目录
Resource Info Paper https://arxiv.org/abs/2409.17561 Code & Data / Public arXiv Date 2025.01.04
Summary Overview
TestBench, a benchmark for class-level LLM-based test case generation. We construct a dataset of 108 Java programs from 9 real-world, large-scale projects on GitHub, each representing a different thematic domain.
Five aspects to evaluate the LLMs: syntactic correctness, compilation correctness, test correctness, code coverage rate and defect detection rate.
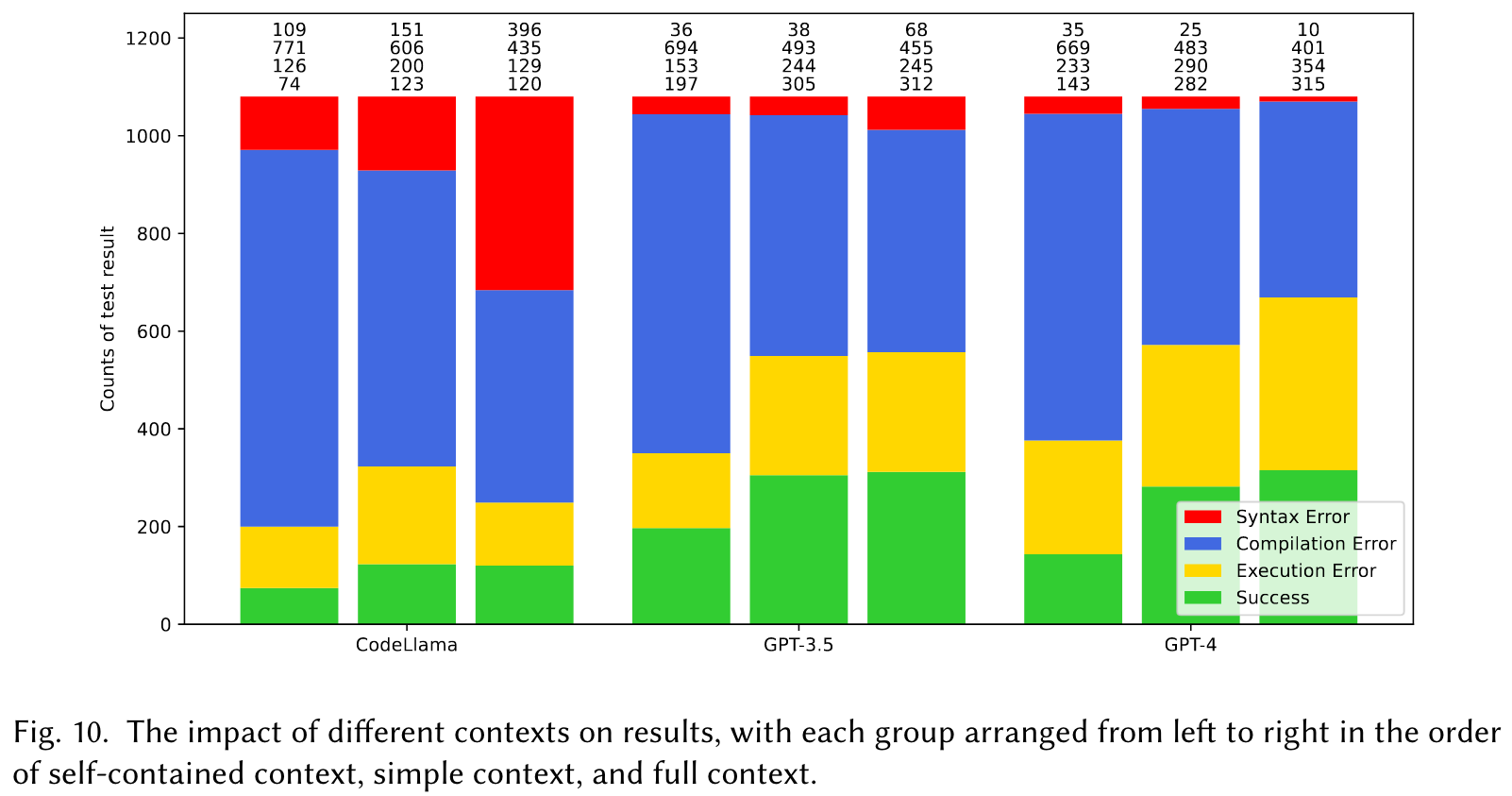
When using simplified version, namely the simple context, which is dervied from the full context via abstract syntax tree analysis, the performance of these models improves significantly.
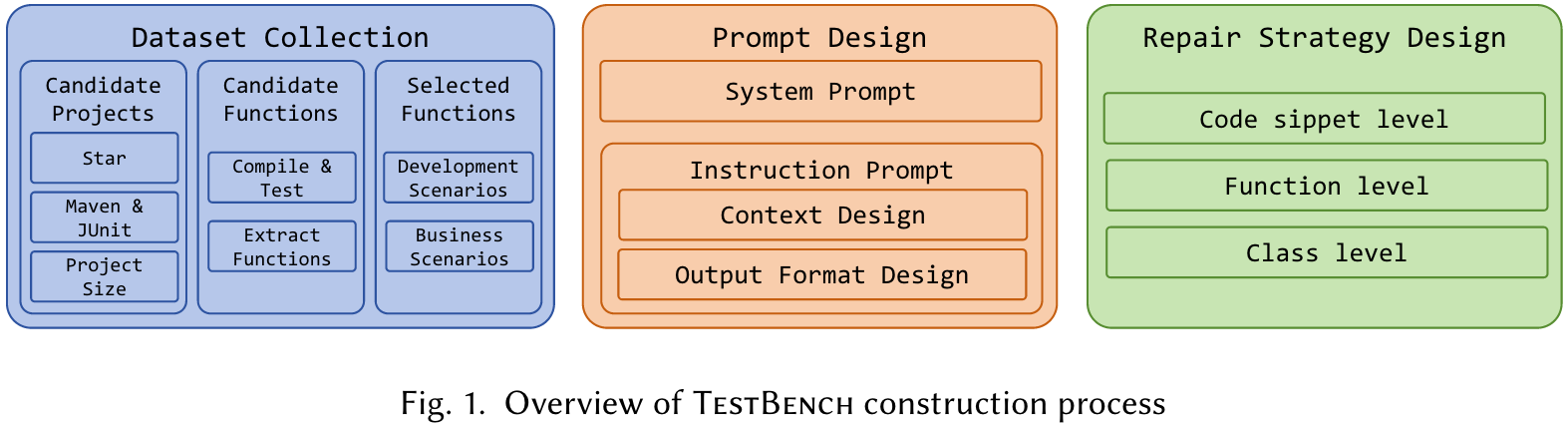
Main Content
Three steps to select functions under test from various open-source projects:
- We initially identify candidate projects by crawling Java repositories with more than 1,000 stars. We then refine the selection by filtering for projects that utilize the Maven and JUnit frameworks and have a project size between 10 to 100 MB, in order to strike a balance between representativeness and efficient compilation. After this step, we collect 99 candidate projects.
- We carefully select 20 projects from the candidate pool, ensuring a diverse range of topics. Each project is cloned and verified for successful compilation and test execution on our verification platform. We then extract all public functions, excluding test functions, interfaces, abstract methods, and deprecated functions.
- We manually select high-quality funcitons from the selected functions, with the primary criterion being whether a function frequently appears in real-world development scenarios. Then, we filter projects based on the number of high-quality functions they contain, helping us to achieve the same number of selected functions with fewer projects.
Prompt Design
- Self-contained context
- Full context

- Simple context

完整的 prompt 结构:

Evaluation Metric:
- Syntactic correctness: 我们希望生成的测试用例可以直接执行。为此,我们将Javalang用作生成测试用例的Java代码的静态分析工具。
- Compilation correctness: 由于静态分析无法识别诸如变量名称,函数名称和范围之类的错误,因此我们使用MVN测试过程动态编译生成的测试用例以对代码进行动态分析,从而确定是否可以正确编译测试用例。
- Execution correctness: 考虑到LLMS代码生成的不确定性,它是否可以用正确的断言生成测试用例,准确地发现生产代码中的缺陷,并避免误判正确的逻辑也是至关重要的部分。我们根据测试案件执行期间是否发生故障或错误来评估测试案例的正确性。
- Coverage rate: 对于可以正确执行的测试用例,我们旨在计算测试功能的覆盖范围,以衡量其检测潜在缺陷的能力。由于所选项目的复杂性,我们选择通过中级代码仪器来衡量覆盖范围指标。为此,我们使用jacoco计算测试用例的覆盖率。
- Defect detection rate: 除了覆盖范围之外,我们还选择经典的突变测试来检测测试案例代码中的缺陷。为此,我们使用默认类型和突变数量来计算测试用例的突变杀伤率以评估其有效性水平。
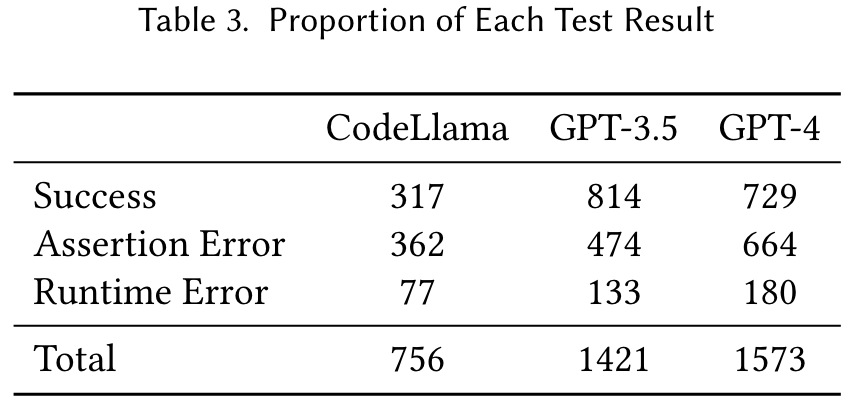
How do CodeLlama, ChatGPT and GPT4 perform on TestBench?
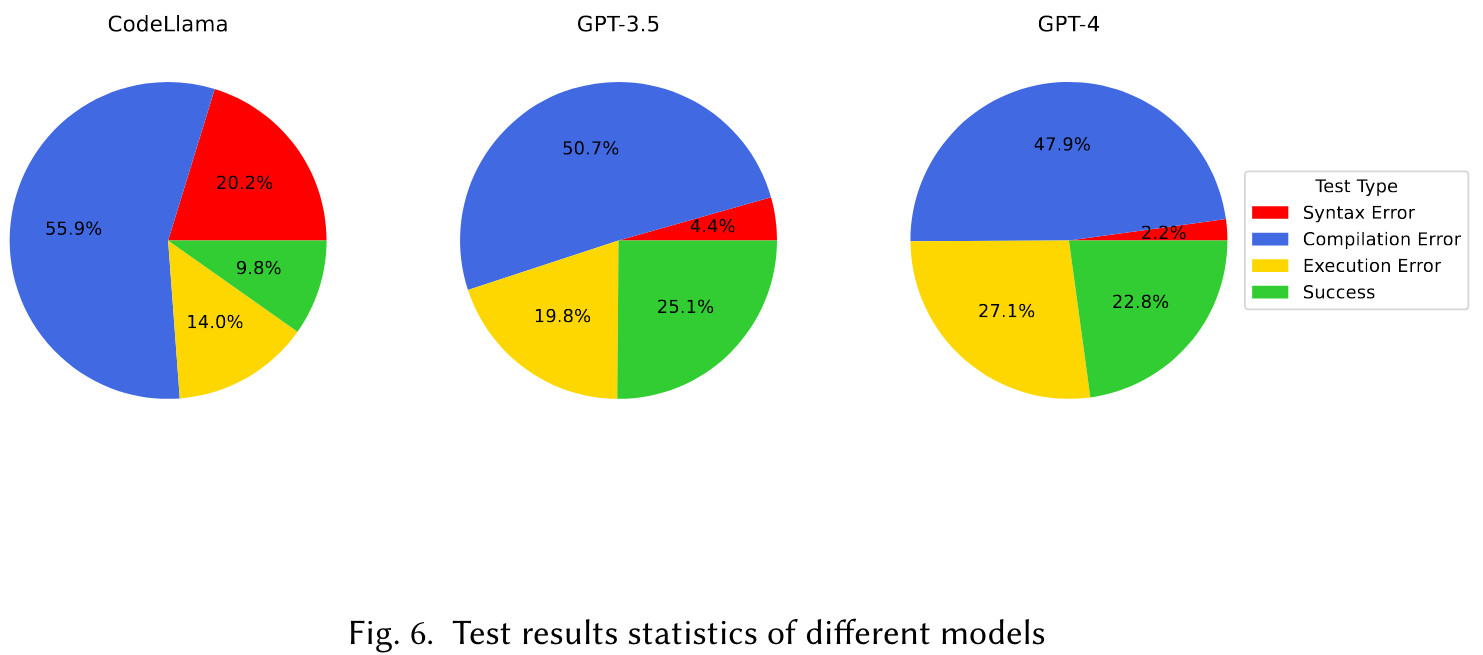
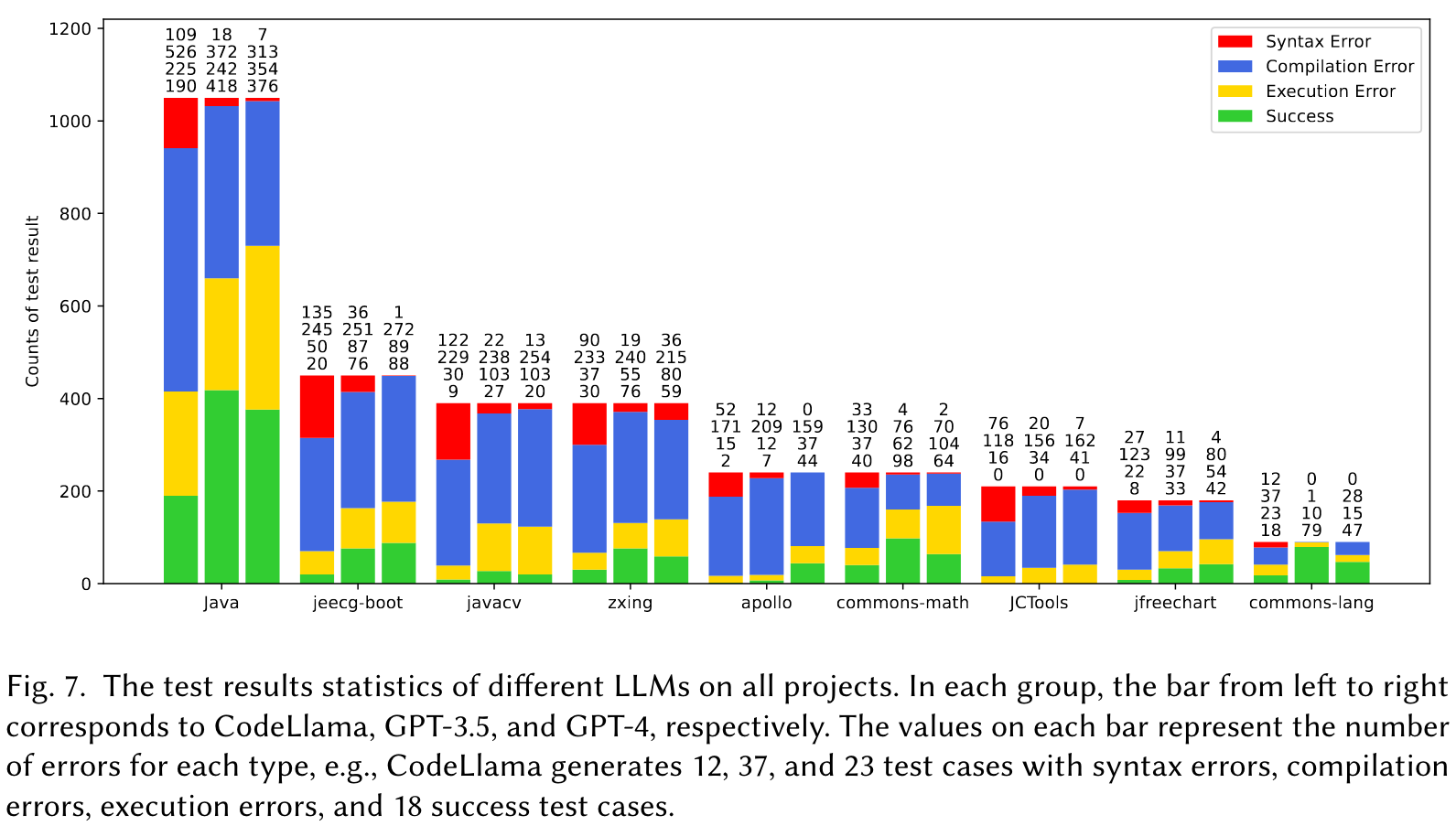
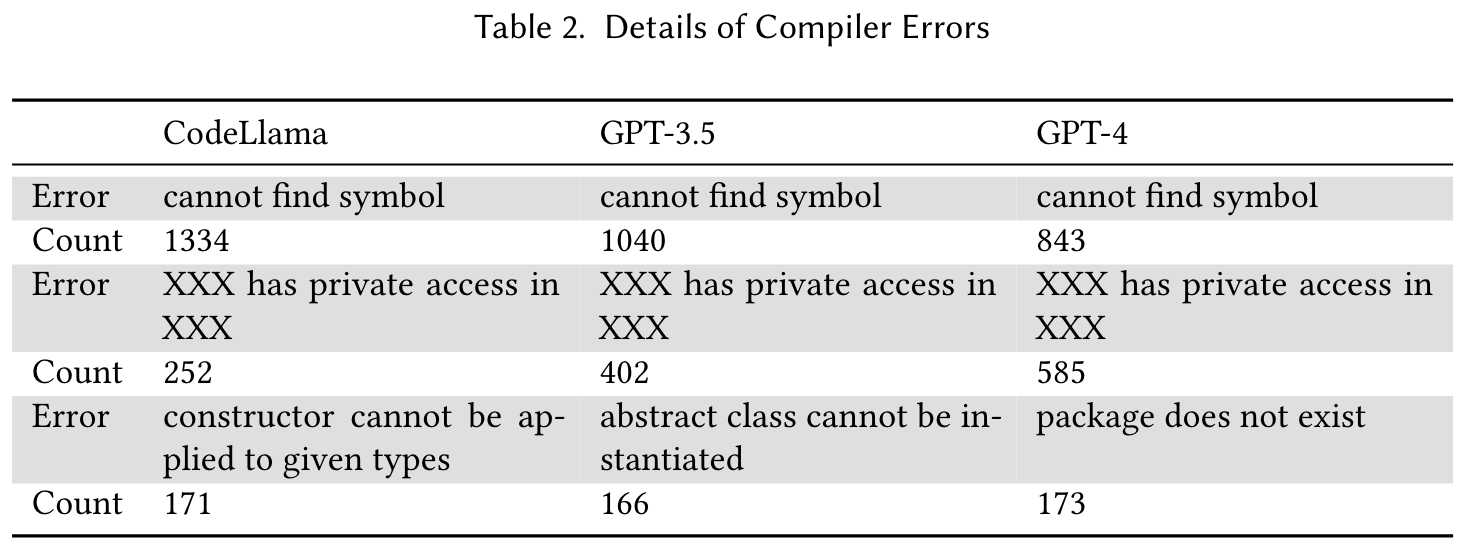

How do different contexts affect the results?
🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 提出了首个针对类级测试用例生成的基准(TestBench):论文填补了测试用例生成领域缺乏公开基准的空白,通过构建TestBench,系统性地评估了大语言模型(LLMs)在生成类级测试用例中的能力。
- 设计了多维度的评估框架:提出了五个细化的评估指标(语法正确性、编译正确性、执行正确性、代码覆盖率和缺陷检测率),为全面评估LLMs生成的测试用例质量提供了依据。
- 引入三种上下文描述:通过对上下文内容的不同设计(自包含上下文、完整上下文、简化上下文),探索了上下文信息对测试用例生成质量的影响。
- 提出启发式修复算法:针对生成测试用例中的常见错误模式,设计了一种启发式修复算法,提高了测试用例的语法正确性和编译通过率。
- 实验结果揭示模型规模对上下文处理能力的影响:研究表明,较大的模型(如GPT-4)在处理复杂上下文时表现更优,而小规模模型(如CodeLlama)在面对丰富上下文时容易受到噪声干扰。
-
论文中存在的问题及改进建议:
- 数据泄漏的潜在威胁:由于TestBench数据集来源于GitHub的开源项目,可能与LLMs的训练数据存在重叠,无法完全排除数据泄漏的可能性。改进建议:通过更严格的去重和验证机制,确保数据集的独立性;或者构建完全独立的测试数据集,比如从未公开的代码库中选取样本。
- 测试用例生成的实际开发场景适用性有限:虽然论文使用了真实的开源项目,但其测试用例生成的适用性主要集中于类级别,缺乏对更复杂场景(如跨模块测试或系统级测试)的探索。改进建议:扩展基准测试的范围,涵盖更多真实开发场景和复杂系统。
- 模型性能分析的深度不足:虽然论文分析了不同模型的错误类型,但未深入探讨错误的根本原因(如模型生成逻辑或上下文理解能力的不足)。改进建议:结合模型内部的生成过程,分析其在特定任务上的局限性,并提出针对性的改进方法。
- 修复算法的通用性有限:启发式修复算法主要针对结构性错误,未能覆盖逻辑性错误或更复杂的缺陷模式。改进建议:结合程序分析技术(如静态分析和动态分析),设计更智能的修复算法,覆盖更多错误类型。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:基于跨模块上下文的测试用例生成:探索如何利用跨模块或跨类的上下文信息来生成更复杂的测试用例,评估模型对全局代码结构的理解能力。
- 创新点2:引入语义增强的上下文表示:通过结合程序的语义信息(如变量依赖、调用关系图等),优化上下文表示,提升测试用例生成的逻辑正确性。
- 创新点3:开发用于测试用例生成的多模型协作框架:设计一个框架,让不同规模和类型的模型协作生成测试用例,以结合各模型的优势,提升生成质量。
-
为新的研究路径制定的研究方案:
-
研究路径1:基于跨模块上下文的测试用例生成
- 研究方法:从大型开源项目中提取跨模块的代码片段,构建包含跨模块上下文的测试数据集。设计包含跨模块信息的提示词,评估LLMs在生成跨模块测试用例时的表现。
- 研究步骤:
- 数据集构建:选择包含复杂模块依赖关系的开源项目,提取跨模块函数及其调用关系。
- 提示词设计:在提示中加入模块间依赖信息,如调用链、全局变量等。
- 模型评估:使用TestBench的评估框架,增加对跨模块测试用例的覆盖率和缺陷检测能力的评估。
- 期望成果:证明跨模块上下文能够显著提升测试用例的覆盖率和逻辑正确性,提出适用于跨模块测试用例生成的最佳实践。
-
研究路径2:引入语义增强的上下文表示
- 研究方法:通过静态分析工具提取代码的语义信息(如控制流图、数据流图),并将其嵌入到上下文中,作为提示词的一部分进行测试用例生成。
- 研究步骤:
- 语义信息提取:使用工具(如AST解析器或数据流分析工具)提取函数的语义特征。
- 提示词优化:将语义信息转化为自然语言描述或结构化数据,嵌入到提示中。
- 实验验证:比较加入语义信息前后的生成效果,分析语义增强的上下文对生成质量的影响。
- 期望成果:开发出一种结合语义信息的上下文设计方法,显著提升测试用例的逻辑正确性和缺陷检测能力。
-
研究路径3:开发用于测试用例生成的多模型协作框架
- 研究方法:设计一个协作生成框架,利用小模型生成初始测试用例,大模型进行优化和修复,最后通过规则或专家模型进行验证。
- 研究步骤:
- 框架设计:定义多模型协作的流程,包括任务分配、结果整合和反馈机制。
- 实验设置:在TestBench数据集上测试协作框架的性能,比较单模型和多模型的生成效果。
- 性能优化:分析不同模型在协作中的表现,调整任务分配策略以优化生成质量。
- 期望成果:证明多模型协作能够结合各模型的优势,生成更高质量的测试用例,并提出适用于测试用例生成的协作框架设计原则。
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!