目录
Resource Info Paper https://arxiv.org/abs/2307.06962 Code & Data https://github.com/gmftbyGMFTBY/Copyisallyouneed Public ICLR Date 2024.04.07
Summary Overview
主要文本生成模型通过固定词汇表中顺序选择单词来组成输出。在本文中,我们将文本生成表述为从现有文本集合中逐步复制文本段(例如单词或短语)。我们计算有意义的文本片段的上下文表示,并使用高效的向量搜索工具包对它们进行索引。然后,文本生成的任务被分解为一系列复制和粘贴操作:在每个时间步骤,我们从文本集合中寻找合适的文本范围,而不是从独立的词汇表中进行选择。
Main Content
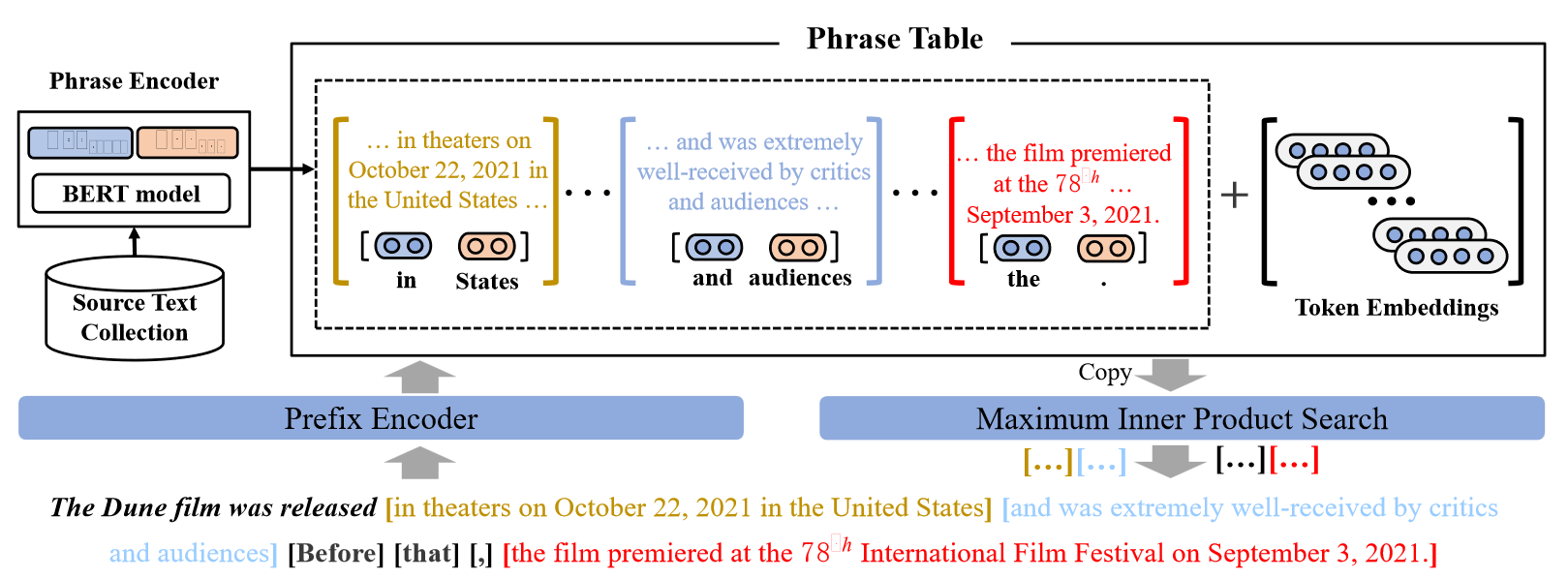
CoG (COPY-GENERATOR): 在每个解码步骤中,都会从离线索引中检索合适的短语并将其附加到当前前缀。换句话说,传统神经语言模型的下一个标记预测被一系列复制粘贴操作代替。
Advantages:
- 选择特定上下文中的短语,而不是固定词汇表中的独特标记。它可能允许更准确的候选代表和选择。
- 无需训练即可适应新的数据源,因为文本集合可以即插即用的方法更新。它可以使领域适应和数据扩展/过滤等应用场景受益。
- 允许多个标记的序列(即多词短语)在一个步骤内生成。它可以减少解码步骤的总数,从而提高推理效率。
Contributions:
- 提出了 COG,一种将文本生成任务重新表述为一系列现有文本集合的复制和粘贴操作的方法。
- 证明COG 在现有语言建模基准上可以优于标准神经语言模型基线。
- 证明 COG 允许无需训练即可适应更大的文本集合和特定领域的文本集合。
无条件文本生成(Uncoditional text generation)或语言建模(Language modeling)旨在生成给定前缀的连贯文本延续。
计算下一个token为的概率为
CoG工作流程:
假设一组原文档可用。对于每个文档,可以提取长度为的短语,其中和标记短语在文档中的开始和结束位置。我们将源文本集合中的所有短语表示为。对于给定的前缀,目标是选择可以在前缀之后形成连贯文本延续的最佳短语。为此,使用短语编码器(Phrase Encoder)计算每个短语的上下文表示。这样就可以构造一个短语表。与传统语言模型类似,在测试时,CoG也采用前缀编码器将前缀映射为向量表示。然后,短语对前缀的适合度通过其向量表示和的点积来衡量:
Prefix Encoder:
Phrase Encoder:
给定一组源文档,短语编码器计算文档中所有短语的向量表示。对于文档,首先使用bidirectional Transformer来获得上下文化的令牌表示,其中是令牌表示的维度。然后,应用两个模型和。将分别转换为开始和结束标记表示
对于文档从开始到结束的每个短语,我们使用相应的开始和结束向量的串联作为短语表示。
上述方法的优点是:
- 我们只需要对文档进行一次编码即可获得所有短语表示
- 只需要存储所有的标记表而不是所有的短语表示
通过InfoNCE损失来定义下一个短语预测的训练损失:
此外,为了保留令牌级生成的能力,我们还使用标准令牌级自回归损失来训练 COG。
在本文中,我们将文本生成重新表述为从大量文本集合中逐步复制短语。在这种形式化之后,我们提出了一种新颖的神经文本生成模型,名为 COG,它通过从其他文档中检索语义连贯且流畅的短语来生成文本。实验结果证明了 COG 相对于标准语言建模 (WikiText-103)、领域适应 (Law-MT) 和扩大短语索引 (En-Wiki) 三个实验设置的强大基线的优势。
Related Work
Dense Retrieval:
密集检索技术(Karpukhin et al., 2020)已广泛应用于许多下游 NLP 任务,例如开放域问答(Karpukhin et al., 2020; Lee et al., 2021)、开放域对话系统(Lan 等人,2021)和机器翻译(Cai 等人,2021)。与传统的稀疏检索系统(例如 BM25 和 TF-IDF(Robertson & Zaragoza,2009))不同,密集检索学习查询和文档的共享向量空间,其中相关的查询和文档对具有更小的距离(即更高的相似性) )比不相关的对。与我们的研究最密切相关的工作是 DensePhrase (Lee et al., 2021)。 DensePhrase 将问答任务重新表述为短语检索问题,其中直接检索短语并作为事实问题的答案返回。不同的是,我们的工作旨在通过多轮短语检索生成连贯的文本延续。由于在文本生成任务中两个相邻短语之间的连接必须连贯且流畅,因此难度要大得多。
Experiments
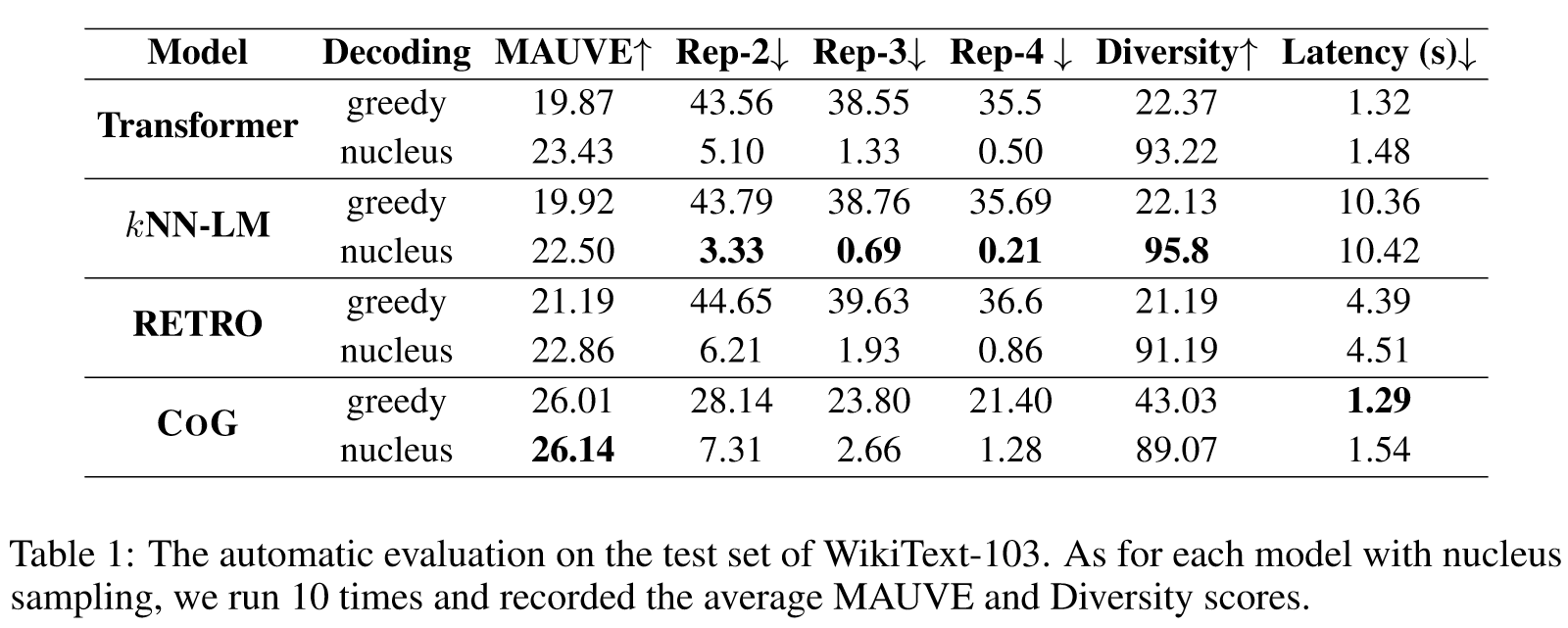
Metrics
- MAUVE:一种高效、可解释、实用的自动评估,与人类判断高度一致,广泛用于评估现代文本生成模型。在本文中,MAUVE利用GPT2large模型来生成分数,缩放因子设置为2.0。
- Rep-n:将序列级重复测量为生成文本中重复 n 元语法的部分。对于生成文本 x,Rep-n 可以表示为:。较高的Rep-n表示生成的严重的退化问题。
- Diversity:衡量世代的多样性,其公式为。多样性得分较高的生成通常信息更丰富。
Datasets
- WikiText-103
Baselines
- Transformer
- kNN-LM
- RETRO
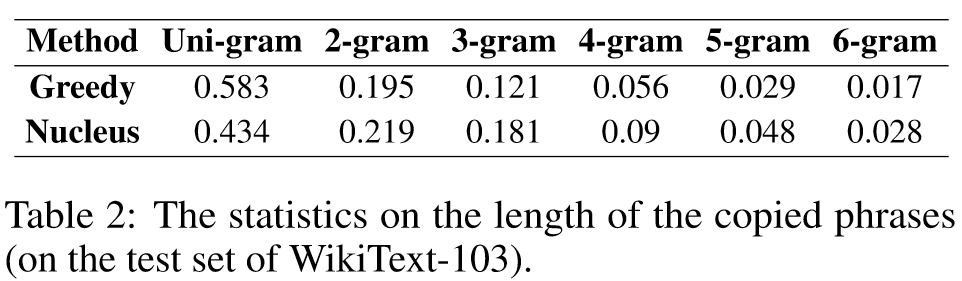
Results

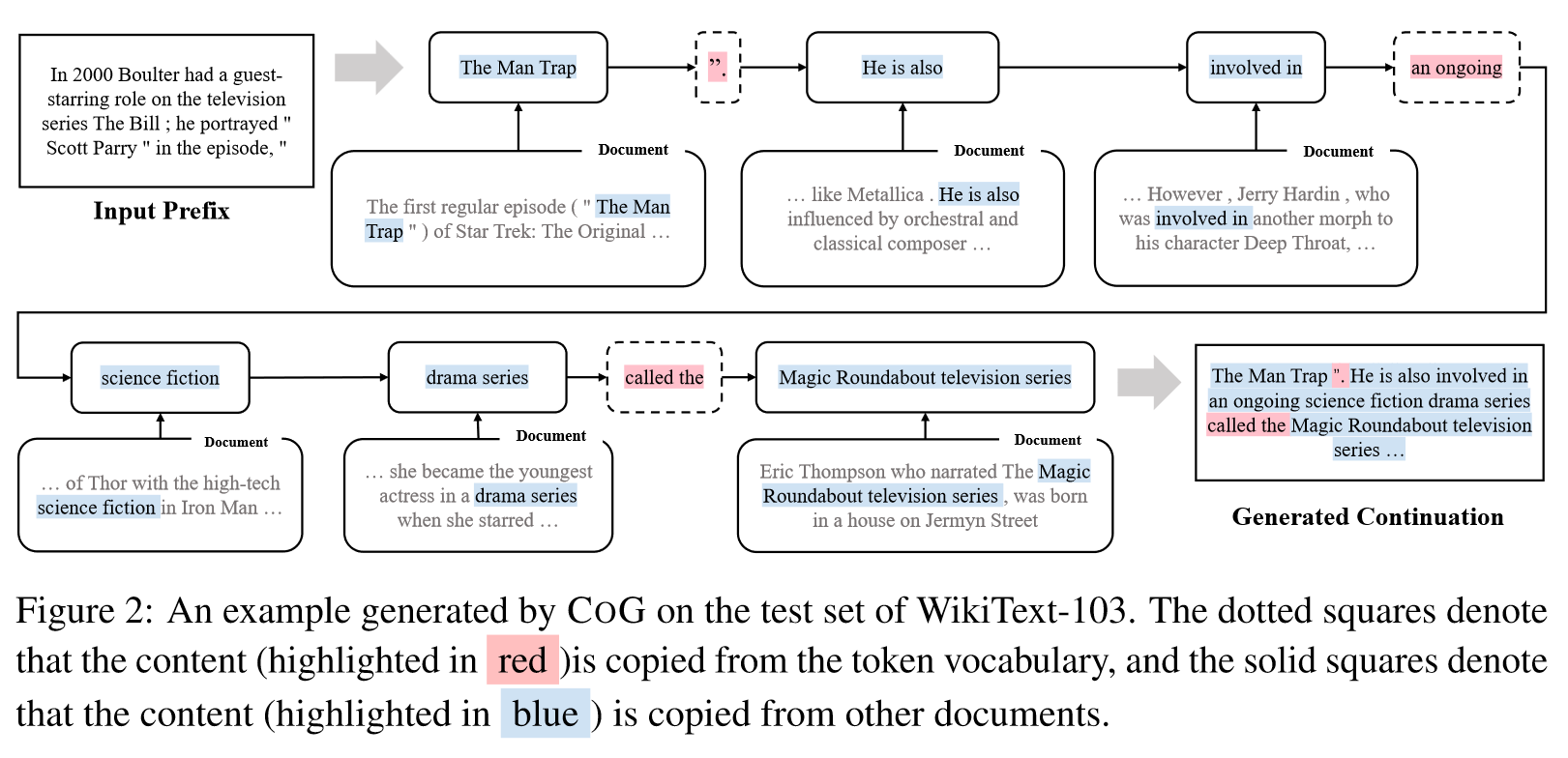
Case Study
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: 本文所研究的论文《Copy Is All You Need》中,提出了一种名为COG的新型文本生成模型,将文本生成任务重新定义为从现有文本集合中逐步复制文本片段(如单词或短语)。此模型的创新点在于它通过使用有效的向量搜索工具来计算有意义文本片段的上下文化表示,并索引它们,而不是从固定词汇表中选择单词。这种方法不仅提高了生成质量(根据自动和人类评估),还使得推理效率与令牌级自回归模型相当。此外,该模型允许通过简单切换到特定领域的文本集合来进行有效的领域适应,无需额外训练,这为文本生成提供了新的视角和技术路径。
-
论文中存在的问题及改进建议: 一方面,尽管COG模型在实验中显示出较强的性能,但其对文本片段的选择和组合仍可能导致语义上的不连贯或不精确。例如,从其他文档复制的短语可能与当前上下文不完全吻合,导致生成文本的一些部分显得生硬或不连贯。另一方面,COG在处理长篇文本时可能面临挑战,因为它需要在大量的文本片段中进行有效搜索。对此,建议进一步优化短语编码器的设计,使其能更好地理解和预测上下文中的短语,以及探索更高效的搜索算法来处理大规模文本片段集合。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 跨语言文本生成:探索COG模型在跨语言文本生成中的应用,例如在给定一种语言的上下文中生成另一种语言的文本,这可能涉及对不同语言文本片段的有效索引和选择。
- 个性化文本生成:使用COG模型进行个性化文本生成,如根据用户的历史数据和偏好来生成定制内容,这要求模型能够理解和适应不同用户的独特风格和需求。
- 多模态文本生成:结合COG模型与视觉或声音数据,探索生成与图像或音频相关联的文本,如图像描述或自动字幕生成,这要求模型能处理不同模态的数据并将它们有效融合。
-
为新的研究路径制定的研究方案:
-
跨语言文本生成:
- 研究方法:开发一种跨语言的短语索引系统,同时提升模型在不同语言上下文中选择恰当短语的能力。
- 研究步骤:首先构建一个包含多种语言的大规模文本数据库;其次,训练模型学习跨语言的短语表示;然后进行跨语言文本生成的实验,并评估其效果。
- 期望结果:生成的文本不仅在语法上正确,而且能够跨语言地传达准确的信息和情感。
-
个性化文本生成:
- 研究方法:整合用户数据,以培养模型对个体偏好和风格的敏感性。
- 研究步骤:收集用户数据,如历史文本和反馈;基于这些数据训练模型;测试模型在不同用户数据上的表现。
- 期望结果:模型能够根据用户的历史交互生成个性化、相关性强的文本内容。
-
多模态文本生成:
- 研究方法:融合视觉或声音数据处理技术,使模型能够理解并结合来自不同模态的信息。
- 研究步骤:首先,开发一种多模态数据处理框架;其次,训练模型处理和理解视觉或音频数据;最后,进行多模态文本生成实验。
- 期望结果:模型能生成准确描述图像或音频内容的文本,并保持文本的流畅性和连贯性。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!