目录
Resource Info Paper https://arxiv.org/abs/2210.11610 Code & Data / Public EMNLP Date 2024.04.08
Summary Overview
大型语言模型(LLM)在各种任务中都取得了优异的表现。然而,微调LLM需要广泛的监督。另一方面,人类可以通过自我思考来提高自己的推理能力,而无需外部输入。在这项工作中,我们证明了LLM也能够仅使用未标记的数据集进行自我改进。我们使用预先训练的LLM,通过思想链提示和自我一致性,为未标记的问题生成“高置信度”的理由增强答案,并使用这些自我生成的解决方案作为目标输出来微调LLM。我们表明,我们的方法提高了 540B 参数 LLM 的一般推理能力(GSM8K 上 74.4%→82.1%,DROP 上 78.2%→83.0%,OpenBookQA 上 90.0%→94.4%,ANLI 上 63.4%→67.9%) A3)并实现了最先进的性能,没有任何真实标签。我们进行了消融研究,结果表明,推理的微调对于自我完善至关重要。
Main Content
在本文中,我们研究了LLM如何在没有监督数据的情况下自我提高推理能力。
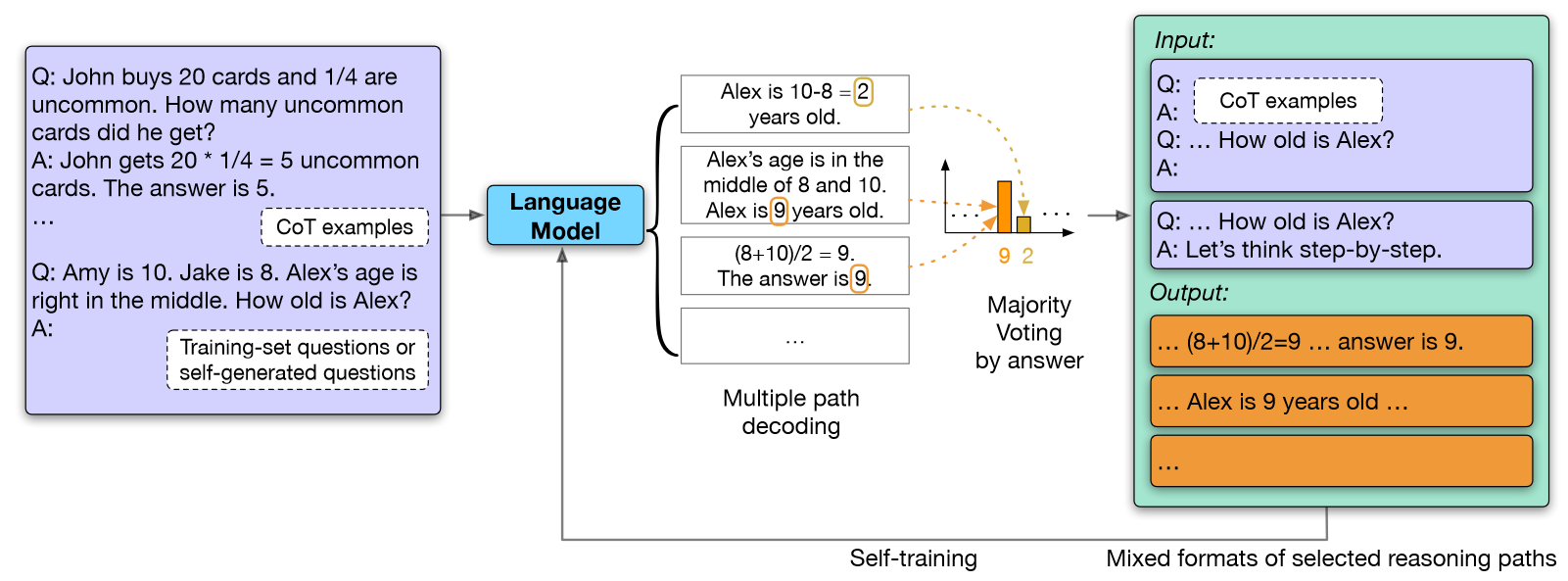
我们首先使用few-shot CoT作为提示对多个预测进行采样,使用多数投票过滤“高置信度”预测,最后进行微调。由此产生的模型显示了贪婪和多路径评估中推理的改进。我们将这种方法微调的模型称为Language Model Self-Improved (LMSI)。
Motivation: 这类似于人脑有时的学习方式:给定一个问题,多次思考以获得不同的可能结果,得出应该如何解决问题的结论,然后学习或记住自己的解决方案。
Contributions:
- 我们证明,大型语言模型可以通过获取没有真实输出的数据集、利用 CoT 推理(Wei 等人,2022b)和自我一致性(Wang 等人,2022b)来自我改进,从而实现有竞争力的域内多任务性能以及域外泛化。我们在 ARC、OpenBookQA 和 ANLI 数据集上取得了最先进的结果。
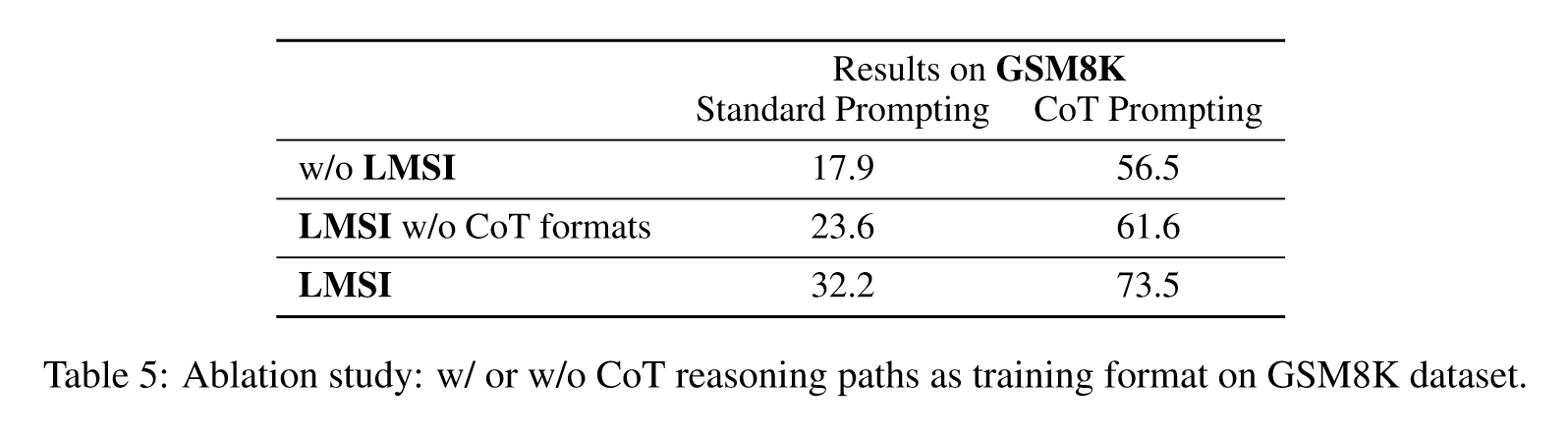
- 我们提供关于微调后的训练样本格式和采样温度的详细消融研究,并确定法学硕士最成功的自我改进的关键设计选择。
- 我们研究了另外两种自我改进的方法,其中模型从有限输入问题中生成附加问题,并自行生成少样本 CoT 提示模板。后者在 GSM8K 上达到了 74.2%,这是最先进的零样本性能,而 Kojima 等人的结果是 43.0%。 (2022) 或 70.1%,通过 Wang 等人的幼稚扩展。 (2022b)。
Method:
我们得到一个预训练的大型语言模型 (LLM)和一个仅问题训练数据集以及少量的思想链 (CoT) 示例。我们应用采样温度的多路径解码来生成个推理路径和答案 对于中的每个问题,并使用多数投票(自我一致性)来选择最一致、最高置信度的答案。

对于每个训练问题,我们采样个CoT推理路径,表示为。由于是由CoT示例提示的。我们应用"The answer is"来生成预测答案。最一致的答案(不一定是正确答案)通过多数投票选出,表示为
对于所有训练问题,我们过滤到达的 CoT 推理路径作为最终答案放入自训练数据中,表示为
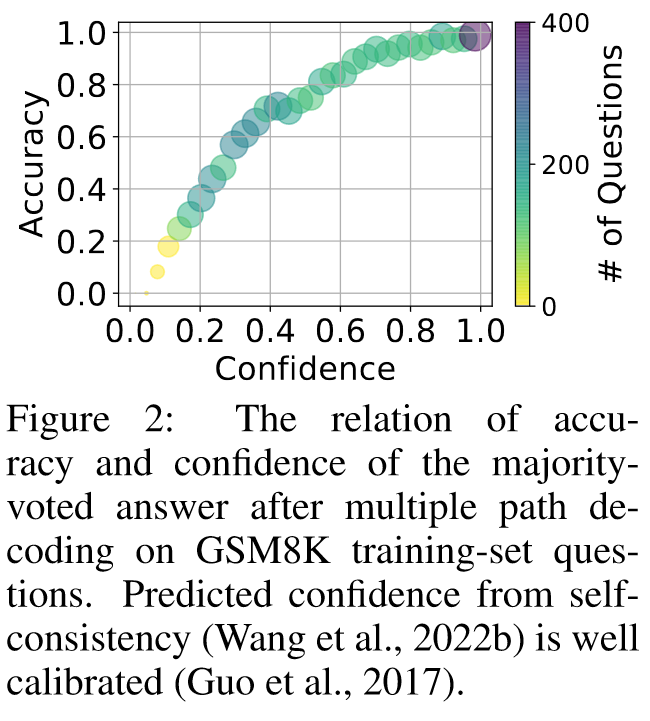 我们在图 2 中绘制了 GSM8K 训练集中每个问题的自生成 CoT 路径的准确性和置信度之间的关系。
我们在图 2 中绘制了 GSM8K 训练集中每个问题的自生成 CoT 路径的准确性和置信度之间的关系。
我们可以观察到,置信的答案更有可能是正确的,这意味着当一个问题有许多一致的 CoT 路径时,那么相应的更有可能是正确的。另一方面,当错误时,它很可能得到较少的 CoT 路径支持,并且给训练样本带来很少的噪声。
Training with mixed formats: 为了防止语言模型过度拟合特定的提示或答案风格,我们为每个推理路径创建了四种不同的格式,以混合在自训练数据中,如表 2 所示。

我们证明了大型语言模型(LLM)能够通过在仅给定输入问题的情况下对其自己生成的标签进行训练来提高其在推理数据集上的性能。使用具有 5400 亿个参数的 LLM 进行的实验表明,我们的方法将六个数据集的准确性分数提高了 1.1% 至 7.7%,在 ARC、OpenBookQA 和 ANLI 上实现了新的最先进结果,而无需进行地面实况训练标签。此外,我们表明,LLM甚至可以根据自己生成的问题和少量的思想链提示进行自我改进。作为我们未来工作的一部分,我们计划将我们的方法生成的大规模数据与现有的监督数据相结合,以进一步提高LLM的表现。
Experiments
Models
PaLM-540B
Datasets
- Arithmetic reasoning:
- GSM8K
- DROP
- Commonse reasoning:
- ARC
- OpenBookQA
- Natural Language Inference:
- ANLI-A2
- ANLI-A3
Results
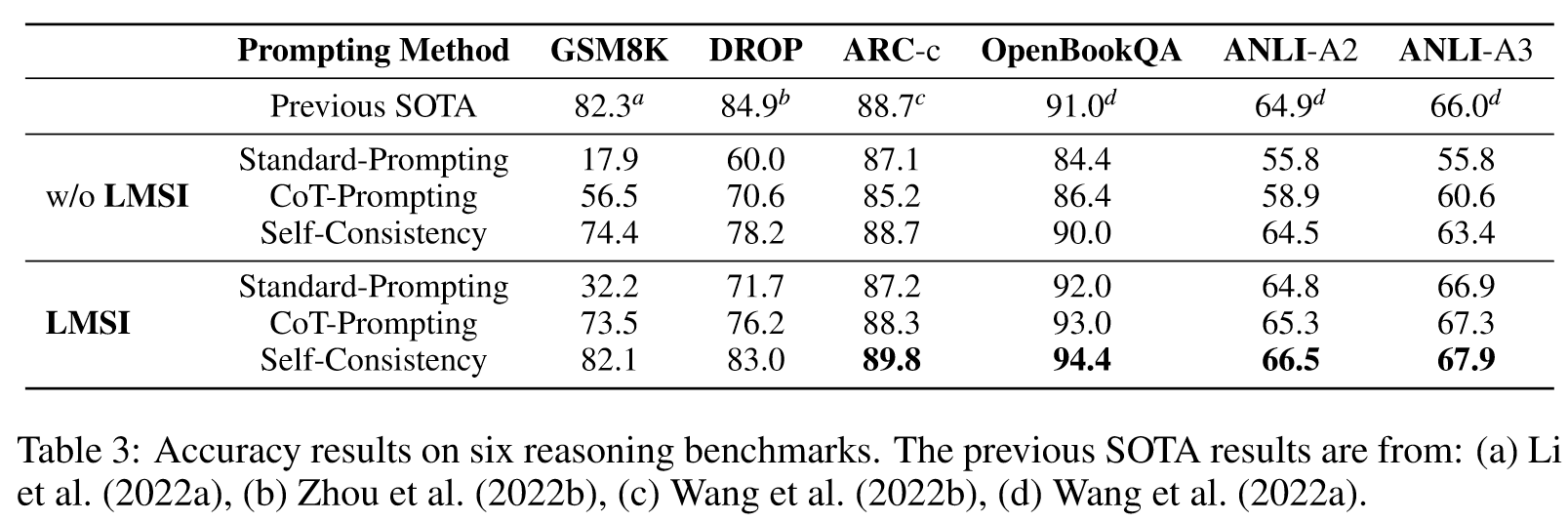
Multi-task self-training for unseen tasks
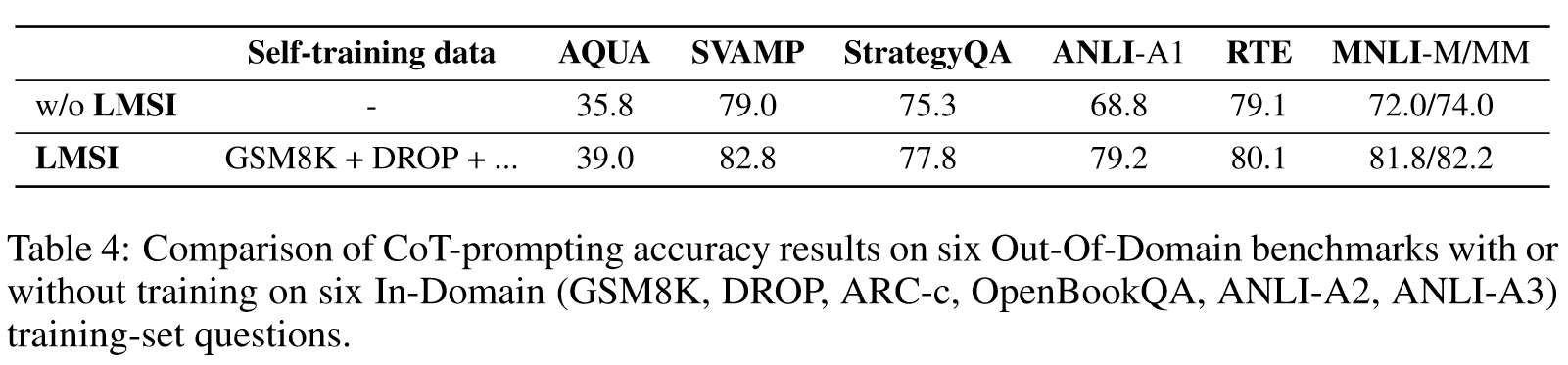
Importance of training with Chain-of-Thought formats
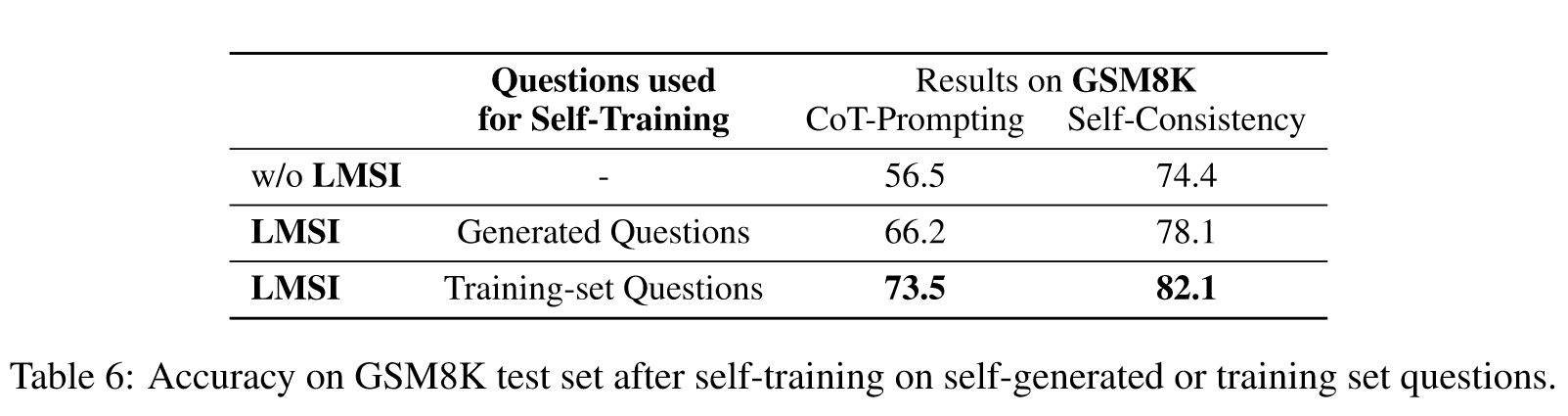
Self-Generating Questions
在 GSM8K 上,我们采样 10 个真实问题作为少样本样本,并使用 3.3 节中的方法使用语言模型生成更多训练问题。然后,我们用这些生成的问题对语言模型进行自训练,并将结果列于表6中。结果表明,使用自生成的问题仍然可以提高语言模型的推理能力,但使用真实的训练集问题会得到更好的结果。
Case Study
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性: Huang等人的研究表明,大型语言模型(LLM)能够通过仅使用未标注数据集自我改进。具体来说,论文的核心创新在于提出了一种基于自我生成的“高置信度”理由增强答案的训练方法,这种方法使得LLM在不依赖标注数据的情况下,通过自我一致性和链式推理来提升其解决问题的能力。这种自我提升的方法展示了在泛化能力、理解能力和推理能力上的明显提升,特别是在GSM8K、DROP、OpenBookQA 和 ANLI-A3等数据集上的表现。这一发现对LLM的训练方法和自然语言处理领域具有重要意义,表明大型模型在无需显式外部指导的情况下,仍有提升空间。
-
论文中存在的问题及改进建议: 尽管该研究展示了LLM在自我提升上的潜力,但仍存在一些限制。例如,论文中采用的自我训练方法可能在特定任务上表现出过度适应的倾向,而在多样性或泛化能力方面表现不足。此外,对于推理路径的质量和可靠性的评估,当前方法可能过于依赖模型本身的置信度判断,忽视了理由的客观合理性。为改进这些问题,建议研究者考虑以下方面:
- 探索结合监督学习与无监督学习的混合方法,以增强模型在不同领域的泛化能力。
- 引入更为复杂和精细的评估机制,不仅评估答案的正确性,也考量推理路径的逻辑一致性和可解释性。
- 将人类反馈纳入自我提升过程,以提高模型推理的准确性和适用性。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
a. 跨领域自我提升机制研究:探索如何在不同领域(如法律、医学)上应用并调整自我提升机制,以探究模型在专业领域知识和推理上的表现。
b. 元认知机制的模拟与集成:研究如何在LLM中模拟人类的元认知过程,例如,通过自我监督和自我调节机制,提高模型的自适应性和问题解决策略。
c. 多模态数据融合与自我提升:结合文本、图像和声音等多模态数据,研究模型如何综合不同模态信息进行更深层次的学习和推理。
-
为新的研究路径制定的研究方案:
a. 跨领域自我提升机制研究:
- 方法:采用多源数据集,包括法律文献、医学论文等,对LLM进行跨领域训练。
- 步骤:先对模型在特定领域进行基线训练,然后应用自我提升方法,并对比其性能差异。
- 期望成果:揭示LLM在不同知识领域中的自我提升能力和限制。
b. 元认知机制的模拟与集成:
- 方法:开发元认知算法,模拟人类的反思、规划和监控等认知过程。
- 步骤:在LLM中集成元认知算法,测试在复杂问题解决中的作用。
- 期望成果:实现更加智能和灵活的语言模型,具有自我调节和自我提升的能力。
c. 多模态数据融合与自我提升:
- 方法:集成文本、图像和声音等多种数据模态,进行模型训练。
- 步骤:在LLM中融合多模态输入,实现跨模态理解和推理。
- 期望成果:展示LLM在多模态数据处理和推理方面的自我提升能力。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!