目录
Resource Info Paper https://arxiv.org/abs/2412.08905 Code & Data / Public arXiv Date 2024.12.17
Summary Overview
这篇是 Phi-4 的技术报告,将模型训练分为了三个阶段 (Pretraining, Midtraining, Post-Training),主要聚焦在各个阶段的数据构造和配比,并且在 Post-Training 阶段提出了用于构造 DPO 对的新技术 pivotal token search。
phi-4 strategically incorporates synthetic data throughout the training process.
Main Content
Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
Principles. Our approach to generating synthetic data fo phi-4 is guided by the following principles:
- Diversity: The data should comprehensively cover subtopics and skills within each domain. This requires curating diverse seeds from organic sources.
- Nuance and Complexity: Effective training requires nuanced, non-trivial examples that reflect the complexity and the richness of the domain. Data must go beyond basics to include edge cases and advanced examples.
- Accuracy: Code should execute correctly, proofs should be valid, and explanations should adhere to established knowledge, etc.
- Chai-of-Thought: Data should encourage systematic reasoning, teaching the model various approaches to the problems in a step-by-step manner. This fosters coherent outputs for complex tasks.
Targeting High-quality Web Data
- Targeted Acquisitions
- Filtering Web Dumps
- Multilingual Data
- Custom Extraction and Cleaning Pipelines
Two key observations
- Web datasets showed small benefits on reasoning heavy benchmarks. Prioritizing more epochs over our synthetic data led to better performance with respect to adding fresh web tokens.
- Models trained only with synthetic data underperformed on the knowledge-heavy benchmarks and demonstrated increased hallucinations.
Pivotal Token Search


Pivotal Token Search (PTS) 是一种用于生成偏好数据的技术,旨在识别生成序列中对模型成功率具有关键影响的“关键性”令牌(pivotal tokens)。这一方法通过分析模型在生成每个令牌时的正确率变化,找到那些对生成结果有显著影响的令牌,并将其用于优化模型的偏好学习流程(如 Direct Preference Optimization, DPO)。
背景与动机
在生成任务中,部分令牌对最终结果的正确性有着决定性作用,而其他令牌的影响则较小甚至会引入噪声。例如,在数学推导或编码任务中,某些关键步骤的输出可能会显著改变问题解决的方向。这些关键令牌被称为“pivotal tokens”。PTS 的目标是:
- 识别这些关键令牌,并生成能够突出它们影响的数据。
- 减少噪声:避免非关键令牌对优化过程的干扰。
- 提高训练效率:通过聚焦关键令牌,增强模型在推理和问题解决中的表现。

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 数据质量优先的训练策略:论文强调通过高质量的合成数据来提升模型性能,尤其是在推理和问题解决任务上的表现。这种策略展示了在计算资源有限的情况下,通过优化数据质量而非单纯扩大模型规模也能取得显著提升。
- 合成数据的多样化生成方法:引入了多代理提示(multi-agent prompting)、自我修订(self-revision)和指令反转(instruction reversal)等创新方法,生成高复杂度和多样化的合成数据,尤其适用于推理和问题解决任务。
- 后训练阶段的优化技术:论文提出了基于拒绝采样(rejection sampling)和关键标记搜索(Pivotal Token Search, PTS)的直接偏好优化(DPO)方法。这些技术显著提高了模型在数学、代码等推理密集型任务上的表现。
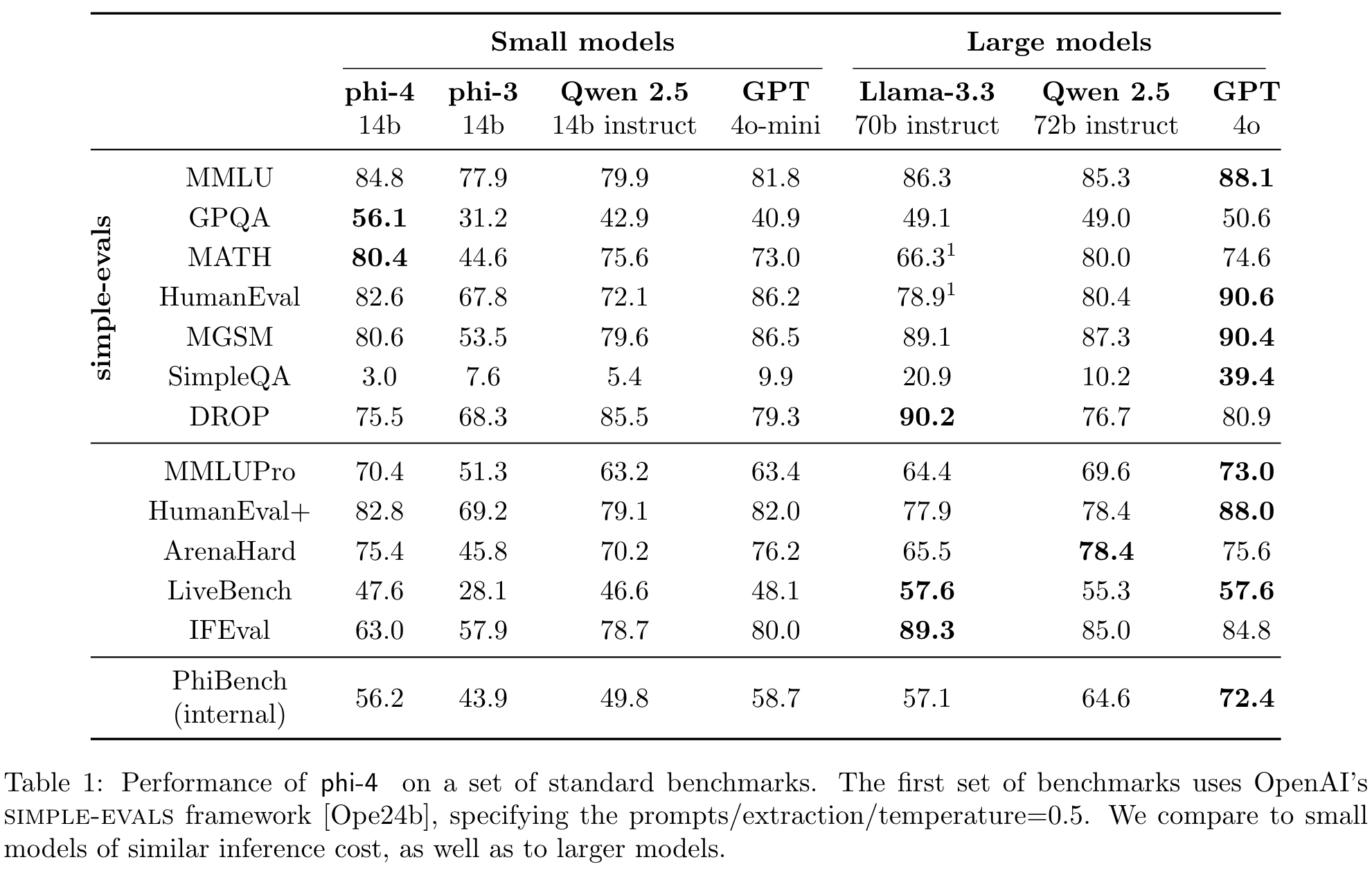
- 高效的小模型性能:Phi-4 模型在多个推理相关基准测试中表现优异,甚至超越了其教师模型 GPT-4o 和一些更大规模的模型(如 Llama-3.3-70B),证明了小规模模型通过优化数据和训练策略可以实现性能突破。
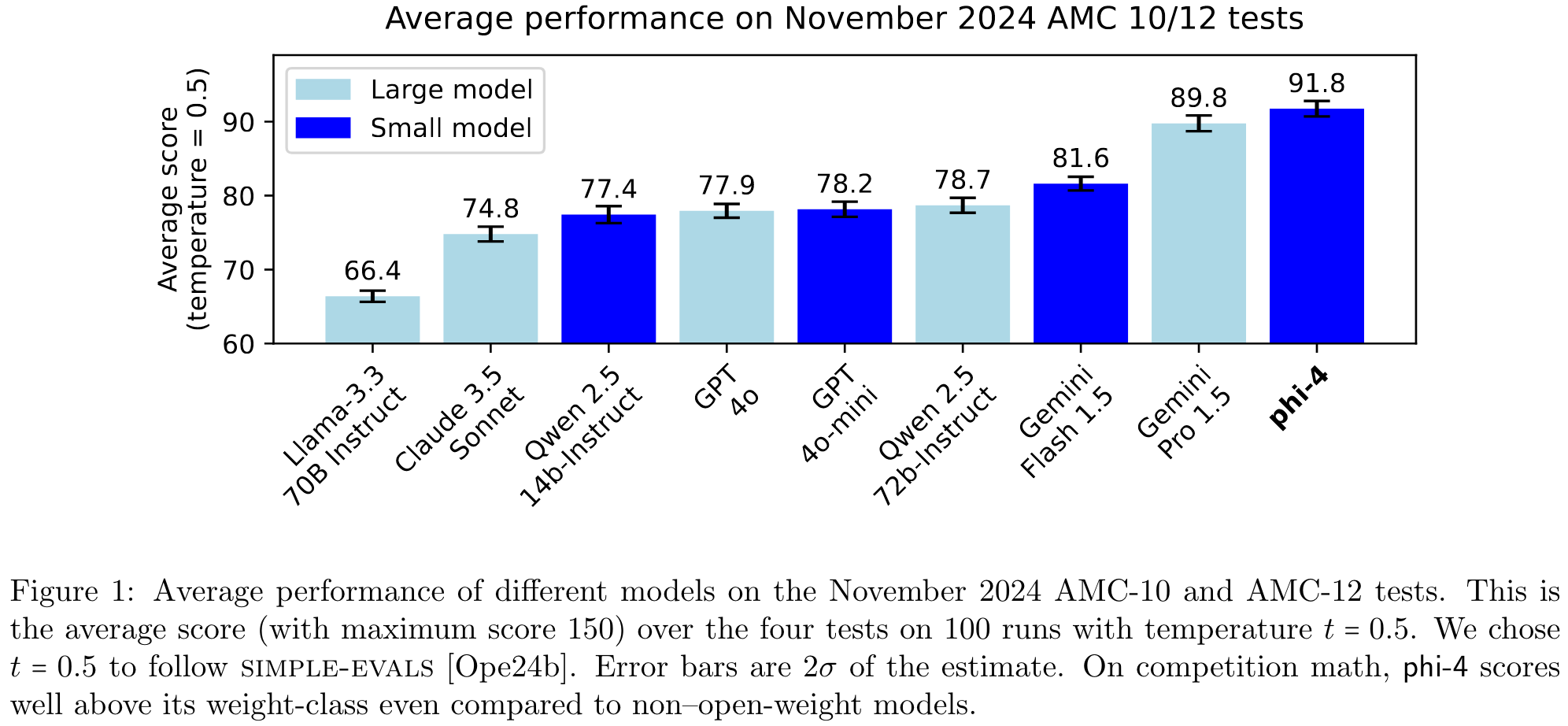
- 去污染与新鲜数据验证:论文在数据去污染和新鲜测试集(如 AMC-10/12 数学竞赛测试集)上采取了严格措施,确保评估的公平性和可靠性。
-
论文中存在的问题及改进建议:
- 指令遵从性不足:Phi-4 在严格遵循复杂指令(如特定格式要求、表格输出等)方面表现较差。这可能是因为训练数据中过于注重推理类任务,而忽略了指令遵从能力。改进建议:
- 在训练数据中增加针对复杂指令的合成数据。
- 设计专门的后训练阶段,优化模型在指令遵从任务上的表现。
- 对知识型任务的局限性:尽管模型在推理任务上表现出色,但在知识密集型任务(如 IFEval 和 SimpleQA)上表现不佳,可能与合成数据的知识覆盖面不足有关。改进建议:
- 增加高质量的知识型数据(如百科全书、领域知识文档)作为训练数据的补充。
- 在合成数据生成中加入更多涉及知识推理的任务。
- 冗长回答问题:由于模型在链式推理(chain-of-thought)任务中训练较多,Phi-4 在简单问题上也可能给出冗长的回答,影响用户体验。改进建议:
- 在后训练阶段加入任务权重调整,优化模型对简单问题的简洁回答能力。
- 设计用户交互式调节机制,允许用户选择回答的详细程度。
- 事实幻觉问题:模型在回答未知问题时可能生成虚假的内容(如编造人物传记)。改进建议:
- 在后训练阶段进一步加强拒绝回答(refusal to hallucinate)的能力。
- 增加检索增强机制(如集成搜索引擎)以减少幻觉。
- 指令遵从性不足:Phi-4 在严格遵循复杂指令(如特定格式要求、表格输出等)方面表现较差。这可能是因为训练数据中过于注重推理类任务,而忽略了指令遵从能力。改进建议:
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 研究路径 1:开发更高效的合成数据生成技术,专注于多语言环境中的推理任务。
- 研究路径 2:探索关键标记搜索(PTS)在其他领域(如多模态模型、长上下文模型)中的应用。
- 研究路径 3:针对小模型的知识增强任务,结合知识图谱和检索增强方法,提升知识型任务的表现。
-
为新的研究路径制定的研究方案:
-
研究路径 1:高效合成数据生成技术
- 研究目标:设计一种新的合成数据生成框架,支持多语言推理任务的数据生成。
- 研究方法:
- 从多语言语料库中提取高质量种子数据,涵盖不同语言的逻辑推理、数学问题和知识问答。
- 使用多代理提示和自我修订技术生成多语言合成数据,并确保数据的多样性和复杂性。
- 设计多语言推理基准测试,评估生成数据对模型性能的提升效果。
- 期望成果:
- 一套高效的多语言合成数据生成工具。
- 提升小模型在多语言推理任务上的性能。
- 推动多语言领域的推理研究。
-
研究路径 2:关键标记搜索在多模态模型中的应用
- 研究目标:将关键标记搜索(PTS)技术扩展到多模态模型的训练和优化中,提升跨模态推理能力。
- 研究方法:
- 在多模态任务(如图像-文本匹配、视频问答)中定义“关键标记”。
- 设计基于 PTS 的数据生成与优化流程,生成关键标记对模型性能有显著影响的多模态数据。
- 通过实验验证 PTS 在多模态任务中的有效性,并与传统优化方法进行对比。
- 期望成果:
- 一种适用于多模态任务的关键标记搜索技术。
- 提升多模态模型在复杂推理任务中的表现。
- 为多模态数据优化提供新的思路。
-
研究路径 3:结合知识图谱的知识增强
- 研究目标:通过结合知识图谱和检索增强方法,提升小模型在知识型任务(如 IFEval 和 SimpleQA)上的表现。
- 研究方法:
- 构建一个高质量的知识图谱,涵盖广泛领域的实体和关系。
- 在训练中引入知识图谱增强机制,使模型能够从知识图谱中检索相关信息并整合到回答中。
- 设计知识检索任务和基准测试,评估增强机制的效果。
- 期望成果:
- 一种结合知识图谱的小模型知识增强框架。
- 提升模型在知识型任务上的准确性和鲁棒性。
- 为小模型的知识推理能力提供新的解决方案。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!