目录
Resource Info Paper https://arxiv.org/abs/2305.04207 Code & Data https://github.com/FudanSELab/ChatTester/tree/main Public FSE Date 2024.12.16
Summary Overview
尽管传统技术能够以合理的覆盖范围生成测试,但证明它们的可读性较低,而开发人员在实践中仍然无法直接采用。在这项工作中,我们执行了第一项经验研究,以评估ChatGpt(即,在代码生成和理解中具有出色表现的最具代表性的LLM之一)的能力。我们进一步提出了ChatTester,这是一种基于ChatGPT的新型单元测试生成方法,该方法利用ChatGPT来提高其生成的测试的质量。
Main Content
Unit test:
- test prefix: 测试前缀通常是一系列方法调用语句或分配语句,旨在将 focal method 推向可测试状态。
- test oracle: 用作检查 focal method 当前行为是否满足预期的规范。
传统的单元测试生成技术利用基于搜索 (search-based),基于约束 (constraint-based) 或基于随机的策略 (random-based)生成一套单元测试,其主要目标是最大化测试软件中的覆盖范围。
为了启用全面的评估,我们首先构建了1,000个Java焦点方法的数据集,每种方法以及完整且可执行的项目环境。我们合并了为每种焦点方法生成单元测试的CHATGPT,并分析生成测试的质量以回答以下四个研究问题。
- RQ1 (Correctness): How is the correctness of the unit tests generated by ChatGPT?
- RQ2 (Sufficiency): How is the sufficiency of the unit tests generated by ChatGPT?
- RQ3 (Readability): How is the readability of the unit tests generated by ChatGPT?
- RQ4 (Usability): How can the tests generated by ChatGPT be used by developers?
ChatTester包括初始测试生成器和迭代测试修改器。初始测试生成器将测试生成任务分解为两个子任务,通过(i)首先利用ChatGPT通过意图提示来理解焦点方法,然后(ii)利用ChatGPT与生成意图一起生成焦点方法的测试通过一代提示。然后,迭代测试修改器迭代地修复了初始测试生成器生成的测试中的汇编错误,该测试生成的测试遵循验证和固定范式以根据编译错误消息和其他代码上下文提示ChatGPT。
- RQ5 (Improvement): How effective is ChatTester in generating correct tests compared to ChatGPT? How effective is each component in ChatTester?
- RQ6 (Generalization): How effective is ChatTester in improving the quality of generated tests when applied to other LLMs?
- RQ7 (Project-level Effectiveness): How effectiness is ChatTester when applied to the entire projects?
Study Setup
Benchmark
Project Collection:
Two criteria:
- the project is under continuous maintenance (i.e., the project should have been updated as of January 1, 2023);
- the project has at least 100 stars;
- the project is built with Maven framework (for the ease of test executions) and it could be successfully compiled in our local environment
Data Pair Collection: 我们从185个Java项目中提取数据对。每个数据对均指焦点方法及其相应的测试方法。
Following steps:
- Given a Java project, we first find all the test classes in the project. If a class contains at least one method annotated with
@Test, we regard this classes as a test class and collect all the test methods in this test class. - We then find the corresponding focal method for each test method based on the file path and the class name matching.
Basic Prompt Design

Two parts:
- the natural language description part (i.e., NL part) that explains the task to ChatGPT.
- the code context part (i.e., CC part) that contains the focal method and the other relevant code context.
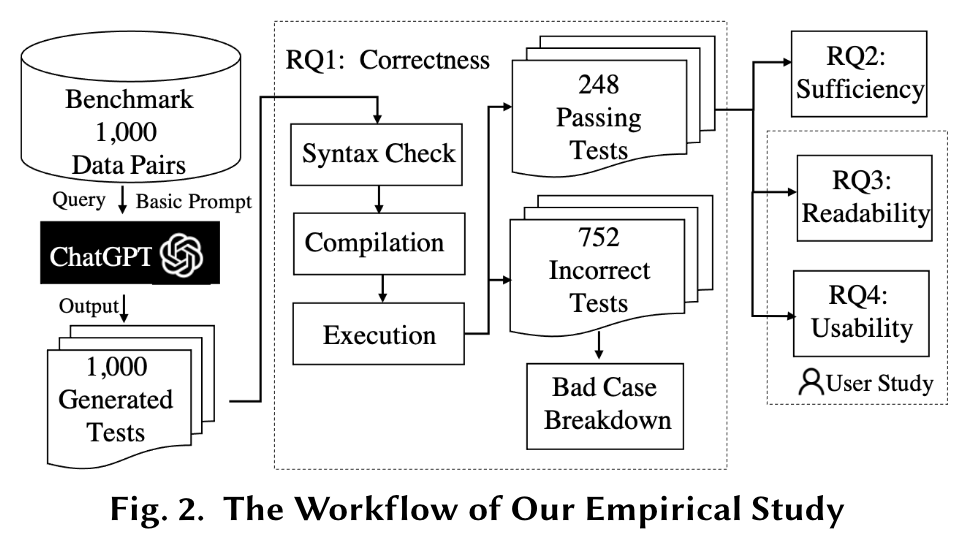
Experimental Procedure
RQ1: Correctness
Three metrics:
- syntactic correctness (whether the test could pass the syntax checker)
- compilation correctness (whether the test could be successfully compiled)
- execution correctness (whether the test could pass the execution)
RQ2: Sufficiency
- the statement coverage of the test on the focal method
- the branch coverage of the test on the focal method
- the number of assertions in the test case
RQ3 & RQ4: User study for readability and usability
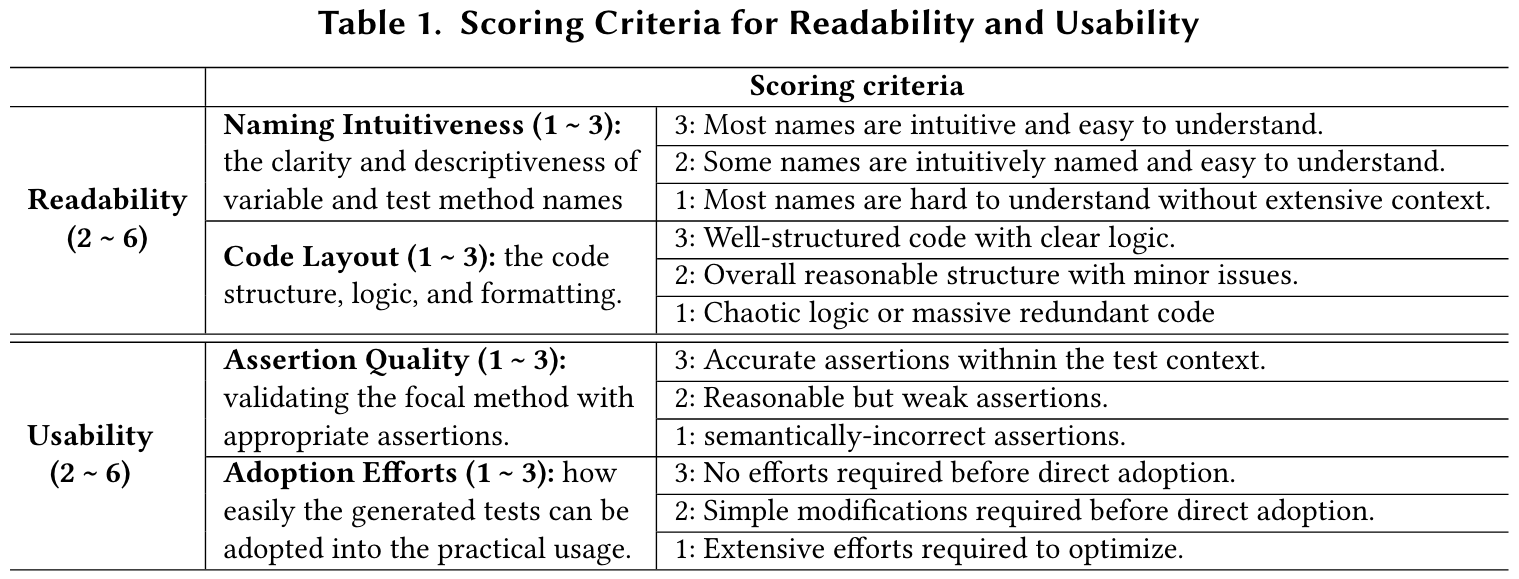
Study Results


Enlightenment: two directions
- to provide ChatGPT with deep knowledge about the code
- to help ChatGPT better understand the intention of the focal method, so as to reduce its compilation errors and assertion errors, respectively
Approach of ChatTester
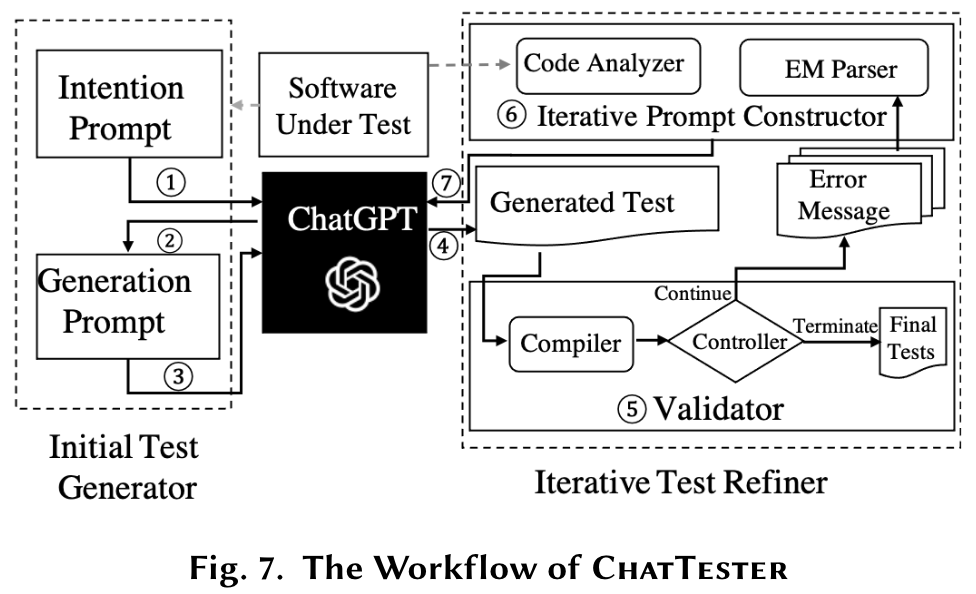
Initial Test Generator
- first leveraging ChatGPT to understand the focal method via the intention prompt
- then leveraging ChatGPT to generate a test for the focal method along with the generated intention via the generation prompt

Iterative Test Refiner
- first validating the generated test by compilinig it in a validation environment
- second constructing a prompt based on the error message during compilation and the extra code context related to the compilation error

Iterative Prompt Constructor
- an EM parser that analyzes the error message about the compilation error
- a code analyzer that extracts the additional code context related to the compilation error
- Error type
- Buggy location
- Buggy element
Evluation Results
RQ5

Cost and number of iterations
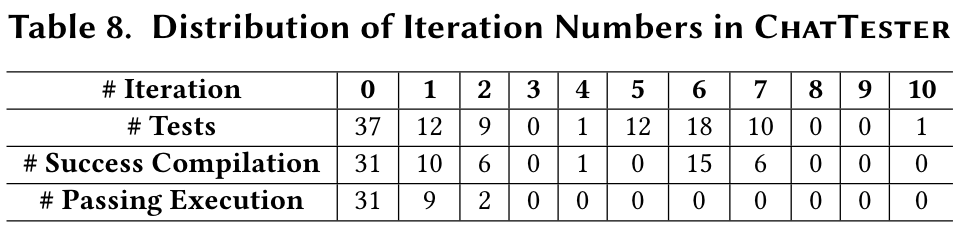
"#Iteration"显示了迭代的数量;"#Tests"显示了此迭代中仍在完善的测试数量;"#Success Compilation"和"#Passing Execution"分别显示了在当前迭代中成功编译和执行的测试数。
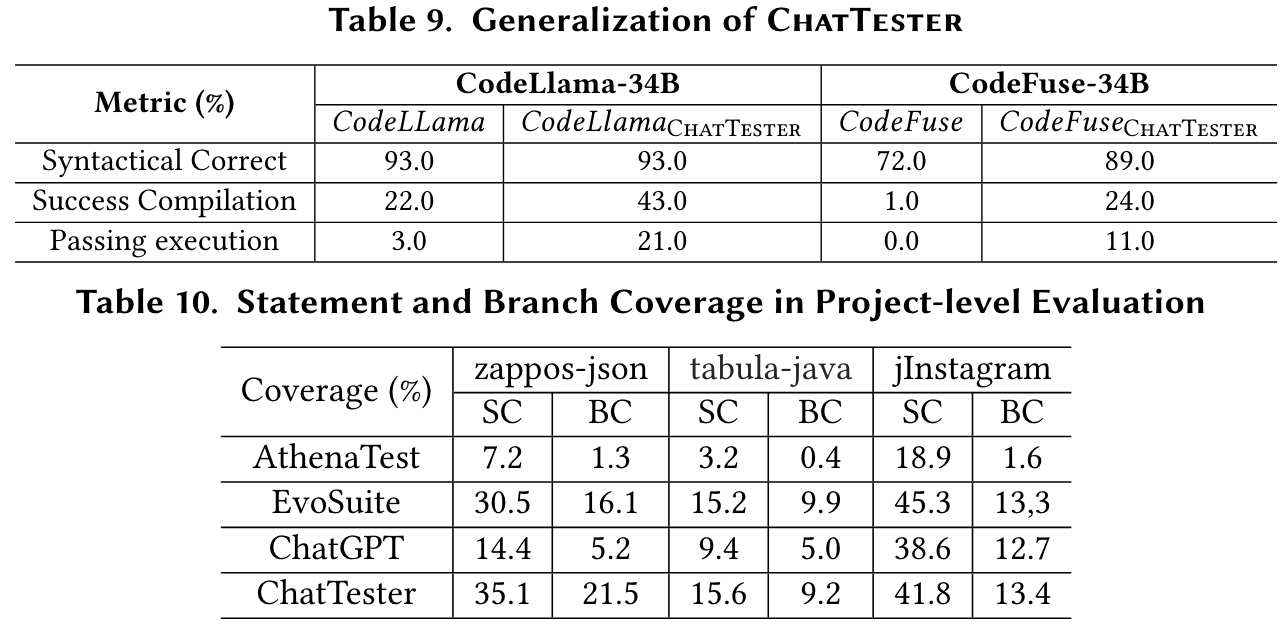
RQ6
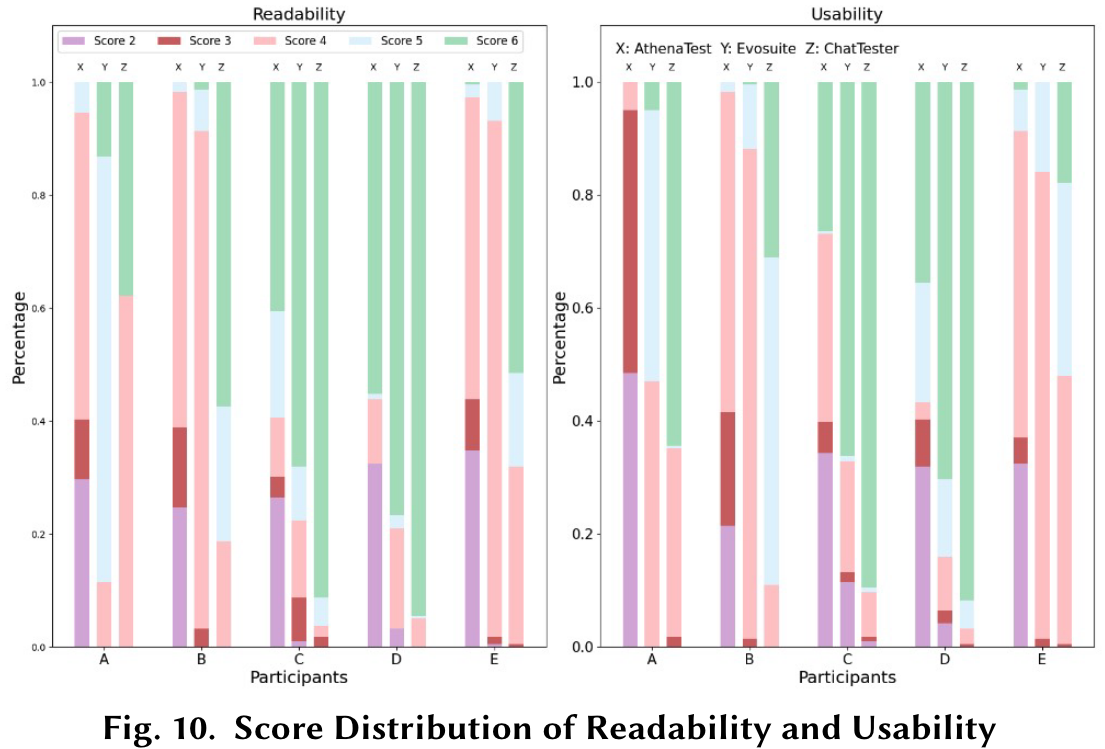
RQ7
表10显示了ChatTester在每个项目中生成的测试以及所有基准生成的测试的说明覆盖范围("SC")和分支覆盖范围("BC")。
Related Work
LLMs for Test Generation
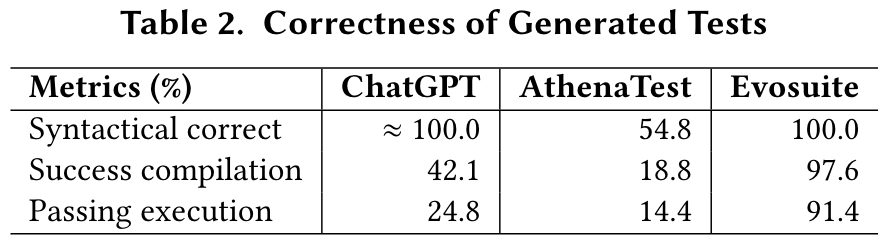
一种典型的基于LLM(大语言模型)的测试生成技术类别主要将测试生成视为一个神经机器翻译问题[54, 73](即,从目标方法到相应的测试前缀或测试断言),并在测试生成数据集上微调LLM。例如,AthenaTest [73] 在一个测试生成数据集上对BART [14] 进行微调,该数据集的输入是包含相关代码上下文的目标方法,而输出是完整的测试用例。我们的研究结果表明,ChatGPT在生成更高正确性和覆盖率的测试方面优于AthenaTest。
最近,随着指令调优LLM的快速发展,越来越多的测试生成技术通过合适的提示(prompt)利用指令化的LLM,而非微调模型[21, 22, 81]。例如,将复杂任务分解为更小的任务(如链式思维推理[80]和树式思维推理[85])已被证明是有效的提示策略,这些也是启发ChatTester的高级理念。Nashid等人[53]提出了一种基于检索的提示构造策略,通过少样本查询Codex生成测试断言。而与他们的工作不同,我们的研究专注于零样本学习场景,生成包括测试前缀和测试断言在内的完整测试用例。
CODAMOSA [46] 通过使用Codex生成的测试来增强传统的基于搜索的技术,以帮助其在搜索过程中摆脱“平台期”。实际上,ChatTester可以与CODAMOSA形成互补关系,因为ChatTester旨在通过LLM为给定的目标方法生成一个测试,而CODAMOSA则通过结合LLM和基于搜索的算法为给定模块生成一组测试。因此,ChatTester可以在CODAMOSA的搜索过程中提供更高质量的测试作为种子。
LIBRO [43] 利用Codex为给定的错误报告生成测试。而与LIBRO不同,我们的研究专注于没有错误报告的测试生成场景。Li等人[48] 提出了差异化提示(differential prompts),通过ChatGPT生成导致失败的测试输入,该方法侧重于通过LLM生成测试输入,而我们的工作专注于生成包括测试输入和测试代码(例如测试前缀)在内的完整单元测试用例。
Ring System [42] 和 TestPilot [69] 也分别使用LLM进行测试生成和错误修复。Ring System采用单轮的方法,专注于特定的代码片段,而我们的工具ChatTester通过与LLM进行多轮对话的方式进行迭代优化,并引入额外的代码上下文以提高准确性。TestPilot与ChatTester在其反馈机制上有所不同,TestPilot通过目标方法搜索代码片段,而ChatTester从错误信息中提取并利用额外的上下文信息以改进测试生成。
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 首次系统性评估ChatGPT在单元测试生成中的能力:论文通过大量实验(覆盖正确性、充分性、可读性和可用性)全面分析了ChatGPT生成单元测试的表现,为理解LLM在软件工程任务中的潜力提供了重要参考。
- 提出ChatTester框架:论文在发现ChatGPT生成测试存在准确性问题后,设计了ChatTester框架,通过初始测试生成器和迭代测试优化器两个模块显著提高了生成测试的正确性。这种利用LLM自身能力提升生成质量的思路具有启发性。
- 通用性验证:论文不仅在ChatGPT上验证了ChatTester的效果,还将其应用于开源LLM(如CodeLlama-Instruct和CodeFuse),显示了该方法的普适性。
- 综合实验与用户研究:论文结合自动化评估和用户研究,全面分析了生成测试的覆盖率、断言质量、可读性和开发者接受度,为未来研究提供了可靠的实验设计模板。
- 明确提出改进LLM生成测试的两大方向:即为LLM提供代码的深层知识以及帮助其更好地理解焦点方法的意图。这些方向为后续研究指明了路径。
-
论文中存在的问题及改进建议:
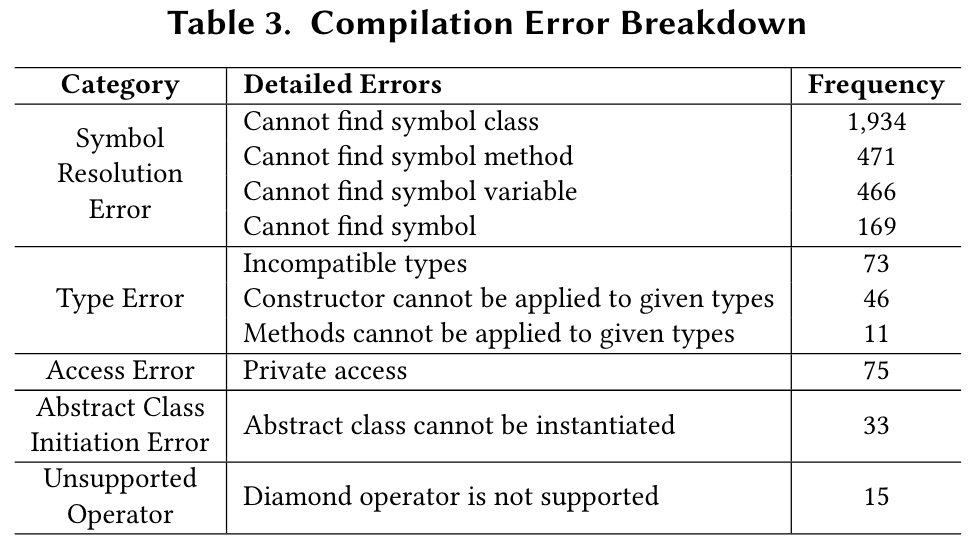
- 对生成测试失败原因的分析深度不足:虽然论文列举了错误类型,但对某些错误(如符号解析错误或断言错误)的深层次成因缺乏更具体的探讨。改进建议:结合ChatGPT的生成过程日志,分析错误生成的上下文和模式,从而更精准地定位问题。
- 对迭代优化的终止条件设置较为简单:论文中设置了固定的最大迭代次数,未深入探讨动态终止条件(如基于错误修复的收敛性)。改进建议:引入动态策略,例如基于错误类型的优先级或生成质量的实时评估,优化迭代效率。
- 对用户研究的范围限制:用户研究主要集中在Java开发者,且参与人数有限。改进建议:扩大参与者范围,涵盖更多编程语言和开发背景,同时引入更大规模的用户研究以提高结论的普适性。
- 对生成测试的执行错误处理不足:论文仅讨论了编译错误的修复,而未尝试优化执行错误的测试生成。改进建议:设计自动化的执行错误分析器,结合运行时信息生成更有效的修复提示。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:基于代码语义分析的深度上下文增强
针对ChatGPT生成测试的符号解析错误和类型错误,开发一种结合代码语义分析的上下文扩展方法,动态为LLM提供更完整的代码依赖关系和类型信息。 - 创新点2:多模态测试生成与验证框架
将LLM生成的测试与动态分析工具(如符号执行或模糊测试)结合,通过多模态验证进一步提升生成测试的覆盖率和正确性。 - 创新点3:基于用户反馈的自监督测试优化
利用开发者对生成测试的评分和修改建议,设计一个自监督学习框架,让LLM通过持续学习改进测试生成能力。
- 创新点1:基于代码语义分析的深度上下文增强
-
为新的研究路径制定的研究方案:
-
研究路径1:基于代码语义分析的深度上下文增强
- 研究方法:
- 开发一个代码语义分析模块,提取代码中的依赖关系、类型信息和访问权限。
- 将语义信息嵌入到LLM的提示中,动态调整生成测试的上下文。
- 比较增强后的LLM生成测试与原始测试在编译和执行正确性上的差异。
- 研究步骤:
- 收集多语言的代码和测试数据集(如Java、Python)。
- 实现语义分析模块并与ChatGPT集成。
- 设计实验评估生成测试的编译成功率、执行成功率和覆盖率。
- 期望成果: 提出一种通用的上下文增强方法,显著降低生成测试的符号解析错误和类型错误。
- 研究方法:
-
研究路径2:多模态测试生成与验证框架
- 研究方法:
- 使用LLM生成初始测试,并通过动态分析工具验证其覆盖率和正确性。
- 将分析结果反馈给LLM,生成修正后的测试。
- 设计实验比较单一LLM生成与多模态框架生成的测试质量。
- 研究步骤:
- 选择一个动态分析工具(如Evosuite或Pynguin)。
- 构建一个多模态测试生成框架,集成LLM和动态分析工具。
- 在不同规模和领域的项目中评估框架性能。
- 期望成果: 提出一种结合LLM与动态分析的多模态框架,提升测试生成的覆盖率和断言质量。
- 研究方法:
-
研究路径3:基于用户反馈的自监督测试优化
- 研究方法:
- 收集开发者对生成测试的评分和修改建议。
- 将用户反馈作为训练数据,微调LLM以改进生成能力。
- 设计实验验证优化后的LLM在用户满意度和测试质量上的提升。
- 研究步骤:
- 创建一个用户反馈收集平台,邀请开发者参与测试。
- 使用反馈数据微调LLM,优化生成策略。
- 比较优化前后LLM生成测试的可读性、可用性和开发者接受度。
- 期望成果: 提出一种基于用户反馈的自监督优化框架,实现LLM对开发者需求的更高适配性。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!