目录
Resource Info Paper http://arxiv.org/abs/2406.04093 Code & Data https://github.com/openai/sparse_autoencoder Public arXiv Date 2024.09.04
Summary Overview
Openai 关于 SAE 的一篇工作。提出了 TopK SAE。Sparse autoencoder (SAE) 提供了一种具有前景的无监督方法,通过从神经网络层中重建激活来提取具有可解释性特征。同时还介绍了一些新指标来评估特征质量。
Main Content
三个问题:
- whether certain hypothesized features were recovered
- whether downstream effects are sparse
- whether features can be explained with both high precision and recall
Methods:
Setup
Wec choose a layer near the end of the network, which should contain many features without being specialized for next-token predictions.
Evaluation: sparsity , reconstruction meansquared error (MSE)
Baseline: ReLU autoencoder
The training loss is defined by , where is reconstruction MSE. is an penalty promoting sparsity in latent activations , and is a hyperarameter that need to be tuned.
TopK activation function
Using an activation function (TopK) that only keeps the largest latents, zeroning the rest.
The training loss is simply . No penalty anymore!
Using -sparse autoencoder has a number of benefits:
- In remove the need for the penalty. is an imperfect approximation of , and it introduces a bias of shrinking all positive activations towward zero.
- It enables setting the directly, as opposed to tuning an coefficient , enabling simpler model comparison and rapid iteration. It can also be used in combination with arbitrary activation functions
- It empirically outperforms baseline ReLU autoencoders on the sparsity-reconstruction frontier, and this gap increases with scale.
- It increases monosemanticity of random activating examples by effectively clamping small activations to zero.
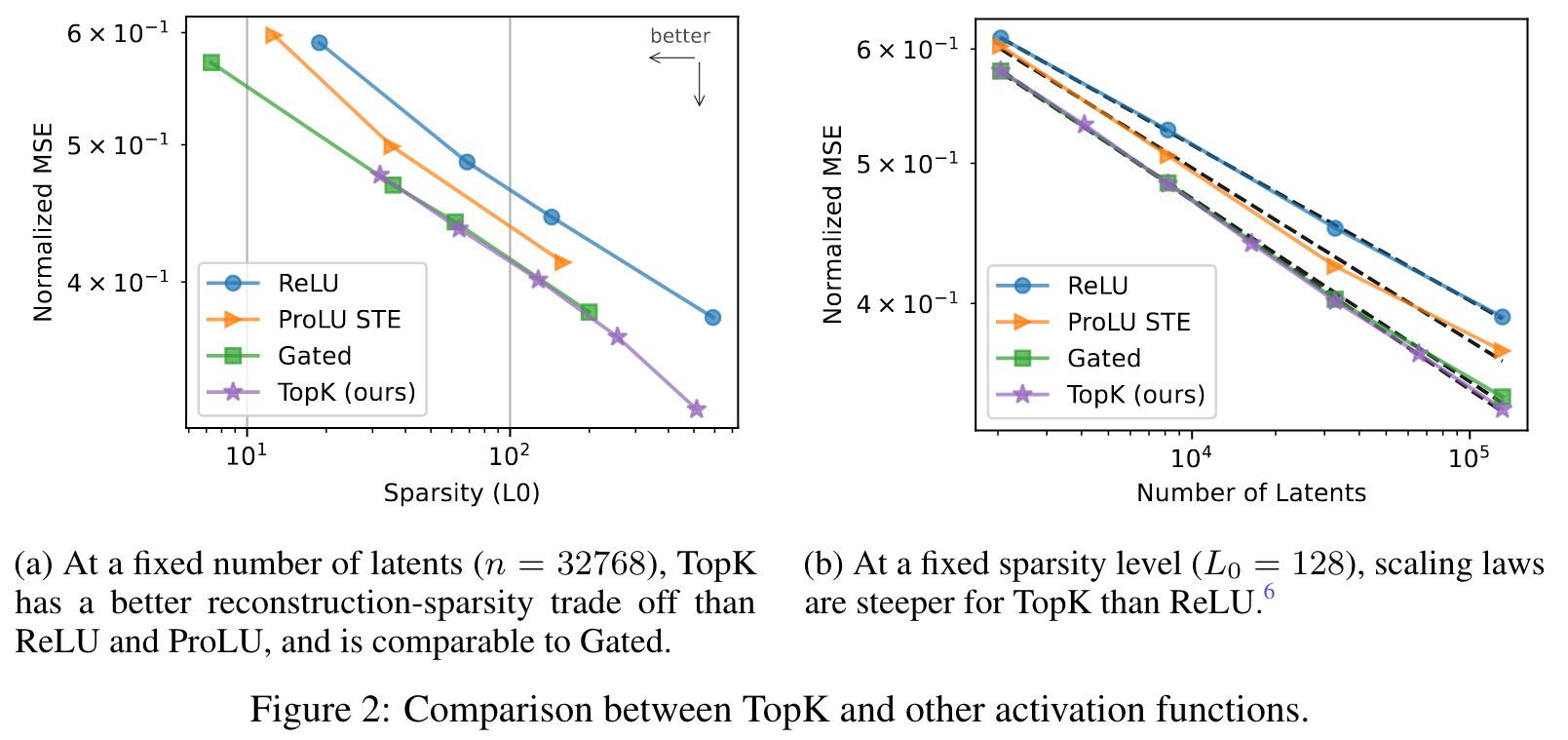
Preventing dead latents
We find two important ingredients for preventing dead latents:
- intialize the encoder to the transpose of the decoder
- use an auxiliary loss that models reconstruction errorusing the top- dead latents.
Using thesetechniques, even in our largest (16 million latent autoencoder only 7% of latents are dead).
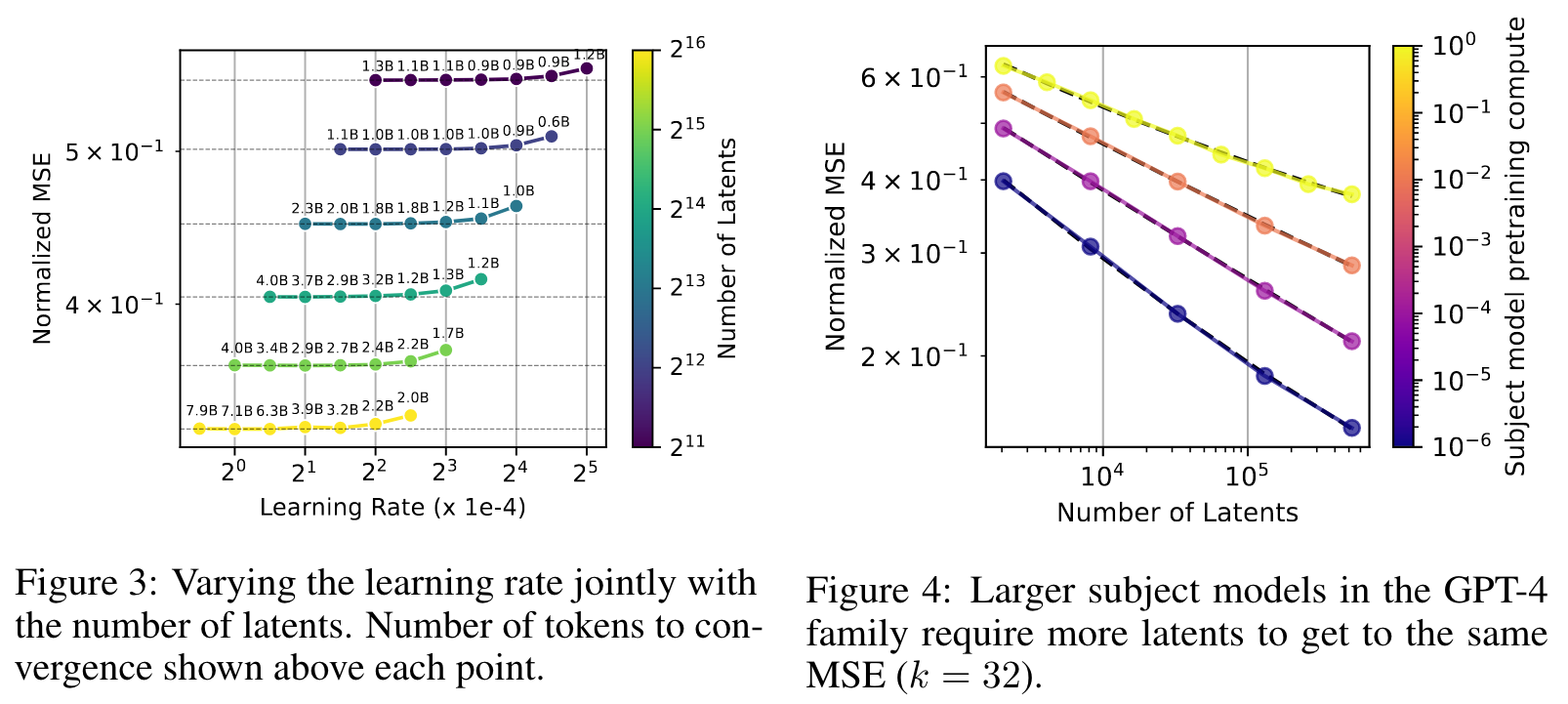
Evaluation
Following metrics:
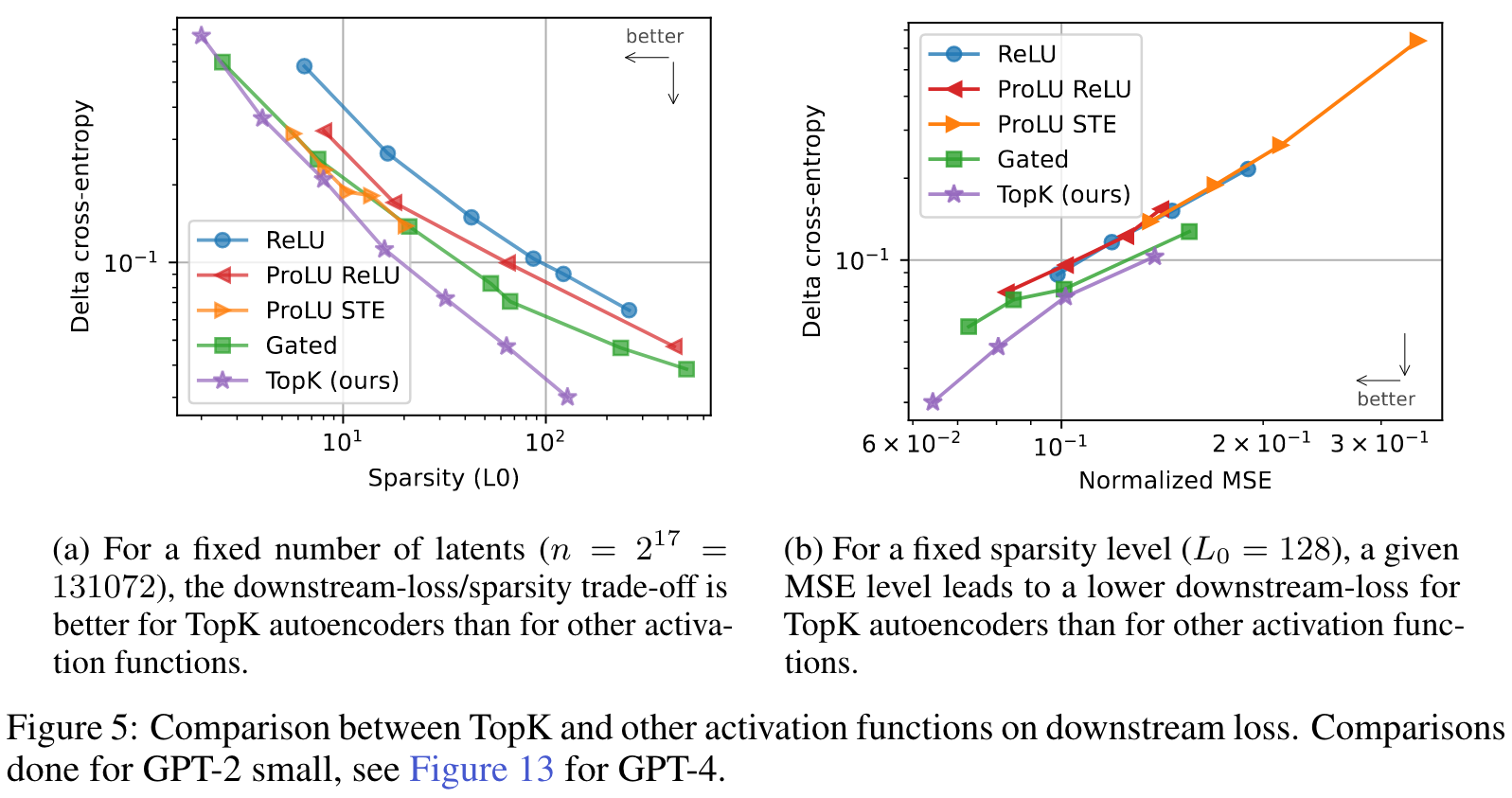
- Downstream loss: How good is the language model loss if the residual stream latent is replaced with the autoencoder reconstruction of that latent?
- Probe loss: Do autoencoders recover features that we believe they might have?
- Explainability: Are there simple explanations that are both necessary and sufficient for the activation of the autoencoder latent?
- Ablation sparsity: Does ablating individual latents have a sparse effect on downstream logits?
Finding simple explaination for features
Neuron to Graph (N2G), a substantially less expressive but much cheaper method that outputs explanations in the form of collections of n-grams with wildcards.

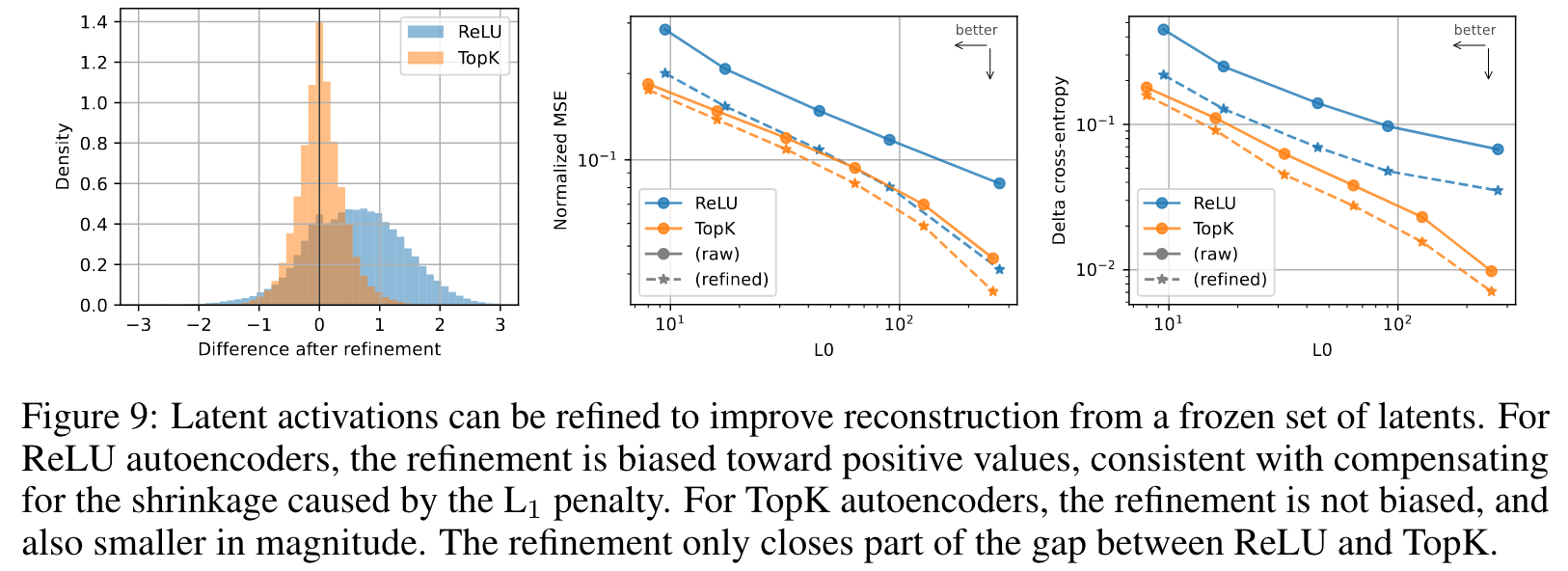
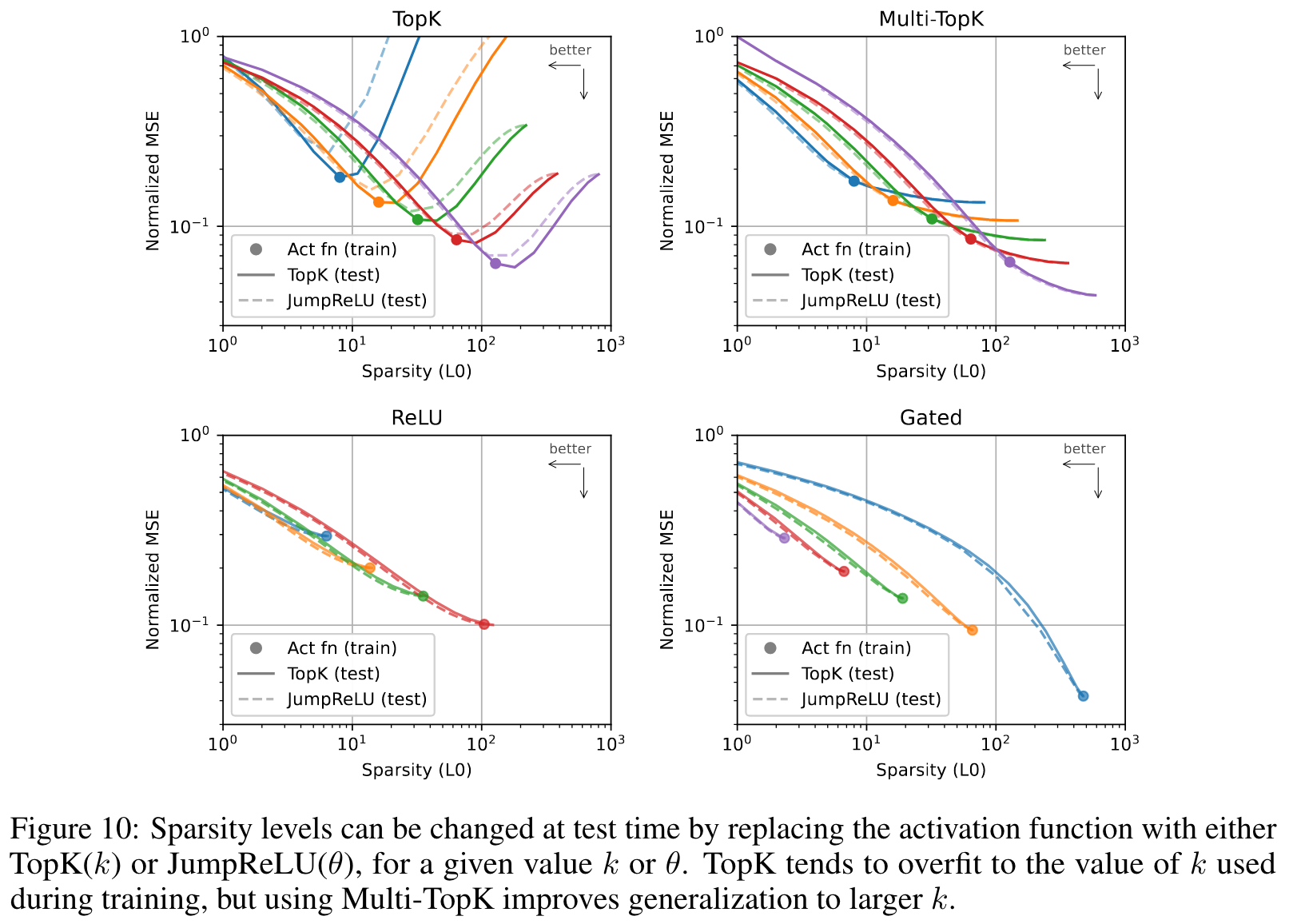
Limitations and Future Directions
- TopK forces every token to use exactly latents, which is likely suboptimal. Ideally we would constrain rather than .
- The optimization can likely be greatly improved, for example with learning rate scheduling, better optimizers, and better aux losses for preventing dead latents.
- Much more could be done to understand what metrics best track relevance to downstream applications, and to study those applications themselves. Applications include: finding vectors for steering behavior, doing anomaly detection, identifying circuits, and more.
- We're excited about work in the direction of combining MoE and autoencoders, which would substantially improve the asymptotic cost of autoencoder training, and enable much larger autoencoders.
- A large fraction of the random activations of features we find, especially in GPT-4, are not yet adequately monosemantic. We believe that with improved techniques and greater scale this is potentially surmountable.
- Our probe based metric is quite noisy, which could be improved by having a greater breadth of tasks and higher quality tasks.
- While we use N2G for its computational efficiency, it is not only able to capture very simple patterns. We believe there is a lot of room for improvement in terms of more expressive explanation methods that are also cheap enough to simulate to estimate explanation precision.
- A context length of 64 tokens is potentially too few tokens to exhibit the most interesting behaviors of GPT-4.
Related Work
Malllat 和 Zhang 引入了在超完整字典上的稀疏编码。Olshausen 和 Field 通过无监督的方法从数据中学习字典改善了此方法。这种方法在图像处理中影响极大。之后 Hinton 和 Salakhutdinov 提出了自动编码器结构以降低维度。结合这些概念,人们开发了 SAE 以训练具有稀疏先验的自动编码器,例如使用惩罚来提取稀疏特征。Makhzani 和 Frey 通过引入 K-Sparse autoencoder,使用 TopK 激活功能而不是 惩罚 来完善这一概念。 Makelov 等人使用度量标准来自动评估编码器,该指标可以测量从先前发现的回路中恢复特征。
最近,将 SAE 用于语言模型,并且有多种 SAE 在开源的小模型上进行训练。Mark 等人发现SAE 可以从语言模型中发现回路。Wright 和 Sharkey 指出 SAE 会受到 惩罚激活缩小。Taggart 和 Rajamanoharan 建议使用不同的激活来解决 SAE 中的激活收缩问题。Braun 等人建议在下游 KL 上训练 SAE,而不是重建 MSE。
Kaplan 等人研究了语言模型的缩放定律,这些定律发掘了损失如何随各种超参数而变化。Clark 等人使用双线性你和探索与稀疏有关的缩放定律。Lindsey 等人研究了专门针对自动编码器的缩放定律,将损失定义为重建和稀疏性的特定平衡(而不是简单地重建)。
🤖ChatGPT
ChapGPT
1. 论文的创新之处与独特性:
这篇论文提出并系统评估了稀疏自动编码器在处理大型语言模型激活数据中的应用,特别是在GPT-4的残差流中。这项工作具有几个创新之处:
- 使用k-稀疏自动编码器:论文采用了k-稀疏自动编码器,这种方法通过限制活跃的潜在变量数量直接控制稀疏性,简化了超参数调优,显著提高了稀疏性和重构精度之间的平衡。
- 解决了死神经元问题:通过引入初始化和辅助损失,显著减少了在大规模训练中出现的死神经元问题,使得在极大规模的稀疏自动编码器中(如16百万潜在变量的模型)依然能够保持高效的训练。
- 提出了新的评价指标:为评估稀疏自动编码器的特征质量,论文引入了一系列新的评价指标,包括对假设特征的恢复、激活模式的可解释性和下游影响的稀疏性,推进了对模型可解释性和特征解读的研究。
- 稀疏自动编码器的扩展性:论文展示了稀疏自动编码器在极大规模条件下的扩展性,成功在GPT-4的40亿个token上训练了具有16百万潜在变量的自动编码器。
这些创新不仅在稀疏性和可解释性方面进行了探索,还推动了稀疏自动编码器的规模扩展能力研究。
2. 论文中存在的问题及改进建议:
虽然论文具有许多创新点,但仍有一些问题值得改进:
- 稀疏性的固定限制:使用TopK方法时,每个token的稀疏性L0是固定的,这可能导致在某些情况下的表达能力不足。改进建议是引入更加灵活的稀疏性约束,例如平均稀疏性约束(E[L0]),允许在特定情况下动态调整稀疏性。
- 优化过程的改进空间:论文提到优化过程(如学习率调度和更好的优化器)可以显著改善性能。建议未来的工作中探索自适应优化器(如RMSProp或AdamW)以及多步学习率衰减方案,提升收敛速度和性能。
- 更多的特征解释:虽然引入了N2G(Neuron to Graph)解释方法来捕捉激活的n-gram模式,但其表达能力有限,建议引入更具表现力的特征解释方法,如基于深度生成模型的特征重构或图模型方法,增强解释的精度和通用性。
3. 基于论文的内容和研究结果,提出的创新点或研究路径:
- 自适应稀疏性自动编码器:探索一种可以动态调整稀疏性L0的自动编码器,允许模型根据输入数据自适应调整稀疏性水平,优化模型在不同复杂度输入下的表现。
- 多尺度特征表示的稀疏自动编码器:设计一个基于多尺度特征表示的自动编码器,能够捕捉不同抽象层次的特征,同时保持较高的稀疏性,提升模型对复杂数据的解读能力。
- 结合稀疏自动编码器的混合专家模型(MoE):研究如何将稀疏自动编码器与混合专家模型结合,利用MoE模型的高效计算特性,在提升自动编码器表达能力的同时减少训练和推理时的计算成本。
4. 为新的研究路径制定的研究方案:
研究路径1:自适应稀疏性自动编码器
- 研究方法:设计一种自适应TopK机制,通过引入一种稀疏性控制模块(如基于LSTM或变分推断的方法),使得模型能够根据输入自适应调整每层的稀疏性L0。模型训练过程中,动态调整每个token的激活神经元数量,确保稀疏性与数据复杂度匹配。
- 步骤:
- 设计自适应稀疏性模块,允许模型动态调整稀疏性L0。
- 在GPT-2和GPT-4的激活数据上进行实验,比较固定L0和自适应L0的效果。
- 评估模型在重构精度、稀疏性控制和下游任务性能上的表现。
- 期望成果:自适应稀疏性模型在处理复杂输入时,能够表现出更高的灵活性,同时保持稀疏性控制,提升整体模型的表达能力。
研究路径2:多尺度特征表示的稀疏自动编码器
- 研究方法:设计一种多尺度自动编码器结构,利用不同规模的潜在表示来捕捉不同抽象层次的特征,结合稀疏性约束,使得模型能够以稀疏的方式表示多尺度特征。
- 步骤:
- 设计一种多尺度的稀疏自动编码器架构,每一层潜在空间表示不同尺度的特征。
- 在GPT-4激活数据上进行实验,验证模型对不同层次特征的捕捉能力。
- 通过下游任务评估模型的泛化能力和可解释性。
- 期望成果:多尺度稀疏自动编码器可以有效捕捉语言模型中的不同层次特征,提升模型对复杂语言现象的解析能力,并增强可解释性。
研究路径3:结合稀疏自动编码器的混合专家模型(MoE)
- 研究方法:将稀疏自动编码器与MoE模型结合,利用MoE模型的专家模块选择机制,实现稀疏自动编码器在处理复杂任务时的高效计算,同时减少训练和推理时的计算成本。
- 步骤:
- 设计一个结合稀疏自动编码器和MoE的模型框架,在每个输入token上选择特定的专家模块进行激活。
- 在GPT-4数据上验证该框架的性能,重点评估模型的计算效率和下游任务表现。
- 对比单一稀疏自动编码器和混合专家模型的性能差异。
- 期望成果:结合MoE的稀疏自动编码器在处理大规模语言模型数据时能够显著减少计算资源需求,并保持或提升模型的解读能力和下游任务性能。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!