目录
Resource Info Paper https://arxiv.org/abs/2411.14257 Code & Data / Public arXiv Date 2025.01.15
Summary Overview
本文使用稀疏自动编码器(SAE)来识别模型表示空间中的方向,该方向编码来关于实体的自我知识形式。作者证明,通过操纵这些方向,可以控制模型拒绝答案或幻觉信息的趋势。同时还提供了有关实体识别方向如何影响模型行为的见解,例如调节对实体 token 的关注以及它们在表达知识不确定性方面的影响。最后,发现了代表特定查询的模型不确定性的方向,能够区分正确和错误的答案。这项工作有助于对语言模型行为的理解,并为改善模型的可靠性和缓解幻觉提供了途径。
Main Content
使用 SAE 作为一种可解释性工具,发现这些机制的关键部分是实体识别,该模型检测到实体是否是已知的。证明,尽管在基本模型上训练了稀疏的自动编码器,但这些方向对聊天模型的拒绝行为产生了因果影响,这表明聊天模型的微调已重新使用了这种现有机制。
SAE是一种可解释的工具,用于寻找模型表示的稀疏,可解释的分解。我们使用Gemma Scope(Lieberum等,2024),它提供了一套在Gemma 2型号(Team等,2024)上训练的SAE,并在Gemma 2 2b和9b中找到自我知识的内部表示。
Contributions:
- 使用稀疏的自动编码器(SAE),我们发现了实体最终令牌的表示空间中的指示,检测模型是否可以回忆起关于实体的事实,这是一种关于其自身能力的自我知识的形式。
- 我们的发现表明,实体识别方向跨越了各种实体类型:播放器,电影,歌曲,城市等。
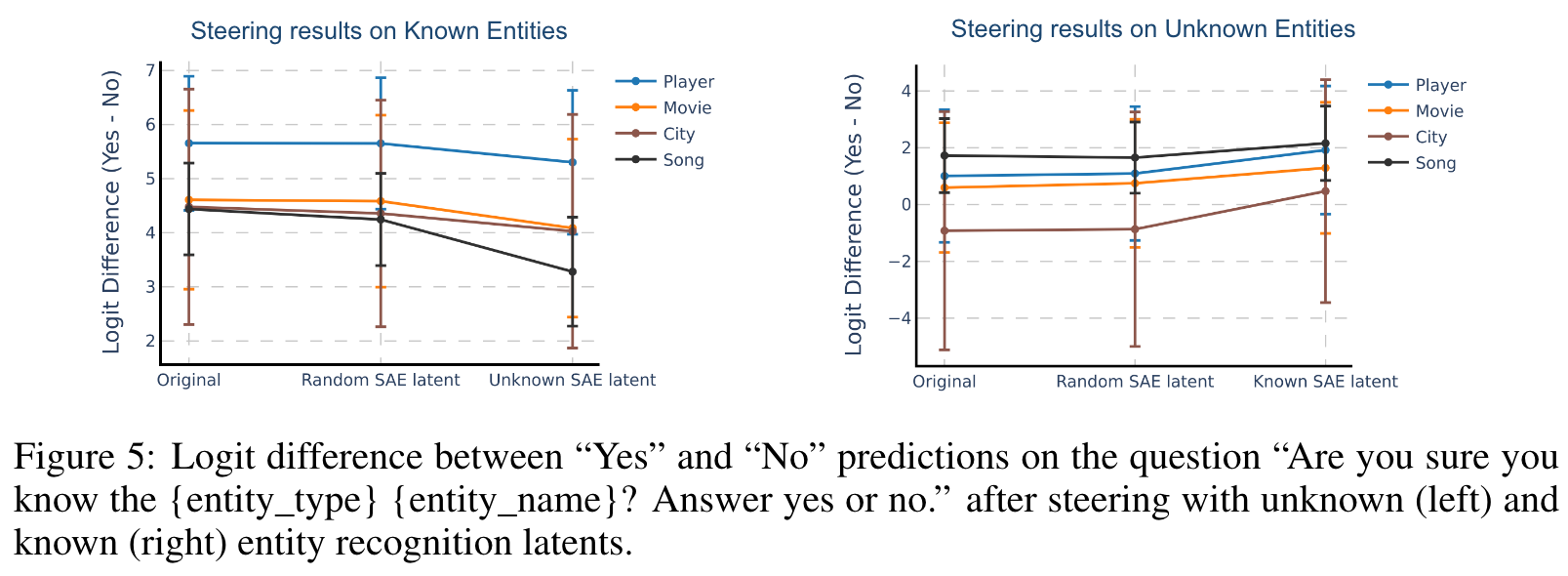
- 我们证明,这些方向在聊天模型中拒绝知识,即通过指导这些方向,我们可以使模型幻觉而不是拒绝未知实体,并拒绝回答有关已知实体的问题。
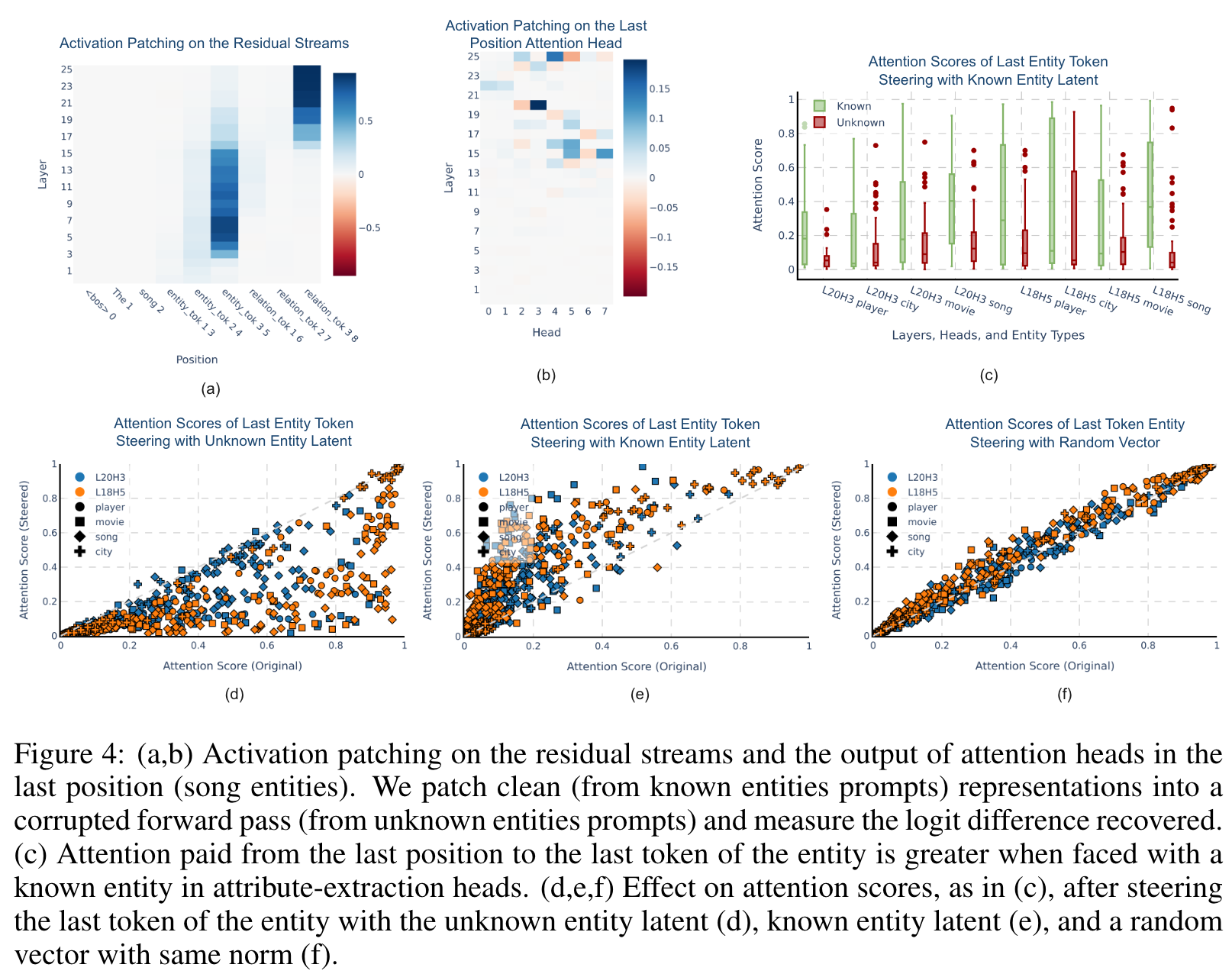
- 我们发现,未知实体识别方向通过抑制属性提取头的注意来破坏事实召回机制,这在先前的工作中显示(Nanda等,2023; Geva等,2023)是该机制的关键部分。
- 我们不仅仅是理解知识拒绝的知识,还找到了可以预测不正确答案的不确定性的SAE潜伏期。
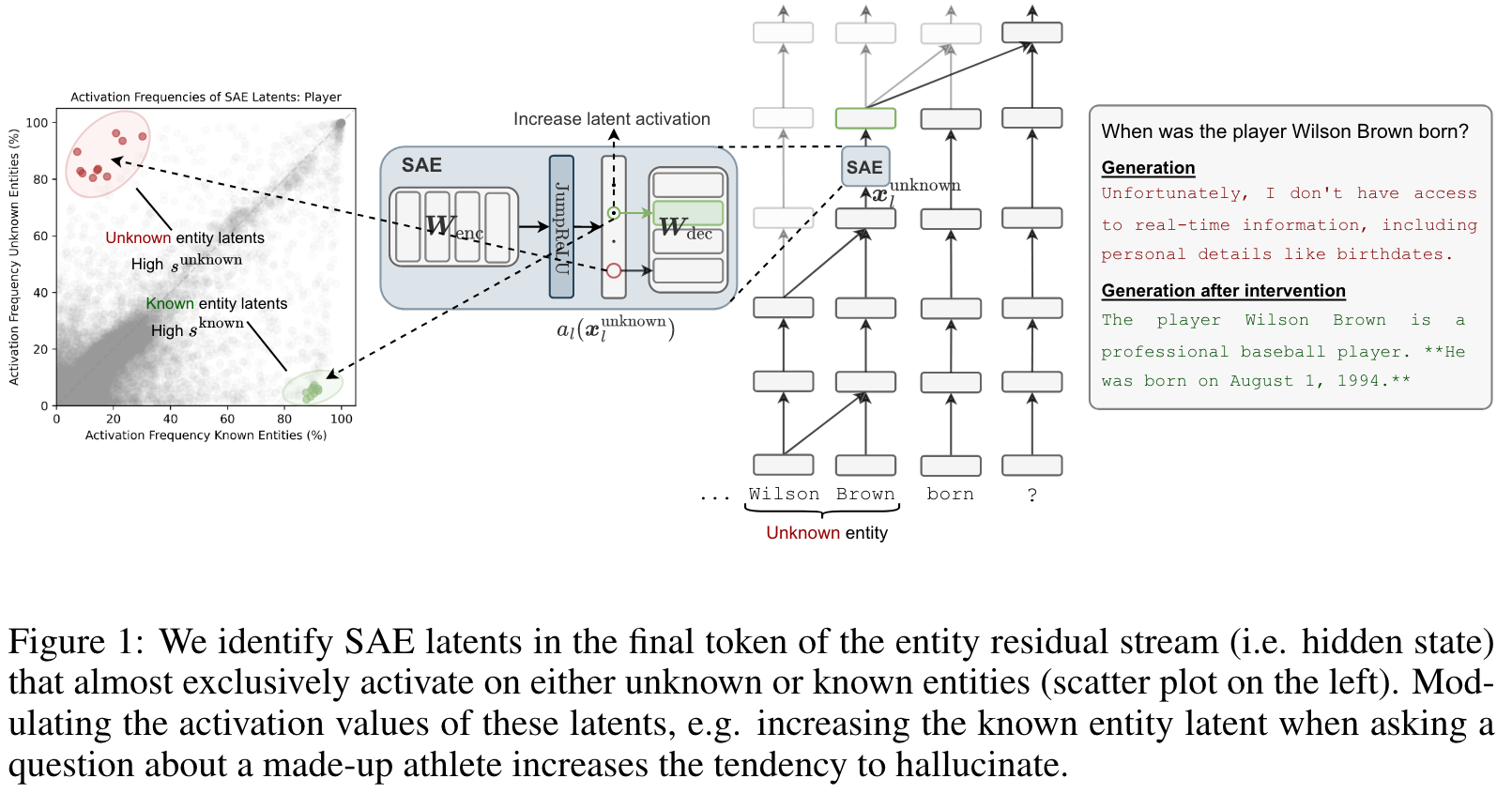
SAE 设置
Steering with SAE Latents.
Recall from Equation (1) that SAEs reconstruct a model's representation as This means that the reconstruction is a linear combination of the decoder latents (rows) of plus a bias, i.e. Thus, increasing/decreasing the activation value of an SAE latent, , is equivalent to doing activation steering (Turner et al., 2023) with the decoder latent vector, i.e. updating the residual stream as follows:
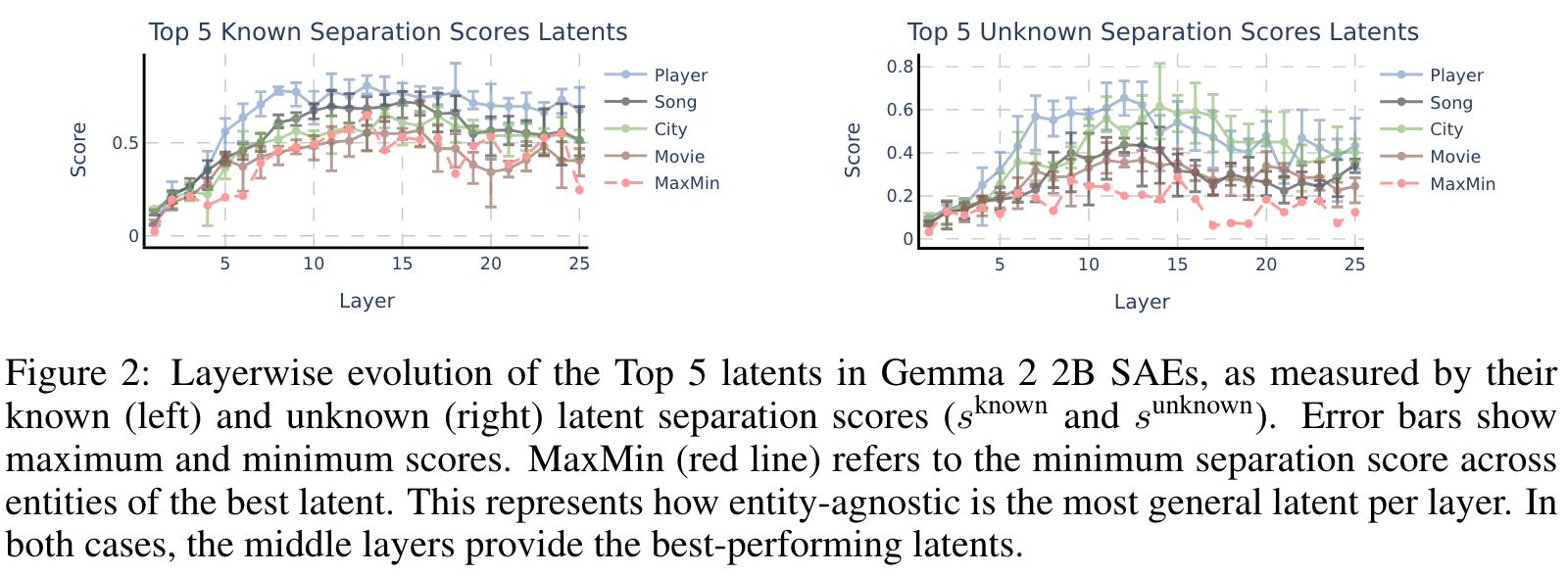
一个有趣的观察结果是,潜在的分离得分揭示了所有实体类型的一致模式,在整个模型中分数都在增加,并且在平稳之前达到了第9层的峰值。
这表明在中间层中发现已知和未知实体的潜在区分。
高最小分离得分表明,潜在的跨实体类型的性能强大,表明强大的概括能力。这一发现指出了模型中实体表示的层次组织,质量更专业,质量更差,较早的层中的潜伏期以及中层层中出现的更广泛的,更高质量的实体型 - 型敏捷的特征。

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 创新性方法: 论文利用稀疏自编码器(Sparse Autoencoders, SAEs)作为一种解释性工具,发现了语言模型中存在的“实体识别方向”,这些方向能够编码模型对自身知识的评估能力。这种方法不仅揭示了模型内部对已知和未知实体的区分机制,还为理解模型的自我知识提供了新的视角。
- 跨实体类型的通用性: 研究表明,这些实体识别方向能够在多个实体类型(如电影、城市、歌曲、运动员)之间泛化,展示了其强大的通用性和适应性。
- 因果相关性分析: 通过操控这些方向,作者发现可以影响模型的行为,例如让模型对已知实体拒绝回答,或对未知实体生成虚假的信息。这种因果验证进一步证明了这些方向对模型行为的直接影响。
- 机制性洞察: 论文深入探讨了这些方向如何通过干扰模型的注意力机制来调节模型的事实回忆能力,特别是在实体属性提取过程中对注意力头的影响。
- 错误预测的潜在标记: 研究还揭示了某些稀疏自编码器方向可以预测模型可能产生错误回答的情况,为未来的错误检测和修复提供了新的方向。
-
论文中存在的问题及改进建议:
- 实验覆盖范围不足: 论文主要集中在Gemma 2模型(2B和9B参数规模)上,缺乏在更大规模模型(如GPT-4或PaLM-2)上的验证。建议扩展实验范围,以验证这些发现是否适用于更大规模的模型。
- 方向的可解释性不足: 尽管发现了实体识别方向,但这些方向的具体语义含义仍然模糊。可以进一步利用可视化工具或语言特征分析方法,深入解释这些方向的含义。
- 实际应用中的局限性: 论文中的方法主要在实验室环境中测试,未探讨如何在实际应用中有效利用这些方向(如在医疗或法律领域)。建议设计真实场景下的测试,验证其实际效用。
- 对未知实体的定义过于简单: 论文将模型无法正确回答的实体归为“未知”,但未考虑模型可能部分掌握相关信息的情况。可以引入更细粒度的分类机制,例如“部分已知”或“模糊已知”。
- 对稀疏自编码器的依赖性: 论文高度依赖于稀疏自编码器,而未讨论其他可能的解释性工具(如特征分解或注意力分析)的潜力。可以尝试多种方法进行对比研究。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1: 探索更大规模模型中的实体识别方向,并研究这些方向是否在模型规模扩大后表现出更强的泛化能力或新的特性。
- 创新点2: 研究不同语言模型(如多语言模型或领域特化模型)中实体识别方向的差异,以及这些方向在跨语言或跨领域任务中的表现。
- 创新点3: 基于实体识别方向,开发一种动态拒绝机制,使模型能够更准确地评估自身知识边界,并在回答前动态调整回答策略。
- 创新点4: 结合实体识别方向与模型生成的不确定性,设计一种新的可解释性框架,用于实时检测和修复模型生成中的潜在错误。
-
为新的研究路径制定的研究方案:
-
研究路径1:探索更大规模模型中的实体识别方向
- 研究方法:
- 选择多个大规模语言模型(如GPT-4、PaLM-2、LLaMA 3)进行实验。
- 在这些模型的中间层和输出层中应用稀疏自编码器,提取潜在的实体识别方向。
- 比较不同规模模型中方向的激活模式、泛化能力和因果效应。
- 研究步骤:
- 设计一组覆盖多种实体类型的测试数据集。
- 对比分析不同模型中方向的分布和语义一致性。
- 验证方向对模型拒绝行为的因果影响。
- 期望成果:
- 确定模型规模对实体识别方向的影响。
- 提供更大规模模型中方向的机制性洞察。
- 为大规模模型的解释性研究提供新工具。
- 研究方法:
-
研究路径2:跨语言和领域的实体识别方向研究
- 研究方法:
- 选择多语言模型(如mT5)和领域特化模型(如医疗领域的PubMedGPT)。
- 分析这些模型中实体识别方向的激活模式和语义特性。
- 研究方向在跨语言任务(如翻译)或跨领域任务(如医学问答)中的表现。
- 研究步骤:
- 构建多语言和多领域的实体测试集。
- 使用稀疏自编码器提取方向,并比较不同语言和领域中的特性。
- 测试方向在跨语言或跨领域任务中的转移能力。
- 期望成果:
- 揭示实体识别方向的语言和领域依赖性。
- 提供跨语言和跨领域模型优化的新思路。
- 为多语言和多领域任务设计更可靠的拒绝机制。
- 研究方法:
-
研究路径3:基于实体识别方向的动态拒绝机制
- 研究方法:
- 将实体识别方向与生成模型的不确定性结合,设计一种动态拒绝机制。
- 通过实时监测方向激活值,动态调整模型的回答策略(如拒绝回答或生成模糊答案)。
- 在实际应用场景(如医疗咨询、法律问答)中测试该机制的有效性。
- 研究步骤:
- 构建包含已知和未知实体的真实场景测试集。
- 实现动态拒绝机制,并集成到现有模型中。
- 测试该机制对回答准确性和用户满意度的影响。
- 期望成果:
- 提供一种更智能的拒绝机制,减少模型的错误回答。
- 提高模型在高风险场景中的可靠性。
- 推动语言模型在实际应用中的安全性和可信度。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!