目录
Resource Info Paper http://arxiv.org/abs/2507.18071 Code & Data / Public arXiv Date 2025.08.07
Summary Overview
作者认为在 GRPO 中的重要性采样仅仅是在 token-level 进行计算,这样会造成对于 LLM RL 训练的不稳定,尤其是对于 MoE 模型来说。作者重写了重要性采样的计算方式,使其变成 sequence-level 的计算。
Main Content
GRPO 在训练大语言模型时可能会出现训练不稳定的问题,通常会导致模型崩溃等问题。在本文中,作者将这种不稳定醒归结于源于 GRPO 算法中的重要性采样权重的错误使用和无效。这在训练中引入了噪声,并且该噪声会随着响应长度的增加而逐渐积累,并通过裁剪机制进一步扩大,最终导致模型塌陷。
Motivation
The growth in model size, sparsity (e.g., in Mixture-of-Experts models), and response length necessitates a large rollout batch size to maximize hardware utilization during RL. To improve sample efficiency, it is standard practice to partition a large batch of rollout data into multiple mini-batches for gradient updates. This procedure inevitably introduces an off-policy learning setting, where responses are sampled from an old policy rather than the current policy being optimized. This also explains the necessity of the clipping mechanism in PPO and GRPO, which prevents overly "off-policy" samples from being involved in gradient esstimation.
While mechanisms like clipping aim to manage this off-policy discrepancy, we identify a more fundamental issue in GRPO: its objective is ill-posed. This problem becomes particularly acute when training large models on long-response tasks, leading to catastrophic model collapse. The ill-posed nature of the GRPO objective stems from a misapplication of importance sampling weights. The principle of importance sampling is to estimate the expectation of a function under a target distribution by re-weighting samples drawn from a behavior distribution :
Crucially, this relies on averaging over multiple samples () from the behavior distribution for the importance weight to effectively correct for the distribution mismatch.
In contrast, GRPO applies the importance weight at each token position . Since this weight is based on a single sample from each next-token distribution , it fails to perform the intended distribution-correction role. Instead, it introduces high-variance noise into the training gradients, which accumulates over long sequences and is exacerbated by the clipping mechanism. We have empirically observed that this can lead to model collapse that is often irreversible. Once the collapse occurs, resuming training is unavailing, even when reverting to a previous checkpoint and meticulously tuning hyperparameters (e.g., the clipping ranges), extending generation length, or switching the RL queries.
The above observation suggests a fundamental issue in GRPO's design. The failure of the token-level importance weight points to a core principle: the unit of optimization objective should match the unit of reward. Since the reward is granted to the entire sequence, applying off-policy correction at the token level appears problematic. This motivates us to forego the token-level objective and explore utilizing importance weights and performing optimization directly at the sequence level.
Therefore, GSPO applies clipping to entire responses instead of individual tokens to exclude the overly "off-policy" samples from gradient estimation, which matches both the sequence-level rewarding and optimization.
与 GRPO 不同的是,GSP 对于一个 response 中的所有 token 都使用统一的 weight。
同时,为了丰富的扩展性,作者还提出了一个 token-level 级别的 Loss: GSPO-token.
代表着停止梯度 (stop the gradient)。
GSPO-token and GSPO are numerically identical in the optimization objective, clipping condition, and theoretical gradient when we set the advantages of all the tokens in the response to the same value (i.e., ), while GSPO-token enjoys the higher flexibility of adjusting the advantages per token.
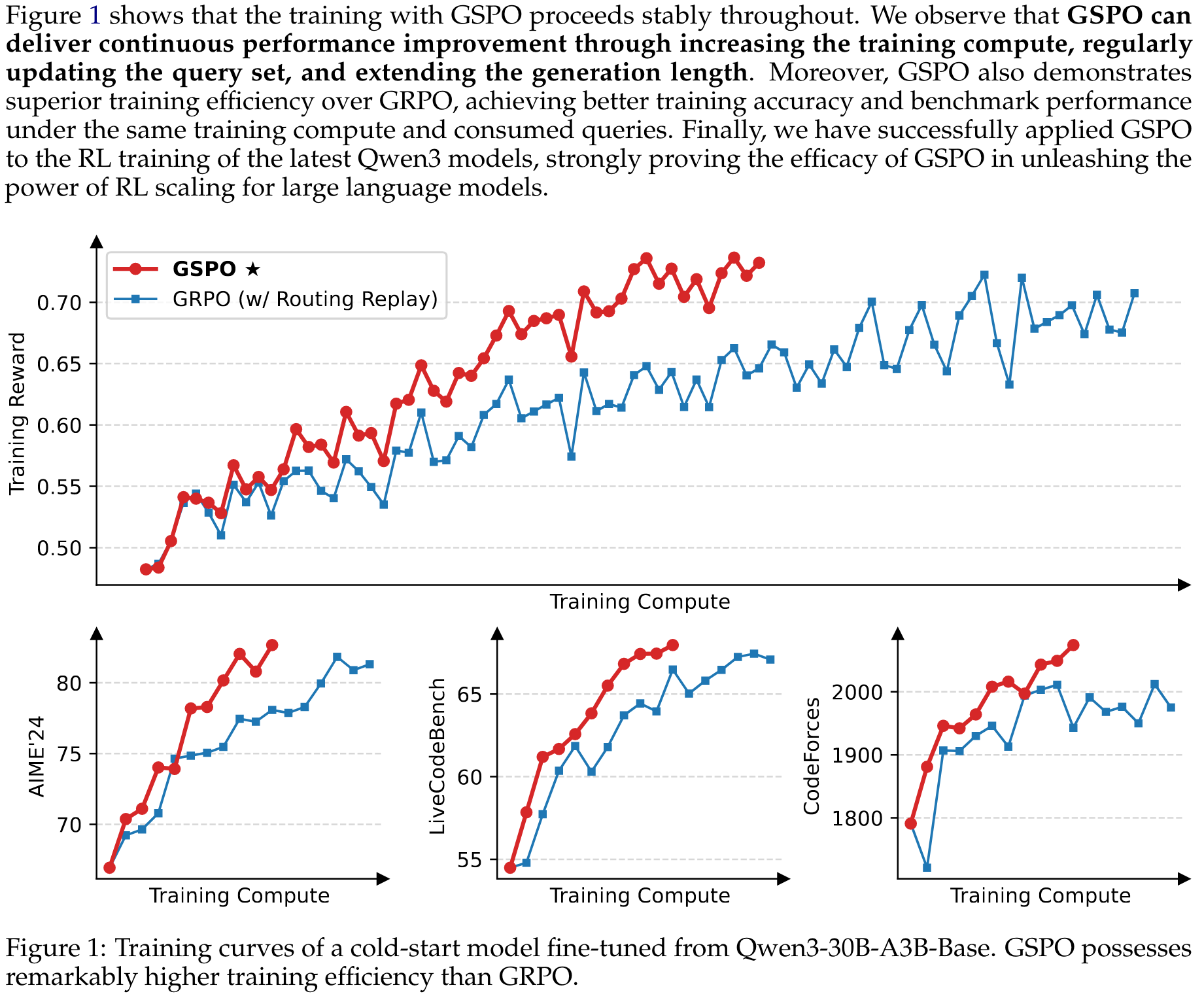
Benefit of GSPO for MoE Training
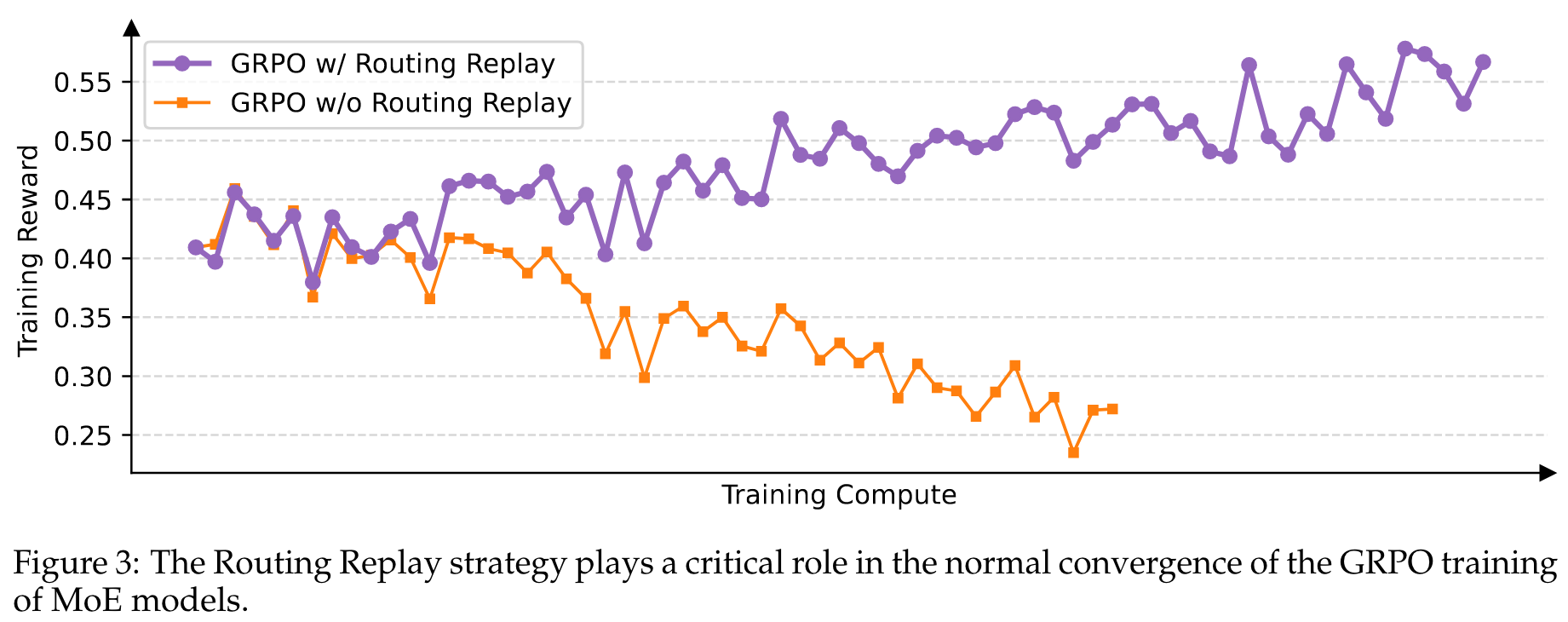
与密集模型的强化学习训练相比,MoE模型的稀疏激活特性引入了独特的稳定性挑战。特别地,我们发现当采用 GRPO 算法时,MoE模型的 expert-activation volatility 会阻止强化学习训练正常收敛。具体而言,经过一次或多次梯度更新后,针对同一响应激活的专家可能会发生显著变化。例如,对于48层的Qwen3-30B-A3B-Base模型,在每次强化学习梯度更新后,对于同一个rollout样本,新策略下激活的专家与旧策略下激活的专家大约有10%的差异。这种现象在更深的MoE模型中变得更加突出,使得token级重要性比率剧烈波动并进一步使其失效,如第3节和第4.2节所讨论的,从而阻碍了强化学习训练的正常收敛。
为了解决这一挑战,我们之前采用了 Routing Replay 训练策略。具体而言,我们缓存中激活的专家,并在计算重要性比率时在中"重放"这些路由模式。通过这种方式,对于每个token ,和共享相同的激活网络,从而我们可以恢复token级重要性比率的稳定性,并确保在梯度更新过程中一致激活网络的优化。图3表明路由重放是MoE模型GRPO训练正常收敛的一项关键技术。
The key insight is that GSPO focuses only on the sequence likelihood (i.e., ) and is not sensitive to the individual token likelihood (i.e., ).
🤖
-
论文的创新之处与独特性:
- 创新算法设计:GSPO
论文提出了Group Sequence Policy Optimization (GSPO)算法,基于序列级别的重要性比率进行优化,取代了传统的基于token级别的重要性比率的设计。这种设计解决了GRPO算法中由于token级别权重波动导致的训练不稳定问题。 - 稳定性与效率提升
GSPO通过序列级别的裁剪和奖励机制,在训练稳定性和效率方面显著优于GRPO。尤其是在训练Mixture-of-Experts (MoE)模型时,GSPO完全消除了复杂稳定化策略的需求,简化了强化学习架构。 - 应用与性能改进
GSPO成功应用于Qwen3模型的强化学习训练,显著提升了模型性能,证明了该算法在大规模语言模型训练中的可扩展性和有效性。 - 基础理论的支持
GSPO基于序列似然性的重要性比率设计,理论上与重要性采样的基本原理一致,为优化目标提供了坚实的数学基础。
- 创新算法设计:GSPO
-
论文中存在的问题及改进建议:
- 序列级别裁剪的适用范围
虽然GSPO在序列级别裁剪上表现优异,但在多轮对话或复杂任务中可能需要更细粒度的控制。建议进一步研究GSPO-token变体的实际表现,以确保其在多样化任务中的适用性。 - 实验覆盖范围有限
实验主要集中在Qwen3模型和几个基准数据集上,缺乏对其他模型架构(如Transformer变体)和更广泛任务的验证。建议扩展实验范围,测试GSPO在其他语言模型和任务中的适用性。 - 裁剪范围的敏感性分析不足
论文未详细探讨裁剪范围对训练效率和稳定性的影响。建议增加对裁剪范围(如左剪和右剪阈值)的敏感性分析,以优化参数选择。 - 对推理效率的讨论较少
虽然GSPO减少了训练引擎与推理引擎之间的精度差异问题,但未深入分析其对推理效率的影响。建议进一步研究GSPO如何在推理阶段优化计算资源。
- 序列级别裁剪的适用范围
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 研究路径1:GSPO-token的优势与局限性分析
探索GSPO-token在多轮对话和复杂任务中的表现,分析其在细粒度奖励调整上的潜力与局限。 - 研究路径2:跨模型架构的GSPO适用性研究
在不同架构(如GPT、BERT及其变体)上实现GSPO,评估其在不同任务(如问答、生成、推理)中的性能。 - 研究路径3:基于GSPO的动态裁剪策略
设计一种动态裁剪机制,根据任务复杂度和响应长度实时调整裁剪范围,以进一步提升训练效率和模型性能。
- 研究路径1:GSPO-token的优势与局限性分析
-
为新的研究路径制定的研究方案:
-
研究路径1:GSPO-token的优势与局限性分析
- 研究方法
在多轮对话任务(如对话生成、情感分析)中,分别应用GSPO和GSPO-token算法,比较两者的训练稳定性、效率和生成质量。 - 研究步骤
- 使用标准对话数据集(如MultiWOZ)进行模型训练,记录训练曲线和奖励变化。
- 通过人工评价和自动评价(如BLEU、ROUGE)评估生成质量。
- 分析GSPO-token在奖励调整上的灵活性及其对模型性能的影响。
- 期望成果
证明GSPO-token在细粒度奖励调整上的优势,明确其适用场景和局限性,为未来任务设计提供指导。
- 研究方法
-
研究路径2:跨模型架构的GSPO适用性研究
- 研究方法
在不同语言模型架构(如GPT、BERT、Transformer-XL)上实现GSPO,测试其在问答、生成、推理任务中的性能。 - 研究步骤
- 使用多个基准数据集(如SQuAD、WikiText、GLUE)训练模型。
- 比较GSPO与传统RL算法(如PPO、GRPO)的训练效率和稳定性。
- 分析GSPO在不同架构上的适配性及其对任务性能的影响。
- 期望成果
证明GSPO的跨架构适用性,为其推广到更多任务和模型提供理论与实践支持。
- 研究方法
-
研究路径3:基于GSPO的动态裁剪策略
- 研究方法
设计一种动态裁剪机制,根据响应长度和任务复杂度实时调整裁剪范围,优化GSPO的训练效率。 - 研究步骤
- 基于现有GSPO算法,开发动态裁剪模块,集成到训练流程中。
- 在不同任务(如代码生成、数学推理)中测试动态裁剪策略的效果。
- 比较动态裁剪与固定裁剪范围的效率和性能差异。
- 期望成果
动态裁剪机制显著提升GSPO的训练效率,减少裁剪对训练样本的影响,为复杂任务提供更精确的优化方法。
- 研究方法
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!