目录
Resource Info Paper https://arxiv.org/abs/2409.14781 Code & Data https://github.com/zhang-wei-chao/DC-PDD Public EMNLP Date 2024.12.11
Summary Overview
最近,已经探讨了通过Black-box访问来推断给定文本是否是LLM培训数据的一部分的数据检测方法。达到最先进结果的Min-K%ProP方法假设一个非训练示例倾向于包含一些具有低令牌概率的异常单词。但是,有效性可能受到限制,因为它倾向于错误分类的非训练文本,这些文本包含许多常见单词,其概率很高。
文章聚焦于检测 LLM 预训练数据检测 (Pretraining Data Detection),提出了 DC-PDD 方法进行检测。
How can we detect if a black-box LLM was pretrained on a given text, considering that its training data is undisclosed?
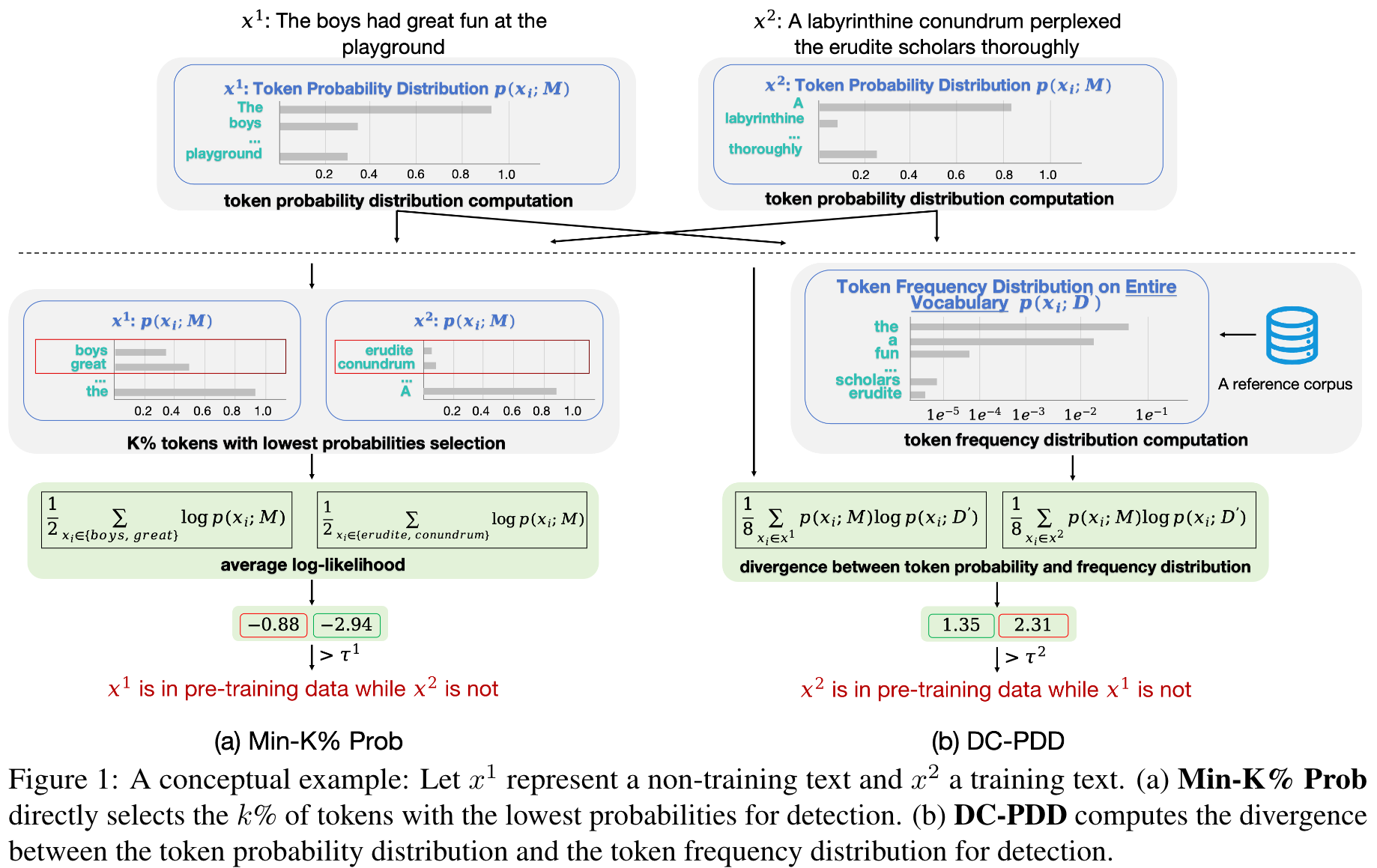
Main Content
使用 divergence-from-randomness 的基本思想是,the higher divergence of the within-document term-frequency of a word in a document from its frequency within the collection, the more information the word carries.
使用的 benchmark
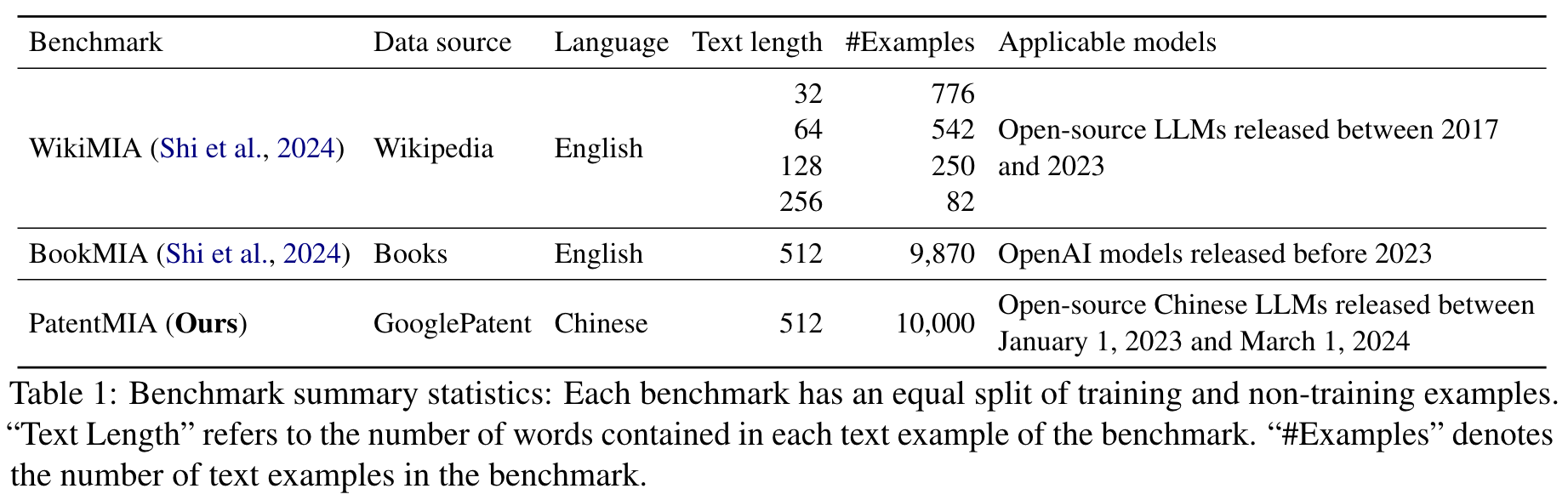
Task Description:
Formally, given a piece of text and an LLM with no knowledge of its pretraining corpus , the pretraining data detection task aims to design a method to determine if was included in . Thus, given and as input, a method for the pretraining data detection task returns 1 if it predicts that is included in and 0 if it is not:
PatentMIA 构建:
- Data crawling: 随机爬取了5000个在2024.03.01之后的中国专利页面和5000个在2023.01.01之前的中国专利页面。
- Data preprocessing: 预处理 + 数据清洗
- Snippet extraction: 对于每个页面,从原始内容中随机提取512个单词的片段,创建了10,000个实例的数据集。
Four steps of DC-PDD:
- Token probability distribution computation, by querying with .
- Token frequency distribution computation, by using a large-scale publicly available corpus as reference corpus to obtain an estimation of the token frequency distribution since 's pretraining corpus is not assumed to be accessible.
- Score calculation via comparision, by comparing the above two distributions to calibrate the token probability for each token in , and dervie a score for pretraining data detection based on the calibrated token probabilities.
- binary decision, by applying a predefined threshold to the score, we predict whether was included in 's pretraining corpus or not.

Token Probability Distribution Computation
simplify to
Token Frequency Distribution Computation
加一平滑:
Score Calculation through Comparison
Binary Decision
Related Work
大多数研究都集中在黑框设置上,假设文本的令牌概率分布可以提供有关文本是否包含在培训集中的重要信息。 Carlini等。 (2021)将文本的模型视为检测GPT-2预处理数据的指标(Radford等,2019)。他们进一步介绍了三种方法,即Zlib,小写和较小的Ref,这些方法考虑了目标文本的内在复杂性。最近,Shi等人。 (2024年)提出了一种称为Min-k%概率的直接但表现良好的方法。 Min-k%概率倾向于将由常用单词组成的非训练文本分类为培训数据。一项并发研究Min-k%++概率(Zhang等,2024)通过标准化令牌概率来改善Min-k%概率,但需要访问LLM的整个词汇量之间的下一个预测概率分布,这在不可避免的情况下是不可接受的关闭llms等gpt-3(Brown等,2020)。我们考虑黑盒子设置和Calibra
Experiments
Metrics
Area Under the ROC Curve (AUC). AUC分数量化了分类方法的整体性能。为了计算AUC分数,需要在所有分类阈值下计算正式的正确率 (TPR) 和假阳性率 (FPR),并绘制 TPR 与 FPR 曲线 (ROC) 曲线。然后将 AUC 定义为 ROC 曲线下的面积,提供了所有可能分类阈值的效果的总测量。因此 AUC 提供了一个全面的,阈值独立的分数,可以反映该方法有效区分正案例和负面案例的能力。
TPR (true positive rate) at a low FPR (false positive rate). 通过调整阈值,选择5%作为目标FPR值,并报告相应的TPR值,以较低的FPR报告TPR。
Baselines
- PPL
- Lowercase
- Zlib
- Small Ref
- Min-k% Prob
- Min-k%++Prob
Results
Main Results


Ablation Studies
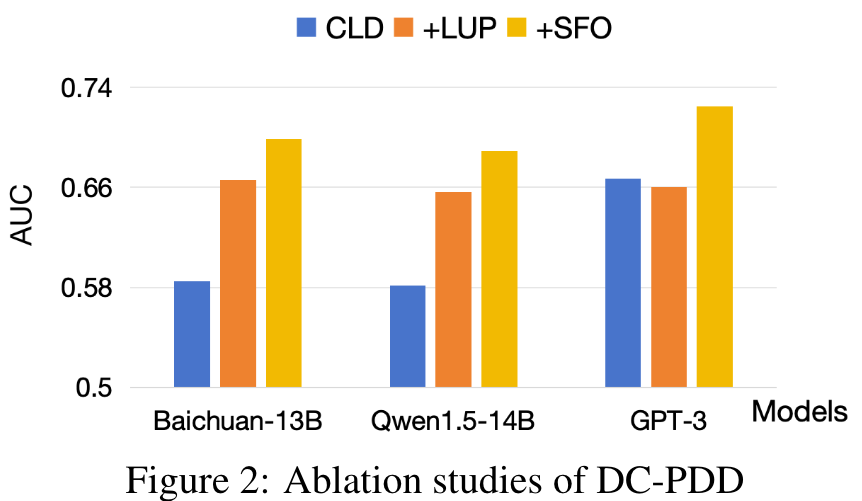
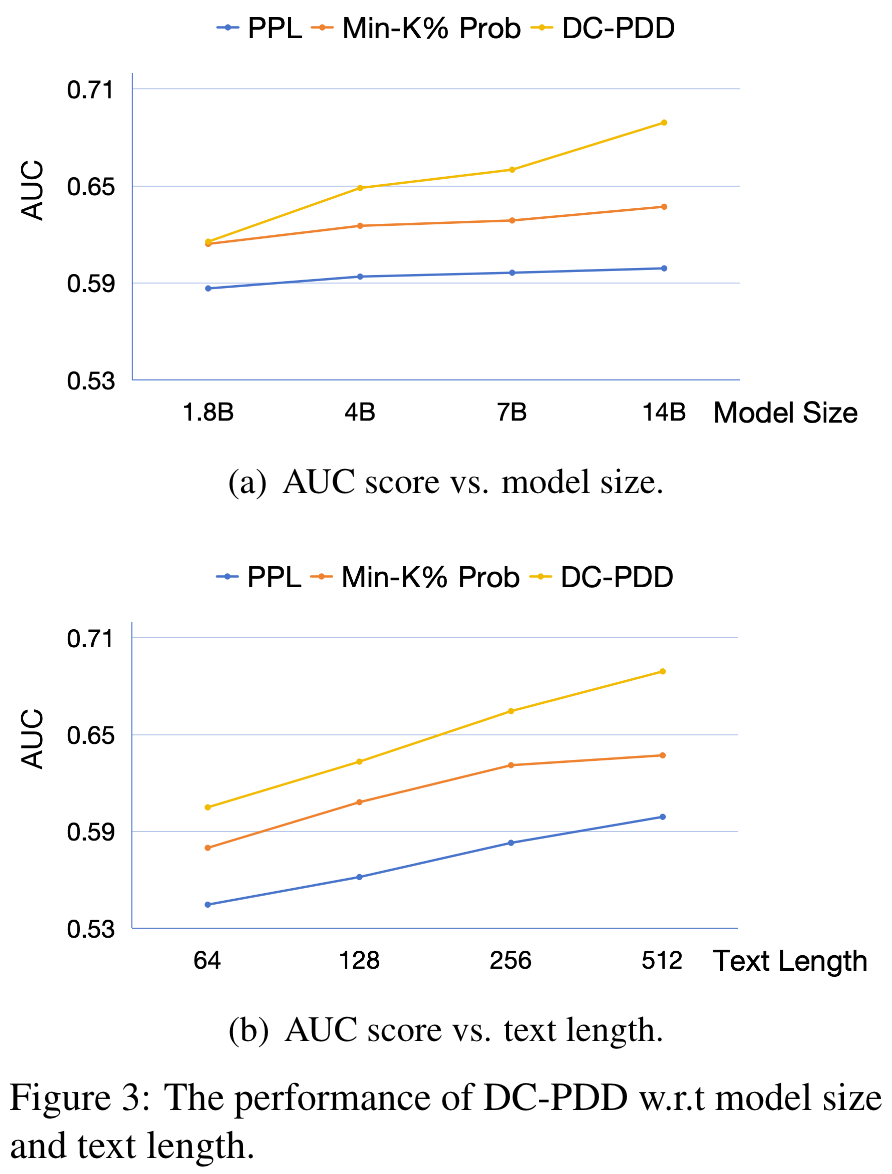
Impact of Different Factors
- model size and text length
- different reference corpus settings
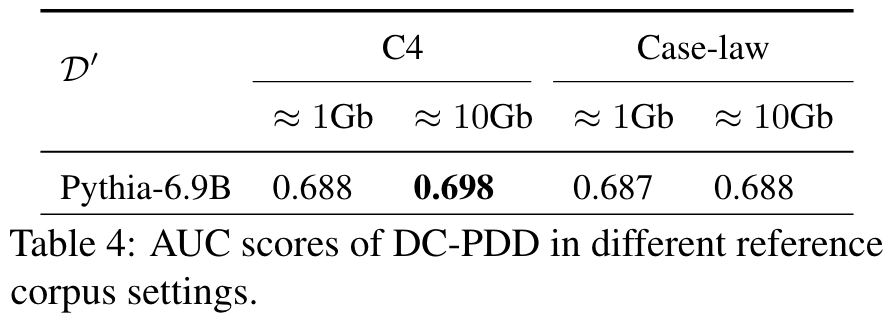
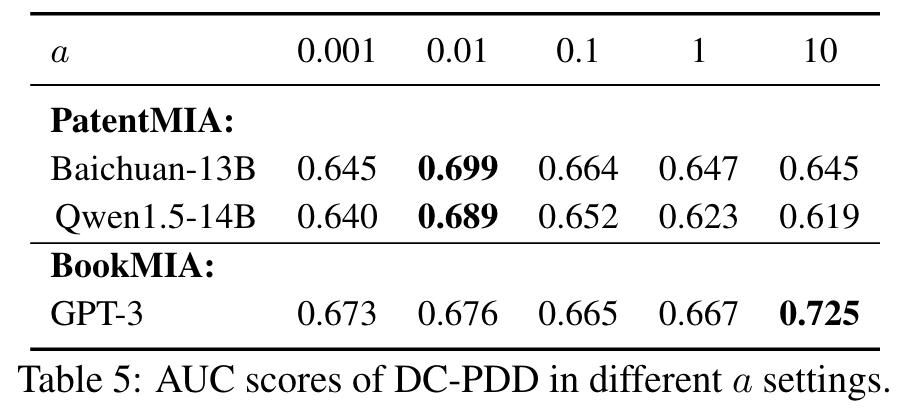
- different settings
🤖ChatGPT
ChapGPT
- 论文的创新之处与独特性:
-
创新点:
- 提出了一种基于“随机性偏离”理论的校准方法(DC-PDD),通过计算目标语言模型的预测概率分布与参考语料的词频分布之间的交叉熵(即散度),校准每个词的概率,用于检测给定文本是否属于语言模型的预训练数据。这种方法克服了现有方法对高频词的误分类问题,显著提升了检测性能。
- 构建了首个中文预训练数据检测基准数据集PatentMIA,通过谷歌专利数据区分训练与非训练样本,填补了现有研究在非英语语料上的空白。
- 提出的DC-PDD方法无需额外的参考模型或对目标语言模型的额外访问权限,降低了实际应用的复杂性,具备更高的通用性和可扩展性。
-
关键点:
- 通过散度校准改进了基于概率的检测方法,显著提高了检测的准确性和鲁棒性。
- 提供了跨语言基准(包括英语和中文)的全面实验,验证了方法的适用性和优越性。
- 系统性地分析了文本长度、模型规模、参考语料等因素对检测性能的影响,为后续研究提供了重要的启示。
- 论文中存在的问题及改进建议:
-
问题:
- 参考语料的局限性:虽然论文使用公开语料库(如C4和ChineseWebText)估算目标模型的词频分布,但这些语料与目标模型的实际预训练语料可能存在较大差异,可能影响校准结果的准确性。
- 超参数敏感性:DC-PDD方法对校准概率的上限参数(a)较为敏感,不同数据集和模型需要不同的参数设置,缺乏通用的优化策略。
- 模型规模的限制:实验主要集中在20亿参数以下的模型,未能验证方法在更大规模模型(如GPT-4级别)上的有效性。
- 方法的适用范围:DC-PDD方法主要针对文本数据,缺乏对多模态数据(如图像、音频等)的适用性讨论。
-
改进建议:
- 增强参考语料的多样性:引入更大规模、更丰富领域的参考语料库,或设计基于生成模型的动态语料扩充方法,以提高词频分布估计的准确性。
- 自动化超参数优化:探索基于贝叶斯优化或强化学习的自动化方法,为不同任务动态调整参数a,减轻人工调参的负担。
- 扩展到更大模型:在硬件条件允许的情况下,验证方法在更大规模模型(如GPT-4、Claude等)上的有效性,进一步提升方法的通用性。
- 探索多模态扩展:将“散度校准”思想扩展到图像、音频等多模态数据,通过结合跨模态特征分布,设计统一的预训练数据检测框架。
- 基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:开发基于生成对抗网络(GAN)的动态参考语料生成方法,用于改进DC-PDD的词频分布估计。
- 创新点2:设计一种跨模态预训练数据检测框架,结合文本、图像和音频的特征分布,扩展DC-PDD的适用范围。
- 创新点3:研究基于模型输出的全黑盒检测方法,避免对目标模型的概率分布访问需求,提升检测方法的适用性。
- 为新的研究路径制定的研究方案:
研究路径1:基于GAN的动态参考语料生成
-
研究方法:
- 使用生成对抗网络(GAN)生成与目标模型预训练语料相似的参考语料。
- 通过对生成语料的词频分布与真实语料的分布进行对比,选择最接近的生成样本构建参考语料库。
- 将动态生成的参考语料用于DC-PDD方法,重新计算词频分布并校准检测分数。
-
研究步骤:
- 收集目标模型可能使用的预训练语料样本,作为GAN的初始训练数据。
- 设计GAN生成器和判别器,优化生成语料的质量和多样性。
- 对比生成语料与目标模型的预测分布,选择最优参考语料。
- 在现有基准数据集(如PatentMIA)上验证改进方法的性能。
-
期望成果:
- 提高DC-PDD方法对参考语料选择的鲁棒性,显著提升检测准确性。
- 发布一套可扩展的动态参考语料生成工具,为其他预训练数据检测任务提供支持。
研究路径2:跨模态预训练数据检测框架
-
研究方法:
- 将文本、图像和音频等模态数据的特征分布映射到统一的潜在空间。
- 基于散度校准思想,计算每种模态的特征分布与参考语料分布之间的散度。
- 设计融合策略,将多模态散度综合为统一的检测分数。
-
研究步骤:
- 构建跨模态数据集,包括文本、图像和音频的配对样本。
- 设计跨模态特征提取网络,确保不同模态的特征可以在潜在空间中对齐。
- 在每种模态上分别计算散度校准分数,并设计融合策略(如加权平均或注意力机制)。
- 在多模态基准数据集上验证方法性能,并与单模态方法对比。
-
期望成果:
- 提出首个支持多模态预训练数据检测的通用框架。
- 实现跨模态检测性能的显著提升,为多模态模型的透明性研究提供新工具。
研究路径3:基于模型输出的全黑盒检测方法
-
研究方法:
- 通过分析目标模型的生成输出特征(如生成文本的重复率、语义一致性等),提取与预训练数据相关的信号。
- 设计无监督聚类方法,将生成输出分为可能的训练数据和非训练数据两类。
- 利用对抗样本生成技术,进一步验证模型对训练数据的敏感性。
-
研究步骤:
- 收集目标模型在不同输入条件下的生成输出,构建输出特征库。
- 提取生成输出的统计特征,并分析特征与训练数据的相关性。
- 设计基于特征的聚类算法,预测生成输出是否来自训练数据。
- 在现有基准数据集上验证方法性能,并分析与概率分布方法的差异。
-
期望成果:
- 提出一种完全黑盒的预训练数据检测方法,适用于封闭源模型。
- 为语言模型的隐私保护和数据透明性研究提供新思路。
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!