目录
Resource Info Paper https://arxiv.org/abs/2403.03187 Code & Data / Public ArXiv Date 2024.04.03
本文讲述了当前RAG的发展,值得一读。
Summary Overview
参数语言模型 (Parametric language models, LMs)经过大量网络数据训练,表现出卓越的灵活性和功能。然而,他们仍然面临着幻觉、难以适应新数据分布、缺乏可验证性等实际挑战。在这篇paper中,作者们主张使用检索增强型语言模型来取代参数型语言模型,成为下一代语言模型。通过在推理过程中合并大规模数据存储,检索增强的LM可以更加可靠、适应性强和可归因。尽管具有潜力,但由于一些障碍,检索增强语言模型尚未得到广泛采用:具体来说,当前的检索增强模型很难利用知识密集型任务(例如QA)之外的有用文本,检索和语言模型组件之间的交互有限,并且缺乏扩展的基础设施。为了解决这些问题,我们提出了开发通用增强型语言模型的路线图。这涉及到重新考虑数据存储和检索器、探索改进检索器与LM交互的管道,以及对基础设施进行大量投资以实现高效的训练和推理。
Main Content
Weakness of parametric LMs:
- the prevalence of factual errors
- the difficulty of verification
- difficulty of opting out certain sequences with concerns
- computationally expensive costs for adaptations
- prohibitively large model size
与仅在训练期间使用大规模文本数据的参数 LM 不同,检索增强 LM 通过从数据存储中选择相关文档来在推理时利用外部大规模文档集合(数据存储)
- largely reduce factual errors
- provide better attributions
- enabling flexible opt-in and out of sequences
- easily adapt to new distributions
- more parameter-efficient
Challenges in the future:
- 现有方法主要利用与输入具有高度语义或词汇相似性的上下文,当公共数据存储中缺少有用的文本或与传统的相关性定义不符合时就会陷入困境。
- 将检索到的文本添加到最近广泛使用的现成语言模型组件之间的浅层交互。这通常会导致不受支持的生成、对不相关文本的敏感性以及处理来自多个文本片段的信息的挑战。
- 与parametric LM的高效训练和推理的快速进展不同,大规模提高检索增强LM的训练和推理效率的研究和开源工作有限。
作者们提出的未来的研究路线:
- 为了解决不同任务找到有用文本的挑战,重新考虑相关性概念并加深我们对有效数据存储的构成的理解非常重要,特别是探索应从各种数据存储中检索信息类型更广泛任务的效果
- 确保两个组件之间更深入交互的方法,包括架构、预训练和训练后适应,而不是专注于现有parametric LM的补充增强
- 对于扩展的挑战,呼吁在硬件、系统和算法方面进行更多开源和跨学科的努力,以开发用于训练和推理的基础设施(例如,将数据存储扩展至万亿token)
通过探索这些途径,我预计将释放检索增强型LM的全部功能,并将应用扩展到一系列任务和领域。
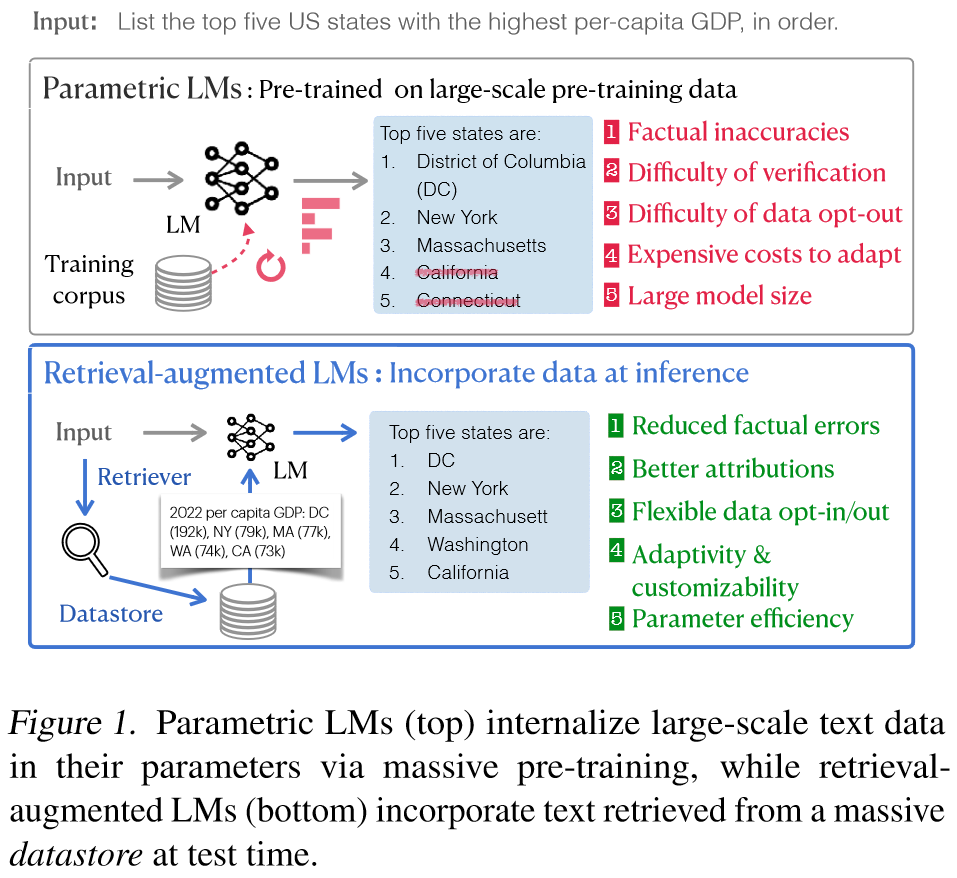
How Far Can We Go with Parametric LMs?
Definition: Parametric LM由一组参数组成。给定来自大规模文本数据集的输入序列,训练可学习参数来预测未来或屏蔽标记的概率。在测试期间,对于输入序列,经过训练的预测输出:,而无需访问当前任务之外的任何外部数据。
Weakness of Parametric LMs
- W1: Factual inaccuracies
- 试图记住参数内所有学到的知识可能会导致事实不准确(幻觉)。最近的几篇论文报告称,即使是ChatGPT等最先进的LM在其大部分输出中也会表现出幻觉。研究表明,LMs特别难以处理长尾知识(在预训练期间较少代表的事实知识),并且扩展只能带来微笑改进。并且发现在指令调整期间增加合成标记数据可能不会提高模型输出的真实性。
- W2: Difficulty of verifications
- 不仅LM在生成中表现出了产生幻觉的倾向,而且由于缺乏明确的归属或出处,从业者也很难对他们的输出进行事实核查。强大的LM的输出通常冗长、自信且可信,这使得事后归因或事实验证成为具有挑战性且基本上未解决的任务。
- W3: Difficulty of opting out certain sequences from the datasets
- 管理大量的预训练数据在识别和过滤具有潜在隐私或受版权保护的数据的训练实例方面提出了相当大的挑战。最近的工作研究了安全工作、遗忘或删除某些数据后对语料库模型进行迭代预训练。然而,缺乏适当的归因使这些努力进一步复杂化,因为追溯和消除特定的训练实例变得非常重要。
- W4: Computationally expensive costs to adapt
- 在静态未标记文本(即在某一时间从网上手机的文字)上训练Parametric LMs需要持续训练或昂贵的适应新数据分布的过程。例如,他们的参数知识很快就会过时。虽然有几种方法提出查找二号编辑某些过时的知识或进行有效的持续训练从而达到跟上世界的步伐,但这些方法需要额外的计算成本高昂的学习过程。在广泛采用的预训练语料库上进行训练的语言模型通常在新闻文章等通用领域表现良好,但在专家领域表现不佳。先前的工作证明了持续预训练或指令调整的有效性,尽管计算成本相当大并且可能发生灾难性遗忘。
- W5: Prohibitively large model size
- 大量研究展示了模型扩展对任务效果的积极影响,以及回忆从训练数据中记忆的事实知识的能力。这一趋势促使社区专注于提高模型大小以追求更好的性能,但代价是巨大的。尽管努力提高效率,但托管这些通常超过千亿个参数的大模型依然不切实际。
How Can Retrieval-Augmented LMs Address These Issues?
Definition: 检索增强LM,通常由两个关键部件组成:检索器和参数化LM。检索器基于数据存储中的文档构建搜索索引。在推理时间内,给定输入序列,检索器利用索引。在推理时间内,给定序列,检索器利用索引。随后LM 使用原始提示和检索到的文本来预测输出。
对检索增强的LM的看法发生了转变,而不是从头开始训练检索增强型LM,一些工作补充性地将检索集成到现有强大的参数化LM之上,而无需任何额外的培训。
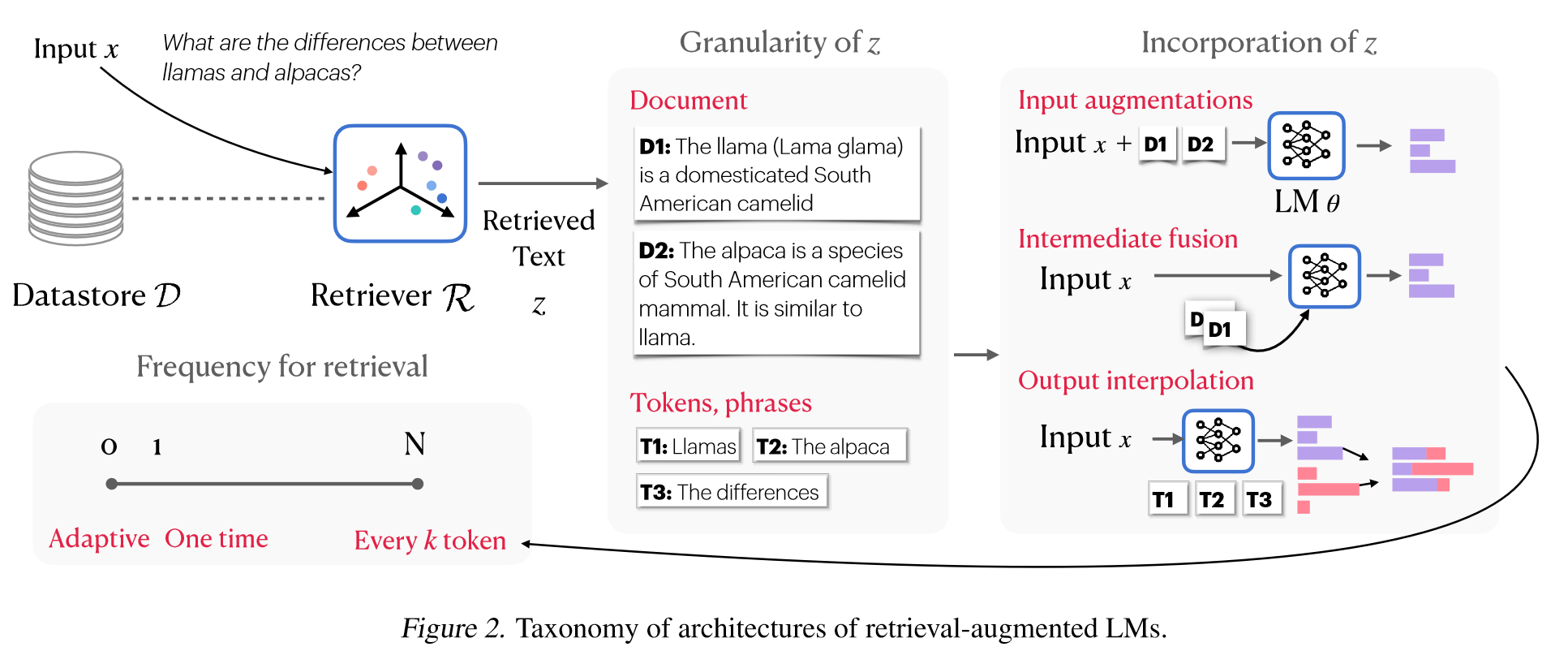
Effectiveness of Retrieval-Augmentede LMs
- W1: Reduced factual errors in long-tail knowledge.
- 最近的研究表明,检索增强的LM可以通过明确捕获长尾知识来缓解参数记忆的缺点。因此,检索增强型语言模型可以最大限度地减少幻觉并提高生成输出的真实性。
- W2: Better attributions.
- 检索增强的LM提供推理期间使用的检索结构,这可以帮助从业者手动检查模型输出的正确性或自动检查模型输出的正确性。另一种验证方法是给定模型输出进行事后归因,检索支持的文档。先前的工作发现检索增强的LM在推理时使用证据提供比事后归因更准确的归因。
- W3: Enabling flexible opt-in of sequences
- 通过改进的归因和适应性强的数据存储更新,检索的LM为与海量训练数据相关的问题提供了一些有效的解决方案。增强的归因使从业者能够从数据存储中排除特定序列,从而降低逐字生成他们的风险。此外,仅在推理过程中集成数据存储仍然允许检索增强的LM跨未包含在训练数据中的域保持性能。
- W4: Adaptability and customizability
- 数据存储的分离和可互换性可以更好地定制特定领域、应用程序和时间戳,而无需额外的培训。最近的工作表明,检索增强甚至可以由于在QA下游数据上微调的LM。这种领域适应的有效性也在非知识密集型任务中得到了发现,包括机器翻译。
- W5: Parameter efficiency
- 通过减轻记忆模型参数中所有知识的负担,检索增强型LM通常表现出强大的参数效率,具有更少参数的检索增强LM可以胜过更大的参数LM。
Why Haven't Retrieval-Augmented LMs Been Widely Adopted?
Current State of Retrieval-Augmented LMs
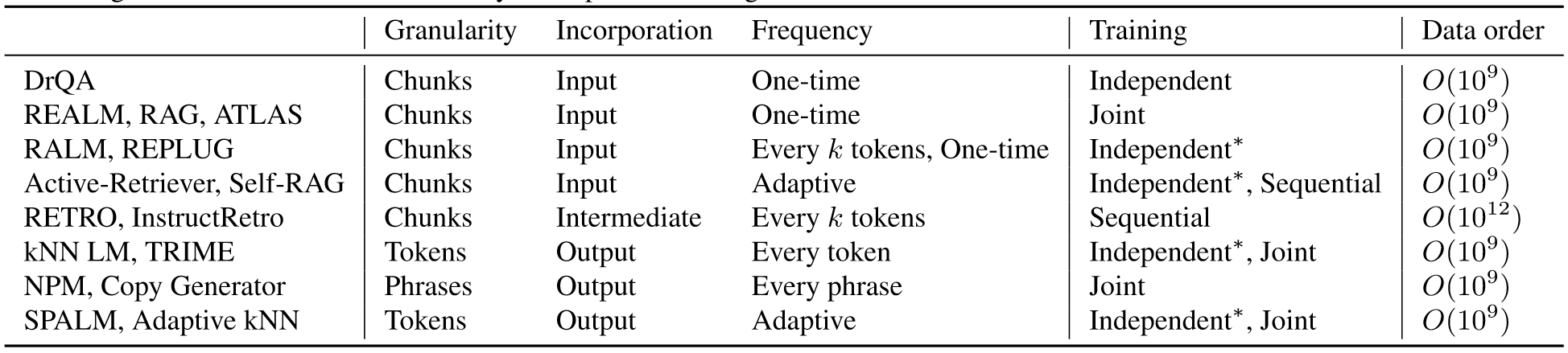
本质上,检索增强的语言模型架构可以分为以下三组:
-
Input augmentation:
输入增强在 LM 的输入空间中使用检索结果增强原始输入并运行标准LM推理。正如 Chen 等人的开创性工作一样,输入增强可以灵活地插入不同模型的检索和 LM 组件。许多广泛采用的模型,包括那些用现成的检索器增强强大的语言模型的模型,大多属于这一类。这种方法的一个显着瓶颈是冗余和低效率。在输入空间中对许多文档进行编码会导致上下文长度窗口限制,并以指数方式增加推理成本。虽然 FiD等一些工作探索并行编码来克服这种低效率,但它仍然对每个输入进行重复编码。
-
Intermediate fusion
为了以更具可扩展性的方式集成检索结果,RETRO引入了一种新的注意力机制,该机制采用许多独立于查询的预编码文本块,并同时将它们合并到中间空间中。 RETRO++和 InstructRetro证明了该方法在较大的仅解码器LM之上的有效性。然而,中间融合的一个缺点是需要对新编码块进行广泛的架构修改和LM预训练,这可能会限制广泛采用。
-
Output interpolation
输入增强和中间融合都需要 LM 从其词汇表中生成延续。相比之下,kNN LM使用检索到的令牌分布来插值参数化 LM 令牌分布,而不需要额外的训练。一些工作通过设计新的训练目标或在数据存储中的每个短语上用非参数分布完全替换参数分布来扩展这个方向.b 虽然这些方法经常证明其与语言建模中的输入增强相比的功效,但它们需要比其他两种架构大得多的索引。这是因为需要为数据存储中的所有令牌生成嵌入,从而带来了可扩展性挑战。
Training
Independent or sequential training 独立训练涉及Retriever和LM的单独开发,训练期间没有直接互动。这包括kNN LM等方法,或者最近应用于现成LM和检索系统的RAG等方法。这使得从业者能够利用现有的培训渠道和目标来增强各个组件。IR领域又丰富的文献介绍如何构建可靠且高效的IR系统。经典的基于术语的检索系统,例如TF-IDF或BM25已被广泛使用。最近,神经检索系统例如DPR或CoIBERT,已经表现出了卓越的性能。
然而,对于整个检索增强的LM流程来说,独立训练通常不是最佳选择;例如,未经检索训练的LM很容易被不相关的先前上下文分散注意力。为了缓解这个问题,顺序训练首先训练检索器或LM,然后使用来自第一个训练组件的信号来训练另一个。许多研究使用强大的预训练检索器(例如DPR、搜索引擎或冻结的预训练编码器)来训练LM组件,或者相反,使用来自LM的信号来训练检索器。
Joint training 联合训练同时训练 LM 和检索组件,以进一步优化它们的交互和端到端检索增强的 LM 管道。联合训练中的一个显着挑战是在训练期间更新检索器模型和结果索引所产生的大量计算开销。在每个时间步长为数据存储中的数百万或数十亿个文档重复生成嵌入是不切实际的。在合理的资源要求下,有两种方法可以实现此目的:使用更新的参数异步更新数据存储或使用完整数据存储的批处理近似值。异步更新是一种允许索引在更新前经过固定数量的训练步骤变得陈旧的技术,旨在在训练期间使用完整的语料库),就像在推理时间一样。更新频率和计算开销之间需要权衡:为了获得更好的性能,索引应该更频繁地更新。批内近似使用来自同一小批量的训练样本即时构建临时索引,该索引在训练期间充当完整索引的近似值。设计能够提供强训练信号的训练批次需要仔细考虑。
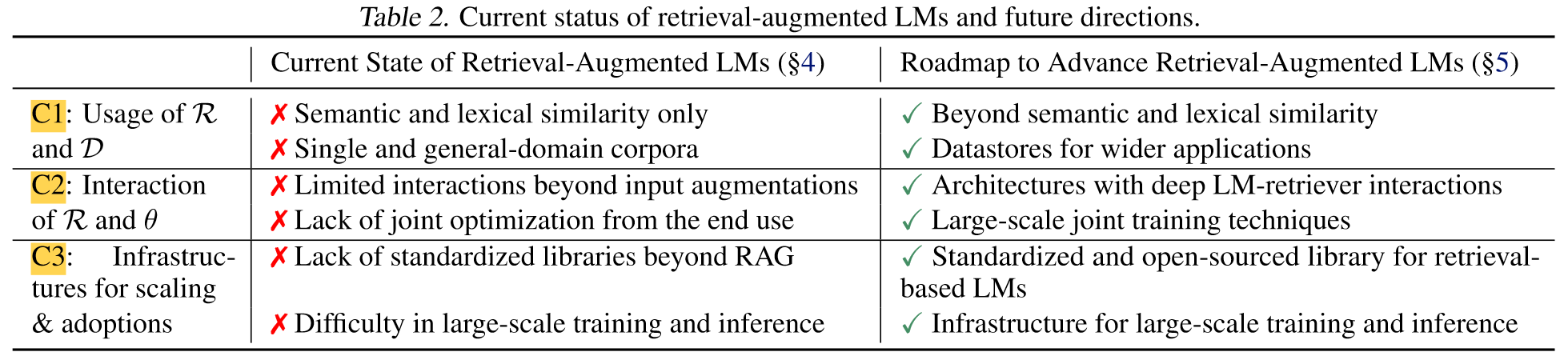
Limitations of Current Retrieval-Augmented LMs
- C1: Limitations of retrievers and datastores
- C2: Limited interactions between retrievers and LMs
- C3: Lack of infrastructure specialized for retrieval-based LMs
How Can We Further Advance Retrieval-Augmented LMs?
- Rethinking Retrieval and the Datastore
- Beyond semantic and lexical similarity
- Reconsidering and improving the datastore
- Enhancing Retriever-LM Interactions
- New architectures beyond input augmentation
- Incorporating retrieval during LM pre-training
- Further adaptation after pre-training
- Efficient end-to-end training of retrieval-augmented LMs
- Building Better Systems and Infrastructures for Scaling and Adaptation
- Scalable search for massive-scale datastores
- Standardization and open-source developments
Conclusion
本文主张将检索增强型语言模型作为下一代语言模型,以构建更可靠、适应性更强和可归因的智能系统。尽管它们比参数化 LM 有显着的优势,但它们的采用仍然有限。这种限制可能归因于对狭义形式的检索增强的关注,它简单地以事后方式结合现有的检索模型和语言模型来补充参数语言模型。我们概述了在架构、训练方法和基础设施方面从根本上推进检索增强型语言模型的路线图。我们强调跨学科合作努力实现这些进步的重要性。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!