目录
Resource Info Paper https://arxiv.org/abs/2412.11990 Code & Data https://execrepobench.github.io/ Public arXiv Date 2024
Summary Overview
本文主要提出了 ExecRepoBench 和指令数据集 RepoInstruct。
ExecRepoBench 包括了1.2K个从活跃的 Python 仓库中抽取的样本。提出了一个基于多级语法的完成方法,该方法在抽象语法树上进行了调节,以掩盖各种逻辑单元(例如语句,表达式和函数)的掩盖代码片段。
Main Content
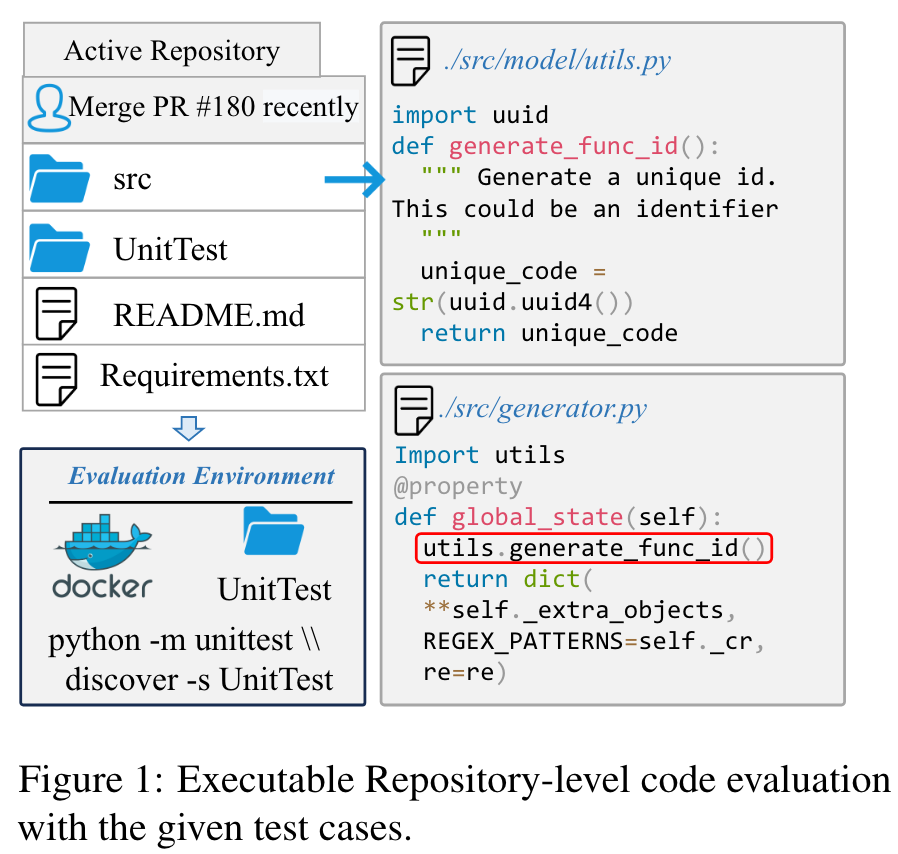
However, the community still lacks an executable evaluation reposity-level benchmark from live repositories and the corresponding instruction corpora.
ExecRepoBench 构建单元测试,以验证完成代码的正确性,该代码包含来自50个活动 Python 存储库中的1.2K样本。基于多级语法的完成来创建repoinstruct,其中在不同级别的逻辑单元下的代码片段被掩盖,以使用解析的抽象语法树(AST)完成。
ExecRepoBench Contruction
Data Collection and Annotation:
- Search Github code repositories of the Python language that have been continuously updated.
- Given the collected repositories, the annotator should collect or create the test cases for evaluation.
- All collected repositories should pass the test cases in a limited time for fast evaluation (<2 minutes).
Decontainmation:
To avoid data leakage, we remove exact matches (20-gram word overlap) from CrossCodeEval and the pretraining corpus stack V2.
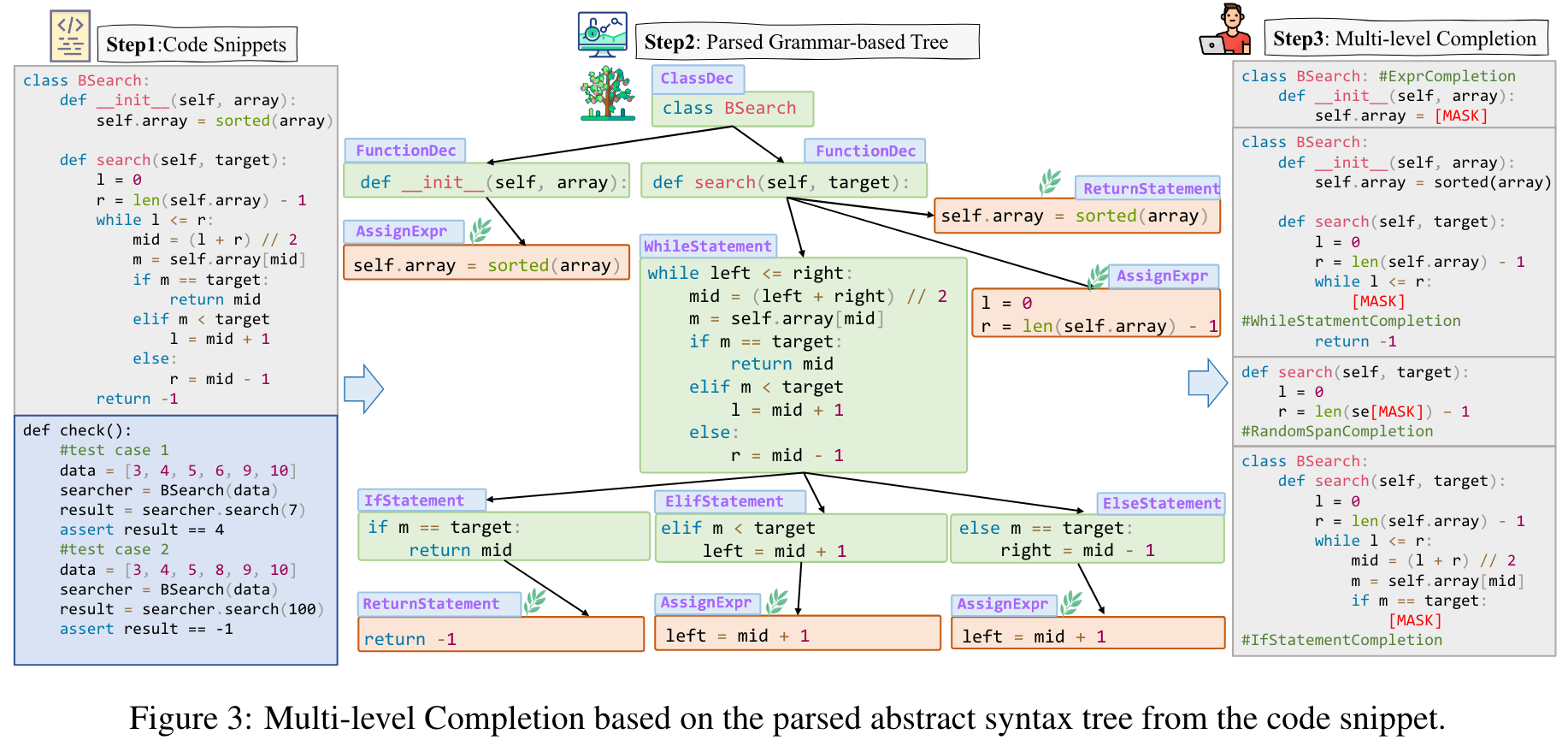

Completion:
- Problem Defintion
- In-file Completion
- Reposity-level Completion
- Multi-level Grammar-based Completion
- Expression-level Completion
- Statement-level Completion
- Function-level Completion
Qwen2.5-Coder-Instruct-C
Experiments
Metrics
- Edit Similarity
- Pass@k
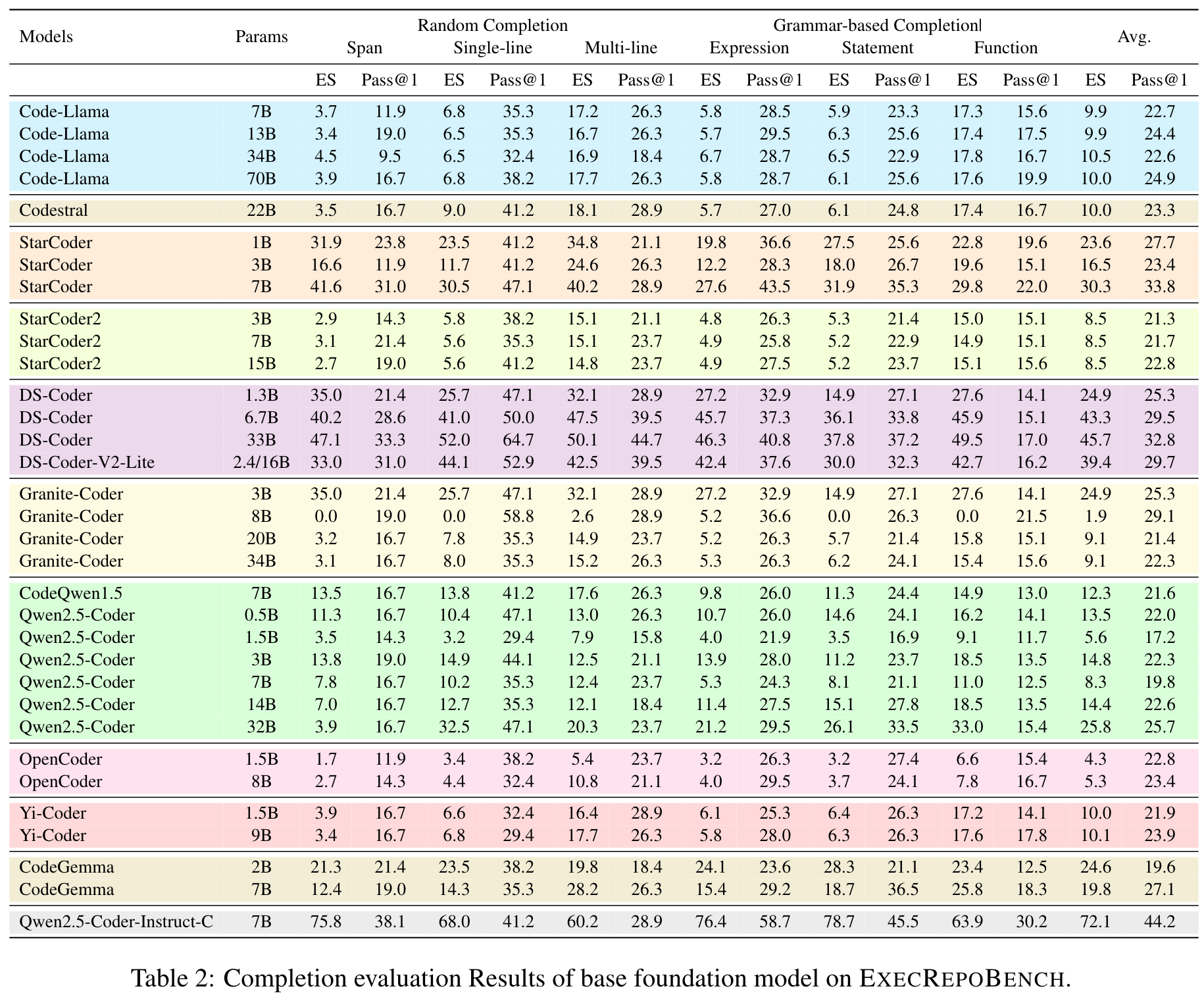
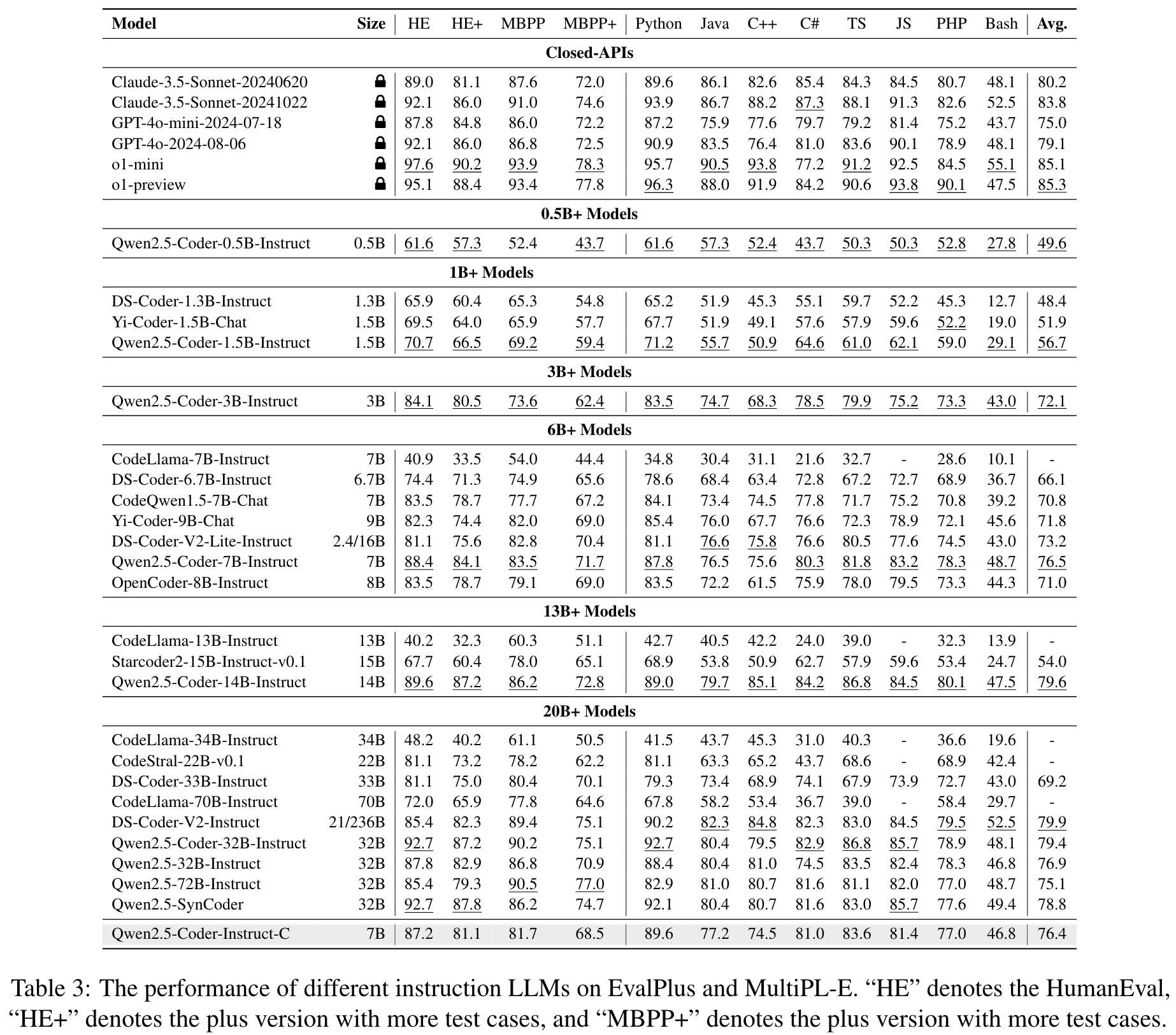
Results
Case Study

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 全新的可执行代码补全评估基准(EXECREPOBENCH):论文提出了一个基于真实代码库的评估基准 EXECREPOBENCH,区别于传统的静态评估方法,该基准通过单元测试验证代码补全的正确性,真实反映代码补全模型在实际开发中的表现。
- 多层次语法驱动的代码补全方法:通过基于抽象语法树(AST)的多层次掩码策略(表达式级、语句级、函数级等),改进了代码补全任务的细粒度性和上下文依赖性。
- 针对大规模开源模型的定制优化:论文基于开源大模型 Qwen2.5-Coder,通过混合指令调优(Hybrid Instruction Tuning),结合代码补全和问答任务,提出了性能优异的 Qwen2.5-Coder-Instruct-C 模型。
- 多语言支持与强大的跨语言性能:模型在 EXECREPOBENCH 和 MultiPL-E 等基准上展现了跨语言的优秀性能,尤其在 Pass@1 指标上显著优于其他同类模型。
- 强调执行结果的指标:论文指出传统基于字符串匹配的指标(如 Edit Similarity)存在局限性,提出以代码可执行性为核心的 Pass@k 指标更能反映模型实际能力。
-
论文中存在的问题及改进建议:
- 多语言场景的覆盖不足:尽管模型在多语言评估中表现良好,但论文主要集中于 Python,其他语言(如 JavaScript、C++)的评估样本较少,未能全面验证模型在复杂多语言代码库中的表现。
- 改进建议:扩展 EXECREPOBENCH 的多语言代码库,增加多语言代码的单元测试覆盖率,进一步验证模型在多语言场景下的泛化能力。
- 未充分探索模型的生成错误类型:论文主要关注生成代码的正确性,但未深入分析模型生成错误的具体类型(如逻辑错误、语法错误)。
- 改进建议:对生成错误进行分类统计,结合错误分析优化模型的训练目标,例如引入基于错误类型的权重调整或对常见错误场景进行强化学习。
- 缺乏对用户体验的优化探索:论文提出模型可用于本地开发服务,但未深入探讨其在实际开发环境中的用户体验(如响应速度、交互性)。
- 改进建议:设计用户调研或与 IDE 集成的实验,评估模型在真实开发场景中的使用效果,并针对用户反馈进行优化。
- 模型优化方法的局限性:论文主要采用监督微调(SFT)和混合指令调优,未探索诸如强化学习(RLHF)等方法的潜力。
- 改进建议:结合用户反馈或自动化测试结果,采用基于强化学习的模型优化方法,进一步提升模型的实际表现。
- 多语言场景的覆盖不足:尽管模型在多语言评估中表现良好,但论文主要集中于 Python,其他语言(如 JavaScript、C++)的评估样本较少,未能全面验证模型在复杂多语言代码库中的表现。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点 1:多语言动态依赖解析与代码补全
在复杂代码库中,动态依赖解析是一个关键问题。设计一个能够自动解析多语言代码库中跨文件依赖关系并利用其进行上下文感知补全的模型。 - 创新点 2:基于错误类型的自适应训练方法
针对代码补全生成的错误类型(如语法错误、逻辑错误等),设计一种自适应训练方法,通过错误分类权重调整模型的学习目标。 - 创新点 3:实时交互式代码补全与调试系统
开发一个实时交互式代码补全与调试系统,结合模型生成与单元测试结果,实时为开发者提供代码建议和错误修复。
- 创新点 1:多语言动态依赖解析与代码补全
-
为新的研究路径制定的研究方案:
-
研究路径 1:多语言动态依赖解析与代码补全
- 研究方法:
- 构建多语言代码库,涵盖 Python、JavaScript、C++ 等主流语言,标注跨文件依赖关系。
- 使用图神经网络(GNN)建模代码库的依赖关系图,捕获跨文件的上下文信息。
- 将依赖关系图嵌入到代码补全模型中,结合语法树(AST)进行上下文感知的代码生成。
- 研究步骤:
- 数据准备:扩展 EXECREPOBENCH,收集多语言代码库并标注依赖关系。
- 模型设计:设计结合 GNN 和 AST 的代码补全模型。
- 模型训练与评估:在扩展后的 EXECREPOBENCH 上训练模型,使用 Pass@k 和执行结果验证性能。
- 期望成果: 提出一种支持多语言动态依赖解析的代码补全方法,显著提升模型在跨文件依赖场景下的补全准确性。
- 研究方法:
-
研究路径 2:基于错误类型的自适应训练方法
- 研究方法:
- 对现有代码补全数据进行错误分类标注,区分语法错误、逻辑错误等。
- 设计一种基于错误类型的损失函数,动态调整模型对不同错误类型的关注权重。
- 引入强化学习(RLHF),结合用户反馈优化模型生成质量。
- 研究步骤:
- 数据标注:对 EXECREPOBENCH 和其他公开数据集中的生成错误进行分类。
- 模型训练:设计基于错误类型的自适应损失函数,并进行模型训练。
- 用户评估:结合用户调研和实验评估模型对不同错误类型的改进效果。
- 期望成果: 提出一种基于错误类型的自适应训练方法,显著降低模型生成错误率,提高代码补全的准确性和实用性。
- 研究方法:
-
研究路径 3:实时交互式代码补全与调试系统
- 研究方法:
- 设计一个 IDE 插件,集成代码补全模型和单元测试模块。
- 开发实时交互功能,允许开发者对生成代码进行反馈并实时更新模型建议。
- 利用强化学习优化模型的交互性能,提升用户体验。
- 研究步骤:
- 系统设计:开发一个结合代码补全与单元测试的 IDE 插件。
- 用户实验:邀请开发者参与实验,收集使用反馈。
- 模型优化:基于用户反馈和测试结果,使用 RLHF 优化模型性能。
- 期望成果: 开发一个实时交互式代码补全与调试系统,显著提升开发者的生产力和模型的实际应用价值。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!