请注意,本文编写于 579 天前,最后修改于 579 天前,其中某些信息可能已经过时。
目录
Resource Info Paper https://arxiv.org/abs/2412.05210 Code & Data https://codearenaeval.github.io/ Public arXiv Date 2024
Summary Overview
当前的代码LLM专注于合成正确的代码段,忽略了与人类偏好的对齐,在这些偏好中应从实际的应用程序场景中采样查询,并且模型生成的响应应满足人类偏好。为了解决上述问题,作者提出了 CodeArena。

Main Content
Contributions:
- We propose CodeArena comprised of 397 manually annotated samples, a comprehensive code evaluation benchmark for evaluating the alignment between the model-generated response and human preference, encompassing 7 major categories and 40 subcategories.
- We introduce SynCode-Instruct, the large-scale synthetic code instruction corpora from the website. Based on SynCode-Instruct, an effective coder Qwen2.5-SynCoder is used as a strong baseline for CodeArena.
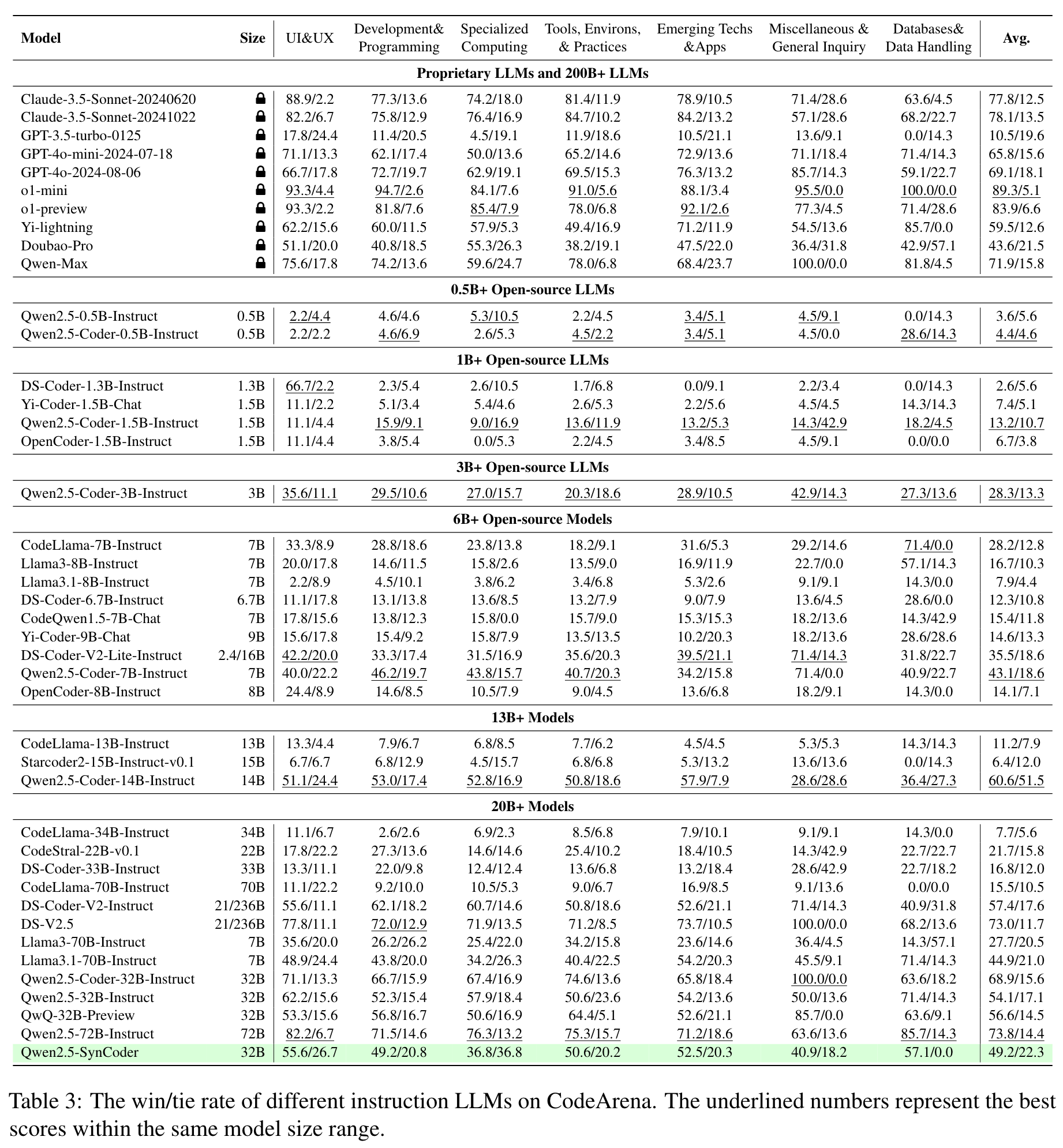
- We systematically evaluate 40+ LLMs on CodeArena and create a leaderboard to dynamically update the results. Notably, extensive experiments suggest that CodeArena can effectively measure the alignment between the model-generated response and human preference.
Dataset Statistics:

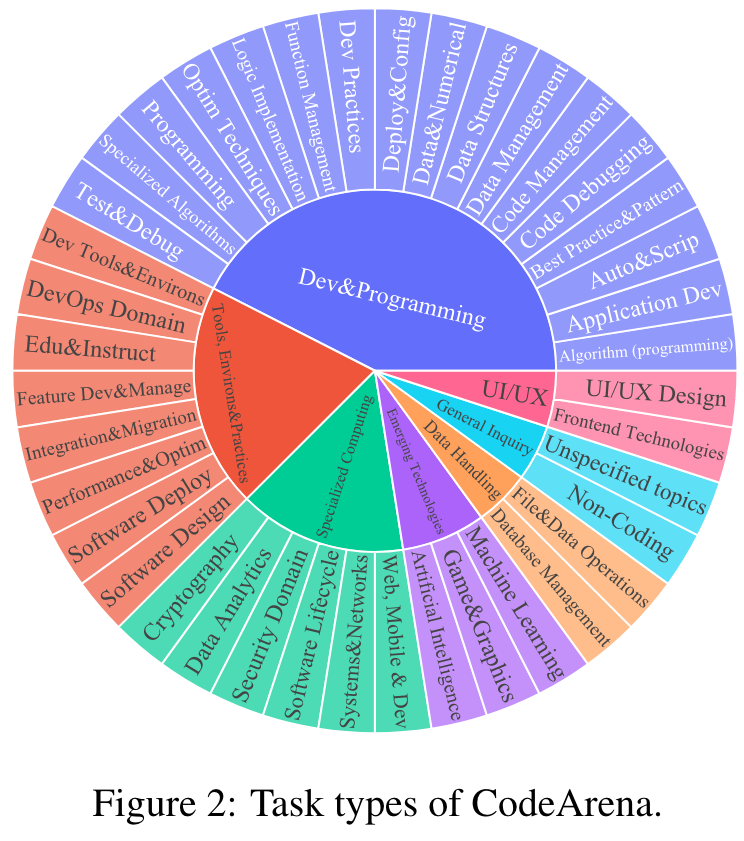
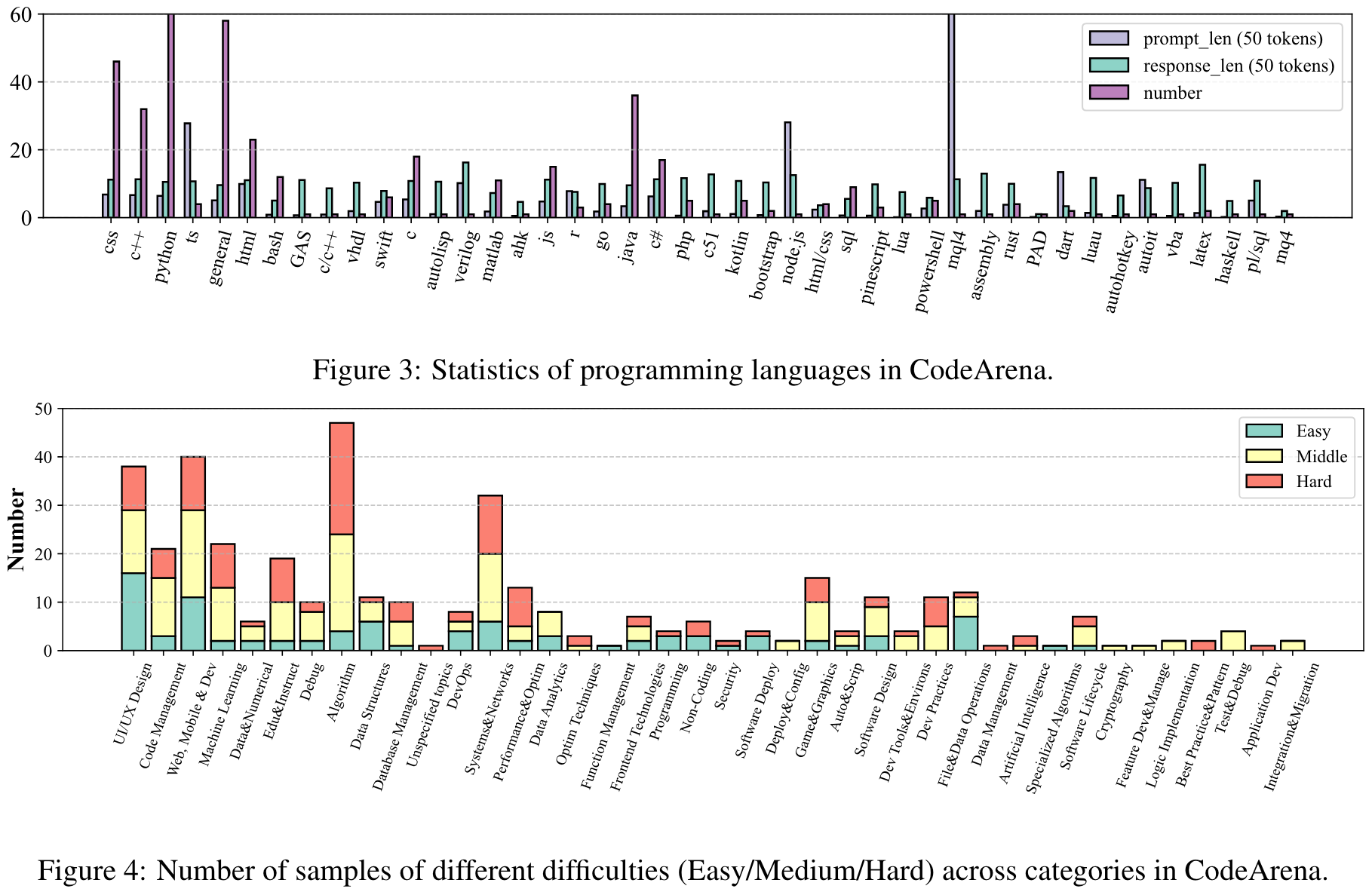
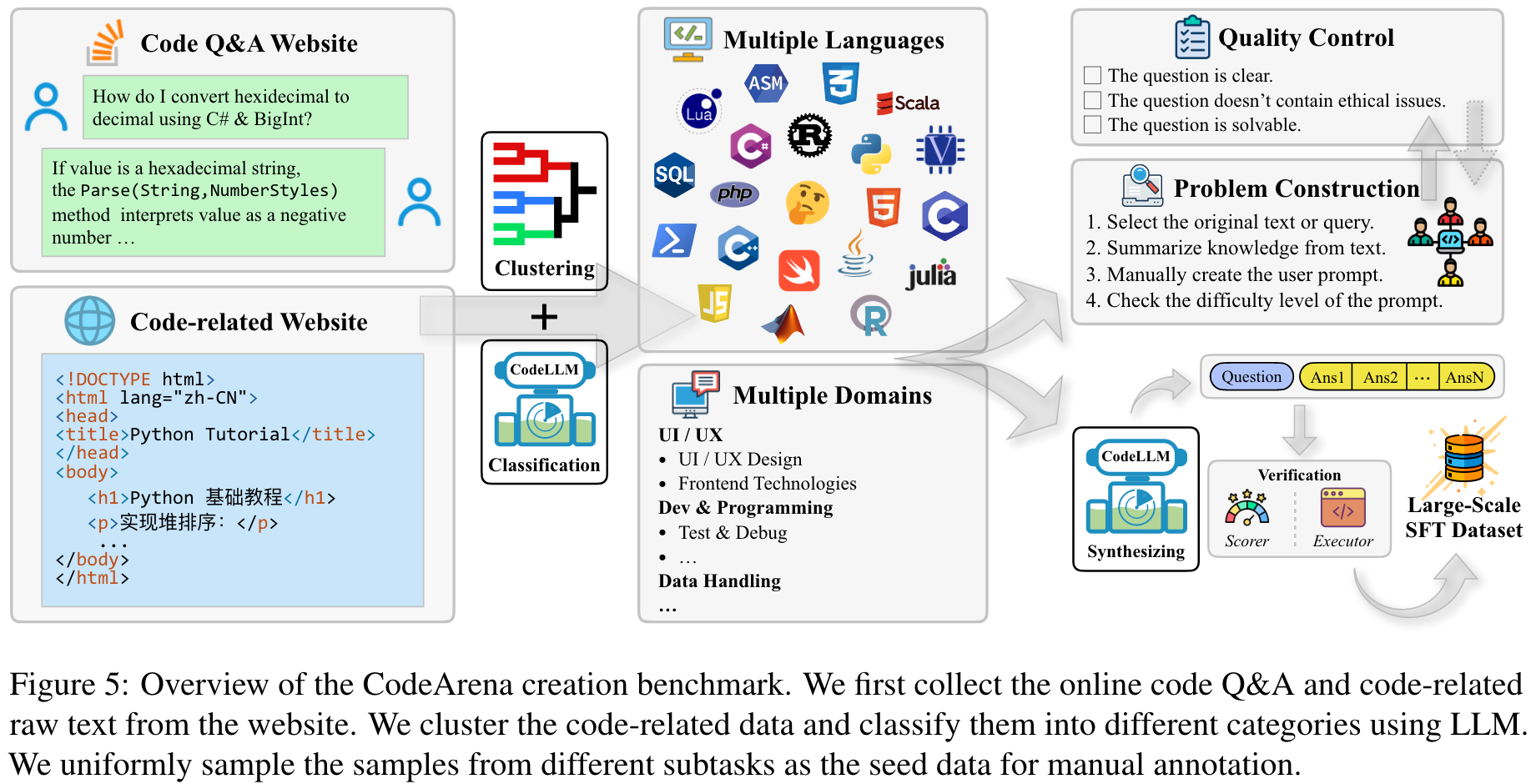
Prompt:

Results:
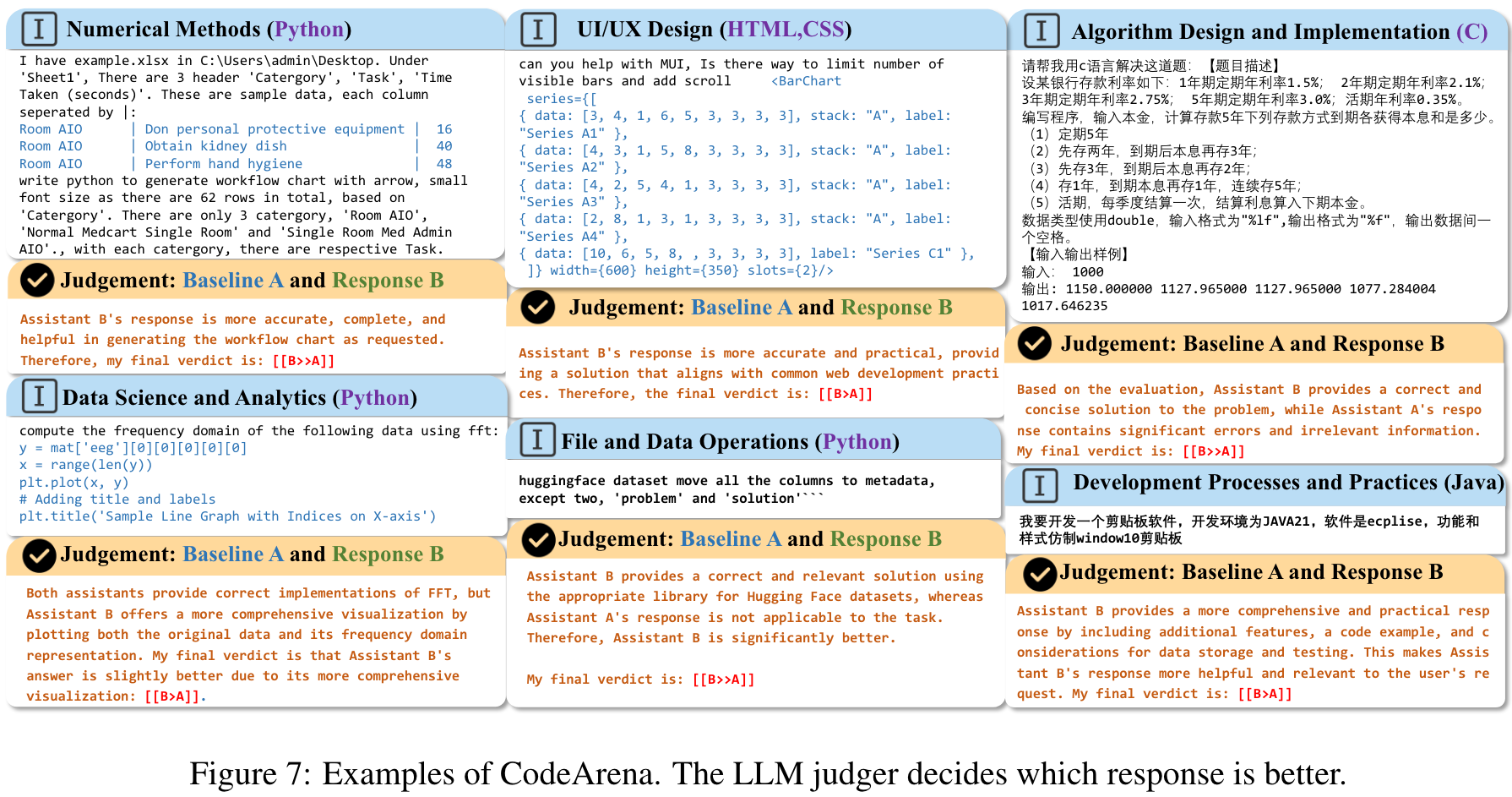
Examples:
Distribution of different benchmarks:
We visualize the quries of CodeArena and MultiPL-E(Python, Java, and CPP) by extracting the encoder representations of the last layer for t-SNE.

🤖ChatGPT
ChapGPT
-
论文的创新之处与独特性:
- 提出了CodeArena基准:CodeArena是一个人类精心设计的高质量基准,包含397个样本,涵盖40个类别和44种编程语言,专注于评估代码生成模型与人类偏好的对齐程度。这一基准填补了现有代码基准测试(如HumanEval、MBPP等)仅关注代码正确性的不足,强调了人类偏好的重要性。
- 引入SynCode-Instruct数据集:作者通过从网络上扩展指令,构建了一个包含近200亿标记的大规模合成指令数据集。通过该数据集训练的Qwen2.5-SynCoder模型在CodeArena和传统代码生成基准上的表现均达到开源模型的领先水平。
- 系统评估了40多个LLM的性能:论文对40多个大语言模型(包括开源和闭源模型)的表现进行了全面评估,揭示了开源模型(如Qwen-Coder)与闭源模型(如Claude系列、o1)的显著性能差距,凸显了人类偏好对齐的重要性。
- 创新的评价方法:通过“LLM-as-a-judge”(使用GPT-4o作为评估者)进行对比评估,避免了传统基准测试中单纯依赖代码执行的局限性,更贴近真实使用场景下的人类需求。
-
论文中存在的问题及改进建议:
- 数据集规模有限:尽管CodeArena覆盖了40个类别,但样本数量仅为397,这对于评估模型在更广泛场景中的泛化能力可能不足。建议进一步扩展数据集规模,尤其是增加更多真实用户查询的样本。
- 对齐方法的细节不足:论文虽然强调了人类偏好对齐的重要性,但未提供关于如何高效对齐模型生成的详细技术细节。可以补充更具体的对齐方法,例如基于RLHF(人类反馈强化学习)的优化策略。
- 缺乏对多模态代码生成的研究:当前研究主要集中在单一文本到代码的生成任务上,而未涉及多模态输入(如图像、表格、文本结合)的代码生成任务。建议在未来的研究中探索多模态代码生成的潜力。
- 模型性能的解释性不足:论文主要关注模型的性能比较,但缺乏对模型生成结果的详细分析和解释,尤其是模型为何在某些任务上表现优异或不足的原因分析。
-
基于论文的内容和研究结果,提出的创新点或研究路径:
- 创新点1:构建多模态代码生成基准:设计一个包含文本、图像、表格等多模态输入的代码生成基准,用于评估模型在复杂场景中的代码生成能力。
- 创新点2:开发高效的人类偏好对齐方法:基于RLHF或其他对齐技术,开发一种高效的训练方法,使得代码生成模型能够更好地满足人类偏好。
- 创新点3:探索模型生成结果的解释性:设计一种分析框架,深入研究不同模型在生成代码时的决策过程,揭示其性能差异的原因。
-
为新的研究路径制定的研究方案:
-
研究路径1:构建多模态代码生成基准
- 研究方法:
- 收集多模态数据:从开源项目、技术文档和问答社区中提取包含文本、图像、表格等多模态信息的代码相关问题。
- 标注数据:对问题进行分类,明确每个问题的输入模态和目标输出。
- 设计基准测试:创建多模态任务,包括代码生成、优化和解释等。
- 研究步骤:
- 数据收集与清洗:确保数据质量并去重。
- 数据标注与分类:根据任务类型和输入模态对数据进行标注。
- 模型评估:使用现有的多模态模型(如CodeT5、ImageBind等)在基准上进行测试。
- 期望成果:
- 一个公开的多模态代码生成基准测试数据集。
- 对现有模型在多模态任务上的性能评估报告。
- 提出改进多模态代码生成的方向。
- 研究方法:
-
研究路径2:开发高效的人类偏好对齐方法
- 研究方法:
- 基于RLHF的对齐优化:通过人类反馈强化学习对模型生成结果进行优化。
- 数据增强:利用合成数据扩充偏好对齐训练数据集。
- 交互式学习:设计用户交互界面,收集更多人类偏好数据。
- 研究步骤:
- 构建RLHF训练框架:包括奖励模型和优化算法。
- 设计实验:比较不同对齐方法的效果。
- 模型微调:在CodeArena和其他基准上验证对齐方法的有效性。
- 期望成果:
- 一种高效的偏好对齐训练方法。
- 一个包含人类反馈的高质量对齐数据集。
- 提高模型在CodeArena等基准上的表现。
- 研究方法:
-
研究路径3:探索模型生成结果的解释性
- 研究方法:
- 设计生成分析工具:对模型生成的代码进行语义分析和结构分析。
- 引入可解释性指标:量化模型生成结果的可解释性。
- 比较不同模型的决策过程:揭示模型在生成代码时的逻辑。
- 研究步骤:
- 开发分析工具:包括代码语法分析器和语义匹配工具。
- 设计实验:比较不同模型在生成代码时的可解释性。
- 优化模型:通过分析结果改进模型生成逻辑。
- 期望成果:
- 一个用于代码生成分析的工具包。
- 可解释性指标的定义及其在模型评估中的应用。
- 提高模型生成代码的透明性和用户信任度。
- 研究方法:
-
Others
本文作者:Geaming
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录