目录
Resource Info Paper http://arxiv.org/abs/2505.18454 Code & Data https://github.com/Yueeeeeeee/HRPO Public arXiv Date 2025.07.10
Main Content
作者提出了针对于 latent reasoning 的 RL 算法 (HRPO)。
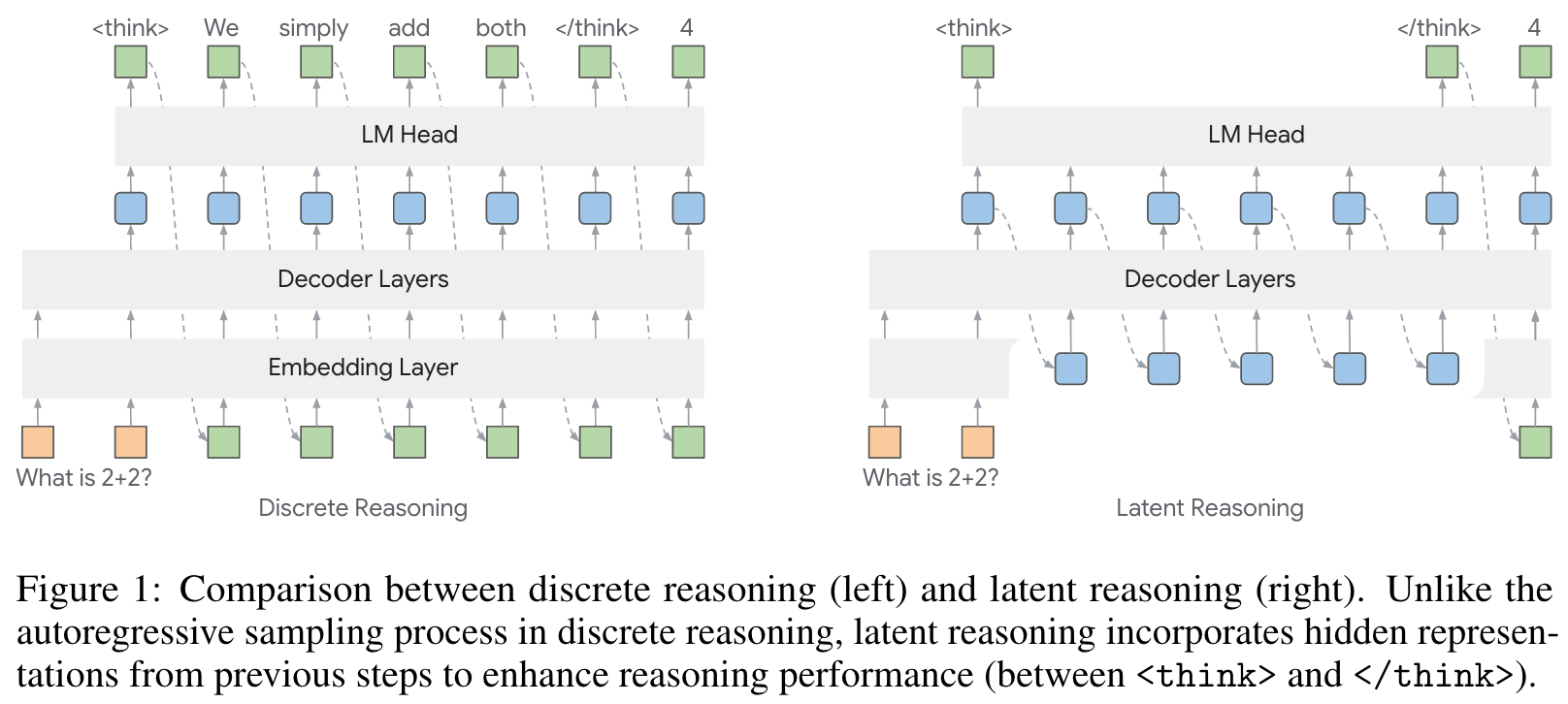
We first describe our notation and settings for hybird latent reasoning. For input query and its corresponding token embeddings , we describe the raw hidden states from the LLM output at step with , namely:
in which denotes the transformer model (i.e., decoder layers), represents the final-layer hidden states produced by the . With the LM head (), the next output token can be sampled from the output distribution over the vocabulary via:
However, hidden states often lie outside the model's token embedding manifold, which degrades generation quality when fed directly. To avoid this, we project back into the embedding space to ensure the inputs conform to the model's learned distribution. Specifically, we use the output probabilities to compute a weighted interpolation over the vocabulary:
in which is the temperature and denotes the embedding matrix of the LLM. In other words, we compute the next input embeddingg as a weighted sum of all token embeddings, with weights given by . In addition, is normalized to preserve the scale and variance of the output vector. This sampling-free mapping ensures differentiability and aligns the projected embedding with the model's native input space, thus leading to improved training dynamics.
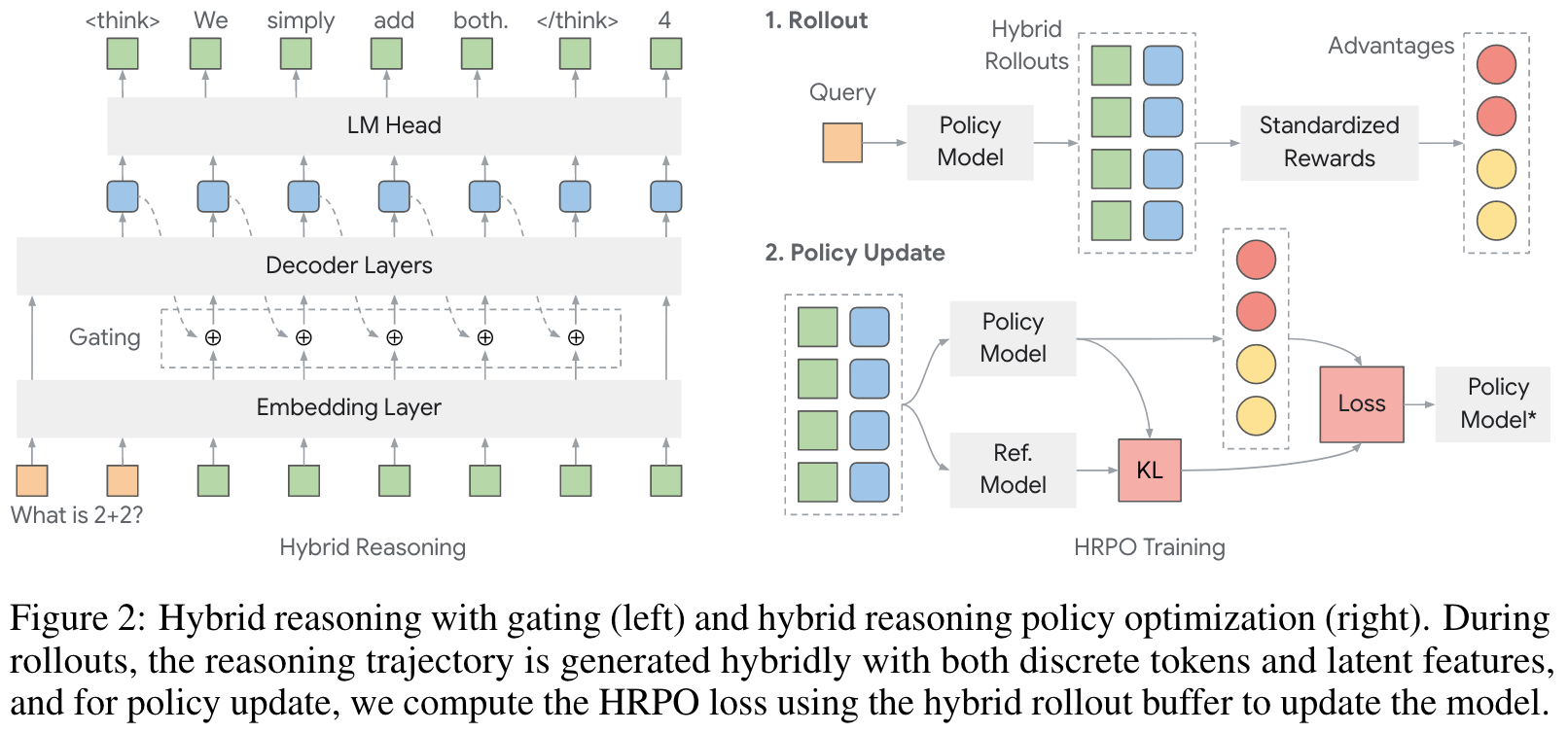
While interpolated embeddings preserve semantic continuity, directly feeding as the next token input removes stochasticity and injects noise from irrelevant tokens, causing degraded generation within RL rollouts. As such, we design a hybird approach for latent reasoning by gradually imposing hidden state representations into the sampled token embeddings with a gating mechanism. Drawing on gated recurrence models, we formulate the gating mechanism as:
is the resulting hybird input for the next step, denotes the embedding of the sampled discrete token , whereas is the projected hidden states. The gates and leverages sigmoid function to control the blending, scales , is a fixed scaling constant, and is a learnable vector. Note that hybird reasoning only applies during the reasoning phase (i.e., ), while the final answer is still generated via standard autoregressive decoding. By initializing , the inputs first draw predominantly from the sampled token embeddings, thereby effectively preserving the LLM's generative capabilities. As the training progresses, the value range of converages to an optimum range and thus incorporates informative features from both hidden representations and sampled tokens.
As such, our HRPO implementation remains light weight, strictly on-policy and could be seamlessly combined with further RL optimizations.
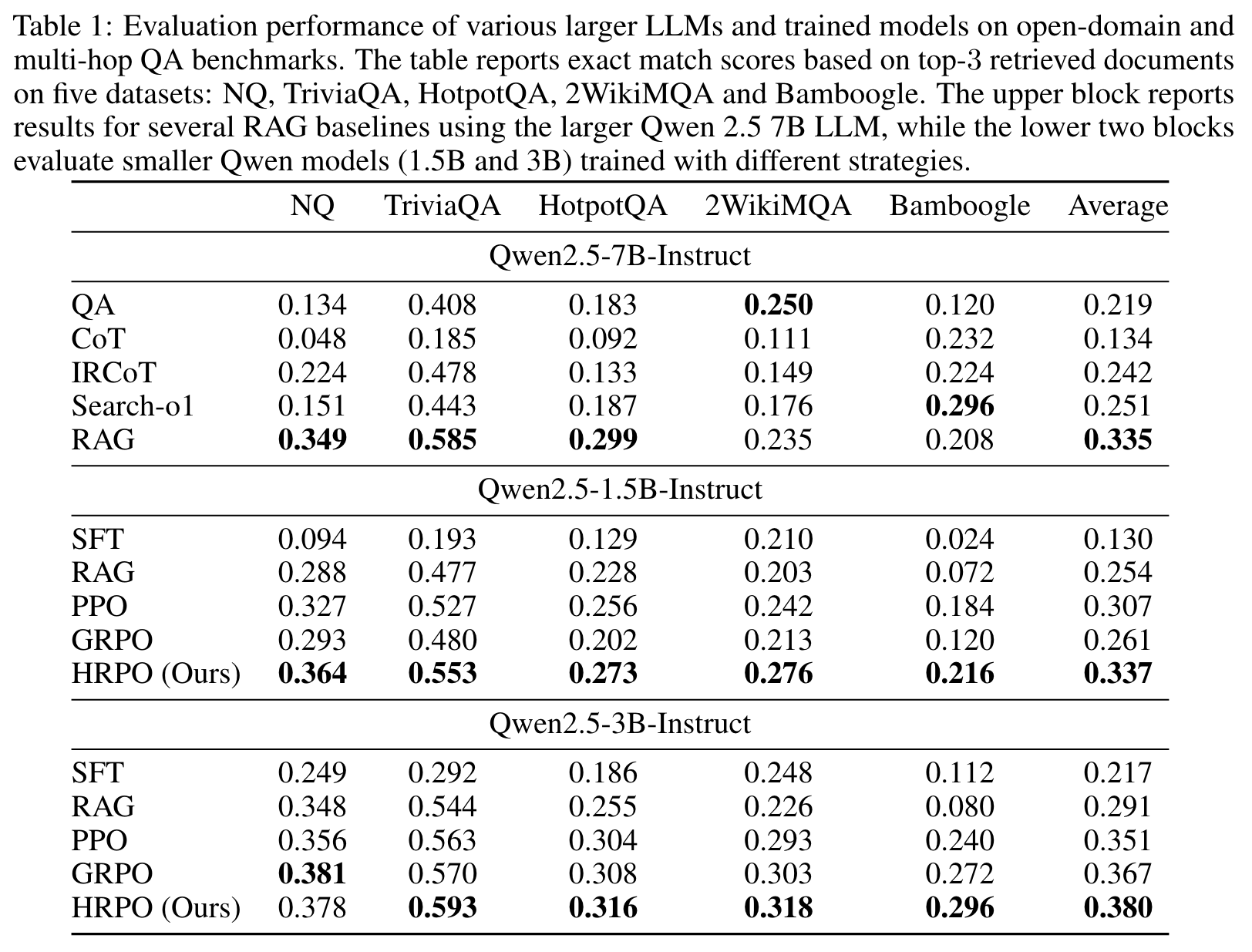
Exp 1: open-domain & multi-hop knowledge-intensive question answering (Knowledge)
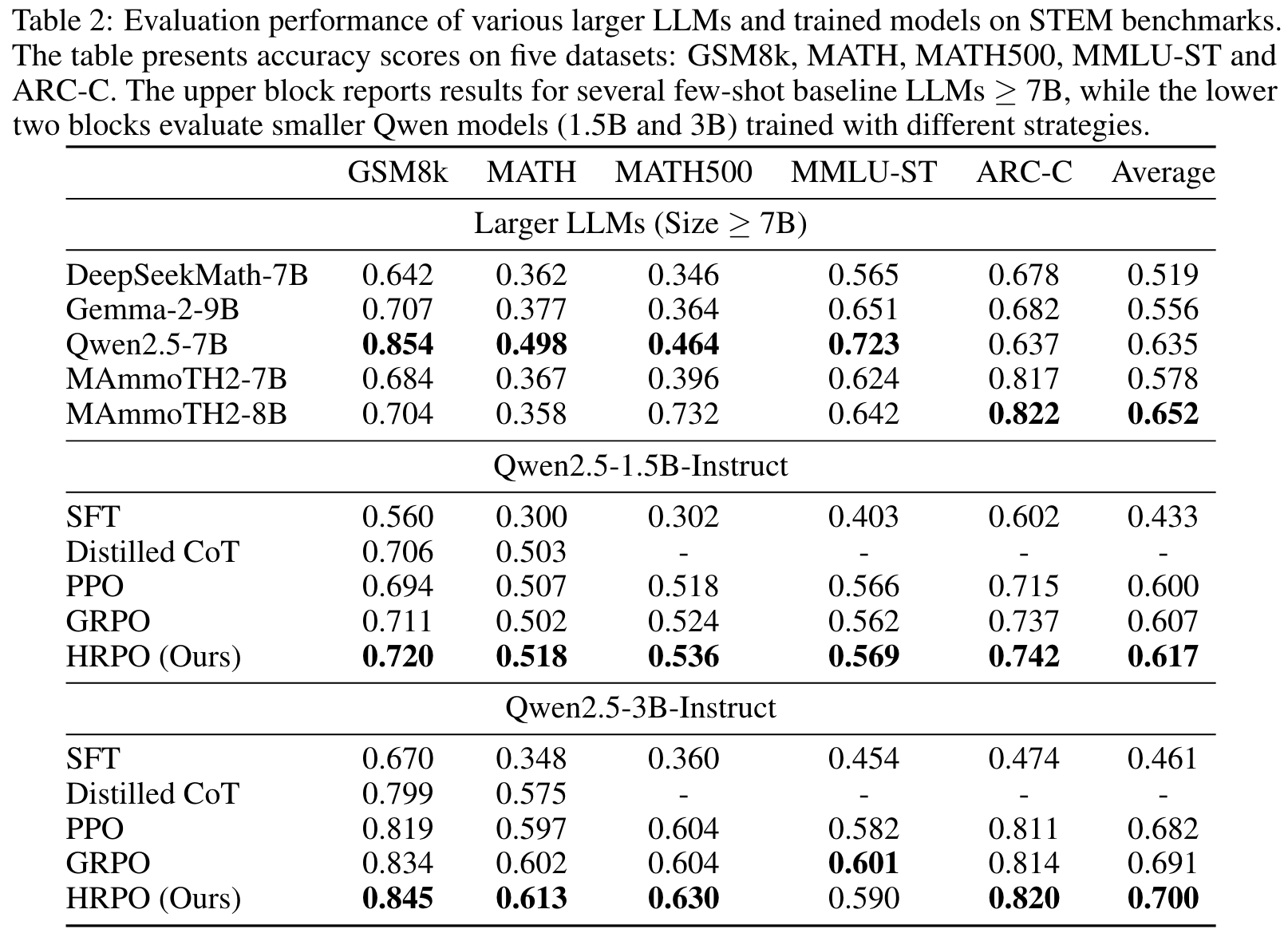
Exp 2: science, technology, engineering or mathematics (STEM) benchmarks.
Different Strategies for Latent Reasoning. We compare different strategies to compute latent representations. Specifically, we use three methods to integrate hidden states into RL and train the 1.5B Qwen model on the MATH dataset. These variants are: (1) hidden states, which use the final layer hidden states as the next input; (2) interpolation, which employs interpolated embeddings; and (3) HRPO, our hybird latent reasoning. We visualize the exponential moving average (EMA) of rewards along with the GRPO baseline. Due to the mismatch between hidden states and embeddings, using hidden states degrades generation and yields nonosensical rollouts with zero reward. Although interpolation performs similar to HRPO for the first few hundred steps, the rewards eventually collapse and only slowly recover, likely because interpolation introduces excessive noise. We also provide a direct comparison between HRPO and latent reasoning mehtods. Overall, our approach achieves superior training dynamics with faste convergence while maintaining stability comparable to GRPO, highlighting the efficacy of our hybird design choice in HRPO.
🤖
-
论文的创新之处与独特性:
- 创新点1:混合隐式推理与强化学习的结合
论文提出了一个名为“混合推理策略优化(HRPO)”的框架,通过强化学习(RL)逐步将隐式推理能力融入到大型语言模型(LLMs)中。相比传统的基于离散推理路径的训练方法,HRPO通过引入连续隐状态与离散嵌入的混合推理方式,减少对链式推理(CoT)标注数据的依赖,同时保留了LLMs的生成能力。 - 创新点2:可学习的门控机制
论文设计了一种门控机制,用于动态调整离散嵌入与隐式推理特征的权重。通过逐步引入隐状态信息,这种机制既保留了模型的生成能力,又实现了连续特征的有效融合。 - 创新点3:无监督奖励优化
HRPO采用了基于结果的简单奖励函数,无需复杂的链式推理标注数据,直接通过强化学习优化模型推理性能。这种方法降低了训练成本,同时提高了模型在知识密集型任务和推理密集型任务中的表现。 - 创新点4:跨语言推理能力
论文展示了HRPO在跨语言推理中的潜力,能够在推理过程中自然地结合多语言信息,表现出更强的泛化能力。
- 创新点1:混合隐式推理与强化学习的结合
-
论文中存在的问题及改进建议:
- 问题1:对隐状态与嵌入空间的映射处理不足
论文中提到直接将隐状态投射到嵌入空间可能会引入噪声,导致生成质量下降。虽然设计了插值机制,但仍可能存在隐状态与嵌入空间的匹配问题。
改进建议:引入更复杂的投射机制,例如基于对比学习的方法,确保隐状态与嵌入空间的语义一致性。 - 问题2:奖励函数设计过于简单
论文中使用了基于答案正确性的单一奖励函数,这可能无法充分捕捉推理过程的质量。
改进建议:设计多维奖励函数,结合推理过程的连贯性、复杂性和生成质量,进一步优化模型性能。 - 问题3:对多语言推理的深入分析不足
虽然论文提到HRPO具备跨语言推理能力,但未深入分析其在多语言任务中的具体表现。
改进建议:增加跨语言任务的实验,分析HRPO如何处理不同语言之间的语义转换与上下文整合问题。 - 问题4:训练效率与资源需求未详细评估
论文未详细说明HRPO在不同规模的模型上训练的效率与资源需求。
改进建议:提供详细的训练时间、资源消耗与模型规模的对比分析,为实际应用提供参考。
- 问题1:对隐状态与嵌入空间的映射处理不足
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:基于强化学习的动态任务适配框架
设计一个能够根据任务需求动态调整隐状态与嵌入比例的框架,使模型能够更高效地适配不同类型的任务(如知识问答、逻辑推理、数学计算)。 - 创新点2:跨语言隐式推理优化
探索如何通过强化学习进一步增强HRPO的跨语言推理能力,研究隐状态在不同语言间的迁移与共享机制。 - 创新点3:隐状态与外部知识库的结合
将HRPO的隐式推理能力与外部知识库(如语义图谱、结构化数据库)相结合,提升模型的知识获取与复杂推理能力。
- 创新点1:基于强化学习的动态任务适配框架
-
为新的研究路径制定的研究方案:
-
研究路径1:基于强化学习的动态任务适配框架
- 研究方法:设计一个动态门控机制,通过强化学习实时调整隐状态与嵌入比例,使模型能够根据任务类型(如知识问答、逻辑推理)自动优化推理过程。
- 研究步骤:
- 收集多样化的任务数据集(如知识问答、逻辑推理、数学计算)。
- 设计动态门控机制,定义任务类型的特征向量。
- 使用强化学习优化门控参数,训练模型在不同任务上的适配能力。
- 测试模型在多任务环境中的表现,分析适配效率与推理质量。
- 期望成果:提出一个能够动态适配任务需求的推理框架,提升模型在多任务环境中的表现。
-
研究路径2:跨语言隐式推理优化
- 研究方法:通过强化学习优化隐状态在不同语言间的迁移与共享机制,探索隐式推理的跨语言泛化能力。
- 研究步骤:
- 收集多语言数据集(如英语、中文、法语等)的推理任务。
- 设计跨语言隐状态共享机制,定义语言间的迁移矩阵。
- 使用HRPO框架训练模型,优化隐状态在多语言任务中的表现。
- 测试模型在跨语言任务上的推理能力,分析语义一致性与泛化性。
- 期望成果:提出一个跨语言隐式推理优化框架,增强模型在多语言环境中的推理能力。
-
研究路径3:隐状态与外部知识库的结合
- 研究方法:将HRPO的隐式推理能力与外部知识库(如语义图谱、结构化数据库)相结合,提升模型的知识获取与复杂推理能力。
- 研究步骤:
- 构建一个包含语义图谱与结构化数据库的知识库。
- 设计隐状态与知识库交互的机制,定义知识检索与推理规则。
- 使用HRPO框架训练模型,优化隐状态与知识库的结合能力。
- 测试模型在知识密集型任务上的表现,分析知识获取效率与推理质量。
- 期望成果:提出一个结合隐状态与外部知识库的推理框架,提升模型在知识密集型任务中的表现。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!