目录
Resource Info Paper https://arxiv.org/abs/2505.15778 Code & Data https://github.com/eric-ai-lab/Soft-Thinking Public arXiv Date 2025.07.11
Main Content
作者提出了 Soft Thinking,一种无需训练的方法来在连续的概念空间中进行推理的方法。
A fundamental limitation of standard CoT reasoning is its inherently unidirectional and sequential nature: at each step, the model samples a single token, committing to one specific branch of the reasoning path.
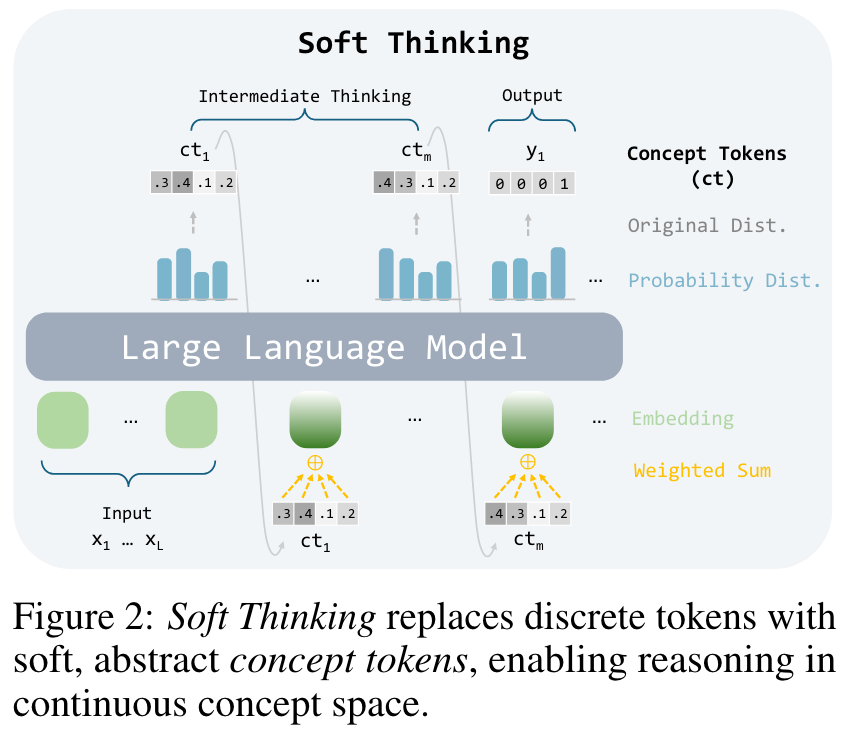
In this work, we propose a new perspective: instead of constraining LLMs to reason within the discrete, sequential space of language tokens, we aim to enable LLMs to reason with soft, abstract concepts, which encompass more general and fine-grained semantics and retain information about multiple possible paths. This retains the original distribution of the next step. At each step, we construct a new embedding from a concept token by probability-weighting all tokens embeddings, which form the continuous concept token. This approach allows the model to represent and process abstract concepts, endowing each output token with more nuanced and fine-grained semantics, and enabling the processing of multiple paths conceptually.
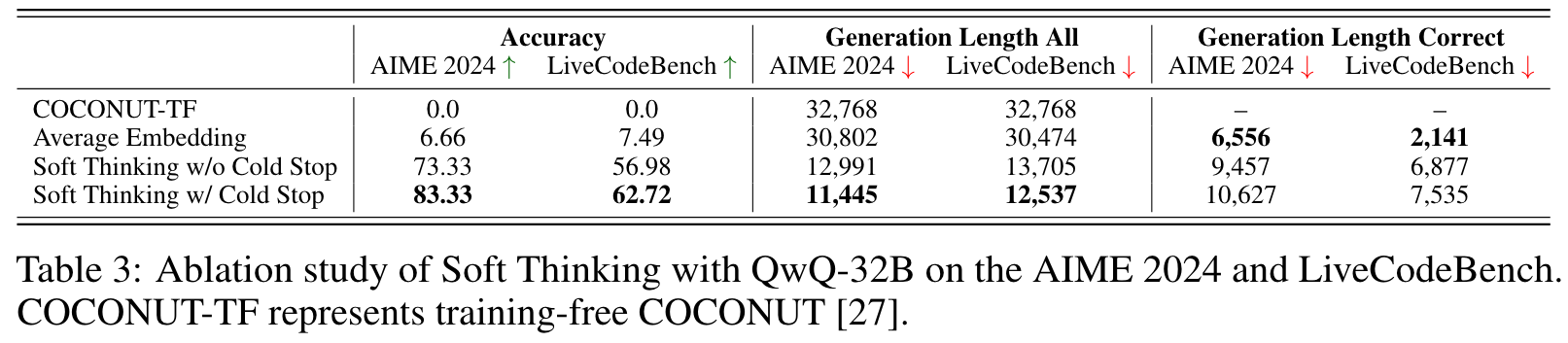
As a result, we introduce a Cold Stop mechanism to further boost efficiency and address the challenge of generation collapse (e.g., repetition) caused by out-of-distribution(OOD) inputs, where certain concept tokens may be unseen during training. To be specific, Cold Stop monitors the entropy of the model's output distribution at each step and terminates the reasoning process early when the model demonstrates high confidence (i.e., low entropy) over several consecutive steps. This mechaism prevents unnecessary computation and mitigates the risk of model collapse when dealing with OOD inputs, ensuring more robust and efficient reasoning.
Two major advances:
- by operating in the continuous concept space formed as a convex combination of all token embeddings, the model can capture and manipulate abstract concepts and detailed semantic information;
- because each concept token keeps a probability distribution from all possible next tokens, the model can implicitly and efficiently explore multiple reasoning paths in parallel, rather than being limited to a single trajectory.
In language models with fewer than 7B parameters, the input embedding layer and the output language model head are typically weight-tied, enabling continuous-space reasoning by aligning the input and output spaces after extensive training. In contrast, for models with more than 7 billion parameters, these components are typically decoupled, meaning that the hidden states and input embeddings reside in different spaces. Directly using hidden states as input embeddings leads to siginficant representational mismatch, which is difficult to bridge even with extensive retraining.
Soft Thinking: Reasoning in a Continuous Concept Space
Definition 1 (Concept Token). At any intermediate thinking step, let be the LLM-produced probability distribution over the vocabulary. We call this probability vector a concept token, denoted by
Unlike a traditional step that collapses the distirbution to a single token id, the concept token preserves the full distribution of every possible next step.
Definition 2 (Continuous Concept Space). Let be the embedding matrix and the embedding of the -th vocabulary item. The continuous concept space is the convex combination of all embedding vectors.
i.e. the set of all probability-weighted mixtures of token embeddings. Note that this is different from the usual semantic space, which is modeled as a -dimensional real vector space.
Reasoning Process. Soft Thinking only replaces the intermediate thinking step of the standard CoT. At each step of soft thinking, the model generates a concept token. Then, in the next step, the concept token is injected back into the LLM by the embedding of concept token:
When the most probable token for a certain concept token is the end-of-thinking, the intermediate reasoning process stops, and the model switches to generating the output. All output stage tokens are sampled in the usual discrete manner; only the intermediate thinking phase flows through the continuous concept space defined above.
Why methodname Helps. Using concept tokens allows the model to avoid making hard decisions too early. Instead of selecting a single token at each step, the model keeps the full probability distribution over vocabulary. This gives it the flexibility to explore different reasoning paths, especially when it's unsure. By working in this continuous concept space, the model can represent more abstract concepts that don't map cleanly to a single word. These abstract concepts can later evolve into more concrete thoughts as reasoning continues. This flexibility helps the model think more clearly, avoid early mistakes, and better handle complex multi-step problems.
Cold Stop While concept tokens enable more abstract reasoning, feeding in continuous concept tokens during inference places the model in an out-of-distribution (OOD) regime. This can lead to model collapse if the reasoning process continues for too long without correction. To mitigate this, we propose a Cold Stop mechanism that dynamically stops intermediate reasoning when the model becomes overconfident. At each step, we compute the entropy of the concept token:
Since preserves the entire probability distribution at each step, the entropy serves as a natural signal for uncertainty, which is often used in LLMs to evaluate the quality of generation. Low entropy, typically represents "cold" in physics, indicates that the model is confident in its prediction~cite{entropy}, and thus can conclude soon. Given an entropy threshold and a required number of consecutive confident steps , we apply the following rule:
- If , increment a low-entropy step counter; otherwise, reset the counter.
- When the counter reaches , we insert an end-of-thinking token to conclude reasoning and begin final answer generation.
This strategy avoids unnecessary computation and prevents the model collapse under OOD conditions, while preserving the benefits of soft thinking through an entropy-based confidence measure.
🤖
1. 论文的创新之处与独特性:
-
创新点一:提出“Soft Thinking”方法
论文提出了一种全新的推理框架——Soft Thinking,突破了传统链式推理(Chain-of-Thought, CoT)方法仅依赖离散语言符号的局限性。Soft Thinking通过概率加权的概念嵌入(concept tokens)在连续概念空间中进行推理,允许模型同时探索多个推理路径,从而提高推理的准确性和效率。这种方法无需额外训练,直接基于现有的语言模型架构实现。 -
创新点二:Cold Stop机制
为解决连续概念空间推理可能导致的生成崩溃(generation collapse)问题,论文设计了Cold Stop机制,通过监测模型输出的熵值,动态终止推理过程。这种机制有效避免了模型在离散分布之外的过度计算,同时提升了推理效率。 -
创新点三:显著的性能提升与效率优化
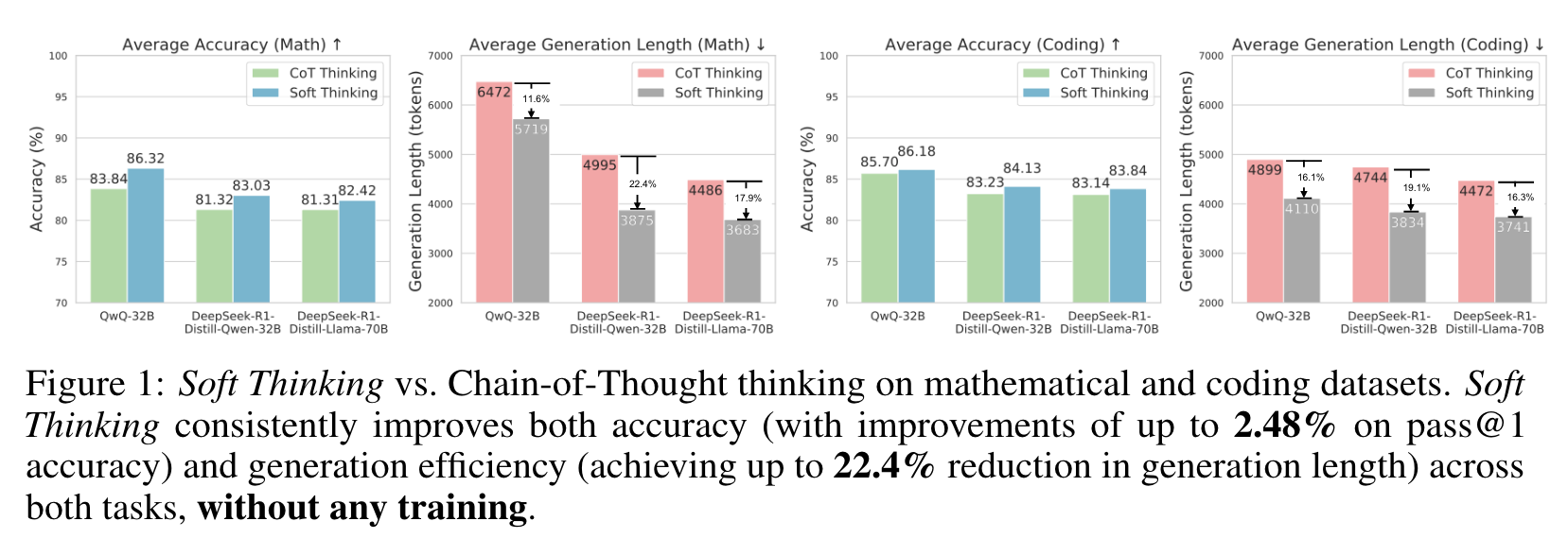
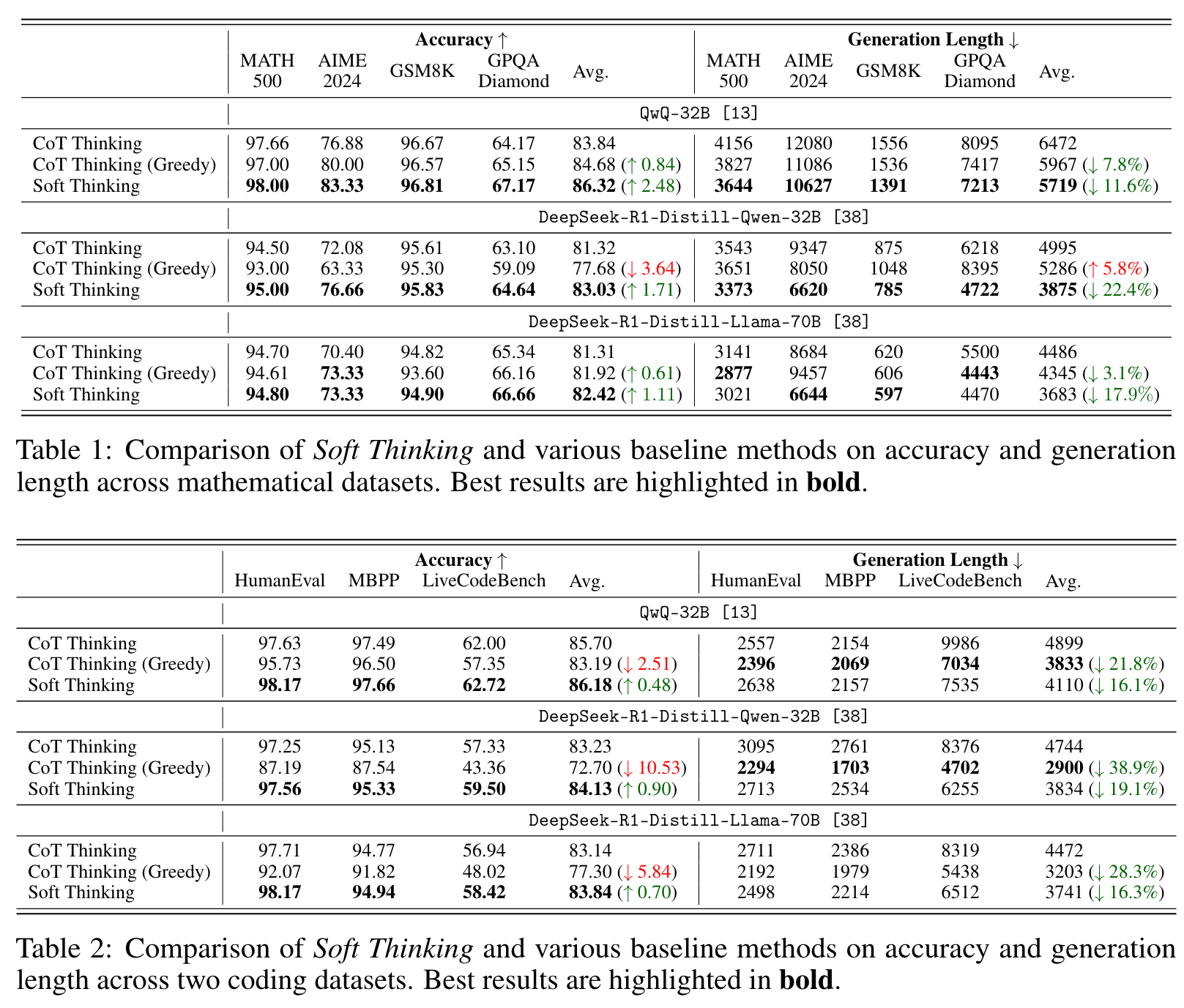
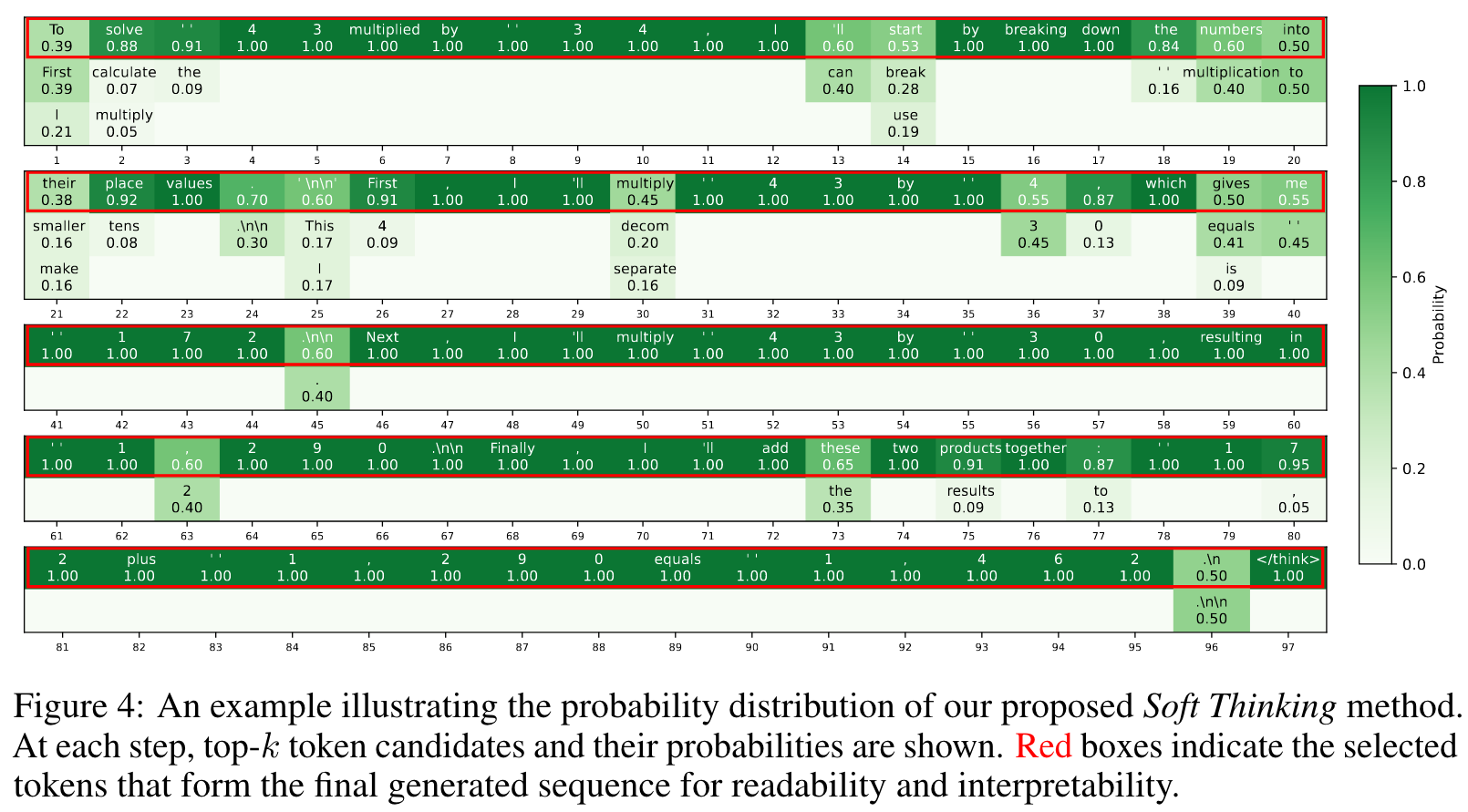
实验结果表明,Soft Thinking在数学和编程任务上均显著提高了Pass@1的准确率(最高提升2.48%)并减少了生成长度(最高减少22.4%)。此外,生成的推理步骤更简洁且易于解释,展示了连续概念空间推理的潜力。 -
创新点四:无需额外训练的实现方式
Soft Thinking完全基于现有模型架构,通过概率加权嵌入实现连续推理,无需额外训练或模型修改。这种轻量级的实现方式为实际应用提供了便利。
2. 论文中存在的问题及改进建议:
-
问题一:离散到连续空间的分布偏移问题
Soft Thinking方法将模型置于离散分布之外(Out-of-Distribution, OOD)的推理环境,可能导致模型不稳定或生成崩溃。虽然Cold Stop机制部分缓解了这一问题,但并未从根本上解决模型对连续概念空间的适应性。改进建议:
- 在模型训练阶段引入概念嵌入的预训练任务,使模型能够学习连续概念空间的表示。
- 设计一种混合推理方法,将离散推理与连续推理结合,动态调整推理模式以适应不同的任务需求。
-
问题二:缺乏对复杂任务的实验验证
论文主要在数学和编程任务上进行了实验验证,但未涉及更复杂的多模态任务或语言理解任务。改进建议:
- 扩展实验范围,验证Soft Thinking在多模态任务(如视觉问答)或语言生成任务中的表现。
- 设计更具挑战性的推理任务,评估Soft Thinking在处理高复杂度问题时的性能。
-
问题三:Cold Stop机制的参数敏感性
Cold Stop机制依赖熵阈值和连续低熵步数的设定,这些参数的选择可能对不同任务表现敏感。改进建议:
- 引入动态参数调整机制,根据任务的复杂度和模型的推理状态实时优化熵阈值。
- 通过强化学习优化Cold Stop参数,使其能够自适应不同的推理场景。
3. 基于论文的内容和研究结果,提出的创新点或研究路径:
创新点一:连续概念空间的多模态推理扩展
探索Soft Thinking在多模态任务中的应用,例如图像与文本结合的推理任务,通过联合概念空间实现跨模态推理。
创新点二:动态推理模式切换机制
设计一种智能推理框架,根据任务需求动态切换离散推理与连续推理模式,优化模型的性能和效率。
创新点三:连续概念空间的任务特定微调
开发一种任务特定的微调方法,使模型能够更好地适应连续概念空间推理,提升在复杂任务中的表现。
4. 为新的研究路径制定的研究方案:
研究路径一:连续概念空间的多模态推理扩展
研究方法:
- 目标: 将Soft Thinking应用于多模态任务(如视觉问答或图像生成)以验证其跨模态推理能力。
- 步骤:
- 构建多模态数据集,包括图像和文本的联合表示。
- 在模型推理阶段引入图像嵌入,结合文本嵌入形成联合连续概念空间。
- 设计实验,比较Soft Thinking与传统多模态推理方法的性能。
- 期望成果:
- 验证Soft Thinking在多模态任务中的有效性。
- 提供一种统一的跨模态推理框架,提升多模态任务的准确性和效率。
研究路径二:动态推理模式切换机制
研究方法:
- 目标: 设计一种智能推理框架,根据任务需求动态切换离散推理与连续推理模式。
- 步骤:
- 引入任务复杂度指标,用于评估任务是否适合连续推理。
- 在推理过程中实时监测模型的熵值和生成状态,动态调整推理模式。
- 通过强化学习优化模式切换策略。
- 期望成果:
- 提供一种灵活的推理框架,适应不同任务需求。
- 在复杂任务中显著提升推理准确性和效率。
研究路径三:连续概念空间的任务特定微调
研究方法:
- 目标: 开发一种任务特定的微调方法,使模型能够更好地适应连续概念空间推理。
- 步骤:
- 在模型训练阶段引入概念嵌入的微调任务。
- 使用任务数据集对模型进行微调,优化模型对连续概念空间的适应性。
- 验证微调后的模型在复杂任务中的表现。
- 期望成果:
- 提升模型在复杂任务中的表现。
- 提供一种高效的微调方法,增强模型的适应性和稳定性。
以上分析与方案旨在深入挖掘Soft Thinking方法的潜力,并为未来研究提供明确方向与可行路径。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!