目录
Resource Info Paper https://arxiv.org/abs/2308.12032 Code & Data https://github.com/tianyi-lab/Cherry_LLM Public NAACL Date 2024.04.07
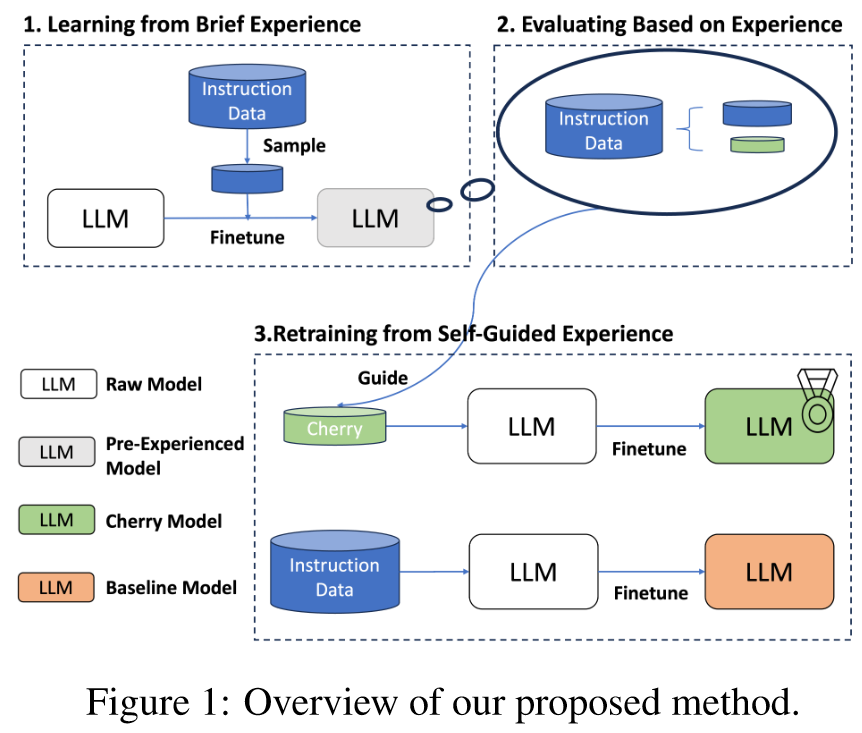
Summary Overview
在大型语言模型领域,指令数据质量和数量之间的平衡已成为焦点。认识到这一点,我们为LLM引入了一种自引导方法,可以从大量开源数据集中自主识别和选择樱桃样本,从而有效地最大限度地减少手动管理和调整LLM指令的潜在成本。我们的关键创新是指令遵循难度 (IFD) 指标,它是识别模型预期响应与其自主生成能力之间差异的关键指标。通过IFD的熟练应用,精确定位樱桃样本,模型训练效率显着提升。对 Alpaca 和 WizardLM 等数据集的实证验证支撑了我们的发现;只需传统数据输入的 10%,我们的策略就展示了改进的结果。这种自我引导的挑选和 IFD 指标的综合标志着法学硕士优化的变革性飞跃,有望实现效率和资源意识的进步。
Main Content
传统上,指令调整主要依赖于积累大量数据集。 LIMA的一项开创性启示强调了指令调整的艺术:决定模型性能的不是数据量,而是数据质量。 LIMA 的研究结果强调,即使是有限数量的手动管理的高质量数据也可以提升模型的指令遵循能力。虽然它强调了数据过剩的有效性,但如何从浩瀚的可用数据集中自动识别高质量数据的问题仍在研究中。
我们建议选择具有中等 IFD 分数的样本进行指令调整,因为这可以在解决挑战性问题和避免冗余之间取得平衡。
Contributions:
- 我们提出了一种自我引导的方法,使模型能够从大量的开源数据集中自主地“选择樱桃数据”。这项创新最大限度地减少了手动管理并优化了现有数据资源的使用,从而降低了成本并简化了培训。
- 我们引入指令遵循难度(IFD)指标作为工具来识别模型响应与其自主生成能力之间的差距。使用 IFD 指标,我们可以精确定位这些樱桃样本,从而优化模型训练效率。
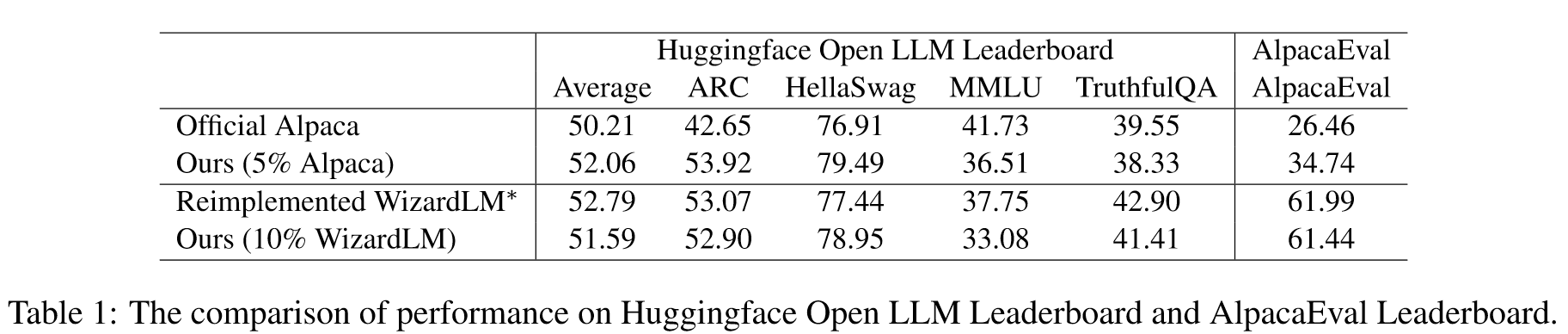
- 在 Alpaca 和 WizardLM 等数据集验证的支持下,我们的策略仅用 10% 的典型数据输入就展示了增强的结果,强调了我们方法的效率和变革性影响。
- 我们提供了不同的特定于模型的视图来衡量新指令的难度,这可能有利于未来的指令数据生成工作。
在指令调整过程中,样本对的损失是通过给定在指令及其后续单词的情况下连续预测下一个标记来计算的:
Conditioned Answer Score:
较高的并不意味着指令更难遵循,这可能只是字符串本身的固有因素造成的。为了估计遵循给定样本的说明的难度,引入
Direct Answer Score:
Instruction-Following Difficulty (IFD):
在这种情况下,LLM固有的对答案串的拟合能力的影响得到了部分缓解。该分数衡量给定指令如何有利于相应响应的一致性的程度。高 IFD 分数表明模型无法将响应与给定的相应指令对齐,这反过来又表明指令的难度。
这项研究阐明了利用LLM的固有能力来选择适合模型的高质量指令调整数据的潜力。通过我们创新的自我引导方法,LLM展示了辨别和挑选最相关的数据样本的能力,我们将这一概念恰当地称为“樱桃数据”。我们方法的核心是指令遵循难度指标,这是一种善于衡量模型自主输出和预期响应之间细微差别的新颖工具。我们的研究结果不仅强调了数据质量比数量更重要,而且还强调了具有成本效益和简化的LLM训练的潜力。
Related Work
Data-driven Instruction Tuning
以前的指令调优集合通常是手工制作的或与任务相关的(Khashabi et al., 2020; Ye et al., 2021; Wei et al., 2022; Wang et al., 2022a; Du et al., 2022; Honovich et al. ., 2023), (Wang et al., 2023b) 利用 GPT3 (Brown et al., 2020) 生成 52k 条与每个任务不直接相关的不同指令,这为通过从教师中提取来生成指令数据集铺平了道路楷模。 Meta LLaMA(Touvron et al., 2023a)发布后,世界见证了开源指令调优数据集和 LLM 的激增。
Coreset Selection
核心集选择在机器学习中至关重要,旨在识别数据点的代表性子集,以加快各种模型的学习。这种方法在 SVM 学习 (Tsang et al., 2005)、k-means (Har-Peled and Kushal, 2005)、逻辑回归 (Munteanu et al., 2018) 中发挥了作用。然而,这些方法主要关注传统机器模型。
在神经网络训练中,最近的进展,例如 Toneva 等人的进展。 (Toneva 等人,2018),探索训练期间数据点效用的动态。他们发现很少被遗忘的点对最终模型精度的影响最小。曼希·保罗等人。 (Paul 等人,2021)证明,在各种权重初始化上平均的预期损失梯度范数分数可以有效地修剪训练数据,而不会显着影响准确性。索伦·明德曼等人。 (Mindermann et al., 2022) 使用贝叶斯概率论来估计训练点对保留损失的个体影响,从而提高训练效率。
这些工作的共同点是关注传统的培训机制。我们的研究重点是优化指令调整中的核心集选择。与上述方法类似,我们的分数估计依赖于目标模型的特征表示。
Instruction Data Selection
尽管人们已经达成共识,即指令调优“质量就是你所需要的”(Touvron 等人,2023b),但通过人工管理以外的方式寻找高质量数据仍然是一个尚未充分探索的话题。最近的两篇论文《Instruction Mining》(Cao et al., 2023)和 ALPAGASUS(Chen et al., 2023)提出了弥合这一差距的方法,与我们的工作有着相似的动机。指令挖掘评估各种指标并应用统计回归模型进行数据选择。然而,它缺乏与在完整数据上训练的模型的比较性能分析,并且其方法被认为过于复杂,涉及将数据拆分为多个容器并完全训练模型。相比之下,ALPAGASUS 利用外部的、经过充分训练的 LLM (ChatGPT) 对每个样本进行评分。它选择了9k Alpaca数据,超过了官方用全数据训练的Alpaca。虽然有效,但这种方法可能会忽视基础模型的内在能力,过度依赖外部模型。
相比之下,我们的工作旨在开发一种利用目标模型的表示特征来识别用于指令调整的高质量数据的方法,以更简单、更有效的方法推进该领域的发展。
Experiments
Metrics
在评估中,评委对每个模型的响应进行评分,评分范围为 1 到 10,反映相关性和准确性等属性。同时与LIMA类似,进行了模型两两之间的比较:Wins, Tie, Loses
Datasets
Training Datasets:
- Alpaca dataset
- WizardLM dataset
Test Datasets:
- Vicuna
- Koala
- WizardLM
- Self-instruct
- LIMA
Baselines
- Alpaca
- WizardLM
Results
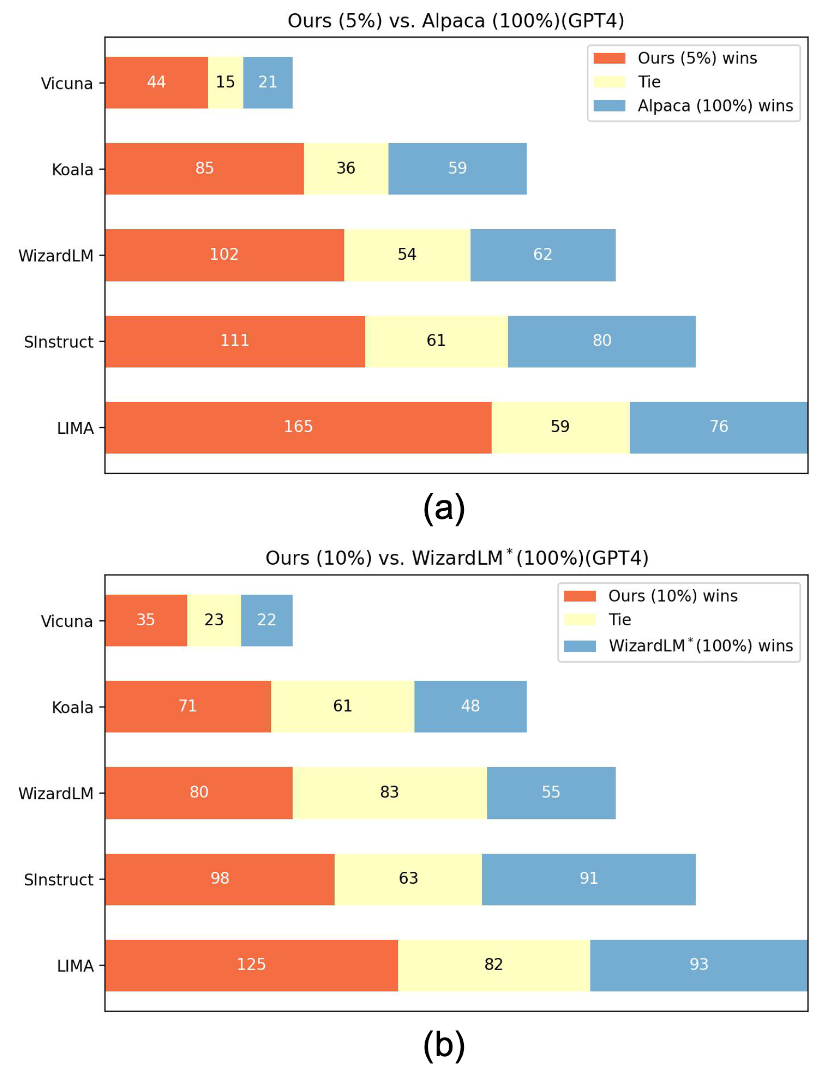
将我们在选定数据上训练的模型与完整数据进行比较。 (a) 我们使用 5% Alpaca 数据的模型与官方 Alpaca 模型的比较。 (b) 具有 10% WizardLM 数据的模型与重新实现的 WizardLM 模型之间的比较。 (a)和(b)都使用GPT4作为判断。每个水平条代表特定测试集中的比较。
我们画出随数据增长的总体胜率变化,计算公式为 (Num(Win)−Num(Lose))/Num(All) +1,
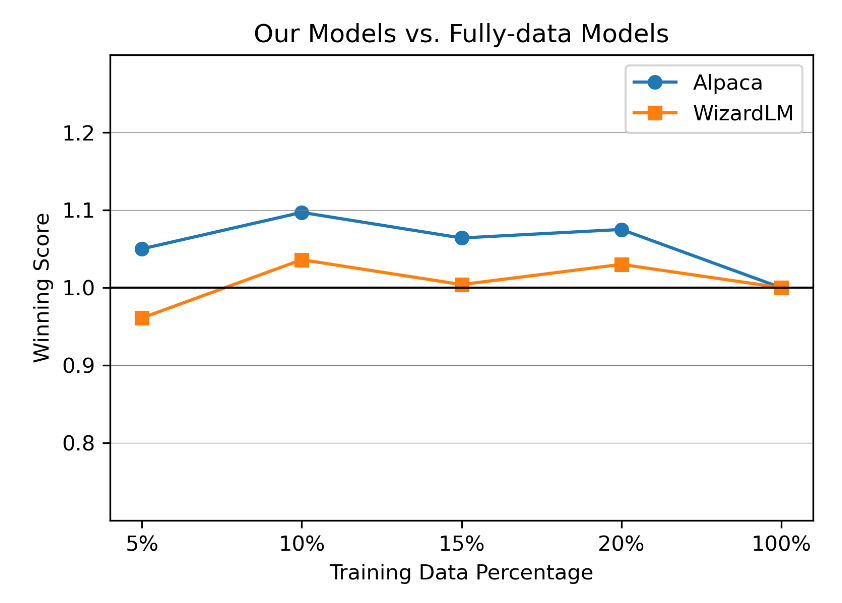 与相应的全数据模型相比,获胜分数随着数据增长而变化。获胜分数的计算方式为(Num(Win)−Num(Lose))/Num(All) +1。获胜次数、失败次数和全部次数是在我们使用的所有五个测试集上计算的。当该值高于 1.0 时,表示该模型的性能优于对比模型。该图中的比较是由 ChatGPT 执行的。
与相应的全数据模型相比,获胜分数随着数据增长而变化。获胜分数的计算方式为(Num(Win)−Num(Lose))/Num(All) +1。获胜次数、失败次数和全部次数是在我们使用的所有五个测试集上计算的。当该值高于 1.0 时,表示该模型的性能优于对比模型。该图中的比较是由 ChatGPT 执行的。
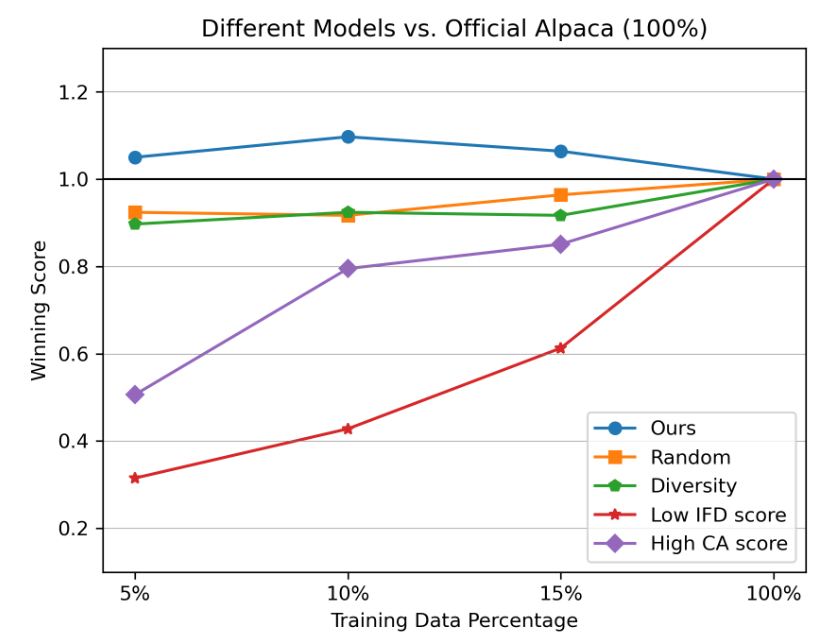 将使用不同数据选择策略的模型与官方 Alpaca 模型进行比较,总体获胜分数随数据增长而变化。图中所有的比较都是由ChatGPT进行的。
将使用不同数据选择策略的模型与官方 Alpaca 模型进行比较,总体获胜分数随数据增长而变化。图中所有的比较都是由ChatGPT进行的。
我们目标是确定基于 IFD 分数选择的数据是否与高质量训练数据的已知特征相符。从得分最高 5% 和最低 5% 的数据中随机抽取 100 个实例。利用 ChatGPT,我们从六个方面评估每条指令:范围、复杂性、清晰度、深度、简单性和所需知识。
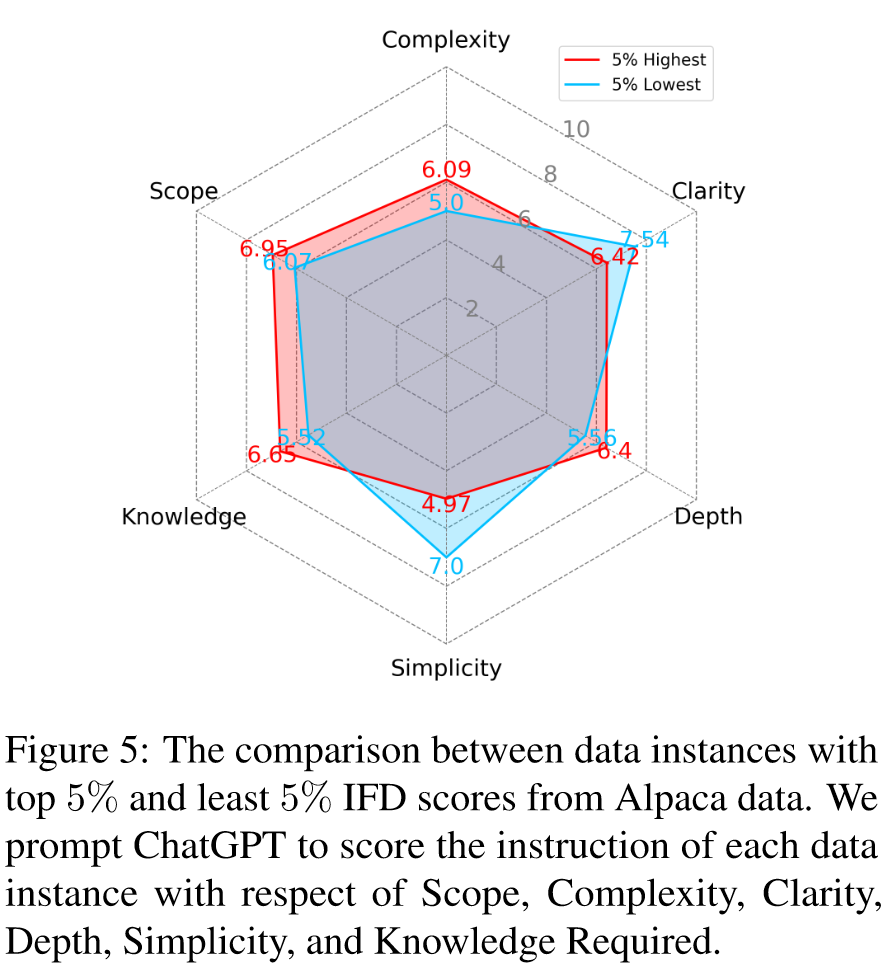
- Scope: 该说明涵盖了成功完成所需的行动或信息的广度和范围。
- Complexity: 该说明集成了需要仔细注意和理解的多个步骤或概念。
- Clarity: 该说明清晰明了,确保易于理解,没有歧义。
- Depth: 该说明提供了详尽的细节和细微差别,确保全面了解手头的任务。
- Simplicity: 该说明虽然详尽,但避免了不必要的术语或晦涩难懂,使其易于理解和遵循。
- Knowledge Required: 该指令确认并在必要时提供用户成功执行所需的基础知识或上下文。
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: 此论文的主要创新在于提出了一种自我引导的数据选择方法,用以优化大型语言模型(LLM)在指令调优过程中的数据使用。论文引入的关键创新是指令遵循难度(Instruction-Following Difficulty, IFD)度量标准,用以识别模型预期响应与其自动生成能力之间的差异。该方法通过自我引导过程,在大量开源数据集中自动识别出对LLM指令调优尤为有效的数据样本(称为"樱桃数据")。这种方法的独特性在于其强调数据质量而非数量,不同于依赖外部模型进行数据策划的现有技术。通过对Alpaca和WizardLM数据集的实验验证,使用仅10%的传统数据输入量,该策略展示了更优的结果。
-
论文中存在的问题及改进建议:
- 问题:尽管IFD标准在识别高质量训练数据方面表现出色,但这一方法在训练预体验模型时存在不便,可能使得在实际应用场景中直接应用该方法变得困难。
- 改进建议:考虑简化预体验模型的训练过程,或探索不需要预体验模型的替代方案。可以考虑使用更先进的无监督学习技术来评估和选择训练数据,以减少对预体验模型的依赖。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 研究路径一:探索IFD度量在不同类型的语言模型中的应用和有效性,例如将IFD应用于小型或特定领域的语言模型。
- 研究路径二:开发一种基于元学习的框架,使得LLMs能够在接受新任务时自我调整IFD参数,进一步提高模型在新领域或新任务上的适应性和效率。
- 研究路径三:利用强化学习方法优化IFD度量标准,允许模型在选择训练数据时考虑长期效益而非仅仅基于当前性能指标。
-
为新的研究路径制定的研究方案:
- 研究方案一:将IFD度量应用于多种类型的语言模型,如基于Transformer的小型模型和特定领域的模型,评估IFD在这些环境下的效果,并调整IFD计算方式以适应不同模型的特性。
- 研究方案二:设计一个元学习系统,训练LLMs以自动调整IFD参数,针对新任务和数据进行优化。研究包括:元学习算法的选择和调整、新任务适应性的评估、以及在多任务学习环境中的表现。
- 研究方案三:采用强化学习技术来优化IFD度量的制定,使模型在选择训练数据时考虑到长期的学习效果。这将包括设计适合的奖励机制、强化学习算法的选择和调整,以及在不同数据集上的实验验证。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!