目录
Resource Info Paper https://arxiv.org/abs/2402.18191 Code & Data https://github.com/IronBeliever/CaR Public ArXiv Date 2024.04.01
Summary Overview
鉴于训练和评估模型需要大量的资源分配,拥有一种有效的方法来选择高质量的 IT 数据是有利的。在本文中,我们提出了一种工业友好型、专家对齐且保留多样性的指令数据选择方法:聚类和排序(Cluster and Ranking, CaR)。
第一步涉及使用与专家偏好非常一致的评分模型对指令对进行排名(准确度达到 84.25%)。第二步涉及通过聚类过程保留数据集多样性。
Main Content
大型语言模型 (LLM) 通过称为指令调优 (IT) 的过程获得遵循指令的能力(Radford 等人,2019;Brown 等人,2020;Zhang 等人,2023),从而弥合了下一个语言模型之间的差距。 - 单词预测和遵守用户提供的说明。
然而,必须注意的是,自指令框架内的过滤阶段主要关注指令结构的完整性和相似性,无意中忽视了关键的指令质量。
从这个角度来看,Alpagasus(Chen et al., 2023)利用 GPT-3.5 Turbo 过滤了大约 9k 条评级为 4.5 或更高的指令,超越了 Alpaca 的性能。
Contributions:
- 我们引入了指令对质量估计(IQE),这是 IT 流程的一个新阶段,旨在利用指令数据集的评估结果来辅助语言模型的实际微调和基准评估,从而减少语言模型的时间和计算费用。 IT 流程中的模型性能验证超过 90%。
- 我们提出了一种新颖的 IT 数据集质量评估范式,该范式独立于外部 API,并且非常符合人类专家的偏好。如表 1 所示,与 GPT-4 Turbo 相比,我们的小型指令对质量评分 (IQS) 模型在符合人类对数据质量的偏好方面实现了 21.05% 的改进。
- 我们提出了 CaR,一种与专家见解相一致并保留多样性的指令选择方法,展示了模型性能和训练效率的显着增强。如图 1 所示,CaR 使用小模型来过滤高质量的指令数据,仅使用 1.96% 的指令子集,在 Alpaca_52k 数据集上实现了超过 Alpaca 约 13.3% 至 32.8% 的平均性能。这意味着培训时间和资源减少了 98%。
从质量估计到指令对质量估计
我们的目标是首先使用 IQE 对大量指令进行粗略筛选,然后用最少的数据集细化和选择最佳的 LLM,以降低指令过滤和验证所涉及的总计算费用。
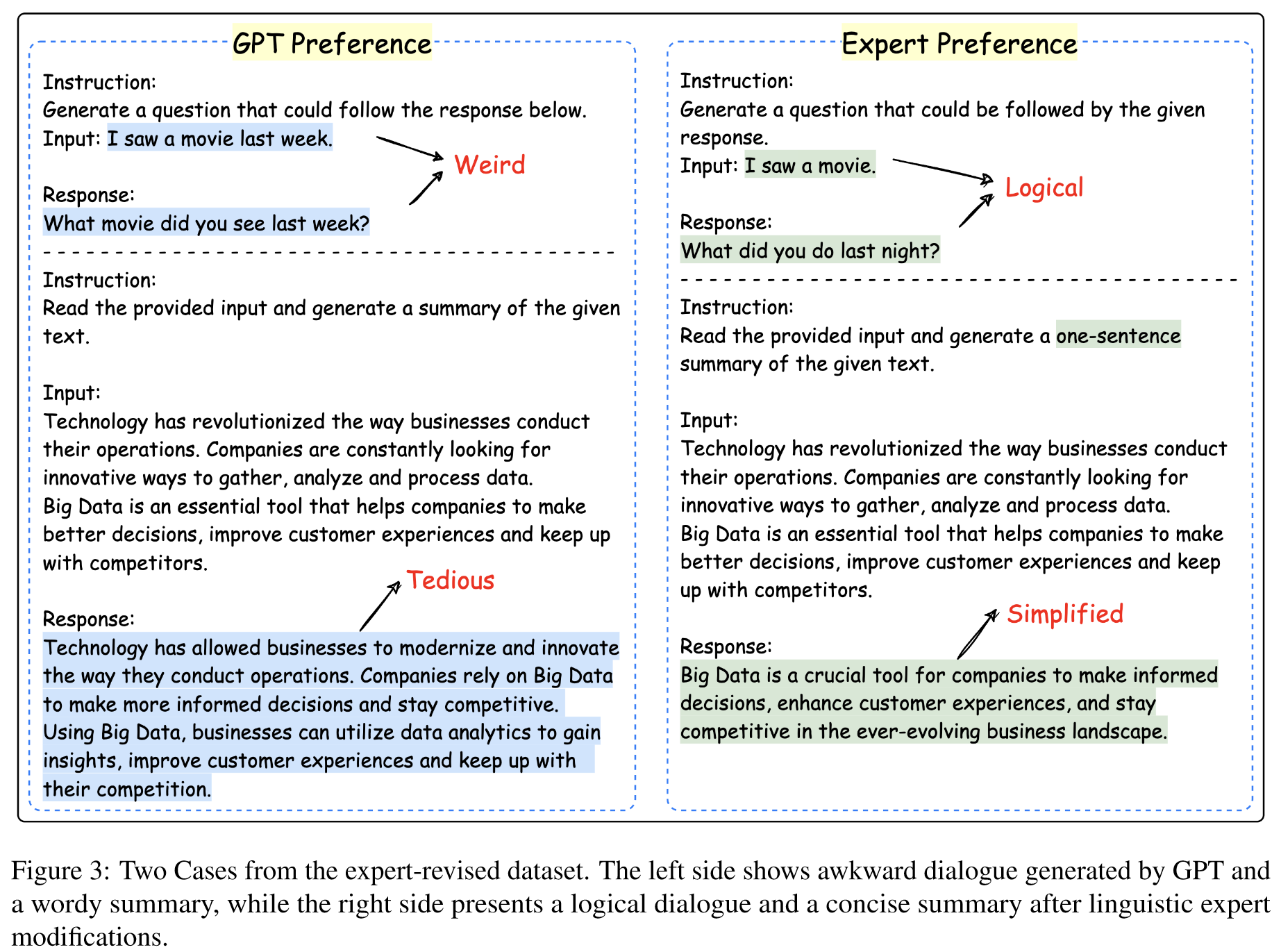
GPT 作为法官表现出系统偏见 在需要人类偏好的场景中
研究人员发现GPT-4的评估存在系统性偏差,包括位置偏差、冗长偏差和自我增强偏差。
教学多样性激发LLMs的多任务能力
在资源匮乏的情况下,混合来自不同任务的这些指令可以增强LLM的能力。
受到周等人的启发。 (2023),我们首先选择一个确保保留大量高质量指令的子集,然后从每个簇中补充少量高质量指令,以在保持指令质量的同时增强数据的多样性。如图2所示,最初,整个数据集通过IQS模型进行评估,为每个指令对分配一个scorei。随后,采用聚类模型将所有候选指令对聚类成k个聚类。最后,将所有指令对按照得分进行排序,选出前n1对;在每个簇内,指令对按分数排序,并选择前 n2 对。然后通过对 n1+k*n2 对指令进行重复数据删除来生成具有保留多样性的高质量子数据集。这个精炼的数据集旨在用于 AlpaCaR 的训练。
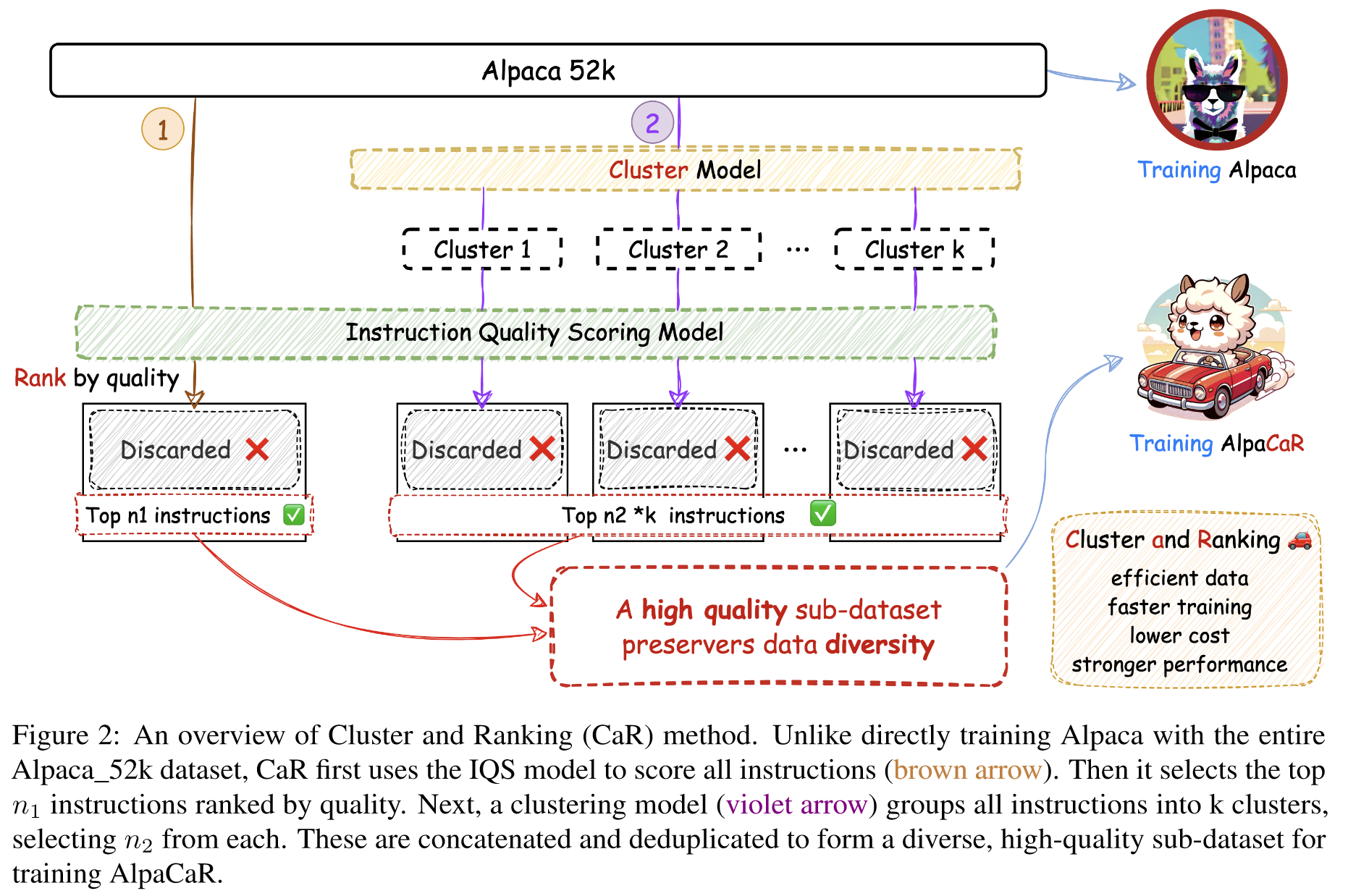
Diversity
混合来自不同任务的训练数据可以提高LLMs跨不同能力的熟练程度。
直观上,通过为每个指令对分配任务标签,我们可以保留与更广泛的任务相关的指令对,从而促进跨任务指令协同并增强模型性能。
为了增强该方法的多功能性,我们选择了基于无监督聚类的方法来保留数据多样性。聚类算法可以识别语义空间中相邻的指令对,并为不同的任务形成簇。此外,这种选择允许有效地适应不同的数据集,而无需在遇到域外指令对时通过形成新的集群来从头开始重新训练。
在聚类方法方面,我们采用k-Means算法。从 SentenceTransformers 模型开始,句子被映射到 384 维密集向量空间。随后,应用 PCA 来降维,同时保留 95% 的主成分。最后,设置簇数为k=pn/2,所有52k指令对被簇为178个簇。通过调整每个簇内指令对的数量来维持指令子数据集的多样性。
尽管 CaR 在多个测试集上表现出色,但其实验仅限于在 Alpaca_52k 数据集上进行过滤。不同开源指令集的不同格式给对指令过滤任务感兴趣的学术界带来了挑战。未来,我们计划在 WizardLM_evol_instruct_70k (Xu et al., 2023) 和 databricks-dolly-15k (Conover et al., 2023) 等数据集上验证 CaR 的有效性。此外,虽然CaR主要用于单轮对话指令过滤,但探索其在多轮对话指令过滤中的应用为未来的研究提供了一个有吸引力的方向。
Experiments
Metrics
对于每个样本,判断模型都会输入一条指令和由不同模型生成的两个候选响应,并需要标记哪个响应是获胜者,如果两者都显着突出,则标记为平局。为了解决 LLM 法官偏爱特定职位的潜在偏见,我们通过交换响应顺序对结果进行了两次测试,并根据以下因素定义了最终判决:
-
win: 获胜两次,或获胜一次平局一次
-
lose:输两次,或者输一次打平一次
-
ties:平局两次,或胜一次负一次
Models
evaluation model:
- GPT-4-Turbo
- PandaLM
Datasets
才用四个数据集进行评估,以达到覆盖更广泛的指令,从而最大限度地减少评估偏差。
- Self-instruct
- Vicuna
- PandaLM
- Vicuna
Baselines
Alpaca
Results
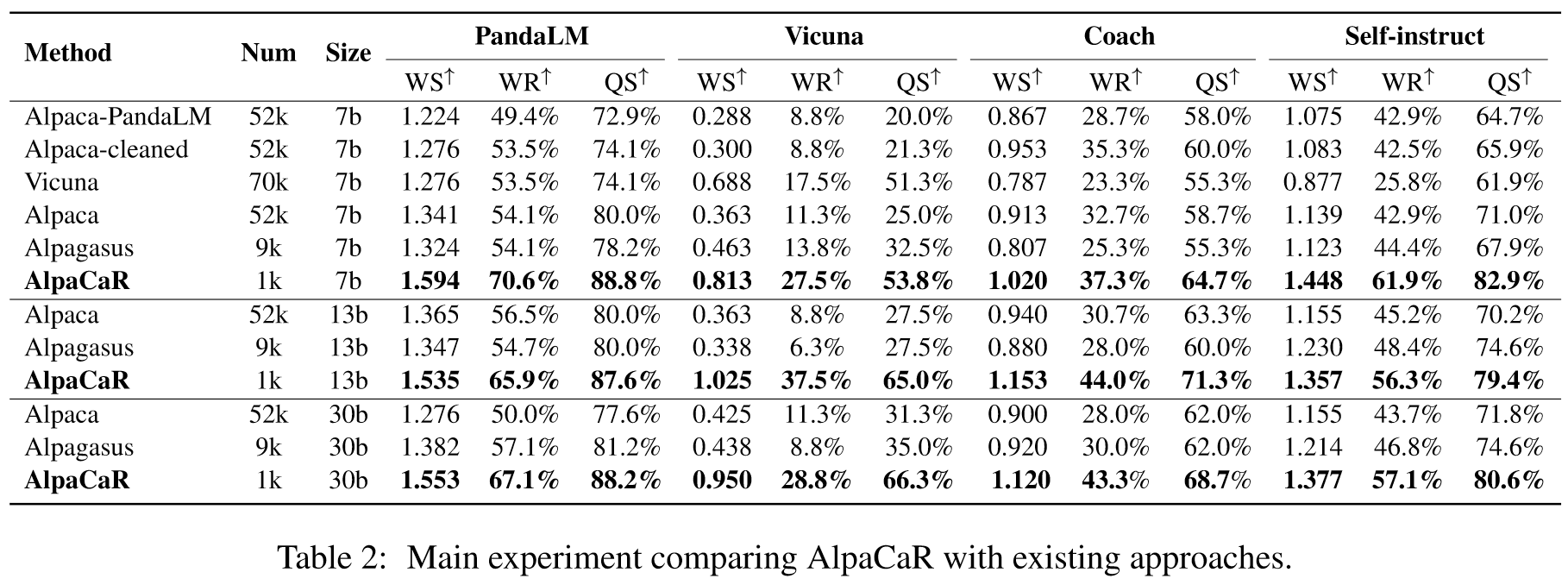
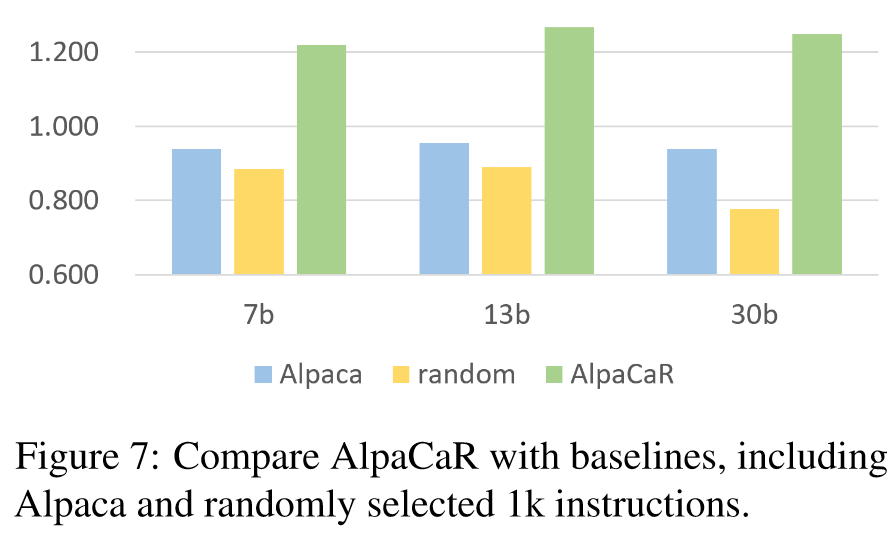
如表 2 所示,AlpaCaR 在 7B 尺度上不仅优于 Alpaca 和 Vicuna 的基础模型,而且相对于 Alpaca-PandaLM、Alpaca-cleaned 和 Alpagasus 也表现出更优越的性能。总体而言,AlpaCaR 在 7B、13B 和 30B 尺度上比 Alpaca 实现了显着的性能改进,从而验证了 CaR 方法的有效性。与 Alpagasus 相比,AlpaCaR 的显着性能提升是通过减少数据使用来实现的,这凸显了利用高质量的人类偏好和数据多样性在增强模型性能方面的至关重要性。
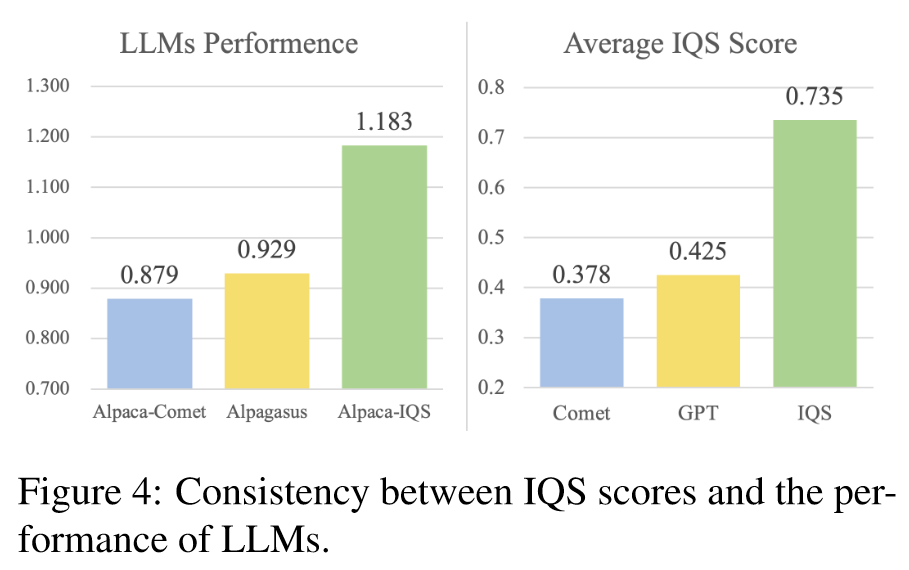

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: 本文提出了一种新的自然语言处理方法——Clustering and Ranking (CaR),旨在高效选择高质量的指令调优(IT)数据。CaR方法的显著特点在于它结合了质量评估和数据多样性保持两个维度。首先,通过与专家偏好相一致的打分模型对指令对进行排序(准确率达到84.25%),然后通过聚类过程保持数据集的多样性。在实验中,CaR方法仅选择了Alpaca IT数据的1.96%,但训练出的模型在GPT-4评估中性能提升了平均32.1%。此外,CaR使用的小型模型(只有355M参数)和较低的成本使其易于在工业场景中部署。
-
论文中存在的问题及改进建议:
- 问题一:CaR方法在Alpaca_52k数据集上的测试可能无法全面反映在不同数据集上的普遍适用性。 改进建议:未来研究应在更多和不同类型的数据集上测试CaR方法,以验证其广泛适用性和鲁棒性。
- 问题二:尽管通过聚类保持了一定程度的多样性,但在选择高质量指令时可能仍存在潜在的偏差风险。 改进建议:引入更多维度的多样性评估指标,确保选取的数据在各方面都具有代表性和多样性。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点一:结合质量评估和语义聚类以及其他形式的数据增强技术(如数据扩充),以进一步提高指令数据的覆盖范围和多样性。
- 创新点二:开发新的评估方法,不仅基于专家偏好,还考虑用户行为和反馈,从而更准确地评估指令数据的实际效用。
- 创新点三:探索CaR方法在多轮对话和更复杂任务指令生成中的应用,以提高大型语言模型在多样场景中的适应性和效能。
-
为新的研究路径制定的研究方案:
- 方案一:结合质量评估和语义聚类以及数据增强
- 研究方法:开发一种整合质量评估、语义聚类和数据增强的指令数据选择框架。
- 研究步骤:首先,使用现有CaR方法筛选高质量数据;然后,通过语义聚类识别数据间的关联性;最后,应用数据扩充技术来增加稀有或未覆盖的场景。
- 期望成果:一个更加全面和多样化的高质量指令数据集,能够提高语言模型在多样任务中的表现。
- 方案二:结合专家偏好和用户行为的评估方法
- 研究方法:构建一个评估系统,该系统不仅考虑专家偏好,还结合用户行为和反馈。
- 研究步骤:首先收集和分析用户互动数据,然后结合专家评分,开发一个混合评估模型。
- 期望成果:一种更加贴近实际应用场景的指令质量评估方法,提高了数据选择的准确性和实用性。
- 方案三:在多轮对话和复杂任务中应用CaR方法
- 研究方法:探索CaR方法在多轮对话和复杂任务指令生成中的应用。
- 研究步骤:对CaR方法进行适应性调整,以处理多轮对话和复杂任务的数据;然后,在不同类型的大型语言模型上进行测试和评估。
- 期望成果:在多样化应用场景中表现出色的改进型语言模型,展示了更好的适应性和效能。
- 方案一:结合质量评估和语义聚类以及数据增强
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!