目录
Resource Info Paper http://arxiv.org/abs/2501.12948 Code & Data / Public arXiv Date 2025.02.28
Summary Overview
本文介绍了 DeepSeek-R1,DeepSeek-R1-Zero 模型。其中 DeepSeek-R1-Zero 是直接使用的 RL 没有经过 SFT 阶段。DeepSeek-R1-Zero是一种通过大规模增强学习(RL)训练的模型,而无需监督微调(SFT)作为初步的步骤,表现出了显着的推理能力。
Main Content
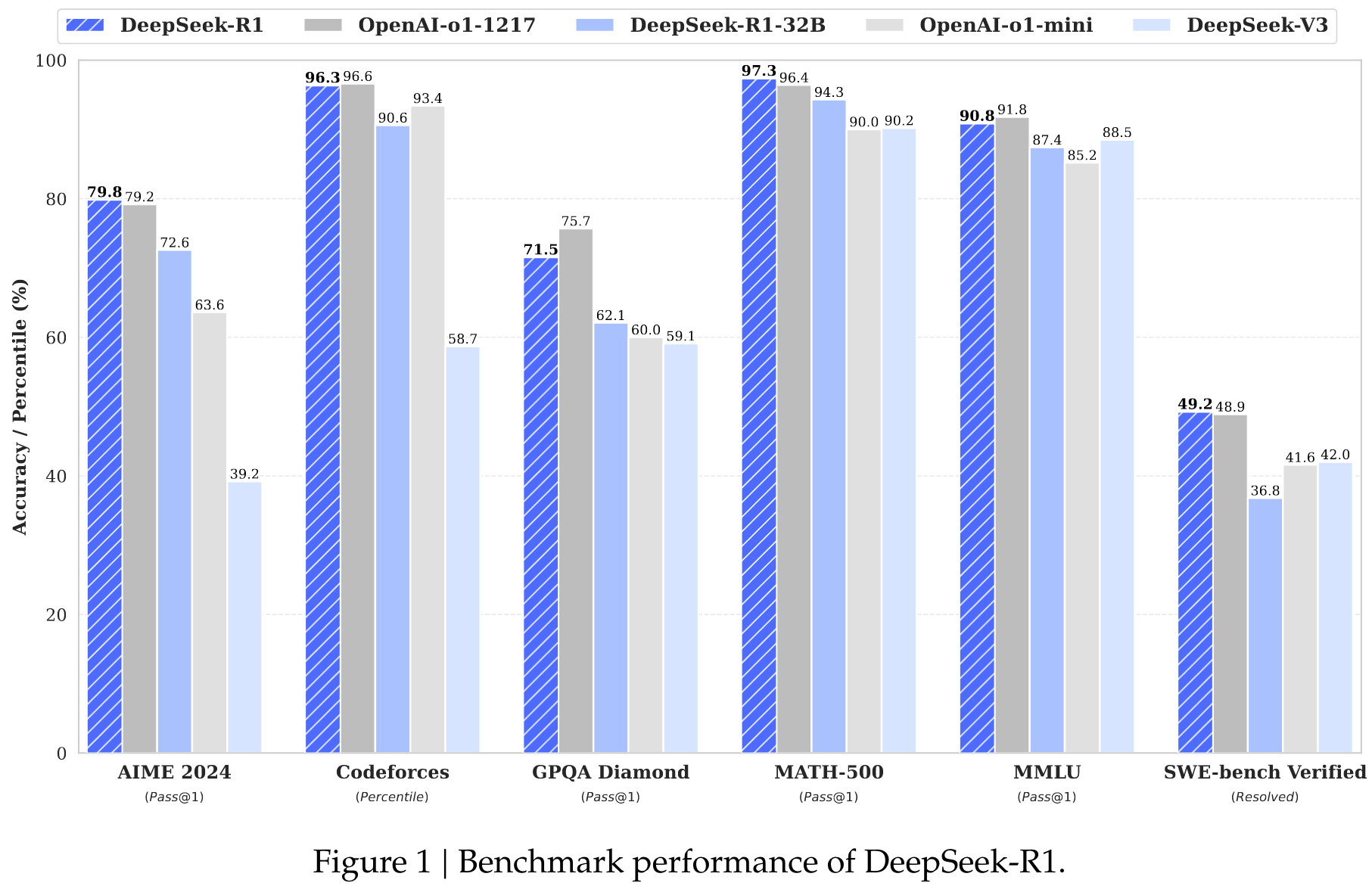
OpenAI的O1(OpenAI,2024b)系列模型是第一个通过增加思考推理过程的长度来引入推理时间缩放的模型。我们的目标是探索LLMS在没有任何监督数据的情况下开发推理能力的潜力,并通过纯RL过程着重于他们的自我进化。这表明,较大的基本模型发现的推理模式对于提高推理能力至关重要。
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
在本节中,我们探讨了LLM在没有任何监督数据的情况下发展推理能力的潜力,并通过纯粹的强化学习过程着重于他们的自我进化。
我们采用 Group Relative Policy Optimization (GRPO)
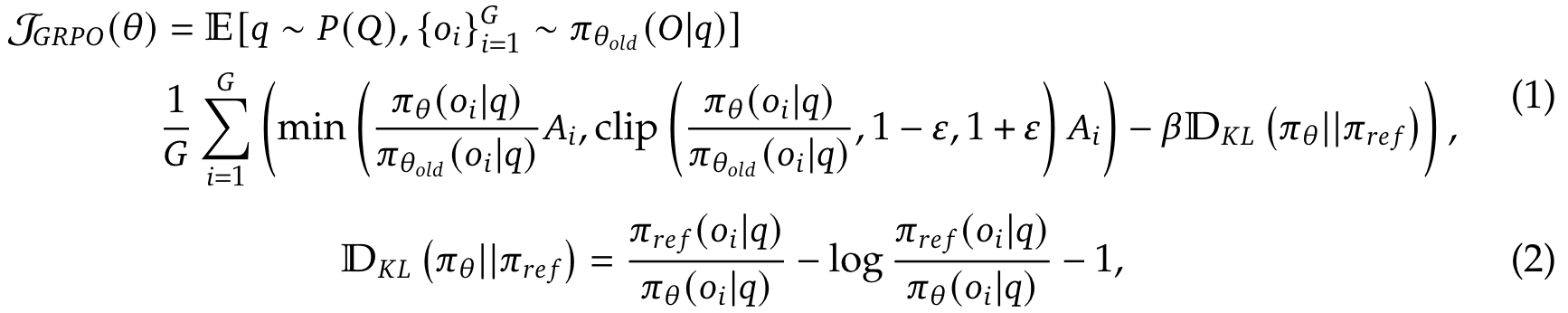
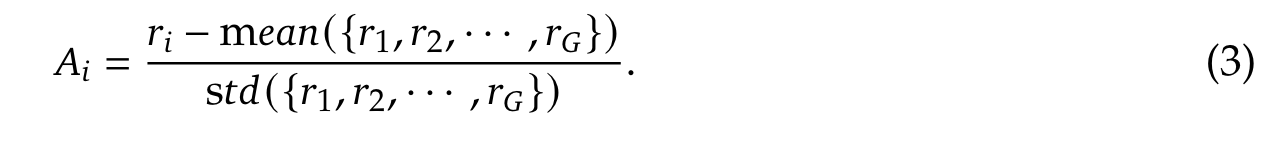
Two types of rewards:
- Accuracy rewards: The accuracy reward model evaluates whether the response is correct. For example, in the case of math problems with deterministic results, the model is required to provide the final answer in a specified format (e.g., within a box) enabling reliable rule-based verification of correctness. Similarity, for LeetCode problems, a complier can be used to generate feedback based on predefined test cases.
- Format rewards: In addition to the accuracy reward model, we employ a format reward model that enforces the model to put its thinking process between
<think>and</think>tags.

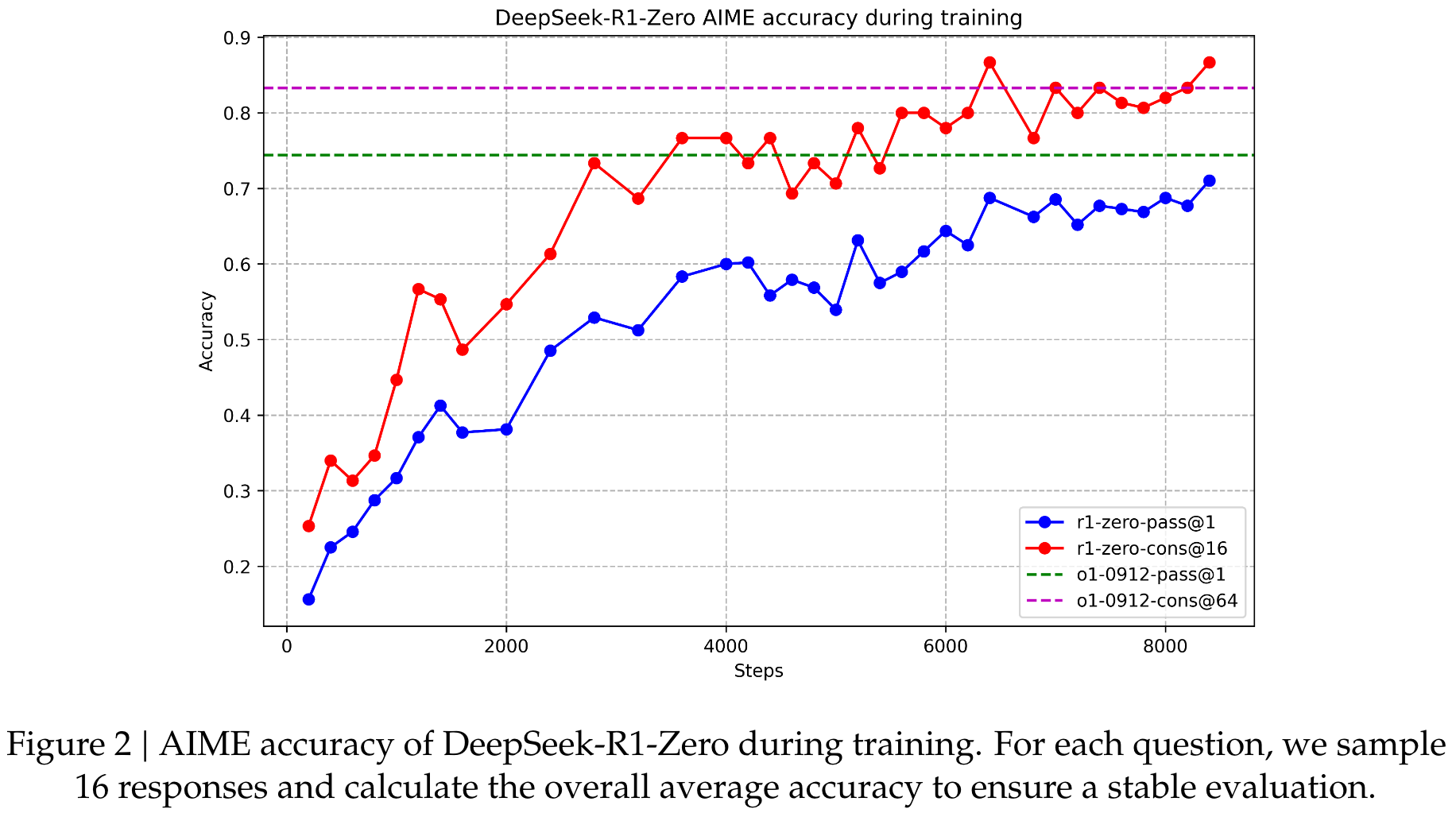
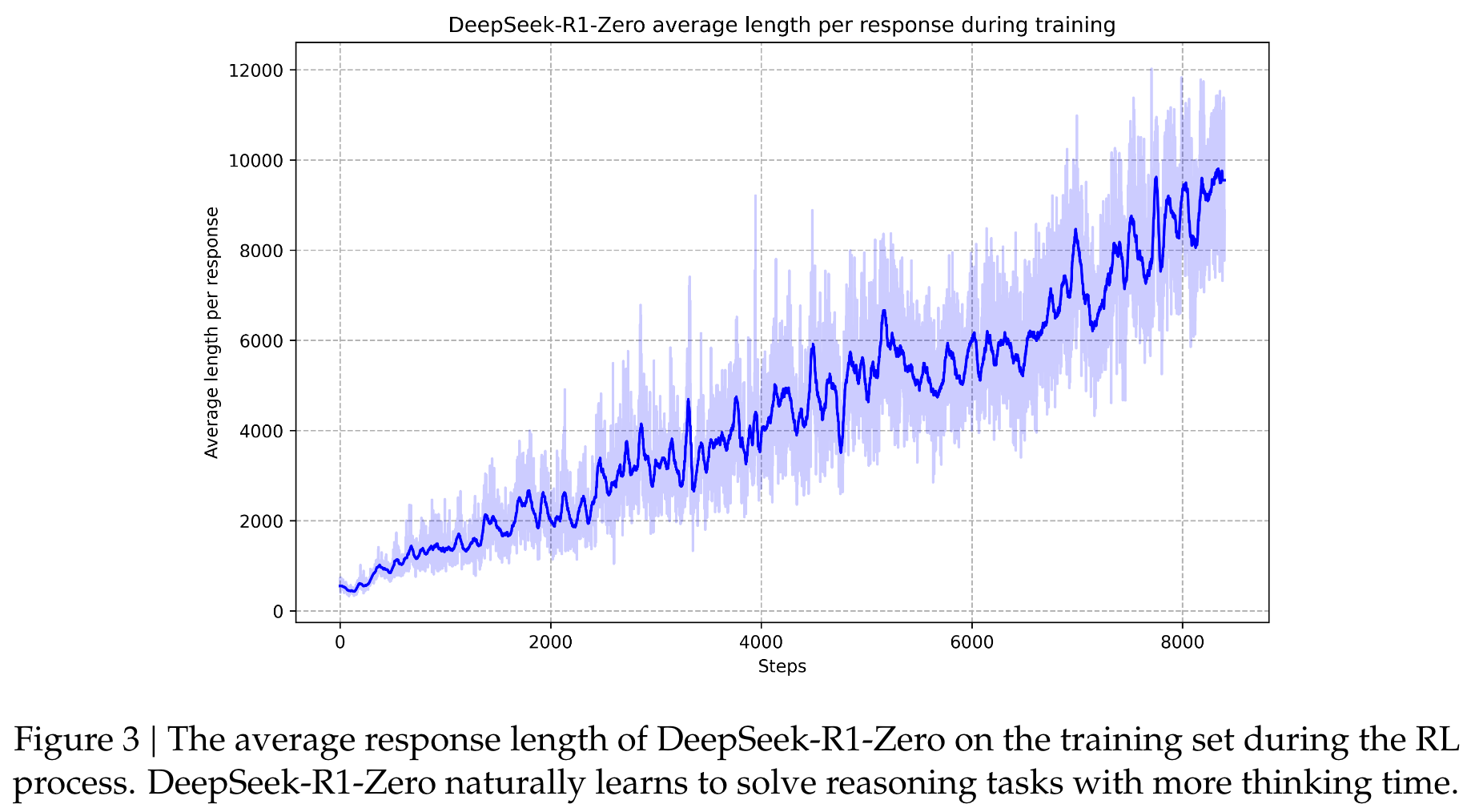
Aha Moment of DeepSeek-R1-Zero
它强调了增强学习的力量和美观:我们没有明确教授有关如何解决问题的模型,而只是为其提供了正确的激励措施,并且自主会自主制定高级问题解决策略。 “ AHA时刻”有力地提醒了RL在人工系统中解锁新智能水平的潜力,为将来的更自主和自适应模型铺平了道路。

Evaluation
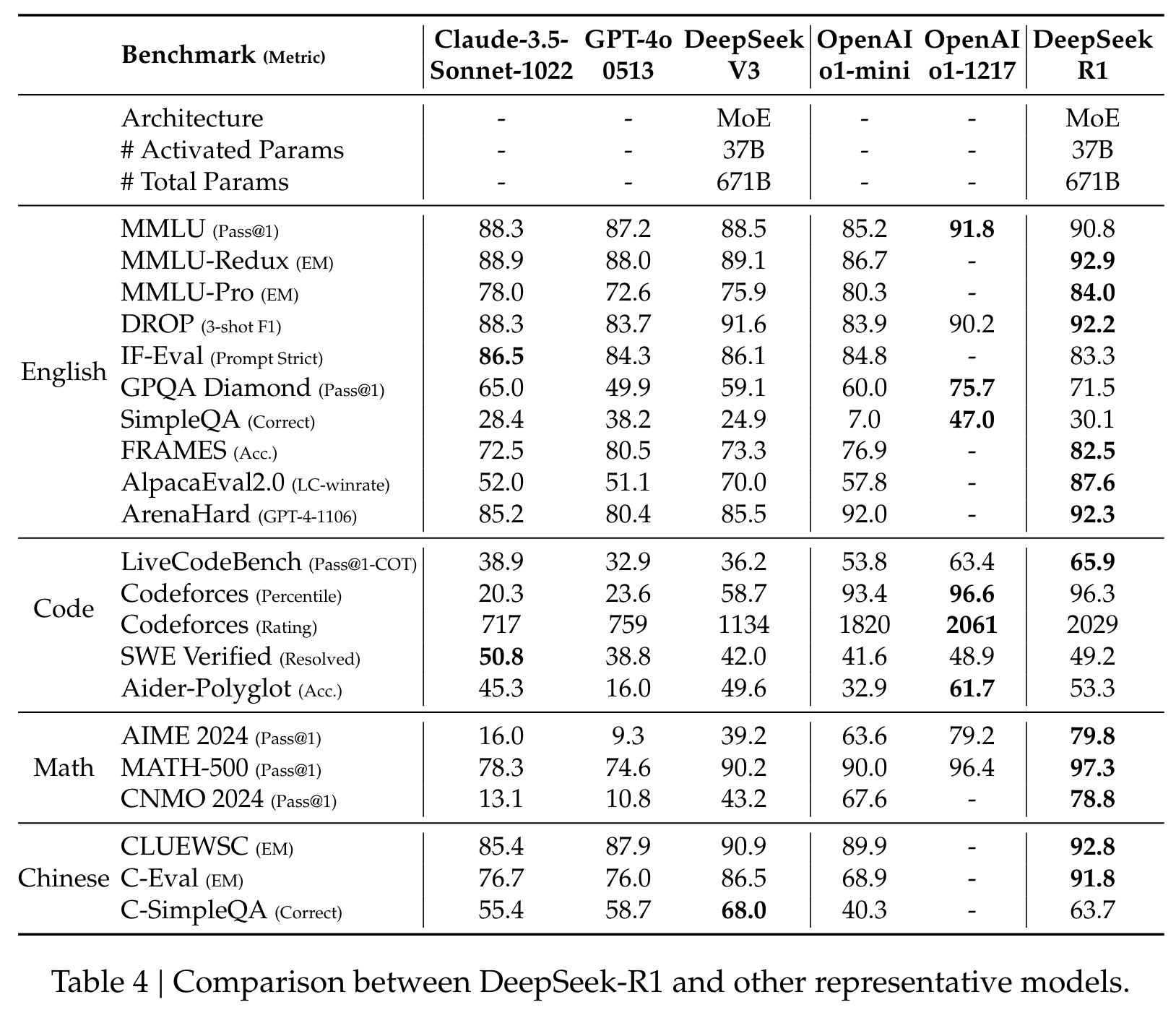
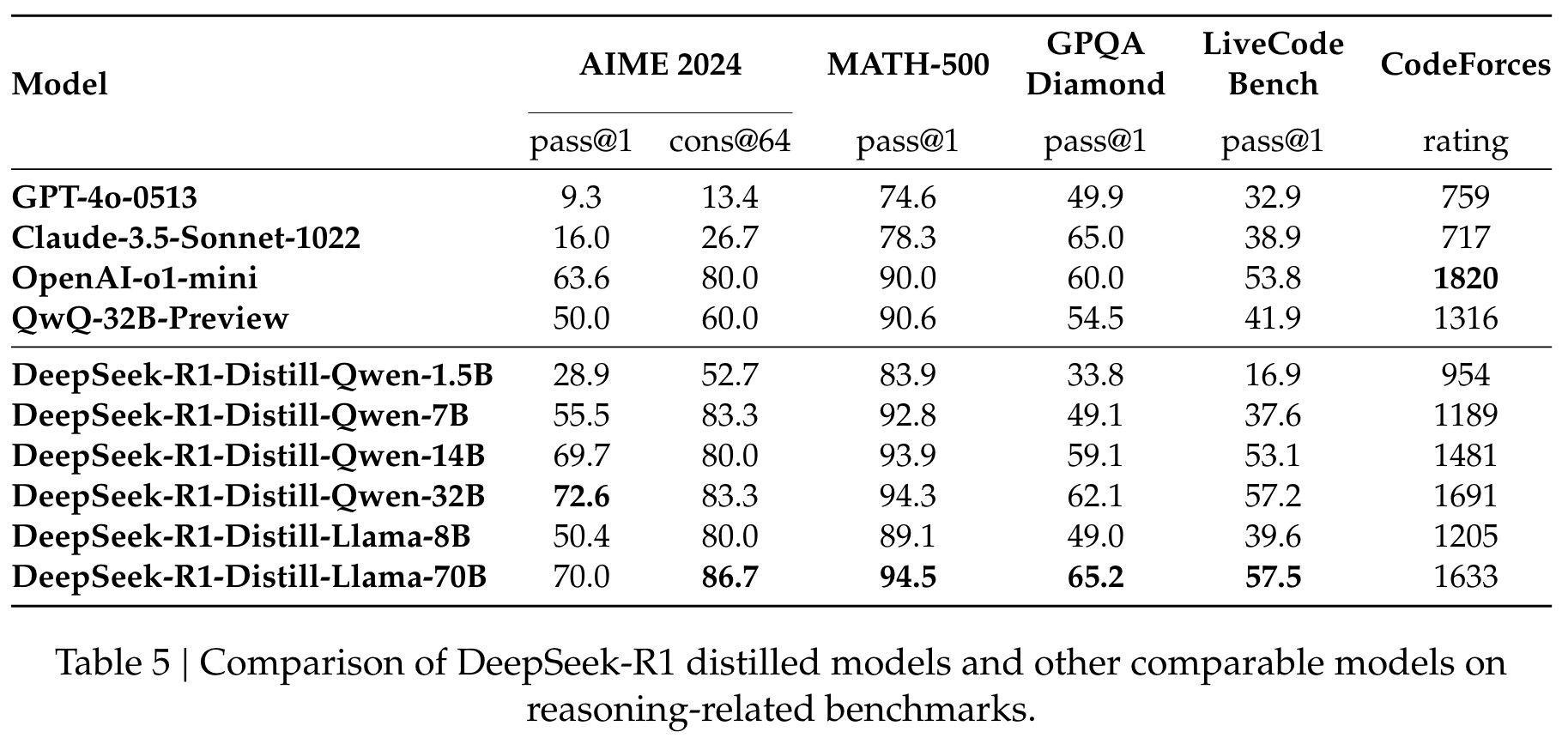
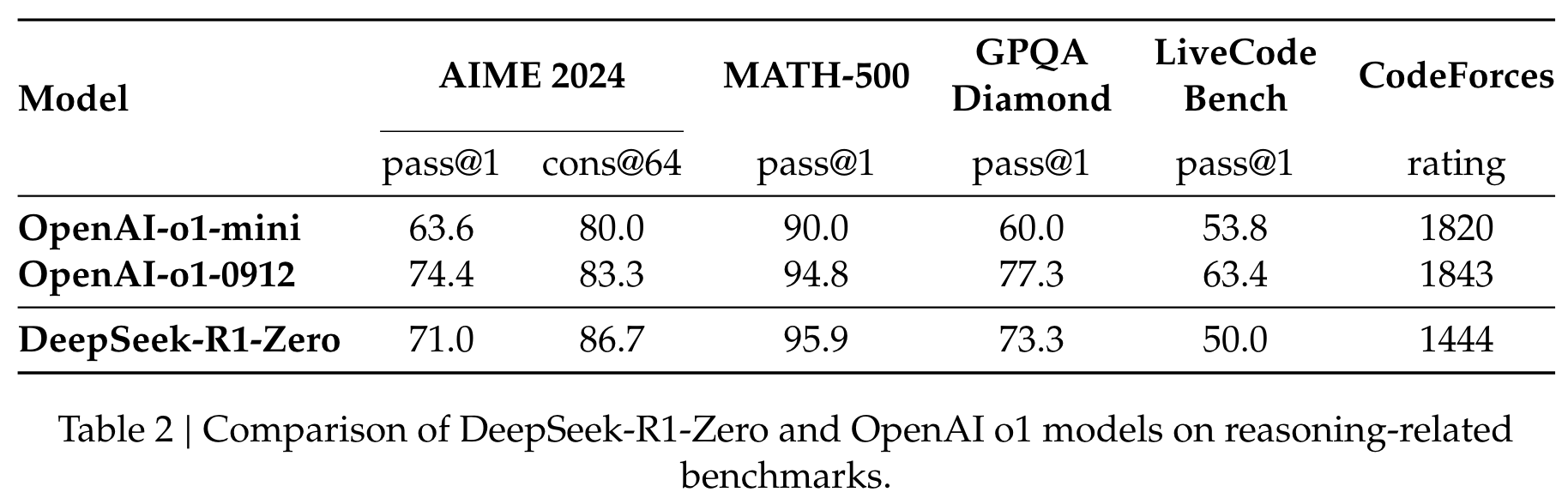
首先,将更强大的模型蒸馏成较小的模型会产生出色的结果,而依赖本文提到的大规模RL的较小模型则需要巨大的计算功率,甚至可能无法实现蒸馏的性能。
其次,尽管蒸馏策略既经济又有效,但超越智能界限的前进仍然可能需要更强大的基础模型和大规模的增强学习。
Future Work
General Capability: Currently, the capabilities of DeepSeek-R1 fall short of DeepSeek-V3 in tasks such as function calling, multi-turn, complex role-playing, and JSON output. Moving forward, we plan to explore how long CoT can be leveraged to enhance tasks in these fields.
Language Mixing: DeepSeek-R1 is currently optimized for Chinese and English, which may result in language mixing issues when handling queries in other languages. For instance, DeepSeek-R1 might use English for reasoning and responses, even if the query is in a language other than English or Chinese. We aim to address this limitation in future updates.
Prompting Engineering: When evaluating DeepSeek-R1, we observe that it is sensitive to prompts. Few-shot prompting consistently degrades its performance. Therefore, we recommend users directly describe the problem and specify the output format using a zero-shot setting for optimal results.
Software Engineering Tasks: Due to the long evaluation times, which impact the efficiency of the RL process, large-scale RL has not been applied extensively in software engineering tasks. As a result, DeepSeek-R1 has not demonstrated a huge improvement over DeepSeek-V3 on software engineering benchmarks. Future versions will address this by implementing rejection sampling on software engineering data or incorporating asynchronous evaluations during the RL process to improve efficiency.
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 纯强化学习(RL)驱动的推理能力训练:论文提出了一种无需监督微调(SFT)的强化学习方法(DeepSeek-R1-Zero),通过直接在基础模型上应用RL,探索LLM自我进化的可能性。这一方法证明了在没有监督数据的情况下,LLM可以通过RL发展出复杂的推理能力,这在领域内是首次公开验证的成果。
- 多阶段训练管道的设计:论文提出了DeepSeek-R1的多阶段训练流程,包括冷启动数据的引入、推理导向的强化学习、拒绝采样生成监督数据以及多场景强化学习。这种管道有效地解决了DeepSeek-R1-Zero在可读性和语言一致性方面的缺陷,使得模型在推理任务上达到与OpenAI-o1-1217相当的水平。
- 蒸馏技术的创新应用:论文展示了如何将大型模型的推理能力蒸馏到较小的模型中,显著提升小模型的性能。尤其是,DeepSeek-R1-Distill-Qwen-32B在多个基准测试上的表现超过了同类开源模型,证明了蒸馏技术在推理能力迁移中的潜力。
- 自发行为的观察与分析:论文详细记录了DeepSeek-R1-Zero在RL过程中自发产生的复杂行为(如反思和重新评估),以及“aha时刻”的出现。这些现象展示了RL在模型智能进化中的潜力,为后续研究提供了重要的启发。
-
论文中存在的问题及改进建议:
- 冷启动数据的依赖性:虽然冷启动数据有效提升了DeepSeek-R1的性能,但这种方法依赖于人为设计的数据集,可能限制了方法的普适性。改进建议是探索更自动化的数据生成方法,例如利用生成式对抗网络(GAN)或其他生成模型自动生成高质量的冷启动数据。
- 语言混杂问题:DeepSeek-R1在多语言任务中存在语言混杂的问题,尤其是当输入为非中英文时,模型倾向于使用英语进行推理和回答。改进建议是在RL过程中引入更细粒度的语言一致性奖励,或通过多语言数据增强训练集来改进模型的多语言适应性。
- 对提示敏感:论文指出DeepSeek-R1对提示的敏感性较高,尤其是少样本提示会显著降低模型性能。建议进一步研究提示工程(prompt engineering)技术,设计更鲁棒的提示策略,或者开发自适应提示优化机制,使模型能更好地适应多样化的输入格式。
- 工程任务的局限性:由于RL在软件工程任务中的应用受限,DeepSeek-R1在相关基准测试中的表现未能显著超越前代模型。建议在未来工作中引入异步评估机制或针对性的数据增强,以提升模型在工程任务中的表现。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:无监督数据生成与强化学习结合:开发一种完全自动化的无监督数据生成框架,结合RL探索模型的自我进化能力,减少对冷启动数据的依赖。
- 创新点2:多语言一致性推理奖励机制:设计一种动态语言一致性奖励机制,在RL过程中实时评估和调整模型的语言输出比例,以提升多语言任务的适应性。
- 创新点3:推理能力的跨领域迁移:研究如何将数学和编码等领域的推理能力迁移到更复杂的开放领域任务中,例如科学推理和社会问题解决。
-
为新的研究路径制定的研究方案:
-
研究方案1:无监督数据生成与强化学习结合
- 研究方法:利用生成式对抗网络(GAN)或变分自编码器(VAE)生成高质量的无监督推理数据,设计一个循环训练框架,模型在RL训练中生成新的数据,新的数据再用于优化GAN/VAE生成器。
- 步骤:
- 初始化GAN/VAE,生成初始推理数据。
- 使用生成的数据对基础模型进行RL训练。
- 从RL模型中采样新数据,更新GAN/VAE生成器。
- 循环上述过程,直到RL模型性能收敛。
- 期望成果:开发出一种完全自动化的推理能力提升方法,减少对人工数据设计的依赖,同时提升模型在无监督环境下的自我进化能力。
-
研究方案2:多语言一致性推理奖励机制
- 研究方法:设计一个动态语言奖励模块,通过实时监控模型输出的语言比例,结合目标语言的词频统计和语法特征,动态调整RL奖励信号。
- 步骤:
- 构建多语言数据集,涵盖多种任务类型。
- 在RL过程中引入语言奖励模块,实时计算目标语言的占比,并根据占比调整奖励值。
- 通过消融实验验证语言奖励模块对模型性能的影响。
- 期望成果:改进模型在多语言任务中的表现,减少语言混杂现象,并提升模型在非中英语言环境下的推理能力。
-
研究方案3:推理能力的跨领域迁移
- 研究方法:设计一个跨领域推理迁移框架,利用领域间的共性(如逻辑结构和问题分解),通过多任务学习和迁移学习提升模型的跨领域推理能力。
- 步骤:
- 选取数学、编码和科学推理等领域的基准数据集。
- 使用多任务学习方法训练模型,在共享参数的同时保留领域特定参数。
- 通过迁移学习将模型在特定领域的推理能力迁移到开放领域任务中。
- 使用开放领域基准测试评估模型性能。
- 期望成果:开发出一种具有通用推理能力的模型,能够在不同领域任务之间高效迁移推理能力,提升开放领域任务的表现。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!