有生成的代码需要符合语言语法规则的问题。
- Generating effective tests. 高质量的单元测试应该彻底探讨目标程序组件的行为。该方法需要了解代码的意图和结构的方法,从而生成具有高测试覆盖范围的缺陷检测能力的测试。
- Generating maintainable tests. 在软件领域,人们更加喜欢易于阅读和更改的单元测试,这需要在之后的测试中充分体现。
在这项工作中,我们进行了首次广泛的研究,以实现上述目标,该目标基于缺陷4J 2.0基准的17个Java项目。
Findings:
- Prompt 设计(描述样式和所选代码功能)对于LLM在单元测试生成中的有效性至关重要。建议考虑LLMS的代码理解能力和生成单元测试的剩余空间,建议将描述样式与培训数据保持一致,并选择代码功能。值得注意的是,包括目标类别中定义的其他方法(焦点方法除外)会对基于LLM的单位测试生成的总体有效性产生负面影响。
- 从开源LLM中得出的结论在其他任务中不一定会推广到单位测试生成,包括研究的LLMS之间的优势关系。但是,所有研究的LLM,包括最先进的GPT-4,都在测试覆盖范围内表现不佳。这主要是由于LLMS幻觉的结果是LLMS产生的大量句法无效的单元测试。因此,需要有效的解决方案,例如,设计后处理规则来解决常见的句法问题。
- 尽管它们在其他任务中有效,但直接适应单位测试生成的思想链(COT)和检索增强产生(RAG)方法并不能提高效力,甚至可能在某些情况下可以降低其效率。 COT主要受LLMS的代码理解能力的限制,而RAG受到检索到的单位测试之间的显着差距和LLMS在生成时出色的差距。需要在单位测试生成中使用ICL方法的特殊设计。
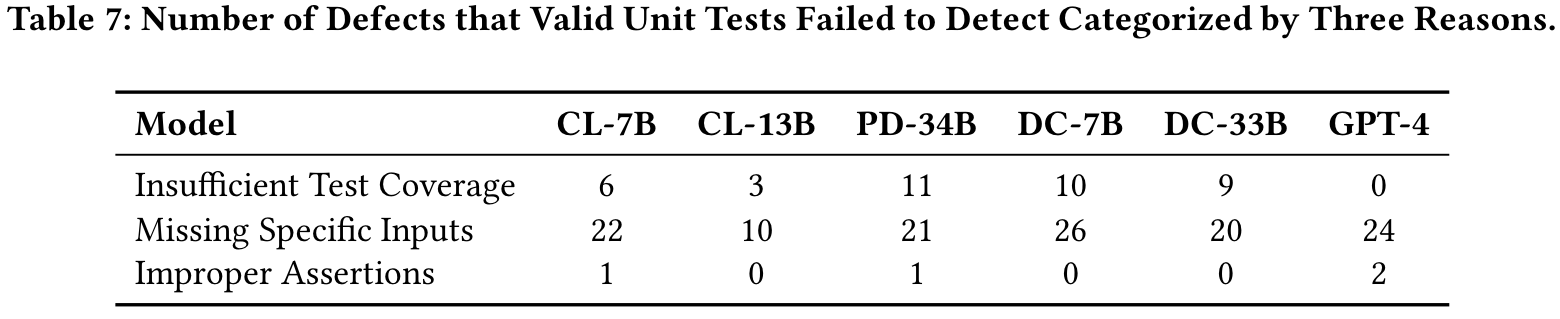
- LLM生成的单位测试的缺陷检测能力受到限制,这主要是由于其有效性低。尽管有效的单位测试是由LLMS生成许多缺陷的,但仍未发现大量缺陷,主要是因为测试未能产生触发这些缺陷所需的特定输入。因此,为生成的单位测试中的输入设计有效的突变策略可以进一步提高缺陷检测效率。
Contributions:
- 我们进行了第一项经验研究,以评估单位测试生成中的开源LLM。我们从众所周知的缺陷4J基准中研究了17个Java项目,研究了五个强大的代码LLM,范围从7B到34B参数。我们的实验需要大约3,000个NVIDIA A100 GPU小时,这突显了我们研究的规模和强度,以推动基于LLMB的单元测试生成。
- 我们从我们的研究问题定义的四个方面评估了基于LLM的单位测试生成,包括及时设计的影响,ICL方法的影响,开源LLMS之间的比较,商业GPT4和传统的EvoSuite以及在各种指标的条款(包括句法有效性,测试覆盖范围和缺陷检测)。
- 我们从我们的广泛研究中总结了9个主要发现,并为指导基于LLM的单位测试生成的未来研究和实践的使用带来了一系列含义。
Research Questions:
- How does prompt design affect the effectiveness of LLMs in unit test generation?
- How do open-source LLMs perform in unit test generation compared to GPT-4 and Evosuite?
- How do in-context learning methods affect the effectiveness of LLM-based unit test generation?
- How effective are the unit tests generated by LLMs in terms of defect detection?
Prompt Design:
- Description Style:
- natural language description
- code language description
- Code Features:
- Focal Method is the target method to be tested. The code features extracted from it include the method body () and its parameters ().
- Focal Class is the class containing the focal method. The code features extracted from it include its constructor (), the fields defined within the class (), and other methods defined within the class ().
- Related Classes are the classes including the constructors of the parameters in the focal method (except the focal class). The code feature extracted from it is these constructors (). Among them, is the basic content in the prompt for LLM-based unit test generation.
Implications:
- Tuning prompt design (including both description styles and code features) for a given LLM is important.
- Removing useless information from code features helps balance prompt content and space for generating unit tests.
- Emperically selecting a proper LLM is necessary, instead of relying on the best LLM according to experience in other tasks.
- Refining the use of ICL methods specific to unit test generation is essential.
- Designing post-processing strategies to fix invalid unit test can help mitigate the influence of LLM's halolucination.
- Desiging mutation strategies for the inputs specified in LLM-generated unit tests is helpful in improving defect detection ability.
- Supervised fine-tuning (SFT) of open-source LLMs by incorporating unit test generation data may fundamentally improve effectiveness.
Related Work
Empirical Study on evaluating LLMs in Code-Related Tasks:
随着LLM的快速发展,有多项研究研究了LLM在与代码相关的任务中的有效性[12,17,22,26,45,46,46,50,52-55,60,60,70,76,85]。特别是,有一些关于基于LLM的单位测试生成的经验研究[14、65、68、88、92]。例如,Yuan等人。 [92]根据单位测试生成中生成的单元测试的正确性,足够性,可读性和可用性,研究了CHATGPT的有效性。 Siddiq等。 [68]研究了GPT-3.5和Codex在单位测试生成中的有效性。 Schafer等。 [65]调查了GPT-3.5在生成JavaScript语言的单元测试中的有效性。但是,这些现有研究主要依赖于基于封闭源LLM的固定提示策略,忽略了先进的开源LLMS的功能和各种提示因素(例如及时设计和ICL方法)。在我们的研究中,我们专注于开源LLM,并广泛考虑了这些因素,并进行了首次研究以证明其有效性。我们的发现为基于LLM的单位测试生成提供了一系列可行的建议。此外,还有一些关于评估LLM的经验研究,以解决其他与代码相关的任务。例如,杜等人。 [17]进行了实验,以研究LLM在类级代码生成中的有效性。 Nam等。 [54]比较了使用LLMS时的代码理解能力来帮助开发人员了解该项目。 Sun等。 [70]进行了实验,以研究CHATGPT在代码摘要中的有效性。 Facundo等。 [53]总结了三种类型的甲壳和威胁,这是由使用LLMS自动生成甲壳引起的。研究人员[31,85]对LLM进行了实验,以研究其在自动化程序维修中的有效性。 Niu等。 [55]对六个与代码相关的任务中预培训模型的有效性进行了全面调查。与它们不同,我们的工作针对单元测试生成的任务。
Experiments
Metrics
- Compilation Success Rate (CSR)
- Line Coverage ()
- Branch Coverage ()
- the Number of Detected Defects (NDD)
Results
Influence of Prompt Design
Influence of Description Style.
为了评估NL和CL之间的差异,我们进行了Wilcoxon秩和测试,其显着性水平为0.05,并计算了等级 - 生物相关性得分以显示效果大小。效应大小高于0.3通常表明比较组之间有意义的差异。

Influence of Code Features
具体来说,我们为提示设计创建了五个变体,每个变体分别从提示中删除了所有研究的代码功能的代码功能。表2显示了CSR的结果,表3显示了COVL和COVB方面的结果。
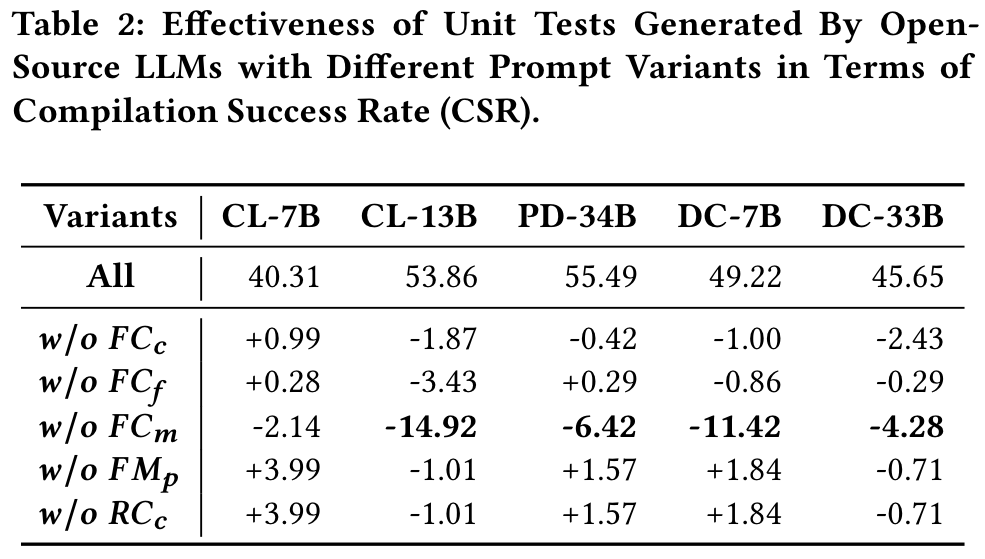
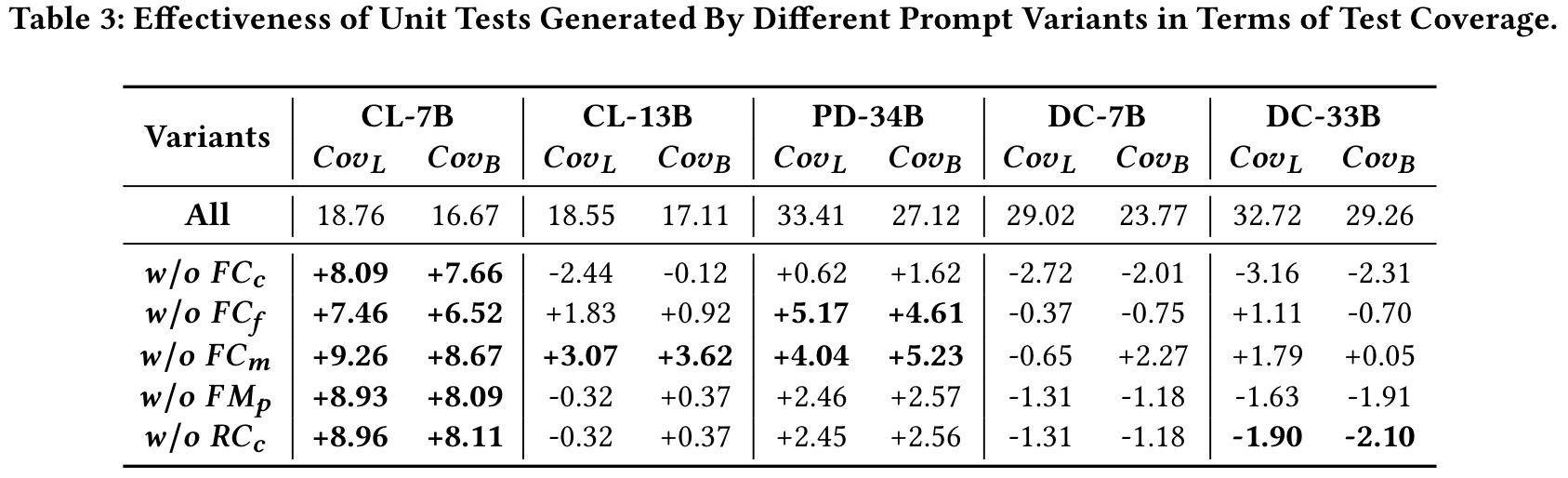
从表3中,我们发现了一个令人惊讶的现象,即,即使具有统计学意义,几乎所有“ W/O FCM”的情况都会增加。这表明在及时设计中删除FCM有助于提高代码覆盖范围,即使这对生成的单元测试的句法有效性有害。
Effectiveness Comparsion
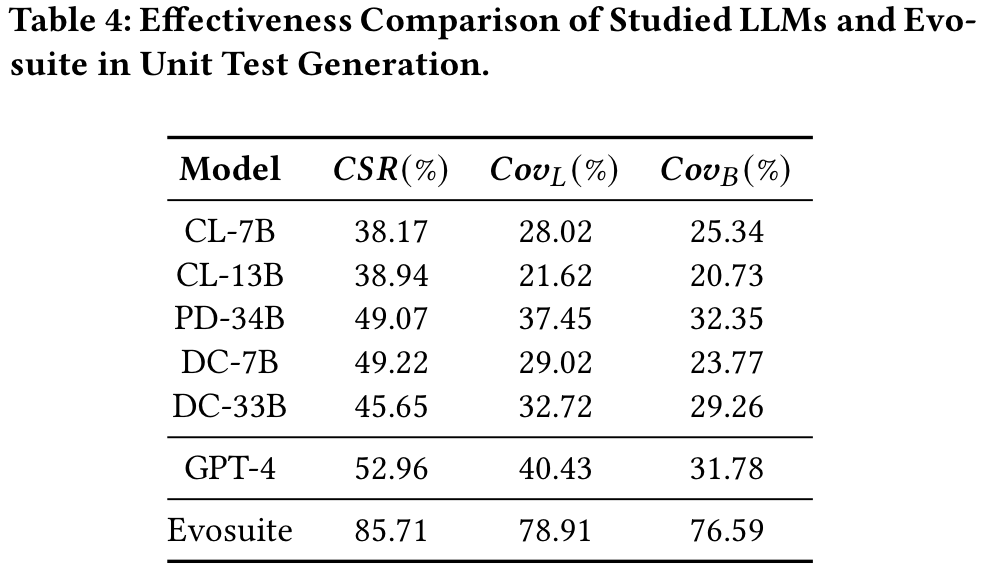
一个可能的原因是,LLMS生成的大量单位测试(范围从34.44%到61.78%)在语法上无效。
Effectiveness of In-Context Learning

Defect Detection Ability
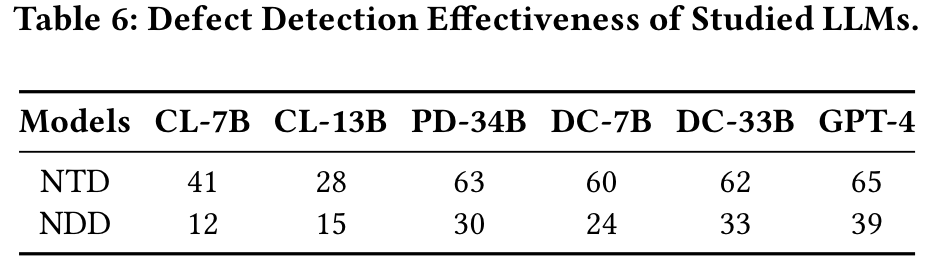
我们进一步研究了每种基于LLM的单位测试生成技术在缺陷检测方面的有效性,通过在相应的故障版本上执行其生成的单位测试。
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 首次系统评估开放源码LLM在单元测试生成中的效果:论文填补了现有研究的空白,集中研究了五种开放源码大型语言模型(LLMs)在单元测试生成任务中的表现,并与传统工具(如Evosuite)和商业化模型(如GPT-4)进行了对比。这种全面的实验设计(基于Defects4J基准和多种评估指标)具有很高的学术价值。
- 深入探讨提示设计对LLM性能的影响:论文通过实验分析了描述风格(自然语言 vs. 代码语言)和代码特性(如目标方法、类构造器等)对单元测试生成效果的影响,提出了优化提示设计的重要性。
- 首次探讨上下文学习方法(ICL)在单元测试生成中的适配性:论文评估了链式思维(CoT)和检索增强生成(RAG)方法在此任务中的作用,发现现有方法需要针对单元测试生成任务进行特殊设计。
- 揭示LLM生成单元测试的局限性:论文指出了LLM生成的单元测试在语法正确性、测试覆盖率和缺陷检测能力上的不足,分析了主要原因(如幻觉问题和缺乏特定输入)。
-
论文中存在的问题及改进建议:
- 对提示优化的探索不够全面:论文仅进行了逐一去除代码特性的消融实验,而未考虑代码特性组合的可能性,可能遗漏了更优的提示设计方法。
- 改进建议:设计全面的实验,探索代码特性组合的影响,或利用自动化搜索算法(如遗传算法)优化提示设计。
- 上下文学习方法的适配性研究较为局限:论文仅适配了CoT和RAG两种方法,未探索其他可能的上下文学习方法(如自修复、自一致性等)。
- 改进建议:引入更多上下文学习方法,尤其是结合单元测试生成任务特点开发新的适配策略。
- 未充分考虑生成后处理策略的潜力:论文虽提到生成后处理可以缓解语法错误,但未深入研究具体的后处理方法。
- 改进建议:开发自动化的后处理工具(如基于静态分析的错误修复),并评估其有效性。
- 实验范围有限:论文仅使用了Defects4J基准数据集,可能导致结论的普适性受到限制。
- 改进建议:扩展实验范围,使用其他基准数据集(如GitBug-Java)验证结论。
- 对提示优化的探索不够全面:论文仅进行了逐一去除代码特性的消融实验,而未考虑代码特性组合的可能性,可能遗漏了更优的提示设计方法。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:基于动态提示优化的单元测试生成
动态调整提示内容,根据生成结果的质量实时优化提示,提升LLM生成单元测试的有效性。 - 创新点2:结合生成后处理与上下文学习的增强策略
将上下文学习方法与自动化生成后处理结合,开发端到端的单元测试生成框架。 - 创新点3:专用单元测试生成语料库的构建与微调
构建专门针对单元测试生成的高质量数据集,结合监督微调(SFT)优化开放源码LLM的性能。
- 创新点1:基于动态提示优化的单元测试生成
-
为新的研究路径制定的研究方案:
-
研究路径1:基于动态提示优化的单元测试生成
- 研究方法:
- 设计动态提示优化框架,实时分析LLM生成的单元测试质量(如语法正确性、覆盖率等)。
- 根据分析结果动态调整提示内容,例如添加缺失的代码特性或修改描述风格。
- 评估动态提示优化对生成效果的提升。
- 步骤:
- 选取开放源码LLM(如CodeLlama)和Defects4J数据集作为实验基础。
- 开发提示优化模块,结合静态分析工具自动检测生成结果中的缺陷。
- 对比动态优化前后生成的单元测试在语法正确性、覆盖率和缺陷检测能力上的差异。
- 期望成果:
- 提供一种动态提示优化方法,显著提升LLM生成单元测试的质量。
- 发布开源工具和实验数据,为后续研究提供参考。
- 研究方法:
-
研究路径2:结合生成后处理与上下文学习的增强策略
- 研究方法:
- 开发自动化生成后处理模块,修复常见语法错误(如未解析符号、参数不匹配等)。
- 探索其他上下文学习方法(如自修复、自一致性),并与生成后处理模块结合。
- 评估增强策略对生成质量和缺陷检测能力的影响。
- 步骤:
- 基于现有研究开发后处理规则,结合静态分析工具实现自动修复。
- 适配新型上下文学习方法,优化提示内容或生成过程。
- 在多个数据集上评估增强策略的效果,验证其通用性。
- 期望成果:
- 提供一个结合上下文学习与生成后处理的综合框架。
- 显著提高LLM生成单元测试的有效性和可靠性。
- 研究方法:
-
研究路径3:专用单元测试生成语料库的构建与微调
- 研究方法:
- 收集和标注高质量单元测试数据,构建专用语料库。
- 对开放源码LLM进行监督微调,优化其在单元测试生成任务上的性能。
- 将微调后的模型与现有模型进行对比,验证其有效性。
- 步骤:
- 从开源项目中提取单元测试代码,结合专家标注构建语料库。
- 使用微调技术(如LoRA或全量微调)训练开放源码LLM。
- 在Defects4J和其他基准数据集上评估微调模型的生成效果。
- 期望成果:
- 构建一个公开可用的单元测试生成语料库。
- 提供经过微调的开放源码LLM,显著提升单元测试生成的质量。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!