目录
The Llama 3 Herd of Models
1 Introduction
Two main stages:
- a pre-training stage in which the model is trained at massive scale using straightforward tasks such as next-word prediction or captioning
- a post-training stage in which the model is tuned to follow instructions, align with human preferences, and improve specific capabilities (for example, coding and reasoning)
We pre-train Llama 3 on a corpus of about 15T multilingual tokens, compared to 1.8T tokens for Llama 2.
Post-training procedure: supervised finetuning (SFT), rejection sampling (RS) and direct preference optimization (DPO).
2 General Overview
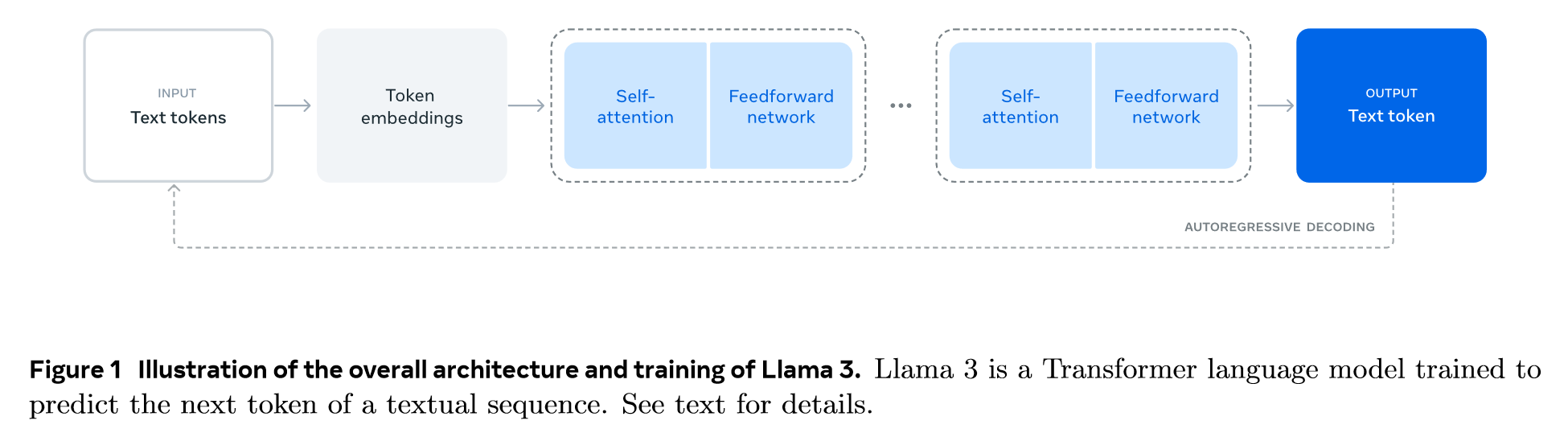
3 Pre-Training
Pre-training involves:
- the curation and filtering of a large-scale training corpus
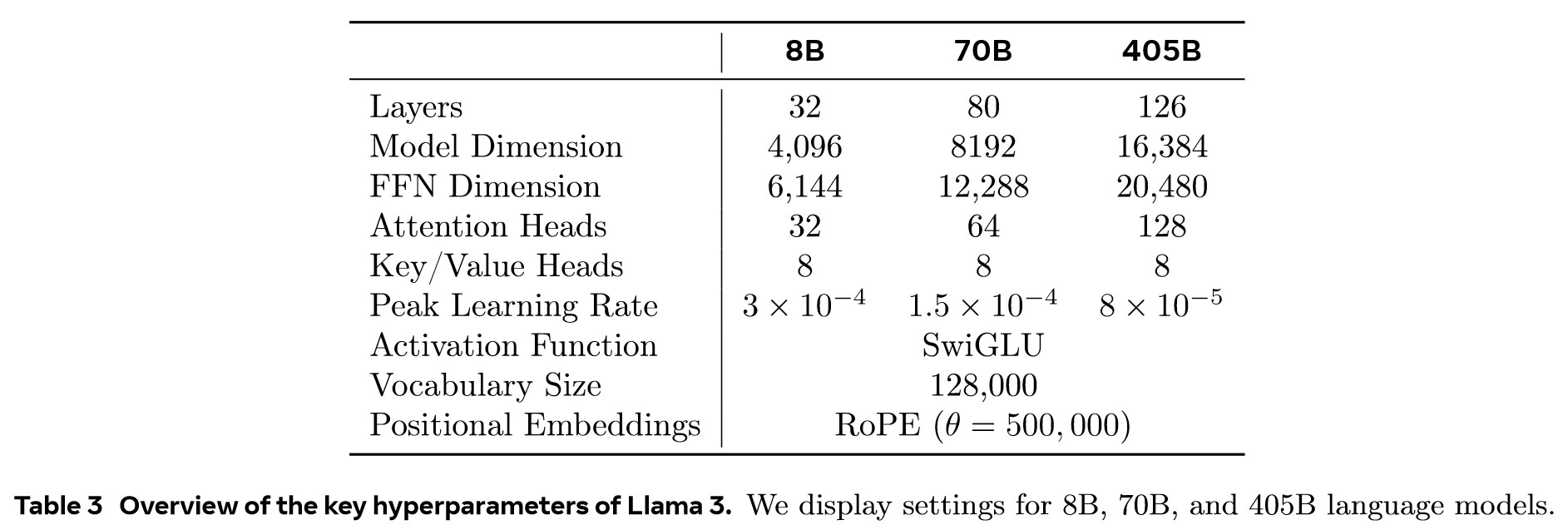
- the development of a model architecture and corresponding scaling laws for determining model size
- the development of techniques for efficient pre-training at large scale
- the development of a pre-training recipe
Web Data Curation:
- PII and safety filtering
- De-duplication
- URL-level de-duplication
- Document-level de-duplication
- Line-level de-duplication
- Heuristic filtering
- Use duplicated n-gram coverage ratio to remove lines that consist of repeated content such as logging or error messages. Those lines could be very long and unique, hence cannot be filtered by line-dedup.
- Use "dirty word" counting to filter out adult websites that are not covered by domain block lists.
- Use a token-distribution Kullback-Leibler divergence to filter out documents containing excessive numbers of outliner tokens compared to the training corpus distribution.
Determining the Data Mix
- Knowledge classification. We develop a classifier to catagorize the types of information contained in our web data to more effectively determine a data mix. We use this classifier to downsample data categories that are over-represented on the web, for example, arts and entertainiment.
- Scaling laws for data mix. To determine the best data mix, we perform scaling law experiments in which we train several small models on a data mix and use that to predict the preformance of a large model on that mix. We repeat this process multiple time for different data mixes to select a new data mix candidate. Subsequently, we train a larger model on this candidate data mix and evaluate the performance of that model on several key benchmarks.
- Data mix summary. Our final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
Scaling Laws Issuses:
- Existing scaling laws typically predict only next-token prediction loss rather than specific benchmark performance.
- Scaling laws can be noisy and un reliable because they are developed based on pre-training runs conducted with small compute budgets.
- Two-stage methodology
- We first establish a correlation between the compute-optimal model's negative log-likelihood on downstream tasks and the training FLOPs.
- Next, we correlate the negative log-likelihood on downstream tasks with task accuracy, utlizing both the scaling law models and older models trained with higher compute FLOPs. In this step, we specifically leverage the Llama 2 family of models.
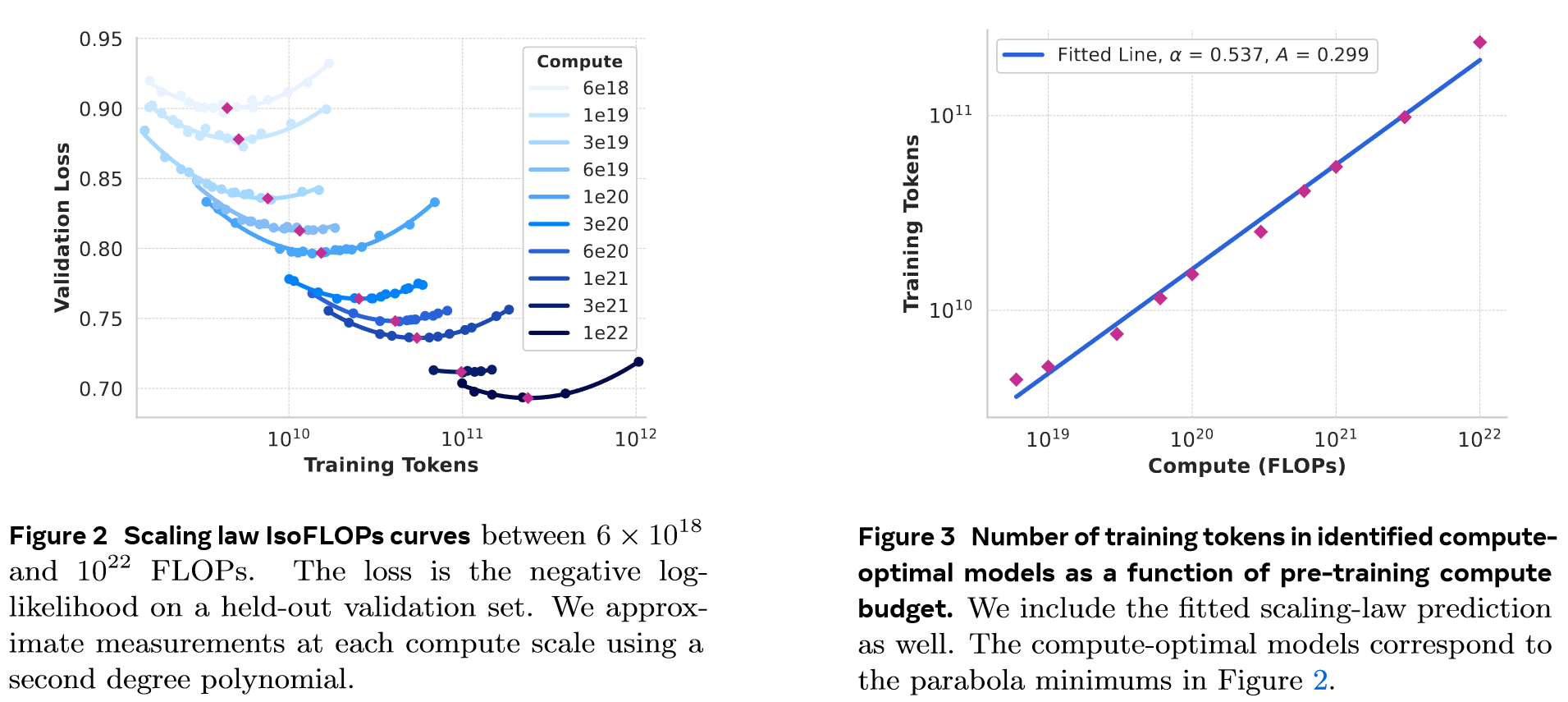
To do so, we assume a power-law relation between compute budget, C, and the optimal number of training tokens, :
We fit and using the data from Figure 2. We find that .
Pre-train Llama 3 405B consists of three main stages:
- initial pre-training
- long-context pre-training
- annealing
4 Post-Training
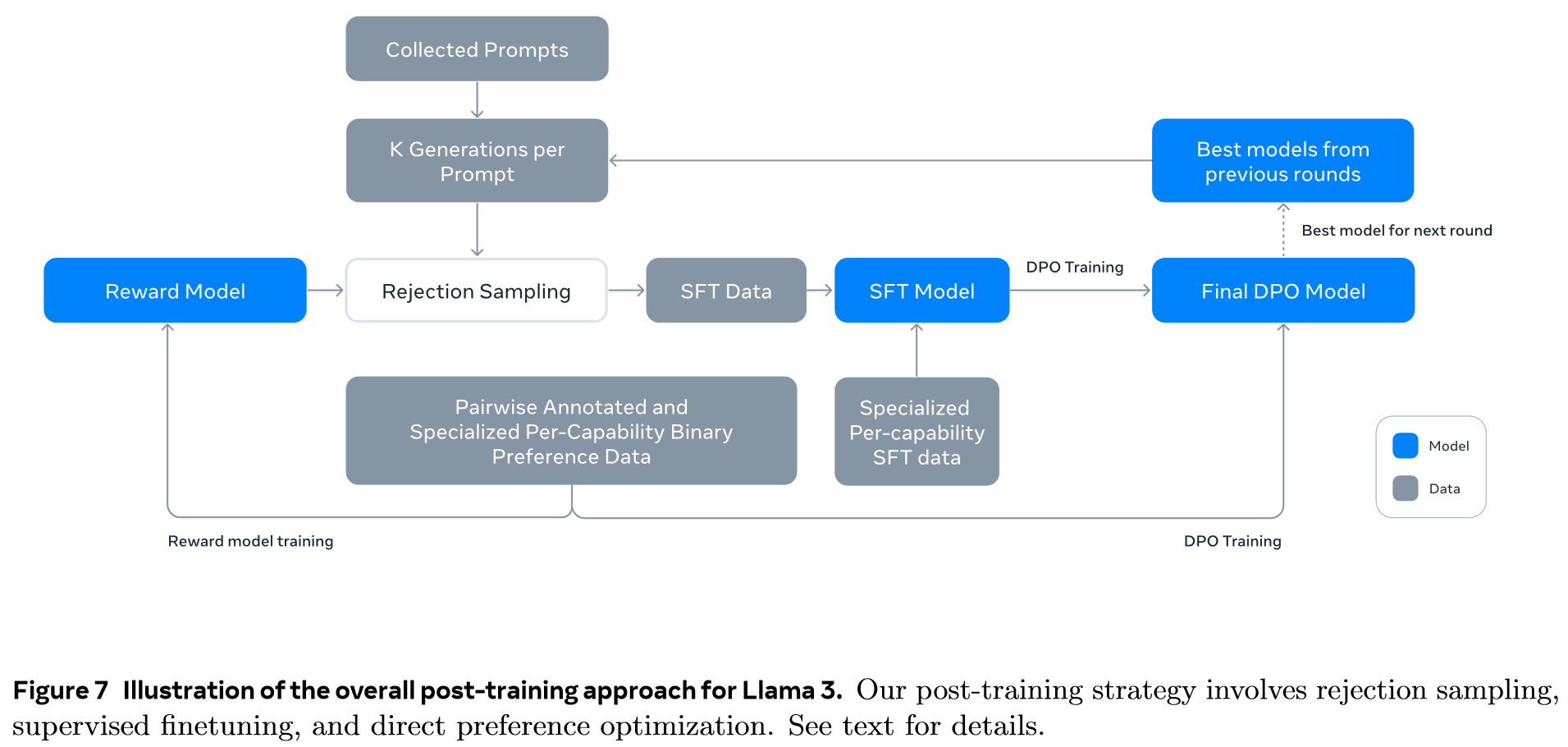
The backbone of our post-training strategy is a reward model and a language model. We first train a reward model on top of the pre-trained checkpoint using human-annotated preference data. We the finetune pre-trained checkpoints with supervised finetuning (SFT), and further align the checkpoints with Direct Preference Optimization (DPO). This process is illustrated in Figure 7. Unless otherwise noted, our modeling procedure applies to Llama 3 405B, and we refer to Llama 3 405B as Llama 3 for simplicity.
We also explored on-policy algorithms such as DPO, but found that DPO required less compute for large-scale models and performed better, especially on instruction following benchmarks like IFEval.
- Masking out formatting tokens in DPO loss
- Regularization with NLL loss
Preference Data
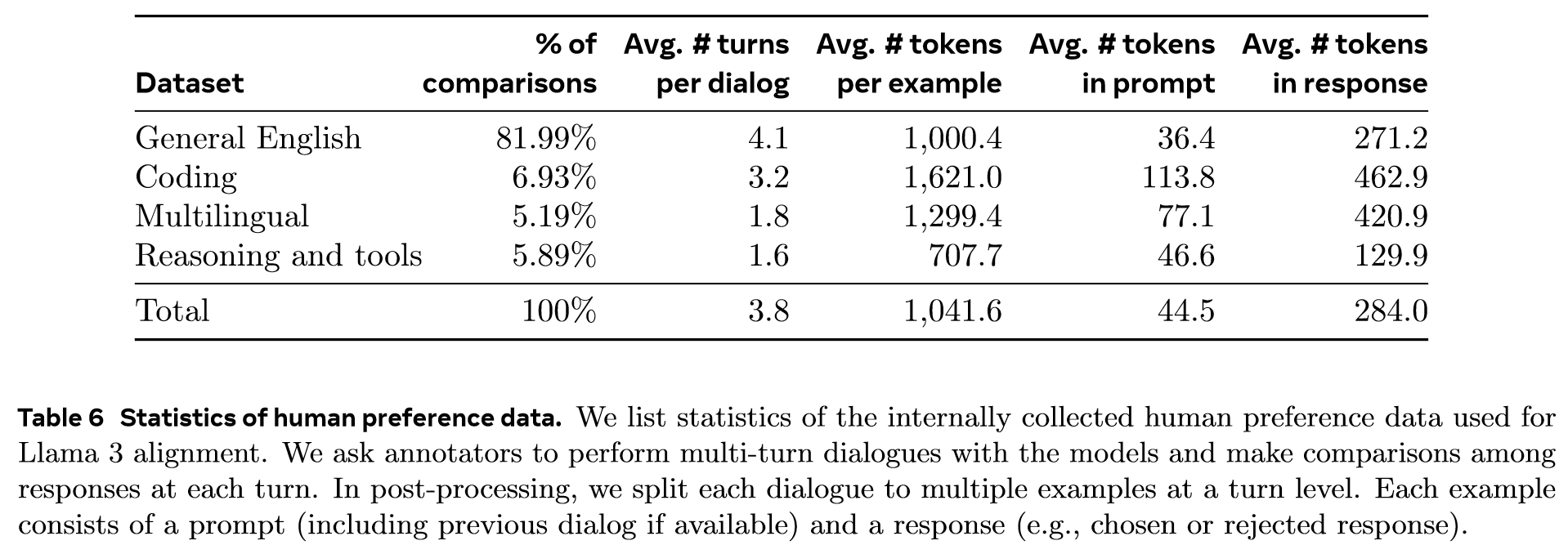
We deploy multiple models for annotation after each round and sample two responses from two different models for each user prompt. We ask annotators to rate the strength of their preference by categorizing it into one of four levels, based on how much more they prefer the chosen response over the rejected one: significantly better, better, slightly better, or marginally better. Consenquently, a portion of our preference data has three responses ranked ()
SFT Data
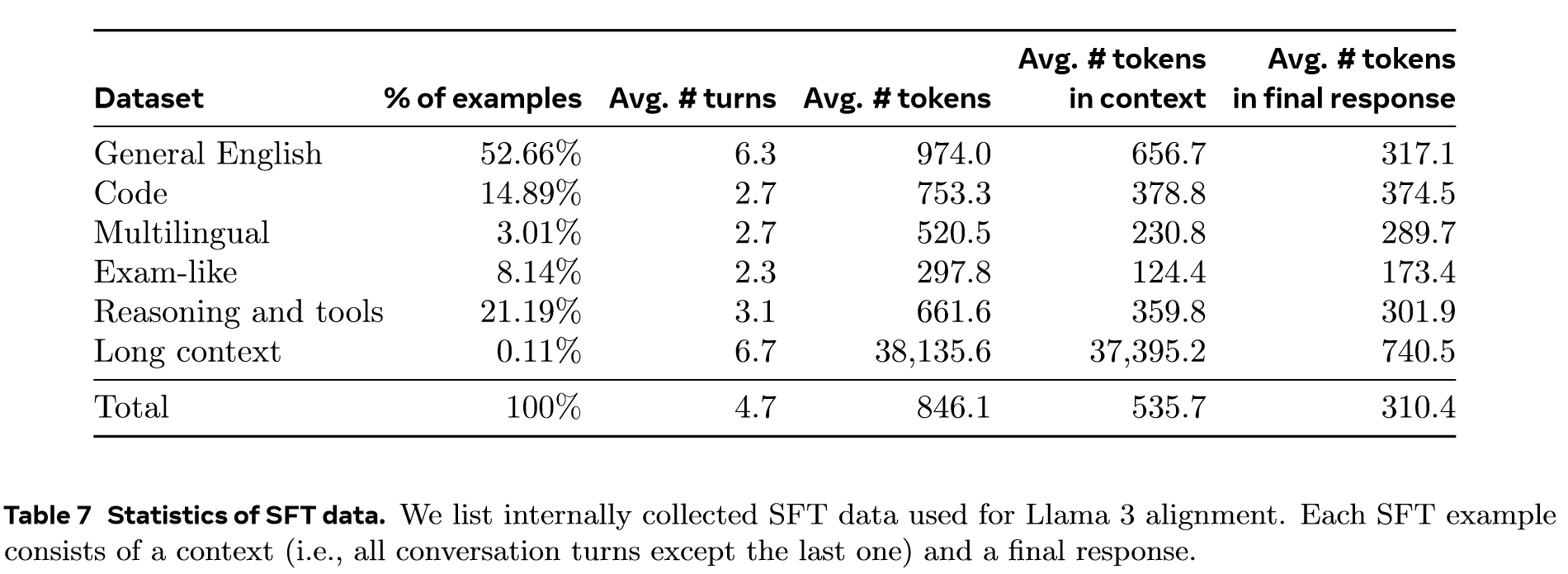
Our finetuning data is largely comprised of the following sources:
- Prompts from our human annotation collection with rejection-sampled repsonses
- Synthetic data targeting specific capabilities
- Small amounts of human-curated data
Data Processing and Quality Control
- Data cleaning
- Data pruning
- Topic classification
- Quality scoring
- Difficulty scoring
- Senmantic deduplication
Code
Here, we present our work on improving these coding capabilities via training a code expert, generating synthetic data for SFT, improving formatting with system prompt steering, and creating quality filters to remove bad samples from our training data.
Continued pre-training on domain-specific data has been shown to be effective for improving performance in a specifc domain.
During development, we identified key issues in code generation, including difficulty in following instructions, code syntax errors, incorrect code generation, and difficulty in fixing bugs.
Howerver, our initial experiments revealed that training Llama 3 405B on its own generated data is not helpful (and can even degrade performance).
- Problem description generation
- Solution generation
- Correctness analysis
- Static analysis
- Unit test generation and execution
- Error feedback and iterative self-correction
- Fine-tuning and iterative improvement

Math and Reasoning
Several challenges:
- Lack of prompts
- Lack of ground truth chain of thought
- Incorrect intermediate steps
- Teaching models to use external tools
- Discrepancy between training and inference
Following methodologies;
- Addressing the lack of prompts
- Augmenting training data with step-wise reasoning traces
- Filtering incorrect reasoning traces
- Interleaving code and text reasoning
- Learning from feedback and mistakes
Factuality
We follow the principle that post-training should align the model to "know what it knows" rather than add knowledge. Our primary approach involves generating data that aligns model generations with subsets of factual data. To achieve this, we develop a knowledge probing technique that takes advantage of Llama 3's in-context abilities. This data generation process involves the following procedure:
- Extract a data snippet from the pre-training data.
- Generate a factual question about these snippets (context) by prompting Llama 3
- Sample responses from Llama 3 to the question
- Score the correctness of the generations using the original context as a reference and Llama 3 as a judge
- Score the informativeness of the generations using Llama 3 as a judge
- Generate a refusal for responses which are consistently informative and incorrect across the generations, using Llama 3
We use data generated from the knowledge probe to encourage the model to only answer questions which it has knowledge about, and refuse answering those questions that it is unsure about. Further, pre-training data is not always factually consistent or correct. We therefore also collect a limited set of labeled factuality data that deals with sensitive topics where factually contradictory or incorrect statements are prevalent.
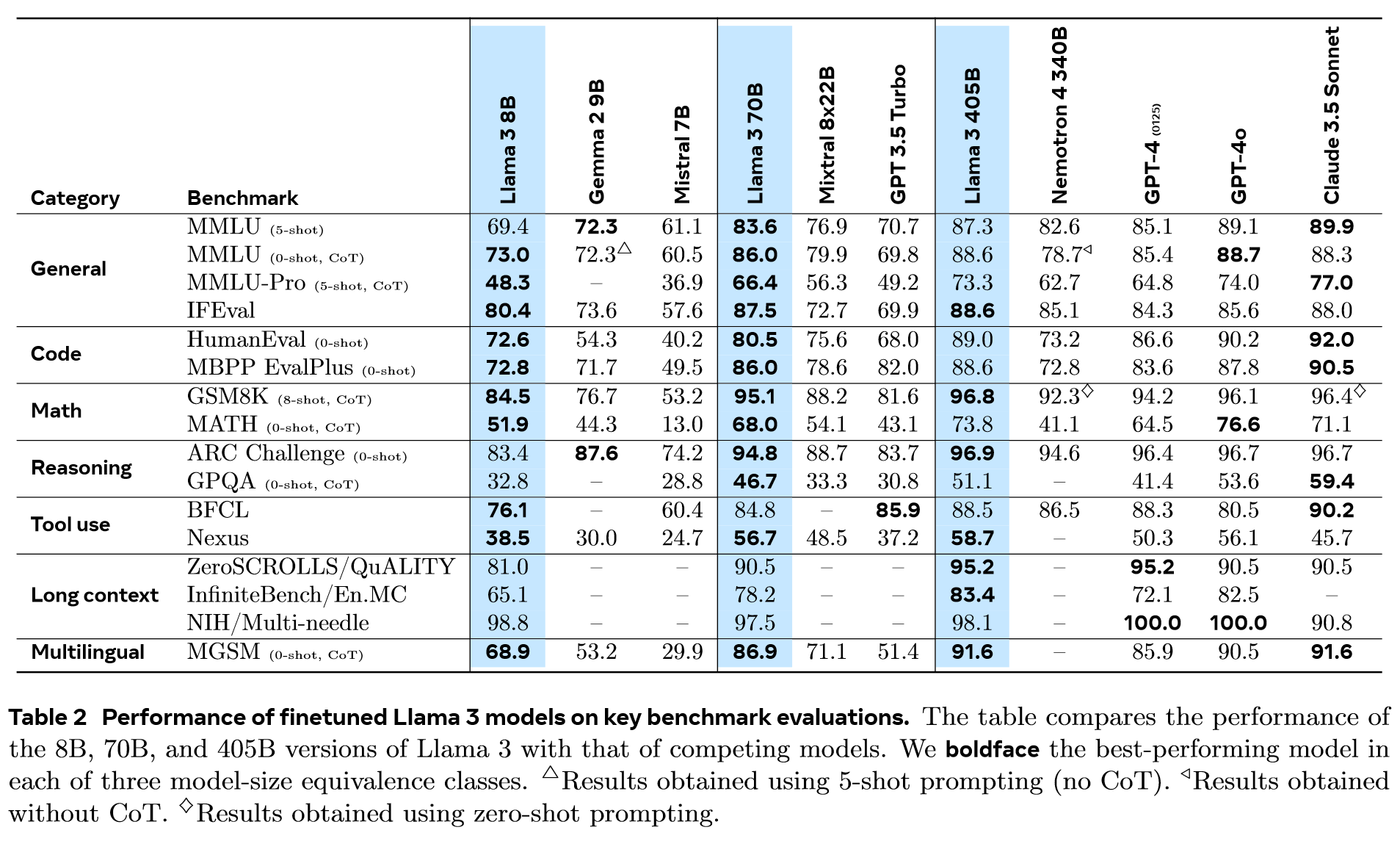
5 Results
6 Inference
7 Vision Experiments
8 Speech Experiments
9 Related Work
10 Conclusion
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!